重要
此功能在 Beta 版中。 工作区管理员可以从 预览 页控制对此功能的访问。 请参阅 管理 Azure Databricks 预览版。
通过生产监视,可以在 GenAI 应用的跟踪上自动运行 MLflow 3 记分器,以持续评估质量。 为一个 MLflow 实验安排评分器,监控服务会评估传入的跟踪数据的可配置样本。 结果作为评估反馈附加到每个跟踪记录。
生产监视包括以下内容:
- 使用内置或自定义评分器进行自动化质量评估,包括用于评估整个对话的多 轮次评委 。
- 可配置的采样率,以便控制覆盖率与计算成本之间的权衡。
- 在开发和生产中使用相同的评分器来确保一致的评估。
- 持续质量评估,后台运行监控。
注释
MLflow 3 生产监控与来自 MLflow 2 的跟踪记录兼容。
先决条件
在设置生产监视之前,请确保具备:
- MLflow 试验:记录跟踪的 MLflow 试验。 如果未指定试验,则使用活动试验。
- 检测化生产应用程序:GenAI 应用必须使用 MLflow 跟踪记录跟踪。 请参阅 生产跟踪指南。
-
定义的记分器:已测试过可与您的应用程序跟踪格式一同使用的记分器。 如果你在开发过程中将生产应用用作
predict_fn中的mlflow.genai.evaluate(),那么你的评分器可能已经兼容。 - SQL 仓库 ID(适用于 Unity Catalog 跟踪):如果跟踪存储在 Unity Catalog 中,则必须配置 SQL 仓库 ID,以使监控功能正常工作。
开始
若要设置生产监视,请在 MLflow 试验中注册记分器,然后使用采样配置启动它。 这两步模式(.register() 然后 .start())适用于所有记分器类型。
注释
在任何给定时间,最多 20 名评分者都可以与持续质量监视的实验相关联。
有关记分器的详细信息,请参阅以下内容:
以下部分介绍如何使用不同类型的法官以及如何组合它们。 展开部分以了解更多。
使用 UI 创建和安排 LLM 法官
使用 UI 创建和安排 LLM 裁判
可以使用 MLflow 试验 UI 来创建和测试基于 LLM 法官的评分器。
创建新的 LLM 法官:
导航到 MLflow 试验 UI 中的 “法官 ”选项卡。
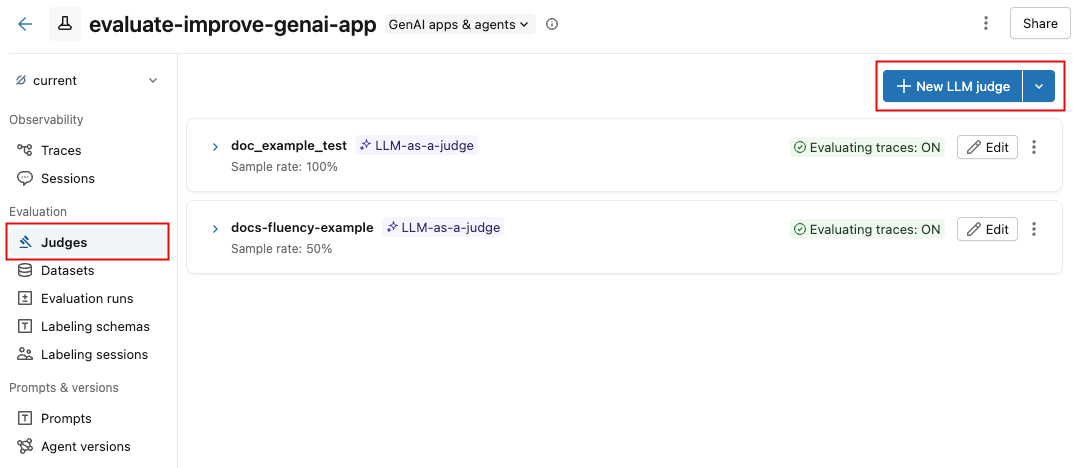
单击 “新建 LLM 法官”。
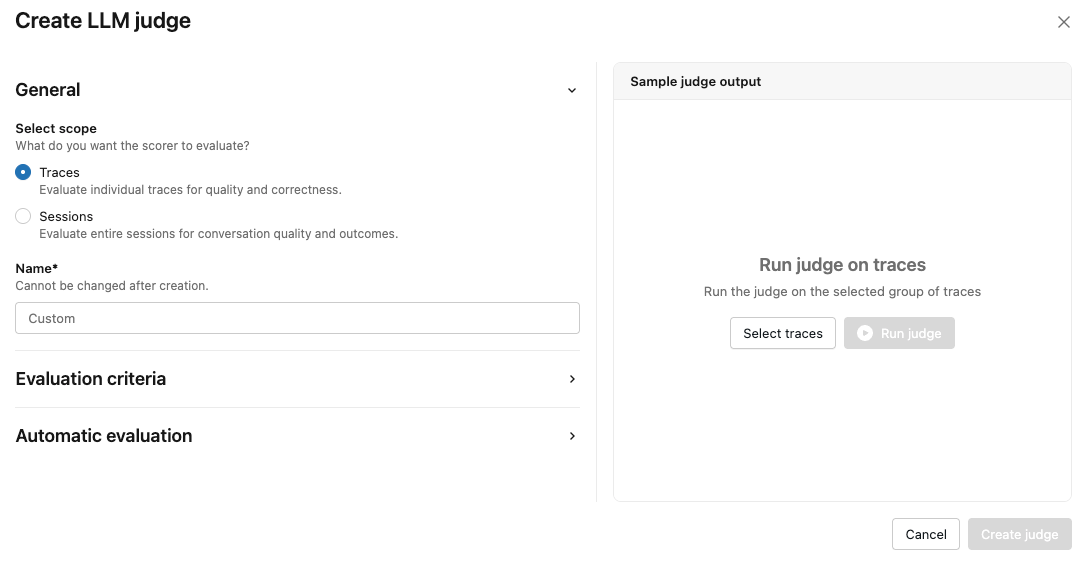
