在部署 HDInsight 群集之前,应确定需要的性能和规模,从而为所需的群集容量做好规划。 这种规划有助于优化可用性与成本。 部署之后,某些群集容量决策不可更改。 如果性能参数发生更改,可以拆除群集,然后重新创建,而不会丢失存储的数据。
容量规划期间要提出的重要问题包括:
- 应在哪个地理区域中部署群集?
- 需要多少存储?
- 应部署哪种群集类型?
- 群集节点应使用的虚拟机 (VM) 大小和类型是什么?
- 群集应包含多少个工作器节点?
选择Azure区域
Azure区域确定群集的物理预配位置。 为了将读写延迟最小化,群集应靠近数据所在的位置。
HDInsight 在许多Azure区域中可用。 若要查找最近的区域,请参阅各区域的产品可用性。
选择存储位置和大小
默认存储的位置
默认存储(Azure 存储帐户或Azure Data Lake Storage)必须与群集位于同一位置。 Azure 存储在所有位置都可用。 某些区域提供Data Lake Storage - 请参阅当前的 Data Lake Storage 可用性。
现有数据的位置
如果要使用现有的存储帐户或Data Lake Storage作为群集的默认存储,则必须在同一位置部署群集。
存储大小
在部署的群集上,可以附加其他Azure 存储帐户或访问其他Data Lake Storage。 所有存储帐户均必须与群集位于同一位置。 Data Lake Storage可能位于不同的位置,但距离很大可能会造成一些延迟。
Azure 存储有一些容量限制,而Data Lake Storage几乎不受限制。 群集可以访问不同存储帐户的组合。 典型示例包括:
- 当数据量可能会超过单个 Blob 存储容器的存储容量时。
- 当对 Blob 容器的访问速率可能会超过阈值,从而发生限制时。
- 想要将已上传到 Blob 容器的数据提供给群集使用时。
- 出于安全原因想要隔离存储的不同部分,或要简化管理时。
为提高性能,请对每个存储帐户仅使用一个容器。
选择群集类型
