Azure Load Balancer公开以下诊断功能:
多维指标和警报:通过 Azure Monitor 为 Azure Load Balancer 的配置提供多维诊断功能。 可以监视、管理和排查标准负载均衡器资源问题。
资源状态:您的负载均衡器的资源健康状态在 Monitor 下的 资源状态 页面中可用。 此自动检查会通知你负载均衡器资源的当前可用性。
本文提供了这些功能的简要概览,并提供了用于标准负载均衡器的方法。
多维指标
Azure Load Balancer通过Azure portal中的Azure指标提供多维指标,有助于获取负载均衡资源的实时诊断信息。 请注意,基本负载均衡器不支持多维指标
各种负载均衡器配置提供以下指标:
| 指标 | 资源类型 | 说明 | 建议的聚合 |
|---|---|---|---|
| 数据路径可用性 | 公共和内部负载均衡器 | 负载均衡器持续使用区域内到其前端的数据路径,从而连接到支持虚拟机的网络。 只要保留正常实例,这种度量就会遵循应用程序负载均衡的流量所用的相同路径。 正在使用的数据路径已验证。 度量对于应用程序不可见,且不会干扰其他操作。 | 平均值 |
| 健康探测状态 | 公用和内部负载均衡器 | load balancer使用分布式运行状况探测服务,该服务根据配置设置监视应用程序终结点的运行状况。 此指标提供负载均衡器池中每个实例的终结点的聚合视图或按每个终结点筛选的视图。 可以看到负载均衡器如何通过您的运行状况探测配置来查看应用程序的运行状况。 | 平均值 |
| SYN 计数 | 公共和内部负载均衡器 | 负载均衡器不会终止传输控制协议(TCP)连接,也不会与 TCP 或用户数据报协议(UDP)流交互。 流及其握手始终位于源和 VM 实例之间。 若要更好地排查 TCP 协议方案的问题,可以使用 SYN 数据包计数器了解进行了多少次 TCP 连接尝试。 该指标将报告接收到的 TCP SYN 数据包数目。 | 总和 |
| 源网络地址转换 (SNAT) 连接计数 | 公共负载均衡器 | 一个负载均衡器报告伪装到公共 IP 地址前端的出站流数。 SNAT 端口是可耗竭性资源。 此指标可以指出应用程序依赖于 SNAT 获取出站发起流的程度有多高。 报告成功和失败的出站 SNAT 流的计数器。 计数器可用于排查和了解出站流的运行状况。 | 总和 |
| 已分配的 SNAT 端口数 | 公共负载均衡器 | 一个负载均衡器显示每个后端实例分配的 SNAT 端口数 | 平均值。 |
| 已用 SNAT 端口数 | 公共负载均衡器 | load balancer报告每个后端实例使用的 SNAT 端口数。 | 平均值 |
| 字节计数 | 公共和内部负载均衡器 | 负载均衡器报告每个前端处理的数据。 你可能会注意到,这些字节并没有均匀地分布在后端实例中。 这是意料之中的,因为Azure Load Balancer的算法是基于数据流的。 | 总和 |
| 数据包计数 | 公共和内部负载均衡器 | 一个负载均衡器报告每个前端处理的数据包数量。 | 总和 |
注意
与带宽相关的指标(例如 SYN 数据包、字节计数和数据包计数)不会通过 UDR 捕获到任何到内部负载均衡器的流量。
最大和最小聚合不适用于 SYN 计数、数据包计数、SNAT 连接计数和字节计数指标。 不建议对数据路径可用性和运行状况探测状态进行计数聚合。 请改为使用平均值作为最佳表示运行状况数据。
注意
创建或更新负载均衡器后,数据路径可用性指标可能需要最多 10 分钟才能显示在 Azure 监控指标中。
在 Azure 门户中查看负载均衡器指标
Azure portal通过“指标”页公开负载均衡器的指标。 此页面可在负载均衡器特定资源的资源页面及Azure监视器页面上使用。
注意
Azure Load Balancer不会向解除分配的虚拟机发送运行状况探测。 在虚拟机解除分配后,负载均衡器将停止报告该实例的指标。 不可用的指标将在门户中显示为一道短划线,或显示一条表示无法检索指标的错误消息。
若要查看负载均衡器资源的指标,
转到“指标”页,执行以下任务之一:
在负载均衡器的资源页面上,从下拉列表中选择指标类型。
在 Azure Monitor 页上,选择负载均衡器资源。
设置适当的指标聚合类型。
(可选)配置需要的筛选和分组。
(可选)配置时间范围和聚合。 默认情况下,时间以 UTC 格式显示。
注意
解释某些指标时,时间聚合非常重要,因为数据每分钟采样一次。 如果时间聚合设置为五分钟,并且指标聚合类型“求和”用于“SNAT 分配”等指标,则图形将显示分配的 SNAT 端口总数的五倍。
建议:分析指标聚合类型 Sum 和 Count 时,建议使用大于一分钟的时间聚合值。
通过 API 以编程方式检索多维指标
有关检索多维指标定义和值的 API 指南,请参阅 Azure 监视 REST API 演练。 可以通过为“所有指标”类别添加诊断设置,将这些指标写入存储帐户。
常见诊断应用场景和建议的视图
数据路径是否已启动并可用于我的负载均衡器前端?
