适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在本教程中,你将使用 Azure 门户创建数据工厂。 然后,你将使用复制数据工具创建一个管道,该管道仅以增量方式复制新的和已更改的文件,从Azure Blob 存储复制到Azure Blob 存储。 它使用 LastModifiedDate 来确定要复制的文件。
完成此处的步骤后,Azure Data Factory将扫描源存储中的所有文件,应用文件筛选器LastModifiedDate,并将那些新文件或自上次以来更新的文件复制到目标存储。 请注意,如果数据工厂扫描大量文件,预计仍需长时间完成。 即使减少了要复制的数据量,文件扫描也很耗时。
注意
如果不熟悉数据工厂,请参阅 Azure Data Factory 简介。
在本教程中,你将完成以下任务:
- 创建数据工厂。
- 使用“复制数据”工具创建管道。
- 监视管道和活动的运行情况。
先决条件
- Azure subscription:如果没有Azure订阅,请在开始前创建 trial account。
- Azure Storage帐户:用 Blob 存储来存储源数据和汇聚器数据。 如果没有Azure Storage帐户,请按照 创建存储帐户中的说明操作。
在 Blob 存储中创建两个容器
完成以下步骤,准备本教程所需的 Blob 存储:
创建名为 source 的容器。 可以使用各种工具来执行此任务,例如 Azure Storage Explorer。
创建名为 destination 的容器。
创建数据工厂
在顶部菜单中,选择“ 创建资源>数据 + 分析>数据工厂 ” :
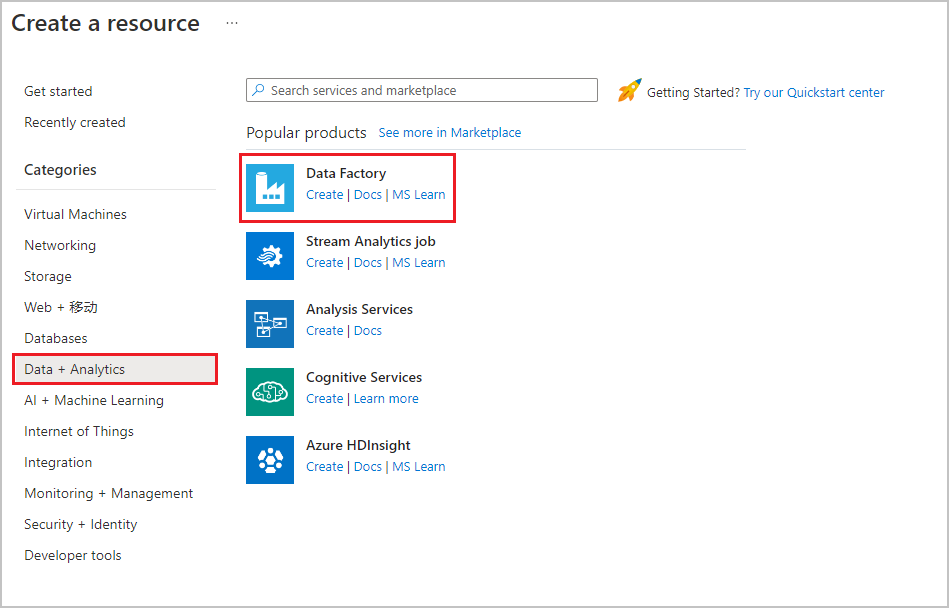
在“新建数据工厂” 页的“名称”下输入 ADFTutorialDataFactory 。
