Service Fabric 是利用分层子系统而生成的。 使用这些子系统,可以编写下面这样的应用程序:
- 高度可用
- 可缩放
- 可管理
- 可测试
下图显示 Service Fabric 的主要子系统。
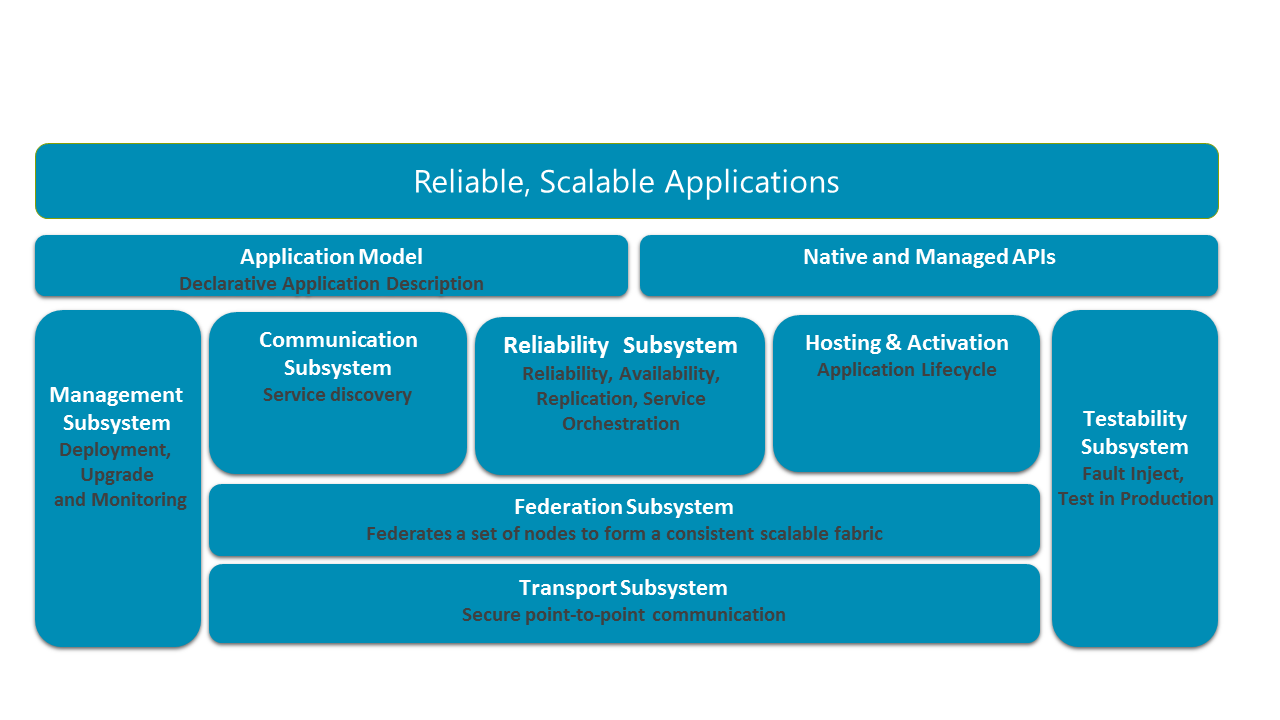
在分布式系统中,在群集中的节点之间进行安全通信的能力至关重要。 堆栈底部是传输子系统,它在节点之间提供安全的通信。 传输子系统之上即是联合子系统,它将不同节点聚集为一个单一实体(名为群集)以便 Service Fabric 可以检测失败、执行群首选举并提供一致性路由。 联合子系统之上是可靠性子系统,它通过诸如复制、资源管理和故障转移等机制负责 Service Fabric 服务的可靠性。 联合子系统之上还有宿主和激活子系统,它管理单个节点上的应用程序的生命周期。 管理子系统管理应用程序和服务的生命周期。 可测试性子系统可帮助应用程序开发人员在将应用程序和服务部署到生产环境之前和之后通过模拟失败测试其服务。 Service Fabric 能够通过其通信子系统来解析服务位置。 向开发人员公开的应用程序编程模型则位于这些子系统以及用于启用工具的应用程序模型之上。
传输子系统
传输子系统实现点对点数据报信道。 此信道用于 Service Fabric 群集内部的通信以及 Service Fabric 群集与客户端之间的通信。 它支持单向和请求答复通信模式,为联合层中的广播和多播提供了基础。 传输子系统通过使用 X509 证书或 Windows 安全性来保护通信安全。 此子系统供 Service Fabric 内部使用,应用程序编程的开发人员不可直接进行访问。
联合子系统
为了推论出分布式系统中的一组节点,需要一致的系统视图。 联合子系统使用传输子系统提供的通信基元,并将各个节点拼结为它可进行推论的单个统一群集。 它提供其他子系统所需的系统基元 - 失败检测、群首选举和一致性路由。 联合子系统构建在具有 128 位令牌空间的分布式哈希表基础之上。 该子系统在节点上方创建一个环形拓扑,环中的每个节点分配拥有一部分令牌空间。 对于失败检测,该层使用基于信号检测和仲裁的租用机制。 此外,联合子系统还通过复杂联接和偏离协议保证在任意时刻都只有一个令牌所有者退出。 这提供了群首选举和一致性路由保证。
可靠性子系统
可靠性子系统通过使用复制器、故障转移管理器和资源平衡器提供一种机制,使得 Service Fabric 服务的状态高度可用。
- 复制器确保主服务副本中的状态更改会自动复制到辅助副本,从而维护服务副本集中主副本和辅助副本之间的一致性。 复制器负责副本集中副本间的仲裁管理。 它与故障转移单元进行交互以获取要复制的操作列表,重新配置代理为其提供副本集的配置。 该配置指示操作需要复制到哪些副本。 Service Fabric 提供名为 Fabric Replicator 的默认复制器,编程模型 API 可使用它来使服务状态高度可用和高度可靠。
