本文提供有关如何运行 Azure HDInsight 的一些最常见问题的解答。
创建或删除 HDInsight 群集
如何预配 HDInsight 群集?
若要查看 HDInsight 群集类型和预配方法,请参阅使用 Apache Hadoop、Apache Spark、Apache Kafka 及其他组件在 HDInsight 中设置群集。
如何删除现有的 HDInsight 群集?
若要详细了解如何删除不再使用的群集,请参阅删除 HDInsight 群集。
尝试在创建群集后,至少等 30 到 60 分钟再删除群集。 否则,操作可能会失败并出现以下错误消息:
Conflict (HTTP Status Code: 409) error when attempting to delete a cluster immediately after creation of a cluster. If you encounter this error, wait until the newly created cluster is in operational state before attempting to delete it.
如何为工作负荷选择适当的核心数或节点数?
适当的核心数和其他配置选项取决于多种因素。
有关详细信息,请参阅 HDInsight 群集的容量规划。
HDInsight 群集中有哪些不同类型的节点?
创建大型 HDInsight 群集的最佳做法有哪些?
- 建议使用自定义 Ambari DB 设置 HDInsight 群集,以提高群集的可伸缩性。
- 使用 Azure Data Lake Storage Gen2 创建 HDInsight 群集,以利用更高的带宽和 Azure Data Lake Storage Gen2 的其他性能特点。
- 头节点应该足够大,能够容纳在这些节点上运行的多个主服务。
- 某些特定工作负载(如 Interactive Query)也需要更大的 Zookeeper 节点。 请考虑至少使用 8 核心 VM。
- 对于 Hive 和 Spark,请使用外部 Hive 元存储。
单个组件
是否可以在群集上安装更多组件?
是的。 若要安装更多组件或自定义群集配置,请使用:
在创建期间或之后使用脚本。 脚本可通过脚本操作调用。 脚本操作是一种配置选项,可通过 Azure 门户、HDInsight Windows PowerShell cmdlet 或 HDInsight .NET SDK 使用。 可通过 Azure 门户、HDInsight Windows PowerShell cmdlet 或 HDInsight .NET SDK 使用此配置选项。
使用 HDInsight 应用程序平台安装应用程序。
请参阅在 HDInsight 中可以使用哪些 Apache Hadoop 组件和版本?,了解受支持组件的列表
是否可以升级预装在群集上的单个组件?
如果升级内置组件或预安装在群集上的应用程序,Microsoft Azure 将不支持生成的配置。 Microsoft 尚未测试这些系统配置。 请尝试使用不同版本的 HDInsight 群集,该版本可能已预装了组件的升级版本。
例如,不支持将 Hive 作为单个组件进行升级。 HDInsight 是一个托管服务;许多服务已与 Ambari 服务器集成并已经过测试。 单独升级 Hive 会导致其他组件的已编制索引的二进制文件发生更改,并会导致群集上出现组件集成问题。
Spark 和 Kafka 是否可在同一 HDInsight 群集上运行?
否,无法在同一 HDInsight 群集上运行 Apache Kafka 和 Apache Spark。 单独为 Kafka 和 Spark 创建群集可避免资源争用问题。
如何更改 Ambari 中的时区?
通过
https://CLUSTERNAME.azurehdinsight.cn(其中,CLUSTERNAME 是群集的名称)打开 Ambari Web UI。在右上角选择“管理”|“设置”。
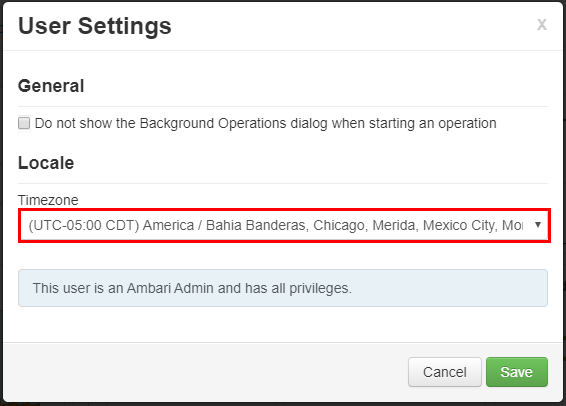
在“用户设置”窗口中,从“时区”下拉列表中选择新的时区,然后选择“保存”。
元存储
如何从现有的元存储迁移到 Azure SQL 数据库?