展开
“数据路径可用性”指标描述 VM 所在计算主机的数据路径区域内的运行状况。 该指标反映了load balancer的运行状况,具体取决于配置和Azure基础结构。 使用此指标可以:
监视您服务的外部可用性。
调查部署服务的平台,并确定其是否正常运行。 确定你的客户操作系统或应用程序实例是否健康。
查明某个事件是与服务还是底层数据平面相关。 不要将该指标与“性能探测状态”指标混淆。
若要获取负载均衡器资源的数据通路可用性,请执行以下操作:
确保选择了正确的负载均衡器资源。
在“指标”下拉列表中选择“数据路径可用性”。
在“聚合”下拉列表中,选择“平均”。
另外,请将基于前端 IP 地址或前端端口的筛选器添加为条件,并指定所需的前端 IP 地址或前端端口。 然后根据选定的维度将其分组。
该指标由区域内模拟流量的探测服务生成。 该探测服务会定期生成与部署的前端和负载均衡规则匹配的数据包。 然后,数据包从源遍历该区域,到达后端池中 VM 的主机。 负载均衡器基础设施执行与所有其他流量相同的负载均衡和转换操作。 探测抵达后端池中 VM 所在的主机后,主机会针对探测服务生成响应。 VM 看不到此流量。
请注意,“数据路径可用性”指标只会在具有负载均衡规则的前端 IP 配置上生成。
由于以下原因,“数据路径可用性”指标可能会降级:
后端池中没有剩余的可用于部署的正常 VM。
发生基础结构服务中断。
可以结合使用“数据路径可用性”指标和运行状况探测状态进行诊断。
在大多数情况下,可以使用“平均值”作为聚合。
我的负载均衡器的后端实例是否对探测作出响应?
展开
运行状况探测状态指标描述了您在配置负载均衡器的运行状况探测时设置的应用程序部署的运行状况。 负载均衡器使用运行状况探测的状态来确定发送新流量的目标位置。 健康探测器来源于 Azure 基础设施地址,并在 VM 的来宾操作系统中可见。
若要获取负载均衡器资源的探测健康状态指标,请执行以下操作:
选择“运行状况探测状态”作为指标,选择“平均值”作为聚合类型。
应用筛选器以过滤所需的前端 IP 地址或端口(或两者)。
运行状况探测会出于以下原因而失败:
将运行状况探测配置到未侦听、未响应或使用错误协议的端口。 如果服务使用直接服务器返回或浮动 IP 规则,请验证服务侦听 NIC IP 配置的 IP 地址和使用前端 IP 地址配置的环回地址。
网络安全组、虚拟机的来宾操作系统防火墙或应用层筛选器不允许运行状况探测流量。
在大多数情况下,可以使用“平均值”作为聚合。
我该如何检查我的出站连接统计信息?
