传统软件和 ML 测试不是为 GenAI 自由格式语言构建的,因此团队难以衡量和提高质量。
MLflow 通过将 能够可靠测量生成式AI质量的AI驱动指标与全面的跟踪可观测性相结合来解决这一问题,使您能够在整个应用生命周期中监测、提升和监督质量。
MLflow 如何帮助衡量和提高 GenAI 应用和代理的质量
MLflow 可帮助你协调持续改进周期,其中包含用户反馈和域专家判断。 从开发到生产,可以使用经过优化以符合人类专业知识的一致质量指标(评分器),确保自动化评估反映实际质量标准。
持续改进周期
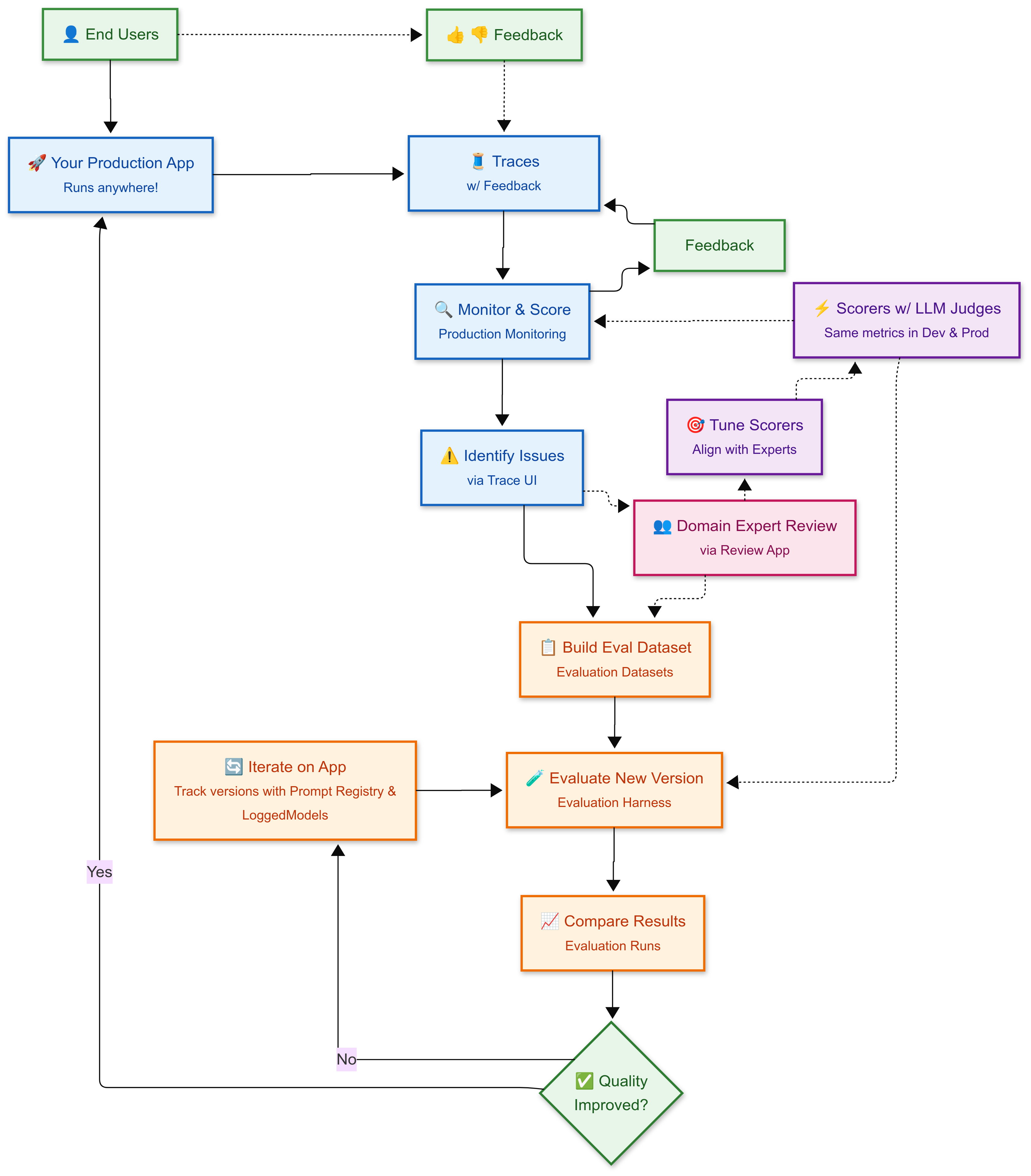
🚀 生产应用:你部署的 GenAI 应用为用户提供服务,生成详细的执行跟踪,记录每个交互的所有步骤、输入和输出。
👍 👎 用户反馈:终端用户提供附加在每个跟踪上的反馈(点赞/点踩、评分),帮助识别质量问题
⚠️ 识别问题:使用 跟踪 UI 通过最终用户和 LLM 评估反馈查找低评分跟踪中的模式
👥 域专家评审:(可选)通过 评审应用 向域专家发送跟踪示例,以便进行详细的标记和质量评估
📋 构建 Eval 数据集:将有问题的跟踪和高质量的跟踪整理到 评估数据集中 ,以便在修复问题的同时保留优质内容
🎯 调整评分系统:(可选)使用专家反馈,将评分系统和评委与人类判断保持一致,确保自动评分系统代表人工判断。
🧪 评估新版本:使用 评估框架 对改进的应用版本进行测试,并应用相同的监控评分标准,以评估质量是否有所提高或下降。 (可选)使用 版本 和 提示 管理来跟踪工作。
📈 比较结果:您可以使用评估工具生成的 评估运行 来跨版本进行比较,从而识别性能最佳的版本。
✅ 部署或迭代:如果质量在没有回归的情况下提高,则部署;否则,迭代并重新评估
为什么此方法有效
- 人工对齐指标: 评分器 经过优化以匹配领域专家判断,确保自动评估反映人类质量标准
- 一致的指标:相同的评分器在开发和生产中都工作
- 实际数据:生产跟踪成为测试用例,确保解决实际用户问题
- 系统验证:在部署之前针对回归数据集测试每个更改
- 持续学习:每个周期都改进了应用和评估数据集
后续步骤
按照 快速入门指南 设置跟踪、运行第一次评估,并从域专家那里收集反馈。
对从跟踪到评估数据集再到评分器的关键抽象进行概念理解,以支持 MLflow 的运作。