要从 SQL Server 迁移到 Azure SQL 数据库,请参阅教程:使用 DMS 将 SQL Server 脱机迁移到 Azure SQL 数据库中的单一数据库或共用数据库。
删除群集时是否会删除 Hive 元存储?
这取决于群集配置为使用的元存储类型。
对于默认元存储:默认元存储是群集生命周期的一部分。 删除群集时,也会删除相应的该元存储和元数据。
对于自定义元存储:元存储的生命周期与群集的生命周期无关。 因此,可以在不丢失元数据的情况下创建和删除群集。 即使在删除和重新创建 HDInsight 群集之后,系统也仍会保留 Hive 架构等元数据。
有关详细信息,请参阅在 Azure HDInsight 中使用外部元数据存储。
迁移 Hive 元存储是否也会迁移 Ranger 数据库的默认策略?
否,策略定义位于 Ranger 数据库中,因此,迁移 Ranger 数据库会迁移其策略。
是否可以将 Hive 元存储从企业安全性套餐 (ESP) 群集迁移到非 ESP 群集,且反之亦然?
是,可以将 Hive 元存储从 ESP 群集迁移到非 ESP 群集。
如何估算 Hive 元存储数据库的大小?
Hive 元存储用于存储 Hive 服务器所用数据源的元数据。 其大小要求一定程度上取决于 Hive 数据源的数量和复杂性。 这些项目无法预先估算。 如 Hive 元存储指南中所述,你可以从 S2 层开始。 该层提供 50 DTU 和 250 GB 的存储;如果遇到瓶颈,请纵向扩展数据库。
是否支持使用除 Azure SQL 数据库以外的其他任何数据库作为外部元存储?
否,Microsoft Azure 仅支持使用 Azure SQL 数据库作为外部自定义元存储。
是否可在多个群集之间共享元存储?
是,可以在多个群集之间共享自定义元存储,前提是这些群集使用相同的 HDInsight 版本。
连接和虚拟网络
在网络中阻止端口 22 和 23 会造成什么影响?
如果阻止端口 22 和端口 23,则无法通过 SSH 访问群集。 HDInsight 服务不使用这些端口。
有关详细信息,请参阅以下文档:
是否可以在 HDInsight 群集所在的同一子网中部署更多虚拟机?
是,可以在 HDInsight 群集所在的同一子网中部署更多虚拟机。 可使用以下配置:
边缘节点:可根据在 HDInsight 中的 Apache Hadoop 群集上使用空边缘节点中所述,将另一个边缘节点添加到群集。
独立节点:你可以将一个独立的虚拟机添加到同一个子网,并通过使用专用终结点
https://<CLUSTERNAME>-int.azurehdinsight.cn从该虚拟机访问群集。 有关详细信息,请参阅控制网络流量。
是否应该将数据存储在边缘节点的本地磁盘上?
否,将数据存储在本地磁盘上不是一个好主意。 如果节点出现故障,本地存储的所有数据都将丢失。 我们建议将数据存储在 Azure Data Lake Storage Gen2 或 Azure Blob 存储中,或者通过装载 Azure 文件共享来存储数据。
是否可将现有的 HDInsight 群集添加到另一个虚拟网络?
不可以。 应在预配时指定虚拟网络。 如果在预配期间未指定任何虚拟网络,则部署过程将会创建一个无法从外部访问的内部网络。 有关详细信息,请参阅将 HDInsight 添加到现有的虚拟网络。
安全性和证书
对于 Azure HDInsight 群集上的恶意软件防护,你们有什么建议?
有关恶意软件防护的详细信息,请参阅适用于 Azure 云服务和虚拟机的 Microsoft Antimalware。
如何为 HDInsight ESP 群集创建密钥表?
为域用户名创建 Kerberos keytab。 以后可以使用此 keytab 对已加入远程域的群集进行身份验证,而无需输入密码。 域名采用大写:
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
创建密钥表时,AES256 加密何时需要加盐?
如果你的 TenantName 和 DomainName 不同(例如 TenantName - bob@CONTOSO.ONMICROSOFT.COM 和 DomainName - bob@CONTOSOMicrosoft.ONMICROSOFT.COM),则需要使用 -s 选项添加 SALT 值。
如何确定正确的 SALT 值?