通过选择 “跟踪 ”或“ 会话”来指定评分器将评估的内容。
输入法官的姓名。
单击显示的箭头以显示 “评估条件 ”部分。
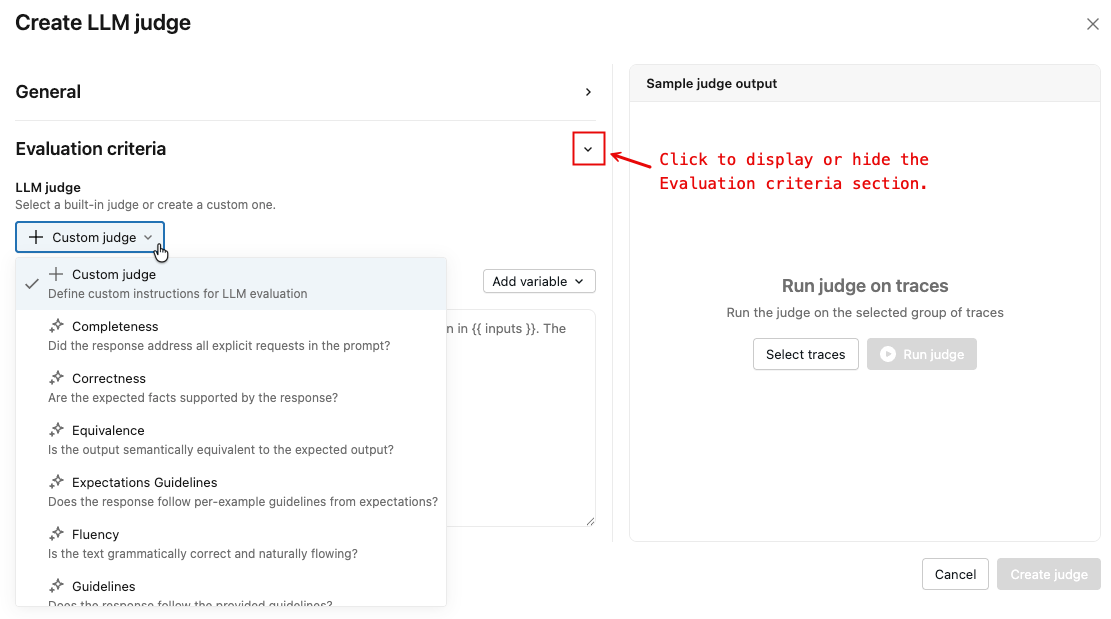
从下拉菜单中,选择法官的类型。 某些判断类型允许输入自定义说明,包括变量。
单击显示的箭头以显示 “自动评估 ”部分。
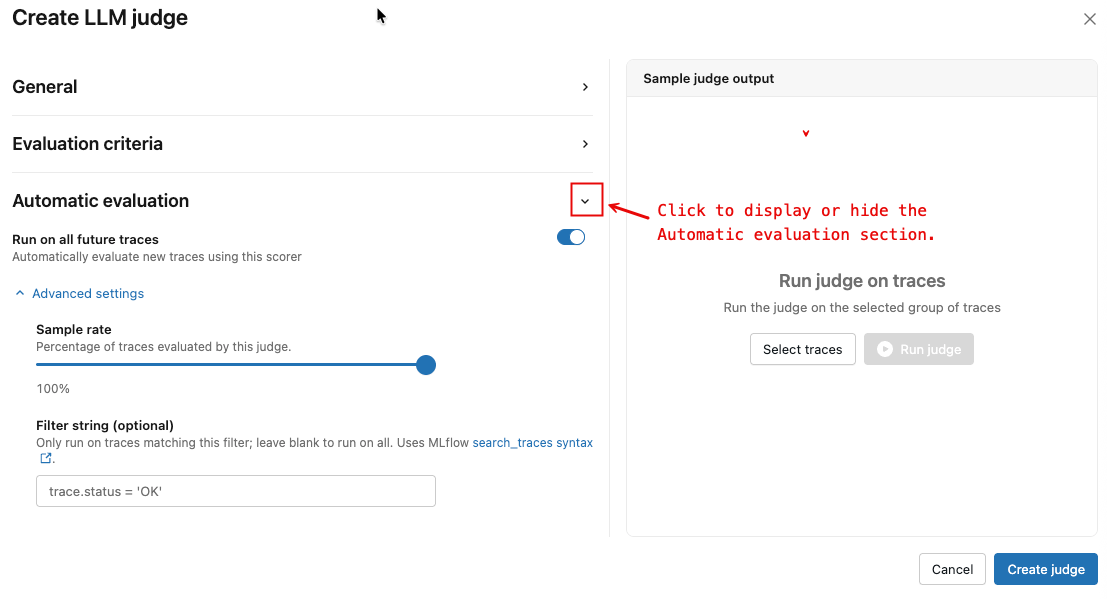
根据需要切换“在所有将来的跟踪上运行”按钮。
(可选)在 “高级设置”下,调整 采样率 和 筛选器字符串 以控制评估哪些跟踪。
(可选)若要测试一组现有跟踪的新判断,
- 在左侧窗格中单击选择跟踪。 弹出窗口出现。
- 选择要运行的跟踪,然后单击“选择”(n)。
- 单击" 运行评测器"。 跟踪已被评估并显示结果。
- 查看结果。 使用 “下一步” 和 “上一步” 按钮逐步浏览每个所选跟踪的结果。
- 如有必要,编辑评估并反复调整,直到你对评估的表现感到满意。
若要创建法官,请单击“ 创建法官”。
不能使用 UI 创建自定义代码评判。 若要查看可复制到笔记本并根据需要进行编辑的模板代码,请执行以下操作:
单击 “新建 LLM 法官 ”按钮旁边的下拉箭头,然后选择 “自定义代码法官”。
此时会显示一个弹出窗口,其中包含说明和模板代码,显示如何定义和运行自定义代码判断。
使用内置的 LLM 法官
使用内置的 LLM 评估器
MLflow 提供了多个内置的 LLM 评估工具,你可以直接使用这些即用型工具。
from mlflow.genai.scorers import Safety, ScorerSamplingConfig
# Register the scorer with a name and start monitoring
safety_judge = Safety().register(name="my_safety_judge") # name must be unique to experiment
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
默认情况下,每个法官都使用 Databricks 托管的 LLM 来执行 GenAI 质量评估。 可以使用记分器定义中的参数,将评判模型更改为使用 model 的 Databricks 模型服务端点。 必须以格式 databricks:/<databricks-serving-endpoint-name>指定模型。
safety_judge = Safety(model="databricks:/databricks-gpt-oss-20b").register(name="my_custom_safety_judge")
使用指南 LLM 法官
使用指南 LLM 法官
指导LLM 法官 使用通过/未通过的自然语言标准来评估输入和输出。
from mlflow.genai.scorers import Guidelines
# Create and register the guidelines scorer
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"]
).register(name="is_english") # name must be unique to experiment
# Start monitoring with the specified sample rate
english_judge = english_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.7))
与内置法官一样,可以更改判断模型以改用 Databricks 模型服务终结点。
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"],
model="databricks:/databricks-gpt-oss-20b",
).register(name="custom_is_english")
在自定义提示中使用 LLM 法官
在自定义提示中使用 LLM 法官
对于比准则评委更大的灵活性,请使用 LLM 法官和自定义提示 ,从而允许使用可自定义的选择类别进行多级质量评估。
from typing import Literal
from mlflow.genai import make_judge
from mlflow.genai.scorers import ScorerSamplingConfig
# Create a custom judge using make_judge
formality_judge = make_judge(
name="formality",
instructions="""You will look at the response and determine the formality of the response.