- 故障转移管理器确保向群集添加节点或从群集中删除节点时,会自动在可用节点间重新分发负载。 如果群集中的节点失败,群集会自动重新配置服务副本以维持可用性。
- Resource Manager 跨集群中的故障域放置服务副本,并确保所有故障转移单元均可运行。 Resource Manager 还会平衡群集节点基础共享池中的服务资源,从而获得最佳的统一负载分布。
管理子系统
管理子系统提供端到端服务和应用程序生命周期管理。 借助 PowerShell cmdlet 和管理 API,可以预配、部署、修补、升级和取消预配应用程序,而不会降低可用性。 管理子系统通过以下服务执行此功能。
- 群集管理器:这是与可靠性子系统中的故障转移管理器交互的主服务,可基于服务放置约束在节点上放置应用程序。 故障转移子系统中的 Resource Manager 确保约束永远不会中断。 群集管理器管理应用程序从设置到取消设置的生命周期。 它与运行状况管理器集成,可确保在升级期间,从语义运行状况的角度来看应用程序可用性不会丢失。
- 运行状况管理器:此服务对应用程序、服务和群集实体启用运行状况监视。 群集实体(如节点、服务分区和副本)可以报告运行状况信息,此信息随后聚合到集中式运行状况存储中。 此类运行状况信息构成了跨群集中多个节点分布的服务和节点的总体时间点运行状况快照,方便用户采取任何所需的纠正措施。 借助运行状况查询 API,可以查询向运行状况子系统报告的运行状况事件。 运行状况查询 API 为特定群集实体返回存储在运行状况存储中的原始运行状况数据,或已解释的聚合运行状况数据。
- 映像存储区:此服务提供存储和分发应用程序二进制文件的功能。 此服务提供简单的分布式文件存储,应用程序可上传到该存储中或从该存储中下载。
宿主子系统
群集管理器通知宿主子系统(在每个节点上运行)需要为特定节点管理的服务。 然后,托管子系统管理相应节点上应用程序的生命周期。 它与可靠性和运行状况组件交互,可确保副本正确放置且正常运行。
通信子系统
此子系统通过命名服务提供群集内部的可靠消息传送和服务发现。 命名服务将服务名称解析到群集中的某个位置,并允许用户管理服务名称和属性。 使用命名服务,客户端可以安全地与群集中任一节点进行通信,以解析服务名称并检索服务元数据。 使用一个简单的命名客户端 API,Service Fabric 的用户可以开发服务和客户端,这些服务和客户端能够解析当前网络位置,而不受节点动态性或群集重设大小的影响。
可测试性子系统
可测试性是一套专为测试建立于Service Fabric 基础之上的服务而设计的工具。 这些工具让开发人员能够轻松地引发有意义的故障及运行测试方案来执行和验证服务在整个生命周期内要经历的大量状态和转换,所有一切都以受控且安全的方式进行。 可测试性还提供了一种机制来运行更长时间的测试,可在不丢失可用性的情况下循环访问各种可能的故障。 这可以提供生产环境中的测试。