- 使用交互式 Kerberos 登录确定密钥表的正确盐值。 交互式 Kerberos 登录默认使用最高加密。 应启用跟踪以观察盐。 下面是 Kerberos 登录示例:
$ KRB5_TRAACE=/dev/stdout kinit <username> -V
- 查看盐 "......." 行的输出。
- 创建密钥表时使用此盐值。
ktutil
ktutil: addent -password -p <username>@<DOMAIN.COM> -k 1 -e aes256-cts-hmac-sha1-96 -s <SALTvalue>
Password for <username>@<DOMAIN.COM>: <password>
ktutil: wkt <username>.keytab
ktutil: q
是否可以使用现有的 Microsoft Entra 租户创建具有 ESP 的 HDInsight 群集?
必须先启用 Microsoft Entra 域服务,然后才能创建具有 ESP 的 HDInsight 群集。 开源 Hadoop 依赖于使用 Kerberos 进行身份验证(与 OAuth 不同)。
若要将 VM 加入域,必须有一个域控制器。 Microsoft Entra 域服务是托管域控制器,被视为 Microsoft Entra ID 的扩展。 Microsoft Entra 域服务提供以托管方式生成安全 Hadoop 群集所需满足的所有 Kerberos 要求。 用作托管服务的 HDInsight 可与 Microsoft Entra 域服务集成来提供安全性。
是否可在 Microsoft Entra 域服务安全 LDAP 设置中使用自签名证书并预配 ESP 群集?
建议使用证书颁发机构颁发的证书。 但在 ESP 上,也支持使用自签名证书。 有关详细信息,请参阅:
能否在 ESP 群集中安装 Data Analytics Studio (DAS)?
否,ESP 群集不支持 DAS。
如何拉取 Ranger 中显示的登录活动?
为满足审核要求,Azure 建议启用 Azure Monitor 日志。
是否可在群集上禁用 Clamscan?
Clamscan 是在 HDInsight 群集上运行的防病毒软件,Azure 安全性 (azsecd) 使用它来保护群集免受病毒攻击。 Microsoft Azure 强烈建议用户不要对默认的 Clamscan 配置进行任何更改。
此进程不会干扰其他进程,也不会中断其运行周期。 它始终屈从于其他进程。 仅当系统空闲时,才应显示 Clamscan 的 CPU 峰值。
如果必须控制计划,可使用以下步骤:
使用以下命令禁用自动执行:
sudo
usr/local/bin/azsecd config -s clamav -d Disabledsudo service azsecd restart添加一个 Cron 作业,以便以 root 身份运行以下命令:
/usr/local/bin/azsecd manual -s clamav
有关如何设置和运行 Cron 作业的详细信息,请参阅如何设置 Cron 作业?
为什么在 Spark ESP 群集上可使用 LLAP?
启用 LLAP 是出于安全(而非性能)原因 (Apache Ranger)。 使用较大的节点 VM 来适应 LLAP 的资源使用(例如最低 D13V2)。
如何在创建 ESP 群集后添加其他 Microsoft Entra 组?
可通过两种方式实现此目的:1- 可以重新创建群集,并在创建群集时添加其他组。 如果你使用 Microsoft Entra 域服务中范围内的同步功能,请确保组 B 包含在范围内的同步中。
2- 将组作为之前用于创建 ESP 群集的组的嵌套子组进行添加。 例如,如果已使用组 A 创建了一个 ESP 群集,则稍后可将组 B 添加为 A 的嵌套子组,在大约一小时后,它将自动同步并在群集中可用。
存储
如何计算 HDInsight 群集的存储帐户和 Blob 容器的用量?
执行下列操作之一:
使用以下命令行查找 HDInsight 群集上的 /user/hive/.Trash/ 文件夹大小:
hdfs dfs -du -h /user/hive/.Trash/
如何设置 Blob 存储帐户的审核?
若要审核 Blob 存储帐户,请使用在 Azure 门户中监视存储帐户中的过程配置监视。 HDFS 审核日志仅提供本地 HDFS 文件系统 (hdfs://mycluster) 的审核信息。 此日志不包括针对远程存储执行的操作。
如何在 Blob 容器与 HDInsight 头节点之间传输文件?
在头节点上运行类似于以下 shell 脚本的脚本:
for i in cat filenames.txt
do
hadoop fs -get $i <local destination>
done
注意
文件 filenames.txt 包含 Blob 容器中的文件的绝对路径。
是否有任何适用于存储的 Ranger 插件?