数据工厂的名称必须在全球范围内独一无二。 可能会收到以下错误消息:
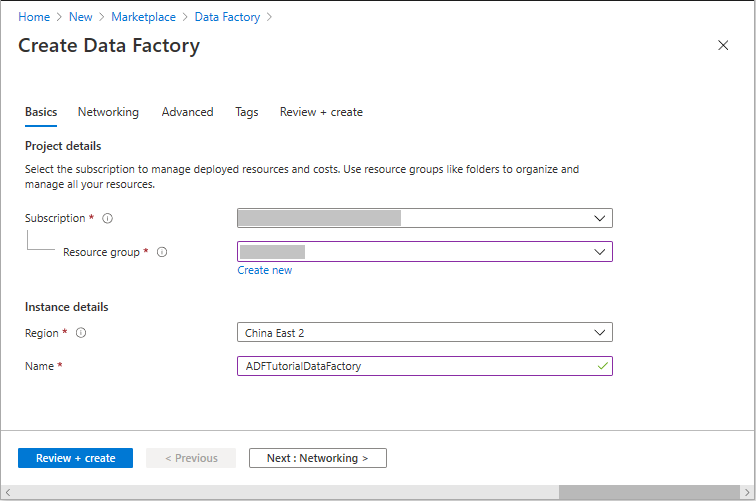
如果收到有关名称值的错误消息,请为数据工厂输入另一名称。 例如,使用名称 yournameADFTutorialDataFactory。 有关数据工厂项目的命名规则,请参阅数据工厂命名规则。
在 Subscription 下,选择要在其中创建新数据工厂的Azure订阅。
在“资源组”下执行以下步骤之一 :
选择“使用现有”,然后在列表中选择现有的资源组。
选择“新建”,然后输入资源组的名称 。
若要了解资源组,请参阅 使用资源组来管理Azure资源。
在“位置”下选择数据工厂的位置。 列表中仅显示支持的位置。 数据存储(例如,Azure Storage和Azure SQL Database)和计算(例如,数据工厂使用的Azure HDInsight)可以位于其他位置和区域。