展开
“SNAT 连接”指标描述适用于出站流的成功和失败连接的数量。
如果失败连接数量大于零,则表示 SNAT 端口已耗尽。 必须进一步调查,确定失败的可能原因。 SNAT端口耗尽的表现为无法建立外部流量。 请查看有关出站连接的文章,以了解相关的场景和运行机制,并了解如何缓解并尽量避免 SNAT 端口耗尽的情况。
若要获取 SNAT 连接统计信息,请执行以下操作:
选择指标类型为SNAT连接,并将聚合选择为总和。
按连接状态分组,以使成功和失败的 SNAT 连接计数由不同的线表示。
我该如何检查 SNAT 端口的使用情况和分配?
展开
“使用的 SNAT 端口数”指标跟踪 SNAT 端口的使用情况,以维护出站流。 该指标表明多少唯一流量在互联网源与位于负载均衡器后且无公共 IP 地址的后端 VM 或虚拟机规模集之间建立。 通过将你使用的 SNAT 端口数与“分配的 SNAT 端口数”指标进行比较,可以确定服务是否因为遇到了 SNAT 耗尽问题或者面临着这种风险而导致出站流失败。
如果指标指示存在出站流量故障的风险,请参考文章并采取措施来缓解此问题,以确保服务健康。
若要查看 SNAT 端口用量和分配:
将图形的时间聚合设置为 1 分钟,以确保显示所需的数据。
选择“使用的 SNAT 端口数”和/或“分配的 SNAT 端口数”作为指标类型,选择“平均值”作为聚合。
默认情况下,这些指标是每个后端 VM 或虚拟机规模集分配和使用的平均 SNAT 端口数。 它们对应于映射至负载均衡器的所有前端公共 IP,这些 IP 是通过 TCP 和 UDP 来聚合的。
若要查看负载均衡器使用或分配的 SNAT 端口总数,请使用指标汇总Sum。
根据特定的“协议类型”、一组“后端 IP”和/或“前端 IP”进行筛选。
若要监视每个后端或前端实例的运行状况,请应用拆分。
- 请注意,拆分时每次只允许显示一个指标。
例如,若要监视每台计算机的 TCP 流的 SNAT 用量,请通过“平均”进行聚合,按“后端 IP”进行拆分,并按“协议类型”进行筛选。
我该如何检查我的服务的入站/出站连接尝试?
展开
“SYN 数据包”指标描述收到或发送的、适用于特定前端关联出站流的 TCP SYN 数据包数量。 您可以使用此指标了解与服务相关的 TCP 连接尝试。有关出站连接的详细信息,请参阅适用于出站连接的源网络地址转换 (SNAT)
在大多数情况下,可以使用“总和”作为聚合。
我如何检查网络带宽消耗情况?
展开
字节和数据包计数器指标描述服务发送或收到的字节和数据包数量,根据前端显示信息。
在大多数情况下,可以使用“总和”作为聚合。
获取字节或数据包计数统计信息:
选择“字节计数”和/或“数据包计数”作为指标类型,并选择“总和”作为聚合。
执行以下操作之一:
对特定前端 IP、前端端口、后端 IP 或后端端口应用筛选器。
获取负载均衡器资源的总体统计信息,而无需进行任何筛选。
如何诊断我的负载均衡器部署?