Request: {{ inputs }}
Response: {{ outputs }}
Evaluate whether the response is formal, somewhat formal, or not formal.
A response is somewhat formal if it mentions friendship, etc.""",
feedback_value_type=Literal["formal", "semi_formal", "not_formal"],
model="databricks:/databricks-gpt-oss-20b", # optional
)
# Register the custom judge and start monitoring
registered_judge = formality_judge.register(name="my_formality_judge") # name must be unique to experiment
registered_judge = registered_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.1))
使用自定义记分器函数
使用自定义记分器函数
为了获得最大的灵活性,请定义和使用 自定义记分器函数。
:::重要的生产监视自定义记分器要求
- 仅
@scorer支持基于修饰器的评分器。 无法注册基于Scorer类的子类进行生产监视。 如果需要基于类的评分器,请重构它以改用@scorer修饰器。 - 必须在 Databricks 笔记本中定义和注册评分器。 监视服务序列化用于远程执行的记分器函数代码,并且此序列化需要笔记本环境。 无法在独立 Python 文件或本地 IDE 环境中定义的记分器进行序列化,以便进行生产监视。
- 记分器必须是自给自足的。 由于记分器函数序列化为用于远程执行的代码,因此必须在函数体内内完成所有导入。 该函数不能引用其外部定义的变量、对象或模块。
:::
定义自定义记分器时,请勿使用需要在函数签名中导入的类型提示。 如果记分器函数正文使用需要导入的包,请将这些包内联导入函数,以确保正确序列化。
某些软件包默认可用,无需进行内联导入操作。 这些包包括databricks-agents、mlflow-skinny和openai无服务器环境版本 2 中包含的所有包。
from mlflow.genai.scorers import scorer, ScorerSamplingConfig
# Custom metric: Check if response mentions Databricks
@scorer
def mentions_databricks(outputs):
"""Check if the response mentions Databricks"""
return "databricks" in str(outputs.get("response", "")).lower()
# Register and start monitoring
databricks_scorer = mentions_databricks.register(name="databricks_mentions")
databricks_scorer = databricks_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
有关更多自定义记分器示例,请参阅 基于代码的评分器。
使用多轮次评判器
使用多轮评审法官
生产监视支持 多轮次评委 来评估整个对话,而不是单个跟踪。 这些评判者会评估多个互动的质量标准,例如用户的沮丧和对话的完整性。 多轮判决法官的注册和启动方式与单轮判决法官相同。
监视作业自动根据mlflow.trace.session标签将跟踪分组到对话中。 多轮对话评审在会话被认为完成后进行——默认情况下,当没有新的包含该会话 ID 的轨迹被摄入超过5 分钟时,会话将被视为完成。 若要配置此缓冲区,请在 MLFLOW_ONLINE_SCORING_DEFAULT_SESSION_COMPLETION_BUFFER_SECONDS 监视作业上设置环境变量。
关于可用的多轮对话判定器的完整列表,请参阅多轮对话判定器。 有关对话评估的详细信息,请参阅 “评估对话”。
注释
若要使用多轮次法官,代理必须在追踪记录上设置会话 ID。 有关详细信息 ,请参阅“跟踪用户和会话 ”。
from mlflow.genai.scorers import (
ConversationCompleteness,
UserFrustration,
ScorerSamplingConfig,
)
# Register and start multi-turn judges just like single-turn judges
completeness_scorer = ConversationCompleteness().register(name="conversation_completeness")
completeness_scorer = completeness_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
frustration_scorer = UserFrustration().register(name="user_frustration")
frustration_scorer = frustration_scorer.start(
sampling_config=ScorerSamplingConfig(sample_rate=1.0),
)
合并法官
合并法官
可以在同一实验中组合单回合评判和多回合评判。 逐一注册并启动每个记分器。
from mlflow.genai.scorers import Safety, Guidelines, UserFrustration, ScorerSamplingConfig
# Single-turn judges
safety_judge = Safety().register(name="safety")
safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0))
english_judge = Guidelines(
name="english",
guidelines=["The response must be in English"]
).register(name="is_english")
english_judge = english_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.5))
# Multi-turn judge
frustration_judge = UserFrustration().register(name="frustration")