选择“创建” 。
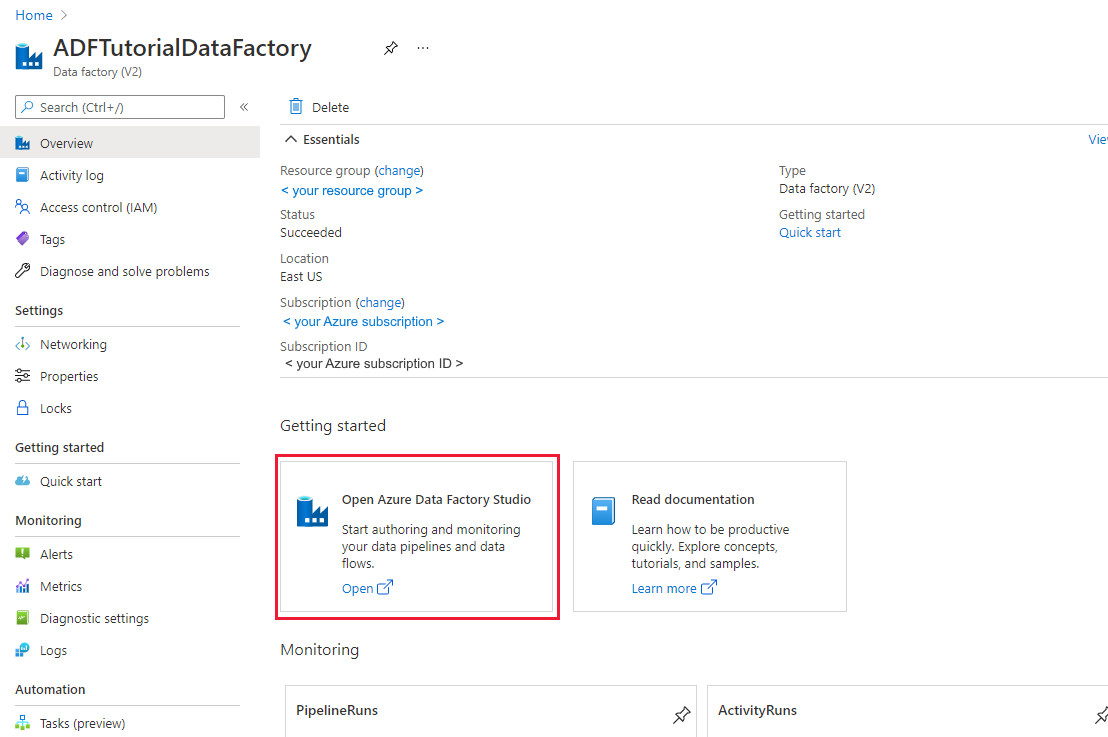
创建数据工厂后,会显示数据工厂主页。
若要在单独的选项卡上打开Azure Data Factory用户界面(UI),请在 Open Azure Data Factory Studio 磁贴上选择 Open:
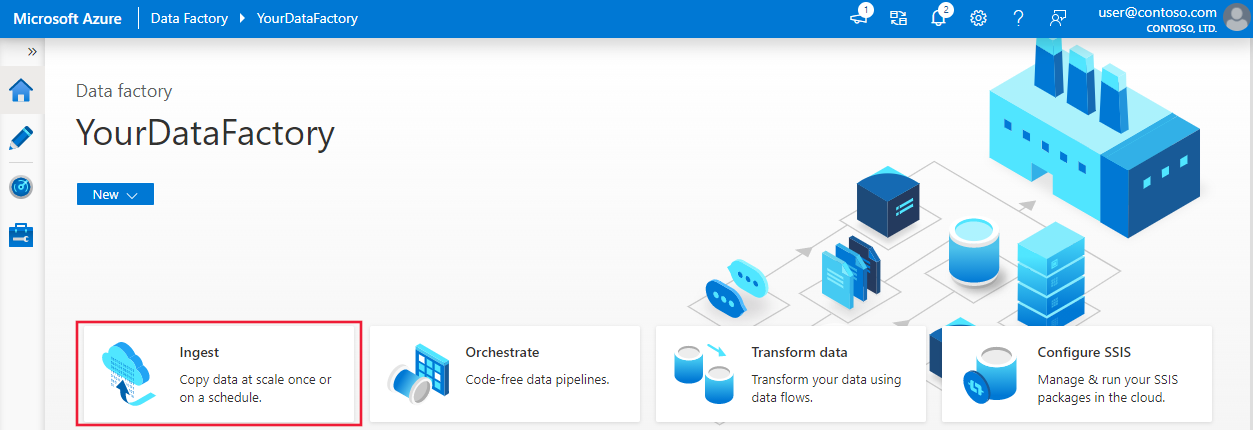
使用“复制数据”工具创建管道
在Azure Data Factory主页上,选择引入磁贴以打开“复制数据”工具:
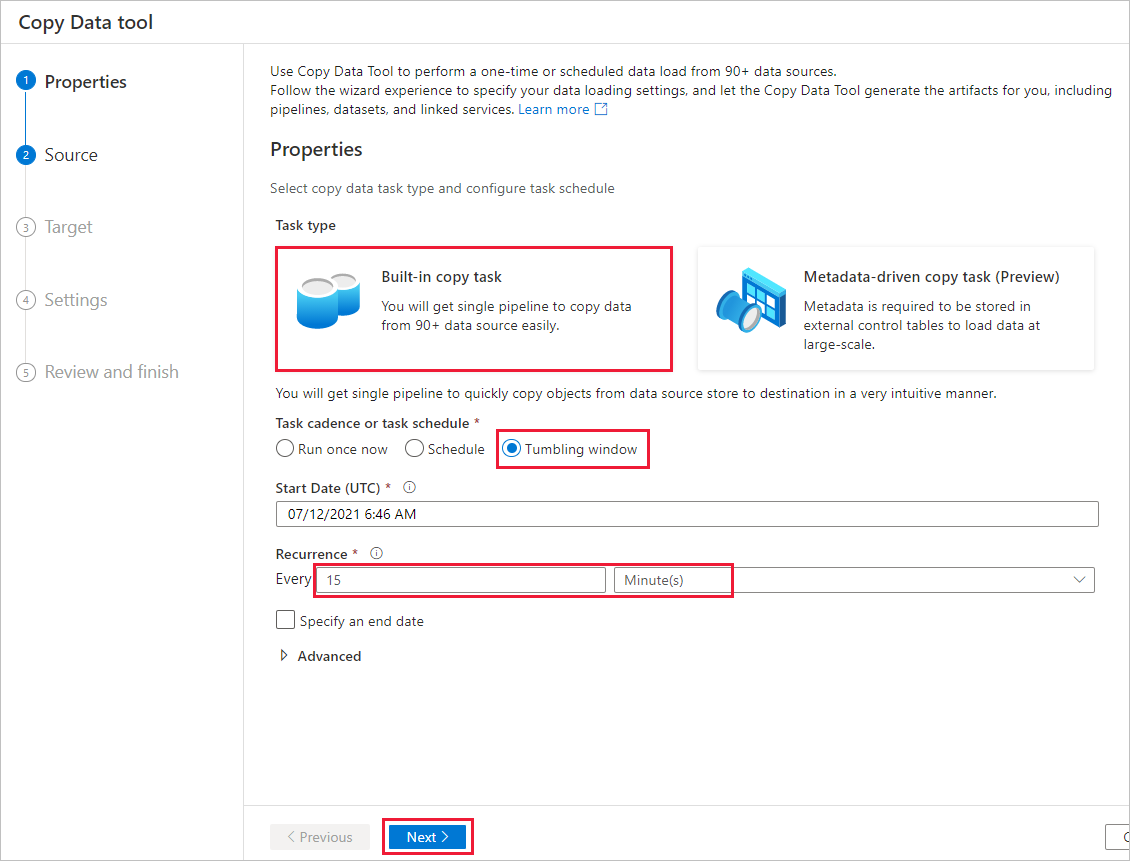
在“属性”页上执行以下步骤:
在“任务类型”下,选择“内置复制任务” 。
在“任务节奏或任务计划”下,选择“滚动窗口”。
在“重复周期”下请输入“15分钟”。
选择“下一步”。
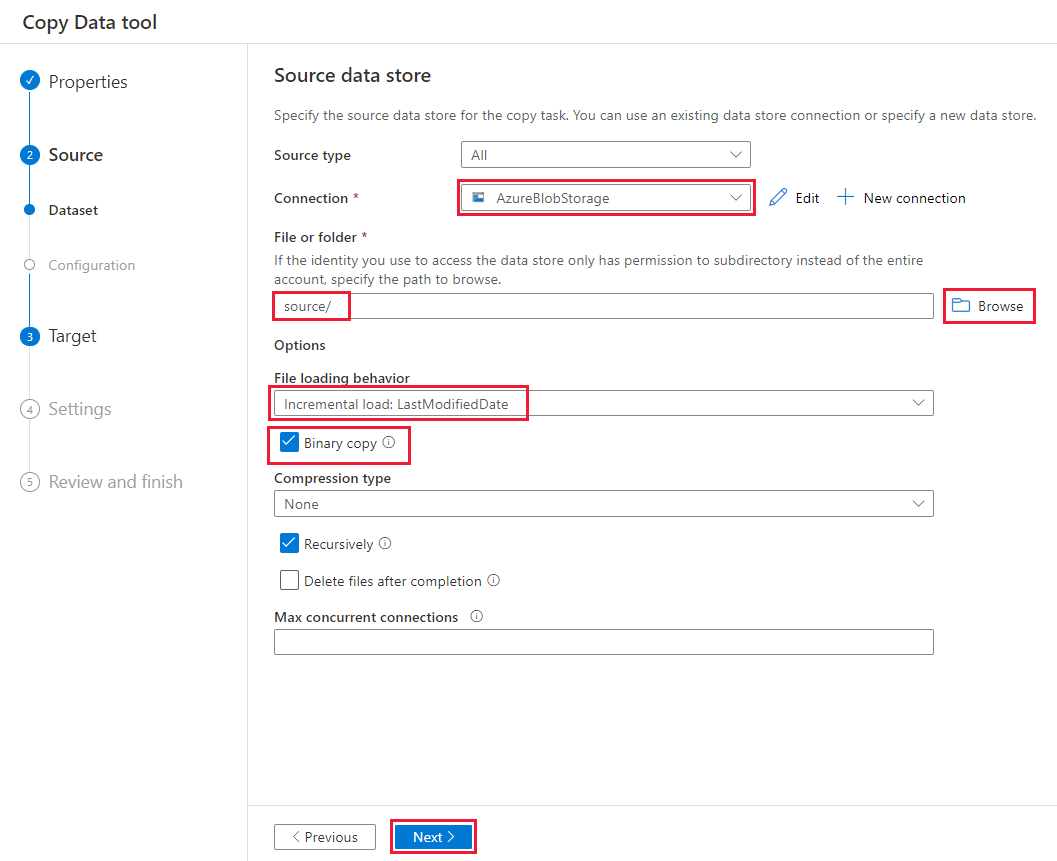
在“源数据存储” 页上,完成以下步骤:
选择“+ 新建连接”添加一个连接。
从库中选择Azure Blob Storage,然后选择继续:

在新连接(Azure Blob Storage)页上,从 Azure 订阅列表中选择Azure订阅,并从 Storage 帐户名称列表中选择存储帐户。 测试连接,然后选择“创建” 。
在“连接”块中选择新建的连接。
在“文件或文件夹”部分中,选择“浏览”并选择源文件夹,然后选择“确定”。
在“文件加载行为”下,选择“增量加载:LastModifiedDate”,然后选择“二进制复制” 。
选择“下一步”。
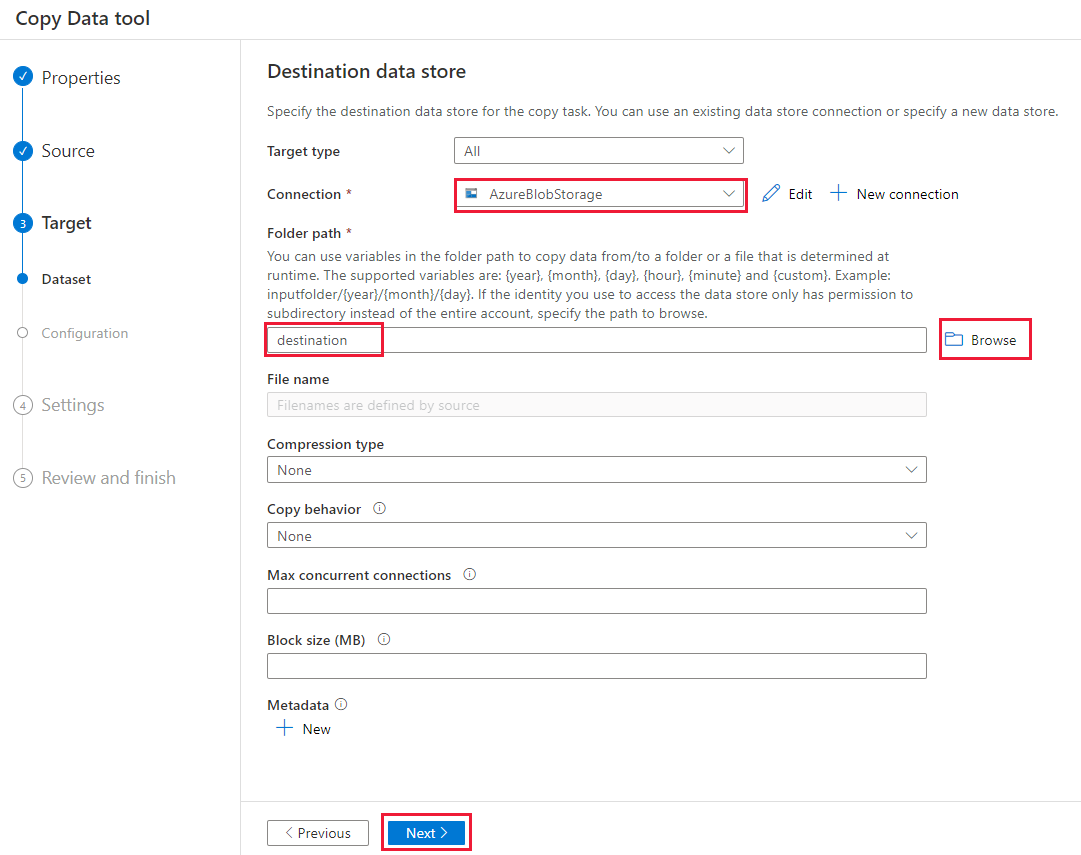
在“目标数据存储”页上,完成以下步骤:
选择已创建的“AzureBlobStorage”连接。 这是与源数据存储相同的存储帐户。
