本文概述 Azure Service Fabric 的监视和诊断。 在任何云环境中开发、测试和部署工作负荷时,监视和诊断至关重要。 例如,可以跟踪应用程序的使用方式、Service Fabric 平台所采取的操作、带性能计数器的资源利用率以及群集的总体运行状况。 可以使用此信息来诊断和更正问题,避免将来发生此类问题。 接下来的几节将简要介绍 Service Fabric 监视的每个区域,以便将生产工作负荷纳入考虑范围。
注意
本文最近已更新,从使用术语“Log Analytics”改为使用术语“Azure Monitor 日志”。 日志数据仍然存储在 Log Analytics 工作区中,并仍然由同一 Log Analytics 服务收集并分析。 我们正在更新术语,以便更好地反映 Azure Monitor 中的日志的角色。 有关详细信息,请参阅 Azure Monitor 术语更改。
应用程序监视
应用程序监视跟踪应用程序的功能和组件的使用方式。 监视应用程序可以确保捕获影响用户的问题。 应用程序监视主要负责用户开发应用程序及其服务,因为它对应用程序的业务逻辑是唯一的。 监视应用程序可能对以下情况有帮助:
- 应用程序遇到了多少流量? - 是否需要缩放服务来满足用户需求,或解决应用程序中的潜在瓶颈?
- 服务到服务调用是否成功并已进行跟踪?
- 应用程序的用户执行哪些操作? - 收集遥测可指导将来的功能开发和更好地诊断应用程序错误
- 应用程序正在引发未经处理的异常?
- 容器内运行的服务中发生了什么情况?
由于应用程序监视位于应用程序的上下文中,因此其最大的优点在于,开发人员可以使用他们喜欢的任意工具和框架! 可以在使用 Application Insights 进行事件分析中了解有关使用 Azure Monitor Application Insights 进行应用程序监视的 Azure 解决方案的更多信息。 我们还提供了介绍如何为 .NET应用程序设置此监视的教程。 本教程介绍如何安装正确的工具、在应用程序中编写自定义遥测的示例以及在 Azure 门户中查看应用程序诊断和遥测。
平台(群集)监视
由于用户自己编写代码,用户可以控制来自其应用程序的遥测,但是来自 Service Fabric 平台的诊断怎么办? Service Fabric 的目标之一是确保应用程序能够灵活应对硬件故障。 为了实现此目的,可以通过平台的系统服务功能检测基础结构问题,并快速将工作负荷故障转移到群集中的其他节点。 但在此特殊情况下,系统服务本身出现问题该怎么办? 或者,在尝试部署或移动工作负荷时,如果违反服务位置的规则该怎么办? Service Fabric 为这些以及更多内容提供诊断,以确保你了解群集中发生的活动。 群集监视的一些示例场景包括:
Service Fabric 提供了一组现成的综合事件。 可以通过 EventStore 或操作通道(平台公开的事件通道)来访问这些 Service Fabric 事件。
Service Fabric 事件通道 - 在 Windows 上,Service Fabric 事件可通过使用一组相关
logLevelKeywordFilters(用于在操作通道与“数据和消息”通道之间进行选择)从单个 ETW 提供程序获得 - 这是我们用来分离出要根据需要筛选的传出 Service Fabric 事件的方式。 在 Linux 中,Service Fabric 事件通过 LTTng 传入一个存储表中,可在其中按需筛选事件。 这些通道包含组织有序的结构化事件用于更好地了解群集的状态。 创建群集时默认会启用“诊断”并创建一个 Azure 存储表,来自这些通道的事件将发送到其中,方便将来进行查询。EventStore - EventStore 是该平台提供的一项功能,它提供通过 REST API 且在 Service Fabric Explorer 中可用的 Service Fabric 平台事件。 可以查看群集中每个实体的动态快照视图,例如节点、服务、应用程序和基于事件时间的查询。 还可以从 EventStore 概述了解有关 EventStore 的详细信息。
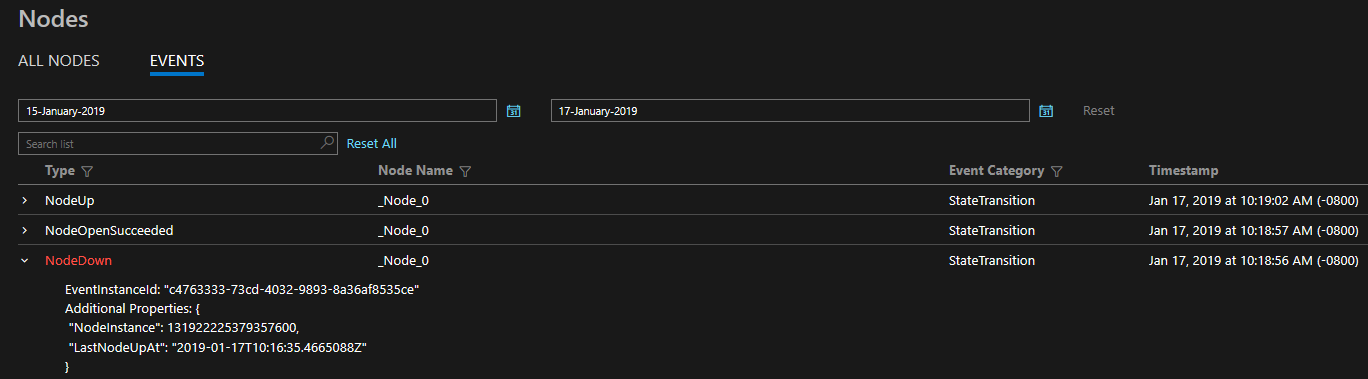
诊断以一系列现成的全面的事件集的形式提供。 这些 Service Fabric 事件说明了平台在节点、应用程序、服务、分区等不同实体上执行的操作。在上述最后一个场景中,如果节点发生故障,平台将发出 NodeDown 事件,可以立即通过所选的监控工具通知你。 故障转移期间,其他常见示例包括 ApplicationUpgradeRollbackStarted 或 PartitionReconfigured。 Windows 和 Linux 群集上都有相同的事件。
事件通过 Windows 和 Linux 上的标准通道发送,并且可以由任何支持这些事件的监视工具读取。 平台级别事件和日志生成提供了更多群集监视概念。
运行状况监视