群集类型决定 HDInsight 群集被配置运行的工作负载。 类型包括 Apache Hadoop、Apache Kafka 或 Apache Spark。 有关可用群集类型的详细说明,请参阅 Azure HDInsight 简介。 每个群集类型具有一个特定的部署拓扑,该拓扑附带大小和节点数方面的要求。
选择 VM 大小和类型
每个群集类型具有一组节点类型,每个节点类型在 VM 大小和类型方面提供特定的选项。
若要确定应用程序的最佳群集大小,可以建立群集容量基准,并根据指示增加大小。 例如,可以使用模拟工作负载或“canary 查询”。 在不同大小的群集上运行模拟工作负载。 逐渐增加大小,直到达到预期性能。 可在其他生产查询之间定期插入 canary 查询,以显示群集是否有足够的资源。
如果要详细了解如何为工作负载选择正确的 VM 系列,请参阅为群集选择适当的 VM 大小。
选择群集规模
群集的规模由其 VM 节点数量决定。 所有群集类型都存在一些具有特定缩放的节点类型,以及一些支持横向扩展的节点类型。例如,某个群集可能恰好需要三个 Apache ZooKeeper 节点或两个头节点。 以分布式方式进行数据处理的工作器节点受益于其他工作器节点。
增加工作器节点数会增加更多计算能力(例如更多核心),这具体取决于群集的类型。 更多节点将增加整个群集支持正在处理的数据的内存中存储所需的总内存。 就像选择 VM 大小和类型一样,适当的群集规模通常是凭经验选择出来的。 使用的是模拟工作负载或 canary 查询。
你可以横向扩展群集以满足峰值负载需求。 然后在不再需要这些额外的节点时,进行纵向缩减。 通过自动缩放功能,你可以根据预先确定的指标和时间安排自动缩放群集。 有关手动缩放群集的详细信息,请参阅缩放 HDInsight 群集。
群集生命周期
在群集的生存期内会产生费用。 如果您只在特定时间需要群集,可以使用 Azure 数据工厂 创建按需群集。 还可以创建用于预配和删除群集的 PowerShell 脚本,然后使用 Azure 自动化 计划这些脚本。
注释