在“文件夹路径”部分中,浏览并选择目标文件夹,然后选择“确定”。
选择“下一步”。
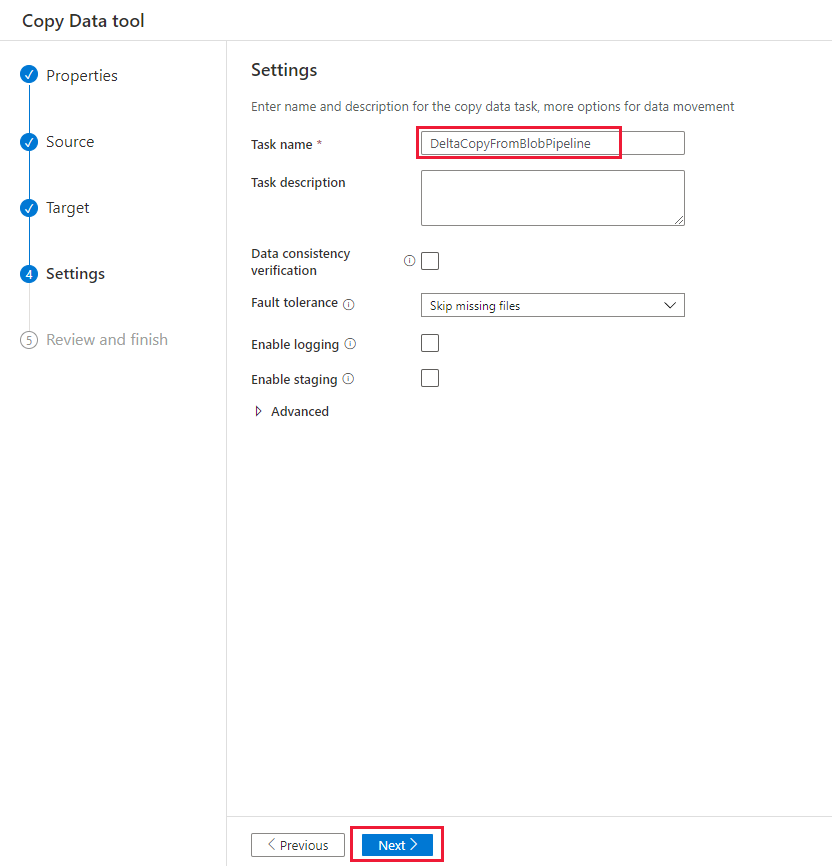
在“设置”页上的“任务名称”下,输入 DeltaCopyFromBlobPipeline,然后选择“下一步”。 数据工厂会使用指定的任务名称创建一个管道。
在“摘要” 页上检查设置,然后选择“下一步” 。
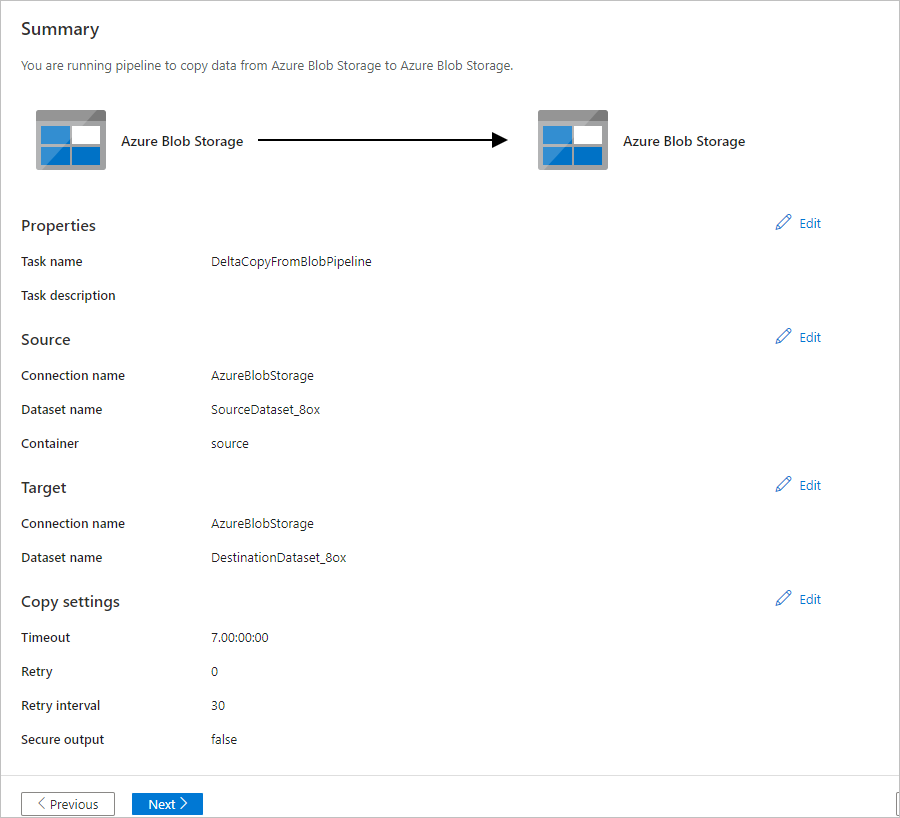
在“部署”页中,选择“监控”以监控管道(任务)。
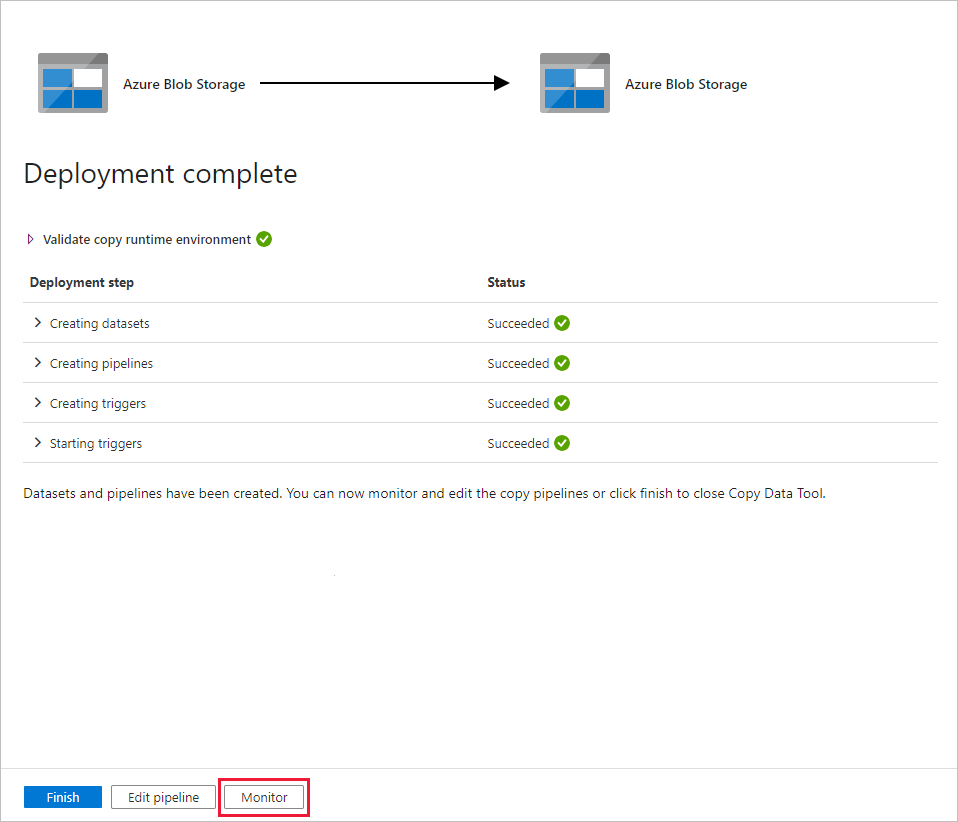
请注意,界面中已自动选择左侧的“监视”选项卡。 应用程序将切换到“监视”选项卡。 请查看管道的状态。 选择“刷新”可刷新列表。 选择“管道名称”下的链接,查看活动运行详细信息或重新运行管道。
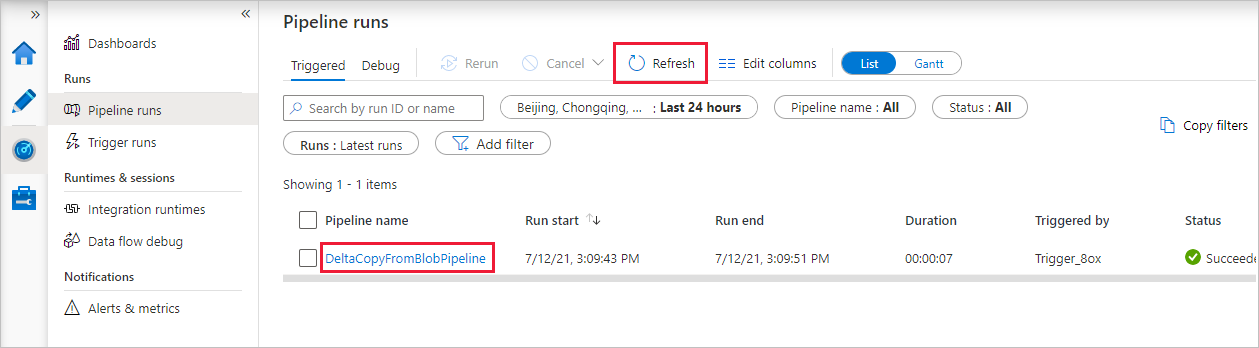