展开
通过在单个图表中结合使用数据路径可用性和运行状况探测状态指标,您可以识别应该在哪里查找问题并解决问题。 可以保证Azure正常工作,并使用此知识确定配置或应用程序是根本原因。
可以使用运行状况探测指标来了解Azure如何根据您提供的配置查看部署的运行状况。 在监测或确定原因时,查看健康探测始终是一个很好的第一步。
可以进一步执行该步骤,并使用数据路径可用性指标来深入了解Azure如何查看负责特定部署的基础数据平面的运行状况。 结合使用两个指标,可以查明错误的所在位置,如以下示例所示:
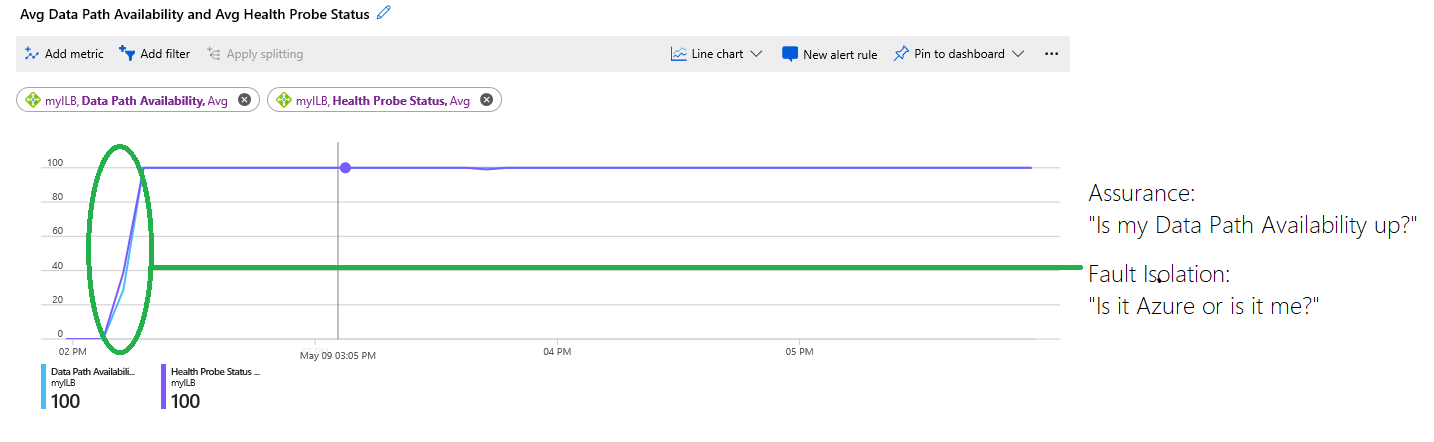
图:组合使用“数据路径可用性”和“运行状况探测状态”指标
此图表显示以下信息:
承载您虚拟机的基础设施在图表的开始阶段不可用,并为 0%。 稍后,基础结构正常,VM 可访问,多个 VM 置于后端。 数据路径可用性的蓝色轨迹(稍后显示为 100%)指示了此信息。
图表开头紫色轨迹所示的运行状况探测状态为 0%。 绿色圆圈突出显示了运行状况探测状态变为正常的位置,以及客户部署可以接受新流量的位置。
客户可以使用该图表来自行排查部署问题,而无需猜测或询问支持部门是否发生了其他问题。 此服务之所以不可用,是因为配置不当或应用程序故障导致运行状况探测失败。
配置针对多维指标的警报
Azure Load Balancer支持针对多维指标轻松配置的警报。 为特定指标配置自定义阈值,用以触发具有不同严重性级别的警报,从而提供无接触的资源监视体验。
配置警报:
转到负载均衡器的警报页面
创建新的警报规则
配置警报条件(注意:为避免干扰警报,我们建议通过将“聚合类型”配置为“平均”,回顾 5 分钟的数据窗口,将阈值设置为 95% 来配置警报)
(可选)添加用于自动修复的操作组
分配警报严重性、名称和说明,以实现直观的反应
入站可用性警报
注意
如果负载均衡器的后端池为空,那么负载均衡器将没有任何有效数据路径可供测试。 因此,数据路径可用性指标将不可用,并且不会触发数据路径可用性指标上配置的任何Azure警报。
如果要对入站可用性发出警报,可以使用数据路径可用性和运行状况探测状态指标创建两个单独的警报。 客户不同的方案可能需要特定的警报逻辑,但以下示例对大多数配置都有帮助。
使用数据路径可用性,可以在特定的负载均衡规则变为不可用时触发警报。 可以配置此警报,方法是为数据路径可用性设置警报条件,并按前端端口和前端 IP 地址的所有当前值和未来值进行拆分。 如果将警报逻辑设置为小于或等于 0,则每当任何负载均衡规则变为无响应时,就会触发此警报。 根据所需的评估设置聚合粒度和评估频率。
通过使用运行状况探测状态,可以在给定的后端实例在相当长的一段时间内没有响应运行状况探测时发出警报。 使用“平均值”聚合类型设置警报条件以使用运行状况探测状态指标,并依据后端 IP 地址和后端端口进行拆分。 这确保可以针对每个后端实例在特定端口上处理流量的能力单独发出警报。
出站可用性警报
对于出站可用性,可以使用 SNAT 连接计数和已用 SNAT 端口指标来配置两个单独的警报。
若要检测出站连接失败,请使用 SNAT 连接计数并筛选为“连接状态 = 失败”来配置警报。 使用“总计”聚合。 然后,可以按后端 IP 地址设置将其拆分为所有当前值和未来值,以分别为每个遇到失败连接的后端实例发出警报。 如果希望看到某些出站连接失败,请将阈值设置为大于零或更大的数字。