frustration_judge = frustration_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=0.3))
查看结果
计划记分器后,允许 15-20 分钟进行初始处理。 然后:
- 进入您的 MLflow 实验。
- 打开 Traces 选项卡,查看附加到追踪的评估。
- 使用监视仪表板跟踪质量趋势。
对于多轮对话评审,评估会附在每个会话中的第一个轨迹上。 有关详细信息 ,请参阅评估的存储方式 。
最佳做法
采样策略
对于安全性和安保检查等关键评分标准,请使用
sample_rate=1.0。对于昂贵的评分系统,例如复杂的 LLM 模型,应使用较低的采样率(0.05-0.2)。
若要在开发期间进行迭代改进,请使用中等速率(0.3-0.5)。
平衡覆盖范围与成本,如以下示例所示:
# High-priority scorers: higher sampling safety_judge = Safety().register(name="safety") safety_judge = safety_judge.start(sampling_config=ScorerSamplingConfig(sample_rate=1.0)) # 100% coverage for critical safety # Expensive scorers: lower sampling complex_scorer = ComplexCustomScorer().register(name="complex_analysis") complex_scorer = complex_scorer.start(sampling_config=ScorerSamplingConfig(sample_rate=0.05)) # 5% for expensive operations
筛选跟踪
在filter_string中使用ScorerSamplingConfig参数以控制评分器评估哪些跟踪。 此使用与mlflow.search_traces()相同的筛选器语法。
from mlflow.genai.scorers import Safety, ScorerSamplingConfig
# Only evaluate traces that completed successfully
safety_judge = Safety().register(name="safety")
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(
sample_rate=1.0,
filter_string="attributes.status = 'OK'"
),
)
可以组合多个条件:
import time
# Evaluate successful traces from the last 24 hours
one_day_ago = int((time.time() - 86400) * 1000)
safety_judge = safety_judge.start(
sampling_config=ScorerSamplingConfig(
sample_rate=0.5,
filter_string=f"attributes.status = 'OK' AND attributes.timestamp_ms > {one_day_ago}"
),
)
自定义记分器设计
使自定义评分器保持独立,如以下示例所示:
@scorer
def well_designed_scorer(inputs, outputs):
# All imports inside the function
import re
import json
# Handle missing data gracefully
response = outputs.get("response", "")
if not response:
return 0.0
# Return consistent types
return float(len(response) > 100)
Troubleshooting
记分器未运行
如果评分人员没有执行任务,请检查以下内容:
- 检查实验:确保将日志记录到实验,而不是记录到单个运行。
- 采样率:采样率较低,可能需要时间才能查看结果。
-
验证筛选器字符串:确保
filter_string匹配实际跟踪信息。
序列化问题
用于生产监视的自定义记分器已序列化,以便监视服务远程执行这些评分器。 这会施加多个约束:
-
笔记本要求:必须从 Databricks 笔记本定义和注册自定义
@scorer函数。 序列化机制依赖于笔记本环境。 - 自包含函数:所有导入都必须在函数体内内内联。 在序列化期间不会捕获对在函数外部定义的外部变量、模块或对象的引用。
-
没有基于类的评分器:只能注册
@scorer基于修饰器的评分器。 无法序列化基于Scorer类的子类以便进行远程执行。 -
不需要导入的类型提示:函数签名中的类型提示如果需要导入语句(例如,从
List导入typing),会导致序列化失败。
创建自定义评分器时,在函数定义中包含导入。
# Avoid external dependencies
import external_library # Outside function
@scorer
def bad_scorer(outputs):
return external_library.process(outputs)
# Include imports in the function definition
@scorer
def good_scorer(outputs):
import json # Inside function
return len(json.dumps(outputs))
# Avoid using type hints in scorer function signature that requires imports
from typing import List
@scorer
def scorer_with_bad_types(outputs: List[str]):
return False
# Class-based scorers are not supported for production monitoring
class MyScorer(Scorer):
name: str = "my_scorer"
def __call__(self, outputs):
return len(outputs) > 10
后续步骤
- 基于代码的评分器 - 生成根据需求定制的评分器。
- 评估对话 - 了解多轮次对话评估和多轮次评委。
- 生成 MLflow 评估数据集 - 使用监视结果提高质量。
参考指南
- 记分器生命周期管理 API 参考 - 记分器生命周期管理的 API 参考。
- 记分器和 LLM 评委 - 了解电源监视的指标。
- 在开发过程中评估 GenAI - 脱机评估与生产的关系。