该管道只包含一个活动(复制活动),因此只显示了一个条目。 要了解有关复制操作的详细信息,请在“活动运行”页上,选择“活动名称”列下的“详细信息”链接(眼镜图标)。 有关属性的详细信息,请参阅 Copy activity 概述。
管道中的
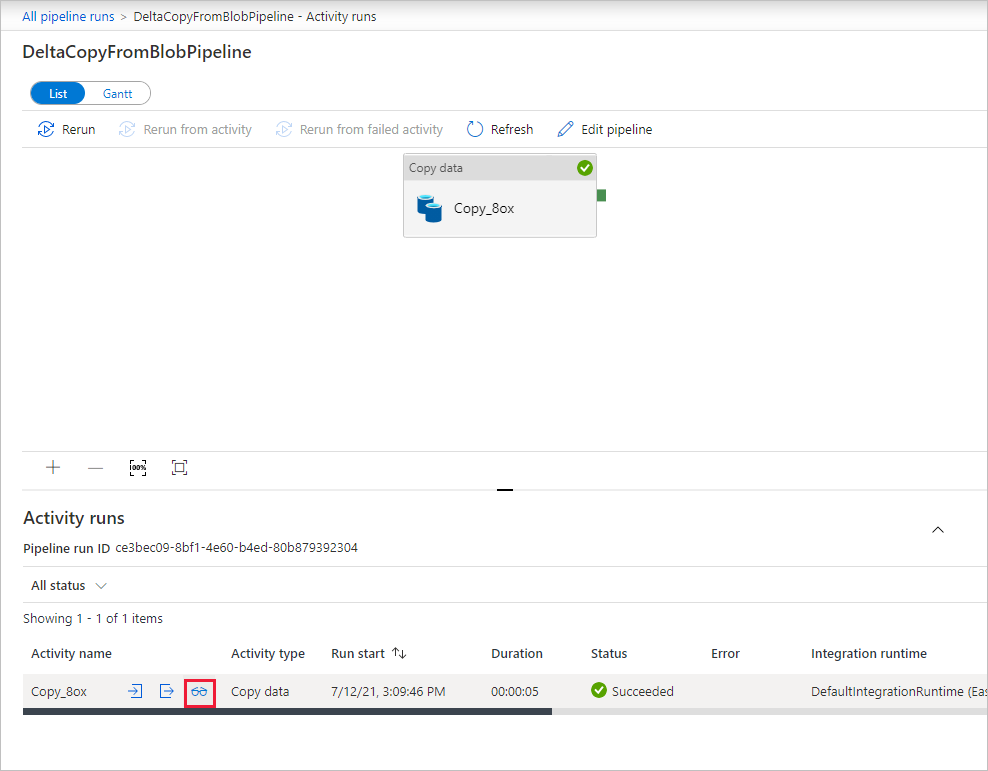
由于 Blob 存储帐户的源容器中没有文件,因此不会看到任何文件复制到该帐户的目标容器中:
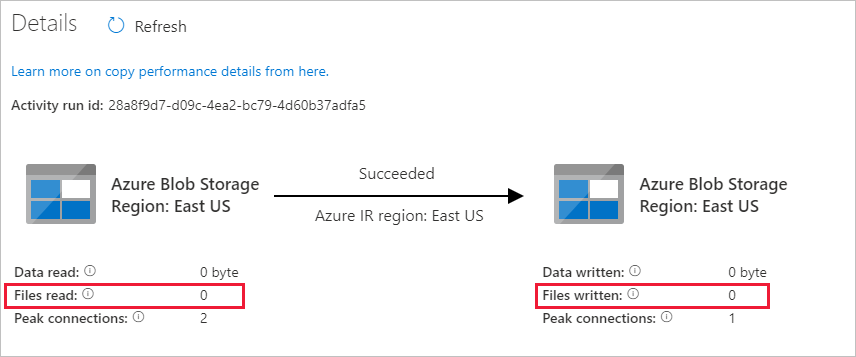
创建空的文本文件,并将其命名为 file1.txt。 将此文本文件上传到存储帐户中的源容器。 可以使用各种工具来执行这些任务,例如 Azure Storage Explorer。
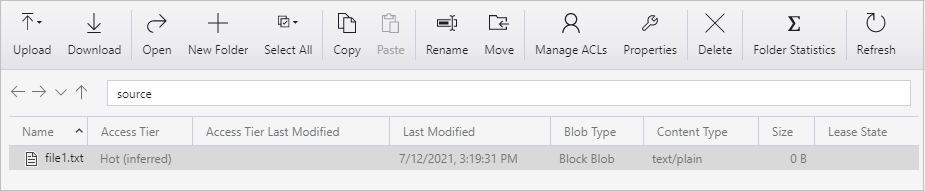