删除某个群集时,也会一并删除其默认 Hive 元存储。 若要保留元存储以重新创建下一个群集,请使用外部元数据存储,例如 Azure Database 或 Apache Oozie。
查明群集作业错误
有时,多节点群集上多个映射和化简组件的并行执行可能导致出错。 若要帮助隔离此问题,请尝试分布式测试。 在单工作器节点群集上并发运行多个作业。 然后将这种方法扩展为在包含多个节点的群集上并发运行多个作业。 若要在 Azure 中创建单节点 HDInsight 群集,请在门户中预配新群集时,使用 Custom(size, settings, apps) 选项,并在群集大小部分将工作节点数设置为 1。
查看 HDInsight 的配额管理
在 VM 系列级别查看配额的精细级别和分类。 在 VM 系列级别查看某个区域的当前配额和剩余配额量。
注释
此功能目前已在中国东部 2 EUAP 区域的 HDInsight 4.x 和 5.x 版本中提供。 随后将在其他区域推出。
查看当前配额:
在 VM 系列级别查看某个区域的当前配额和剩余配额量。
在Azure门户中的顶部搜索栏中,搜索并选择Quotas。
在“配额”页中,选择“Azure HDInsight
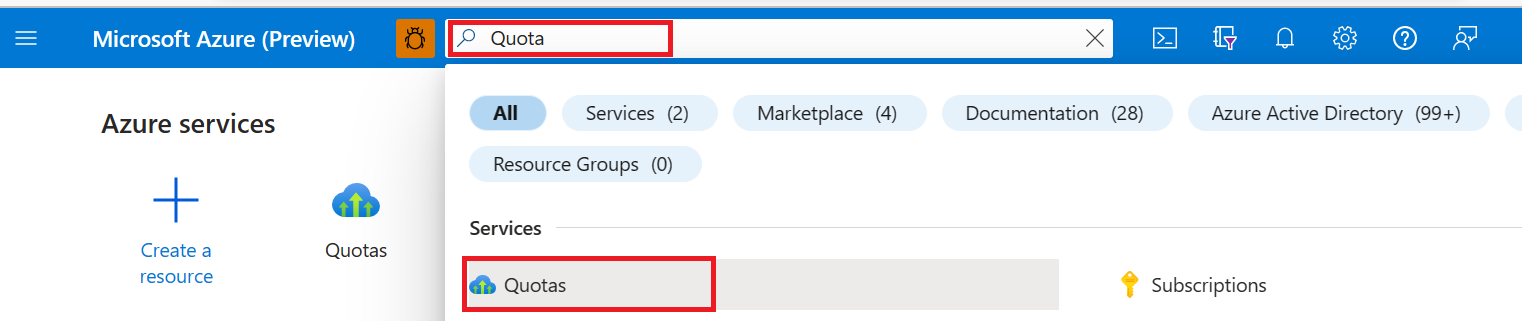
从下拉框中,选择“订阅”和“区域”
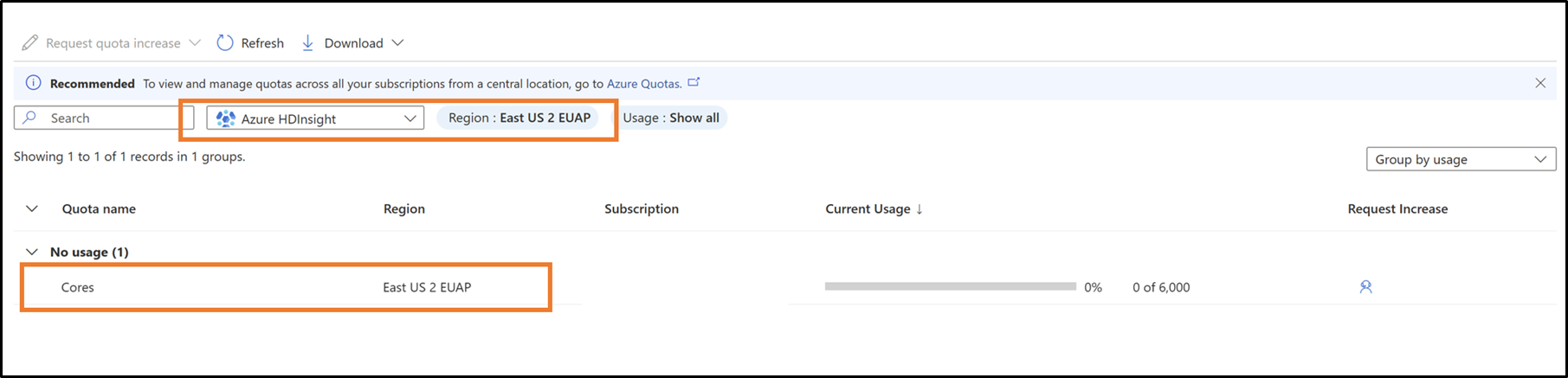
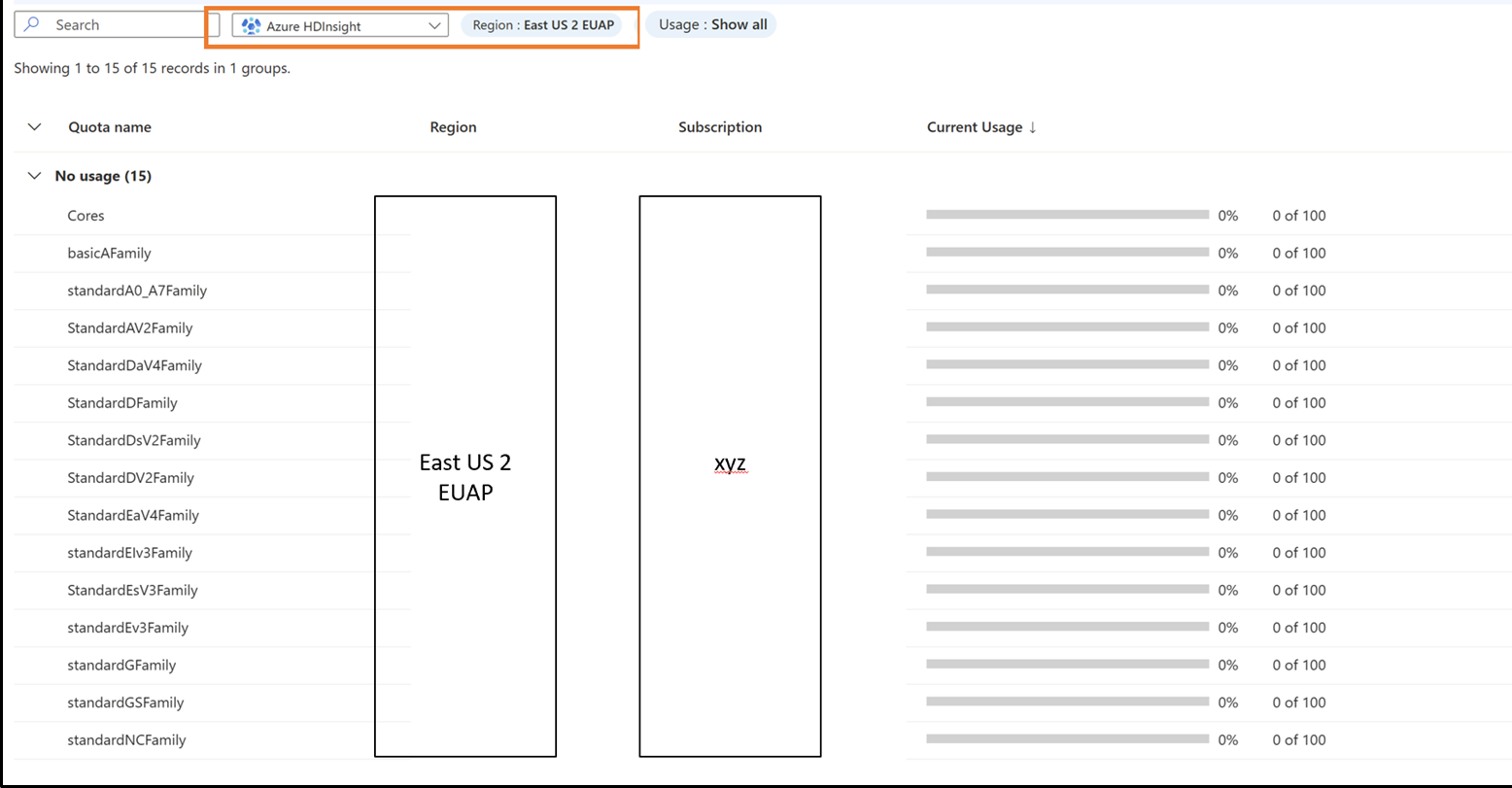
为每个 VM 系列和区域请求新配额
- 单击要查看其配额详细信息的行。
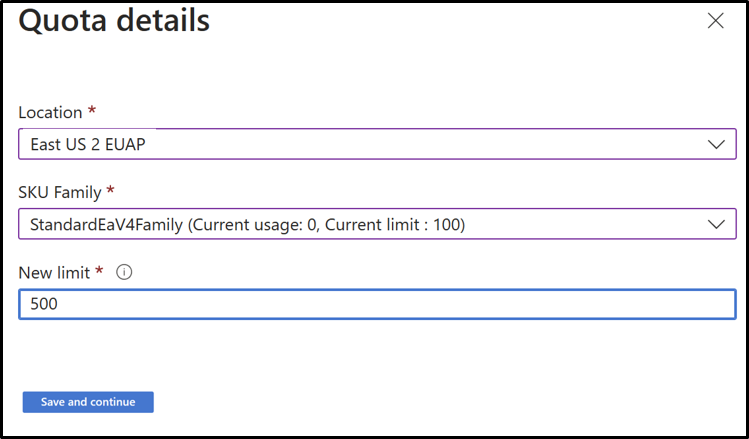




配额
有关管理订阅配额的详细信息,请参阅要求增加配额。
后续步骤
- 使用 Apache Hadoop、Spark、Kafka 等在 HDInsight 中设置群集:了解如何在 HDInsight 中设置和配置群集。
- 监视群集性能:了解要在 HDInsight 群集中监视的、可能会影响群集容量的关键情况。