目前,Blob 存储和 Azure Data Lake Storage Gen2 没有任何 Ranger 插件。 对于 ESP 群集,应使用 Azure Data Lake Storage。 至少可以使用 HDFS 工具在文件系统级别手动设置精细权限。 此外,在使用 Azure Data Lake Storage 时,ESP 群集将在群集级别使用 Microsoft Entra ID 执行某种文件系统访问控制。
可以使用 Azure 存储资源管理器将数据访问策略分配到用户的安全组。 有关详细信息,请参阅:
是否可以在不增大工作器节点的磁盘大小的情况下增大群集上的 HDFS 存储?
不是。 无法增大任何工作器节点的磁盘大小。 因此,增大磁盘大小的唯一方法是删除群集,然后使用更大的工作器 VM 重新创建群集。 请不要使用 HDFS 来存储任何 HDInsight 数据,因为删除群集时会删除这些数据。 请改为在 Azure 中存储数据。 纵向扩展群集也可以将更多的容量添加到 HDInsight 群集。
边缘节点
创建群集后是否可以添加边缘节点?
如何连接到边缘节点?
创建边缘节点后,可以在端口 22 上使用 SSH 连接到该节点。 可以在群集门户中找到边缘节点的名称。 名称通常以 -ed 结尾。
持久化脚本为何未在新建的边缘节点上自动运行?
持久化脚本用于自定义通过缩放操作添加到群集的新工作器节点。 持久化脚本不适用于边缘节点。
REST API
可使用哪些 REST API 调用从群集提取 Tez 查询视图?
可使用以下 REST 终结点来提取 JSON 格式的所需信息。 使用基本身份验证标头发出请求。
-
Tez Query View:https://< cluster name.azurehdinsight.cn/ws/v1/timeline/HIVE_QUERY_ID/> -
Tez Dag View:https://< cluster name.azurehdinsight.cn/ws/v1/timeline/TEZ_DAG_ID/>
如何以 Microsoft Entra 用户身份从 HDI 群集检索配置详细信息?
若要以 Microsoft Entra 用户身份协商正确的身份验证令牌,请使用以下格式浏览网关:
-
<cluster dnsname>https://.azurehdinsight.cn/api/v1/clusters/testclusterdem/stack_versions/1/repository_versions/1
如何使用 Ambari RESTful 监视 YARN 性能?
如果在同一虚拟网络或对等互连的虚拟网络中调用 Curl 命令,则该命令为:
curl -u <cluster login username> -sS -G
http://<headnodehost>:8080/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
如果从虚拟网络外部或者从非对等互连的虚拟网络调用该命令,则命令格式为:
对于非 ESP 群集:
curl -u <cluster login username> -sS -G https://<ClusterName>.azurehdinsight.cn/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu对于 ESP 群集:
curl -u <cluster login username>-sS -G https://<ClusterName>.azurehdinsight.cn/api/v1/clusters/<ClusterName>/services/YARN/components/NODEMANAGER?fields=metrics/cpu
注意
Curl 会提示你输入密码。 必须输入群集登录用户名的有效密码。
计费
部署一个 HDInsight 群集需要多少费用?
有关定价以及计费相关的常见问题解答的详细信息,请参阅 Azure HDInsight 定价页。
HDInsight 计费何时开始和停止?
HDInsight 群集计费在创建群集之后便会开始,删除群集后才会停止。 群集按分钟按比例计费。
如何取消订阅?
有关如何取消订阅的信息,请参阅取消 Azure 订阅。
对于标准预付费套餐订阅,取消订阅后会发生什么情况?
有关取消订阅后发生的情况的详细信息,请参阅取消订阅之后会发生什么情况?
蜂房
为何即使我运行的是 HDInsight 3.6 群集,Ambari UI 中显示的 Hive 版本也仍是 1.2.1000 而不是 2.1?
尽管 Ambari UI 中仅显示 1.2,但 HDInsight 3.6 同时包含 Hive 1.2 和 Hive 2.1。
当群集空闲特定的时间段后,是否可以动态终止群集的头节点?
无法对 HDInsight 群集执行此操作。 可以使用 Azure 数据工厂实现此类目的。
HDInsight 提供哪些合规性产品?
有关符合性信息,请参阅 Azure 信任中心。