要返回“管道运行”视图,请在“活动运行”页的痕迹菜单中选择“所有管道运行”链接,然后等待同一管道再次自动触发。
当第二个管道运行完成时,请按照前述步骤查看活动运行详情。
你会发现,已将一个文件 (file1.txt) 从 Blob 存储帐户的源容器复制到目标容器。
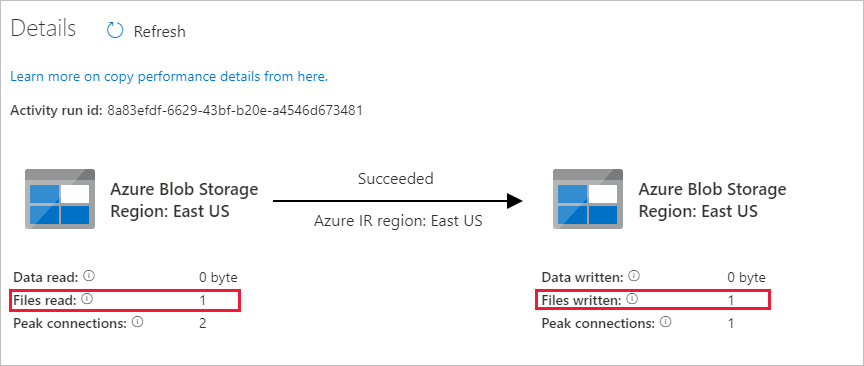
创建另一个空的文本文件,并将其命名为 file2.txt。 将此文本文件上传到 Blob 存储帐户中的源容器。
针对第二个文本文件重复步骤 11 和 12。 你会发现,在执行此管道运行期间,只有新文件 (file2.txt) 从存储帐户中的源容器复制到了目标容器中。
您还可以使用 Azure Storage Explorer 扫描文件,以验证是否只复制了一个文件。
扫描文件 使用 Azure Storage Explorer
相关内容
转到以下教程,了解如何在 Azure 上使用 Apache Spark 群集转换数据: