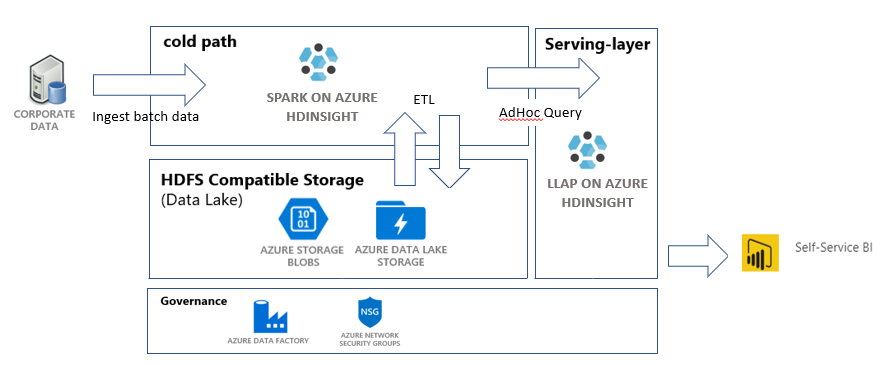
在本教程中,你需要生成一个端到端的数据管道用于执行提取、转换和加载 (ETL) 操作。 该管道使用 Azure HDInsight 上运行的 Apache Spark 和 Apache Hive 群集来查询和处理数据。 你还可使用用于存储数据的 Azure Data Lake Storage Gen2,以及用于可视化的 Power BI 等技术。
此数据管道将合并各种存储中的数据,删除不需要的数据,追加新数据,并将数据加载回存储中,以可视化业务见解。 有关 ETL 管道的详细信息,请参阅大规模提取、转换和加载。
如果没有 Azure 订阅,请在开始前创建一个试用版订阅。
先决条件
- Azure CLI,至少为版本 2.2.0。 请参阅安装 Azure CLI。
- jq,一个命令行 JSON 处理程序。 请参阅 jq 网站。
- Azure 内置角色 - 所有者的一个成员。
- 如果使用 PowerShell 来触发 Azure 数据工厂管道,则需要 Az PowerShell 模块。
- Power BI Desktop,用以可视化本教程结束时生成的业务见解。
创建资源
本部分介绍如何创建资源。
克隆包含脚本和数据的存储库
登录到 Azure 订阅。
az cloud set -n AzureChinaCloud az login # az cloud set -n AzureCloud //means return to Public Azure. # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"确保你是 Azure 角色所有者的成员。 将
user@contoso.com替换为你的帐户,然后输入以下命令:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"如果未返回记录,则你不是成员,将无法完成本教程。
从 HDInsight 销售见解 ETL 存储库下载本教程所需的数据和脚本。 输入以下命令:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etl确保已创建
salesdata scripts templates。 使用以下命令进行验证:ls
部署管道所需的 Azure 资源
通过输入以下命令添加对所有脚本的执行权限:
chmod +x scripts/*.sh设置资源组的变量。 将
RESOURCE_GROUP_NAME替换为现有或新资源组的名称,然后输入以下命令:RESOURCE_GROUP="RESOURCE_GROUP_NAME"运行脚本。 将
LOCATION替换为所需的值,然后输入以下命令:./scripts/resources.sh $RESOURCE_GROUP LOCATION如果不确定要指定哪个区域,则可以使用 az account list-locations 命令检索你的订阅支持的区域列表。
该命令用于部署以下资源:
- 一个 Azure Blob 存储帐户。 此帐户保存公司销售数据。
- Data Lake Storage Gen2 帐户。 此帐户充当两个 HDInsight 群集的存储帐户。 有关 HDInsight 和 Data Lake Storage Gen2 的详细信息,请参阅 Azure HDInsight 与 Data Lake Storage Gen2 的集成。
- 用户分配的托管标识。 此帐户为 HDInsight 群集授予对 Data Lake Storage Gen2 帐户的访问权限。
- Apache Spark 群集。 此群集用于清理和转换原始数据。
- 一个 Apache Hive 交互式查询群集。 可以使用此群集查询销售数据,并使用 Power BI 将其可视化。
- Azure 虚拟网络由网络安全组规则支持。 此虚拟网络允许群集相互通信,并可保护其通信。
创建群集的过程可能需要 20 分钟左右。
用于对群集进行安全外壳 (SSH) 协议访问的默认密码为 Thisisapassword1。 若要更改密码,请转到 ./templates/resourcesparameters_remainder.json 文件,并更改 sparksshPassword、sparkClusterLoginPassword、llapClusterLoginPassword 和 llapsshPassword 参数的密码。
验证部署并收集资源信息
若要检查部署状态,请在 Azure 门户中转到资源组。 在设置中,选择部署。 然后选择你的部署。 在此处可以看到已成功部署的资源,以及仍在部署的资源。
若要查看群集的名称,请输入以下命令:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAME若要查看 Azure 存储帐户和访问密钥,请输入以下命令:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEY若要查看 Data Lake Storage Gen2 帐户和访问密钥,请输入以下命令:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
创建数据工厂