Service Fabric 平台包含运行状况模型,针对群集中的实体状态提供可扩展的运行状况报告。 每个节点、应用程序、服务、分区、副本或实例都具有持续可更新的运行状况。 运行状况可能是“正常”、“警告”或“错误”。 将 Service Fabric 事件视为群集对各种实体所做的动词,将运行状况视为每个实体的形容词。 每次特定实体的运行状况转换时,也会发出事件。 这样,就可以在所选监视工具中为运行状况事件设置查询和警报,就像任何其他事件一样。
此外,我们甚至允许用户重写实体的运行状况。 如果应用程序正在进行升级且验证测试失败,则可以使用运行状况 API 写入 Service Fabric 运行状况,以指示应用程序未正常运行,并且 Service Fabric 将自动回滚升级! 有关运行状况模型的详细信息,请参阅 Service Fabric 运行状况监视简介
监视器
监视器通常是一个独立的服务,用于监视各个服务的运行状况和负载、ping 终结点,以及报告群集中的异常运行状况事件。 这有助于防止出现仅基于单个服务的性能所检测不到的错误。 监视器也是一个托管代码的好选择,无需用户交互即可执行补救措施,例如每隔特定时间就清理一次存储中的日志文件。 如果需要完全实现的开源 SF 监视服务,其中包括易于使用的监视器可扩展性模型,同时在 Windows 和 Linux 群集中都能运行,请参阅 FabricObserver 项目。 FabricObserver 是生产就绪软件。 建议将 FabricObserver 部署到测试和生产群集,并通过其插件模型或者通过分支并编写自己的内置观察器对其扩展,以满足你的需求。 建议采用前一种(插件)方法。
基础结构(性能)监视
既然我们已介绍了应用程序和平台中的诊断,那么如何知道硬件按预期方式正常运行? 监视底层基础结构是了解群集状态和资源利用率的重要组成部分。 测量系统性能取决于多种因素,主观上取决于工作负荷。 这些因素通常通过性能计数器来衡量。 这些性能计数器可以来自各种来源,包括操作系统、.NET Framework 或 Service Fabric 平台本身。 在某些情况下,它们将是有用的
- 能否有效地利用硬件? 是否要以 90% 的 CPU 使用率或 10% 的 CPU 使用率使用硬件。 这在扩展群集或优化应用程序进程时非常方便。
- 是否可以主动预测基础结构问题? - 许多问题在发生之前,都会出现性能骤然发生变化(下降)的前兆,因此,可以使用网络 I/O 和 CPU 利用率等性能计数器来主动预测和诊断问题。
可以在性能指标中找到应在基础结构级别收集的性能计数器列表。
Service Fabric 还为 Reliable Services 和 Reliable Actors 编程模型提供了一组性能计数器。 如果使用其中的任一模型,这些性能计数器可以提供信息,以帮助确保执行组件正常启动和停止,或者以足够快的速度处理可靠服务请求。 有关详细信息,请参阅 Reliable Services 远程处理的监视和 Reliable Actors 的性能监视。
用于收集这些内容的 Azure Monitor 解决方案是 Azure Monitor 日志,就像平台级别监控一样。 应使用 Log Analytics 代理以收集相应的性能计数器,并在 Azure Monitor 日志中查看它们。
建议的安装程序
现已了解监视和示例场景的每个区域,以下是 Azure 监视工具的摘要以及监视上述所有区域所需的设置。
- 使用 Application Insights 监视的应用程序
- 使用诊断代理和 Azure Monitor 日志监视的群集
- 使用 Azure Monitor 日志进行基础结构监视
此外,还可使用并修改位于此处的示例 ARM 模板以自动部署所有必要的资源和代理。
其他日志记录解决方案
尽管我们推荐的解决方案 Application Insights 内置了与 Service Fabric 的集成,但许多事件会通过 ETW 提供程序写出,并且可随其他日志记录解决方案一起扩展。 此外,还应考虑 Elastic Stack(尤其是考虑在脱机环境中运行群集时)、Dynatrace 或其他任何偏好的平台。 我们在此处提供了一个可用的集成合作伙伴列表。
选择任何平台时都应考虑的关键点包括:用户界面的舒适度、查询功能的舒适度、可用的自定义可视化效果和仪表板、平台提供的用于增强监视体验的其他工具。
后续步骤
若要开始检测应用程序,请参阅应用程序级别事件和日志生成。
通过在 Service Fabric 上监视和诊断 ASP.NET Core 应用程序,完成为应用程序设置 Application Insights 的步骤。
在平台级别事件和日志生成中详细了解如何监视平台以及 Service Fabric 提供的事件。
在为群集设置 Azure Monitor 日志中配置与 Service Fabric 的 Azure Monitor 日志集成
在诊断常见方案中查看 Service Fabric 的示例诊断问题和解决方案
在 Service Fabric 诊断合作伙伴中查看与 Service Fabric 集成的其他诊断产品