通过已使用的 SNAT 端口,可以在 SNAT 耗尽和出站连接失败风险增高时发出警报。 使用此警报时,请确保按后端 IP 地址和协议进行拆分。 使用“平均”聚合。 将阈值设置为大于为每个实例分配的、你认为不安全的端口数的百分比。 例如,如果后端实例使用其已分配端口的 75%,则配置低严重性警报。 如果使用其已分配端口的 90% 或 100%,则配置高严重性警报。
资源健康状态
现有的 Monitor > Service health 下的 Resource health 公开标准负载均衡器资源的健康状态。 每“两分钟”对其进行一次评估,方法是测量数据路径可用性,从而确定前端负载均衡终结点是否可用。
| 资源健康状态 | 说明 |
|---|---|
| 可用 | 您的标准负载均衡器资源是健康且可用的。 |
| 已降级 | 标准负载均衡器因平台或用户启动的事件影响了性能。 “数据路径可用性”指标至少有两分钟报告了低于 90% 但高于 25% 的运行状况。 在此状态下,你会遇到中等到严重程度的性能影响。 按照 RHC 故障排除指南确定是否存在用户发起的且会影响你的可用性的事件。 |
| 不可用 | 您的标准负载均衡器资源不健康。 “数据路径可用性”指标至少有两分钟报告了低于 25% 的运行状况。 处于此状态时,你会遇到严重的性能影响,或者入站连接不可用。 可能存在导致不可用的用户或平台事件。 按照 RHC 故障排除指南确定是否存在用户发起的且会影响你的可用性的事件。 |
| 未知 | 负载均衡器资源的健康状态尚未更新,或在过去 10 分钟内未收到有关数据路径可用性的信息。 此状态应该是暂时性的,系统在收到数据后会立即反映正确的状态。 |
若要查看公共的标准负载均衡器资源的健康状况,请执行以下操作:
选择 监控>服务健康。
选择 Resource health,并确保选中 Subscription ID 和 资源类型 = load balancer。
在列表中,选择负载均衡器资源以查看其历史健康状况。
资源健康文档中提供了资源健康状态的通用说明。
资源健康警报
当负载均衡器资源的运行状况发生更改时,Azure Resource Health警报可以几乎实时地通知你。 ** 建议设置资源健康警报,以便在负载均衡器资源处于 Degraded 或 Unavailable 状态时通知你。
当您为负载均衡器创建 Azure 资源健康警报时,Azure 会向您的 Azure 订阅发送资源健康通知。 可根据以下内容创建和自定义警报:
- 受影响的订阅
- 受影响的资源组
- 受影响的资源类型(负载均衡器)
- 特定资源(您选择用于设置警报的任何负载均衡器资源)
- 负载均衡器资源受影响的事件状态
- 受影响的负载均衡器资源的当前状态
- 负载均衡器资源之前的状态受到影响
- 负载均衡器资源受影响的原因类型
还可配置应将警报发送给哪些人员:
- 新操作组(可用于将来的警报)
- 现有操作组
有关如何设置这些资源健康警报的详细信息,请参阅:
- 通过 Azure portal 发出资源健康警报
- 使用 Resource Manager 模板的资源健康警报
后续步骤
- 了解如何使用 Insights 查看为load balancer预配置的这些指标。
- 详细了解 Standard load balancer。