Azure 数据工厂是一个有助于自动化 Azure Pipelines 的工具。 这不是完成这些任务的唯一方式,但它是自动化这些过程的绝佳方法。 有关数据工厂的详细信息,请参阅数据工厂文档。
此数据工厂有一个管道,其中包含两个活动:
- 第一个活动将 Blob 存储中的数据复制到 Data Lake Storage Gen2 存储帐户,以模拟数据引入。
- 第二个活动转换 Spark 群集中的数据。 脚本通过删除不需要的列来转换数据。 它还会追加一个新列来计算单笔交易产生的收入。
若要设置数据工厂管道,请运行以下命令。 你应该还在 hdinsight-sales-insights-etl 目录中。
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
此脚本执行以下操作:
- 创建具有
Storage Blob Data Contributor权限的服务主体,以便在 Data Lake Storage Gen2 存储帐户上使用。 - 获取身份验证令牌,以授权对
POST的 请求。 - 在
sparktransform.py和query.hql文件中填充 Data Lake Storage Gen2 存储帐户的实际名称。 - 获取 Data Lake Storage Gen2 和 Blob 存储帐户的存储密钥。
- 创建另一个资源部署,以创建数据工厂管道及其关联的链接服务和活动。 它将存储密钥作为参数传递给模板文件,使链接服务能够正常访问存储帐户。
运行数据管道
本部分介绍如何运行数据管道。
触发数据工厂活动
创建的数据工厂管道中的第一个活动将 Blob 存储中的数据移到 Data Lake Storage Gen2。 第二个活动对数据应用 Spark 转换,并将转换后的 csv 文件保存到新位置。 整个管道可能需要几分钟时间才能完成。
若要检索数据工厂名称,请输入以下命令:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
若要触发管道,你有两个选择。 您可以:
在 PowerShell 中触发数据工厂管道。 将
RESOURCEGROUP和DataFactoryName替换为适当的值,然后运行以下命令:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipeline根据需要重新执行
Get-AzDataFactoryV2PipelineRun来监视进度。或者您可以:
打开数据工厂并选择“创作和监视”。 从门户触发
IngestAndTransform管道。 有关如何通过门户触发管道的信息,请参阅使用 Azure 数据工厂在 HDInsight 中创建按需 Apache Hadoop 群集。
若要验证管道是否已运行,请执行以下步骤之一:
- 通过门户转到数据工厂的“监视”部分。
- 在 Azure 存储资源管理器中,转到你的 Data Lake Storage Gen2 存储帐户。 转到
files文件系统,然后转到transformed文件夹。 检查文件夹内容,查看管道是否成功。
有关使用 HDInsight 转换数据的其他方式,请参阅这篇有关使用 Jupyter Notebook 的文章。
在交互式查询群集中创建一个表用于查看 Power BI 中的数据
使用安全复制 (SCP) 命令将
query.hql文件复制到 LLAP 群集。 输入以下命令:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.cn:/home/sshuser/提醒:默认密码为
Thisisapassword1。使用 SSH 访问 LLAP 群集。 输入以下命令:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.cn使用以下命令运行该脚本:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hql此脚本将在 Interactive Query 群集中创建一个可从 Power BI 访问的托管表。
基于销售数据创建 Power BI 仪表板
打开 Power BI Desktop。
在菜单中,转到“获取数据”>“更多...”>“Azure”>“HDInsight Interactive Query”。
选择 连接。
在“HDInsight Interactive Query”对话框中执行以下操作:
- 在“服务器”文本框中,以 格式输入 LLAP 群集的名称。
- 在“数据库”文本框中,输入 default。
- 选择“确定”。
在“AzureHive”对话框中执行以下操作:
- 在“用户名”文本框中,输入 admin。
- 在“密码”文本框中,输入 Thisisapassword1。
- 选择 连接。
在“导航器”中,选择 sales 或 sales_raw 以预览数据。 加载数据后,可以尝试创建仪表板。 若要开始使用 Power BI 仪表板,请参阅以下文章:
清理资源
如果你不打算继续使用此应用程序,请删除所有资源,以免产生费用。
若要删除资源组,请输入以下命令:
az group delete -n $RESOURCE_GROUP若要删除服务主体,请输入以下命令:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL