当你运行 Azure Service Fabric 群集时,最好是从一个中心位置的所有节点中收集日志。 将日志放在中心位置可帮助分析和排查群集中的问题,或该群集中运行的应用程序与服务的问题。
上传和收集日志的方式之一是使用可将日志上传到 Azure 存储、也能选择发送日志到 Azure Application Insights 或事件中心的 Azure 诊断 (WAD) 扩展。 也可以使用外部进程读取存储中的事件,并将其放在分析平台产品(例如 Azure Monitor 日志或其他日志分析解决方案)中。
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 若要开始,请参阅安装 Azure PowerShell。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
警告
不再支持用于 Service Fabric SDK 的 Application Insights。
先决条件
本文中使用了以下工具:
Service Fabric 平台事件
Service Fabric 提供了一些 默认的日志记录通道,其中以下通道已通过扩展预先配置,以便将监视和诊断数据发送到存储表或其他位置:
- 操作事件:Service Fabric 平台执行的较高级别的操作。 示例包括创建应用程序和服务、节点状态更改和升级信息。 这些会以 Windows 事件跟踪 (ETW) 日志的形式发出
- Reliable Actors 编程模型事件
- Reliable Services 编程模型事件
通过门户部署诊断扩展
收集日志的第一个步骤是将诊断扩展部署在 Service Fabric 群集中的每个虚拟机规模集节点上。 诊断扩展将收集每个 VM 上的日志,并将它们上传到指定的存储帐户。 以下步骤概述了如何通过 Azure 门户和 Azure 资源管理器模板为新的和现有的群集完成此操作。
在通过 Azure 门户创建群集过程中部署诊断扩展
创建群集时,在群集配置步骤中,展开可选设置并确保将“诊断”设置为“打开” (默认设置)。
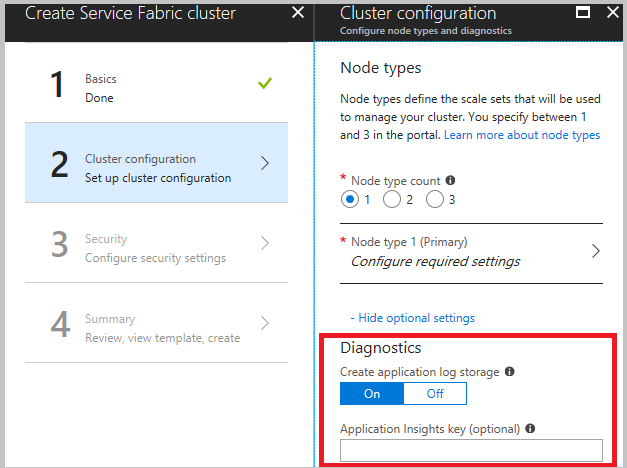
强烈建议在最终步骤中单击“创建”之前下载模板。 有关详细信息,请参阅使用 Azure Resource Manager 模板设置 Service Fabric 群集。 需要使用该模板来更改要从(上面列出的)哪些通道来收集数据。
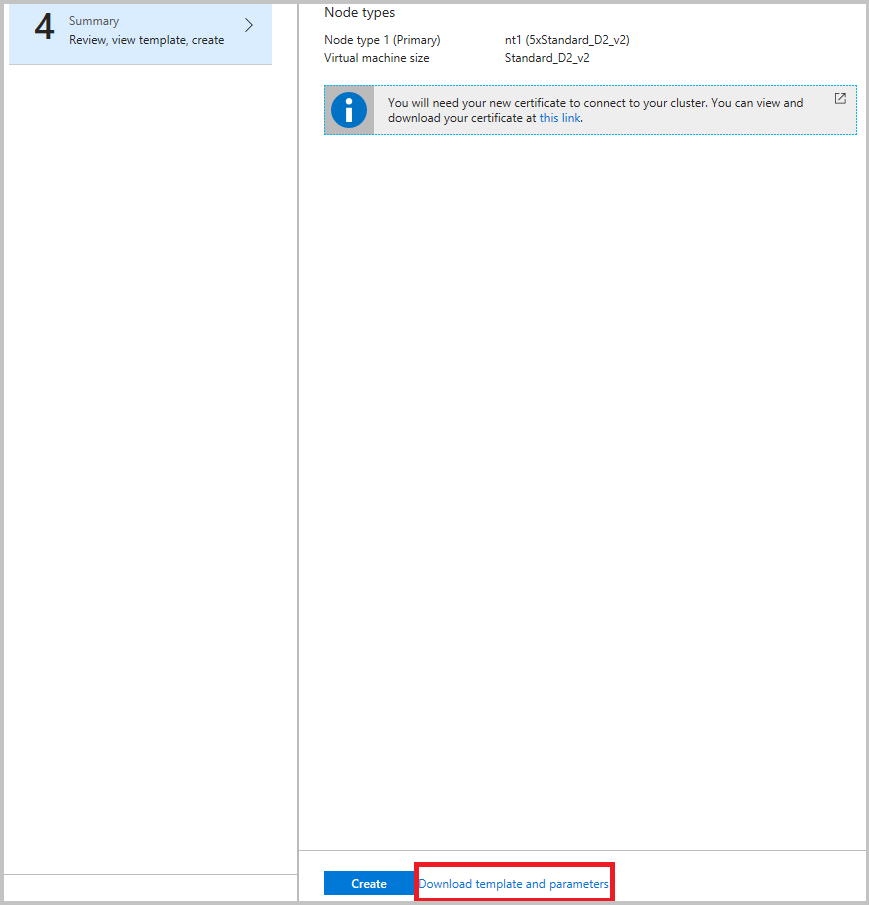
现在,你要在 Azure 存储中聚合事件,可设置 Azure Monitor 日志来获取见解并在 Azure Monitor 门户中查询它们
注意
当前没有办法过滤或整理发送到表格的事件。 如果不实现从表中删除事件的过程,该表将继续增长(默认上限为 50 GB)。 本文的下文中进一步说明了如何对此进行更改。 此外,还有一个在 Watchdog 示例中运行的数据整理服务示例,建议你也为自己编写一个服务,除非有充分的理由将日志存储在 30 或 90 天时间范围内。
通过 Azure 资源管理器部署诊断扩展
创建包含诊断扩展的群集
若要使用资源管理器创建群集,需要将诊断配置 JSON 添加到整个资源管理器模板。 我们为一个五 VM 的群集提供了一个资源管理器模板,并在演示资源管理器模板示例的过程中添加了诊断配置。 可以在 Azure 示例库中的此位置看到它。具有诊断资源管理器的五节点群集的模板示例。
若要查看 Resource Manager 模板中的诊断设置,请打开 azuredeploy.json 文件并搜索 IaaSDiagnostics。 若要使用此模板创建群集,请选择在上面的链接中提供的“部署到 Azure” 按钮。
或者,也可以下载 Resource Manager 示例,进行更改,并在 Azure PowerShell 窗口中输入 New-AzResourceGroupDeployment 命令,使用修改后的模板创建群集。 有关要在命令中传入的参数,请参阅以下代码。 有关如何使用 PowerShell 部署资源组的详细信息,请参阅使用 Azure Resource Manager 模板部署资源组一文。
向现有群集添加诊断扩展
如果存在尚未部署诊断的现有群集,可以通过群集模板来添加或更新该扩展。 修改用于创建现有群集的 Resource Manager 模板,或者如前所述从门户下载该模板。 执行以下任务来修改 template.json 文件:
通过将新存储资源添加到 resources 节将其添加到模板。
{
"apiVersion": "2018-07-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "[parameters('applicationDiagnosticsStorageAccountName')]",
"location": "[parameters('computeLocation')]",
"sku": {
"name": "[parameters('applicationDiagnosticsStorageAccountType')]"
"tier": "standard"
},
"tags": {
"resourceType": "Service Fabric",
"clusterName": "[parameters('clusterName')]"
}
},
接下来,将该资源添加到存储帐户定义后面与 supportLogStorageAccountName 之间的 parameters 节中。 将占位符文本 storage account name goes here 替换为所需的存储帐户的名称。
"applicationDiagnosticsStorageAccountType": {
"type": "string",
"allowedValues": [
"Standard_LRS",
"Standard_GRS"
],
"defaultValue": "Standard_LRS",
"metadata": {
"description": "Replication option for the application diagnostics storage account"
}
},
"applicationDiagnosticsStorageAccountName": {
"type": "string",
"defaultValue": "**STORAGE ACCOUNT NAME GOES HERE**",
"metadata": {
"description": "Name for the storage account that contains application diagnostics data from the cluster"
}
},
然后,通过在 extensions 数组中添加以下代码更新 template.json 文件的 VirtualMachineProfile 节。 请务必根据插入位置,在开头或末尾添加逗点。
{
"name": "[concat(parameters('vmNodeType0Name'),'_Microsoft.Insights.VMDiagnosticsSettings')]",
"properties": {
"type": "IaaSDiagnostics",
"autoUpgradeMinorVersion": true,
"protectedSettings": {
"storageAccountName": "[parameters('applicationDiagnosticsStorageAccountName')]",
"storageAccountKey": "[listKeys(resourceId('Microsoft.Storage/storageAccounts', parameters('applicationDiagnosticsStorageAccountName')),'2015-05-01-preview').key1]",
"storageAccountEndPoint": "https://core.chinacloudapi.cn/"
},
"publisher": "Microsoft.Azure.Diagnostics",
"settings": {
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
"StorageAccount": "[parameters('applicationDiagnosticsStorageAccountName')]"
},
"typeHandlerVersion": "1.5"
}
}
如上所述修改 template.json 文件后,请重新发布 Resource Manager 模板。 如果已导出模板,则运行 deploy.ps1 文件会重新发布模板。 部署后,请确保 ProvisioningState 为 Succeeded。
提示
如果您要将容器部署到群集,请在 WadCfg > DiagnosticMonitorConfiguration 部分添加此项以启用WAD,以采集docker统计数据。
"DockerSources": {
"Stats": {
"enabled": true,
"sampleRate": "PT1M"
}
},
更新存储配额
由于由该扩展填充的表将不断增大,直至达到配额,因此可能需要考虑减小配额大小。 默认值为 50 GB,可以在模板中在 overallQuotaInMB 下的 DiagnosticMonitorConfiguration 字段下进行配置。
"overallQuotaInMB": "50000",
日志收集配置
来自其他通道的日志也可供收集。 对于 Azure 中运行的群集,下面提供了你可以在其模板中进行的一些最常见配置。
操作通道 - 基本:默认情况下启用,由 Service Fabric 和群集执行的高级操作,包括出现节点事件、部署新应用程序或升级回滚等。有关事件的列表,请参阅操作通道事件。
"scheduledTransferKeywordFilter": "4611686018427387904"操作通道 - 详细:这包括运行状况报告和负载均衡决策,加上基本操作通道中的所有内容。 这些事件由系统或代码使用 ReportPartitionHealth 或 ReportLoad 等运行状况或加载报告 API 生成。 要在 Visual Studio 的诊断事件查看器中查看这些事件,请将“Microsoft-ServiceFabric:4:0x4000000000000008”添加到 ETW 提供程序列表。
"scheduledTransferKeywordFilter": "4611686018427387912"数据和消息通道 - 基本:消息(当前仅限 ReverseProxy)和数据路径中生成的关键日志和事件,以及详细操作通道日志。 这些事件是请求处理失败和 ReverseProxy 中的其他严重问题以及已处理的请求。 这是我们针对全面日志记录的建议。 若要在 Visual Studio 的诊断事件查看器中查看这些事件,请将“Microsoft-ServiceFabric:4:0x4000000000000010”添加到 ETW 提供程序列表。
"scheduledTransferKeywordFilter": "4611686018427387928"数据和消息通道 - 详细:此详细通道包含集群中数据和消息的所有非关键日志,以及详细的操作通道。 有关对所有反向代理事件的详细故障排除,请参阅反向代理诊断指南。 若要在 Visual Studio 的诊断事件查看器中查看这些事件,请将“Microsoft-ServiceFabric:4:0x4000000000000020”添加到 ETW 提供程序列表。
"scheduledTransferKeywordFilter": "4611686018427387944"
注意
此通道具有大量事件,通过此详细通道启用事件收集会导致快速生成许多跟踪,并且可以使用存储容量。 仅在必要时启用此功能。
若要启用“基本操作通道”(建议启用以获得干扰最少的全面日志记录),模板的 中的 EtwManifestProviderConfiguration 将如下所示 :
"WadCfg": {
"DiagnosticMonitorConfiguration": {
"overallQuotaInMB": "50000",
"EtwProviders": {
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
{
"provider": "Microsoft-ServiceFabric-Services",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableServiceEventTable"
}
}
],
"EtwManifestProviderConfiguration": [
{
"provider": "cbd93bc2-71e5-4566-b3a7-595d8eeca6e8",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
},
{
"provider": "02d06793-efeb-48c8-8f7f-09713309a810",
"scheduledTransferLogLevelFilter": "Information",
"scheduledTransferKeywordFilter": "4611686018427387904",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricSystemEventTable"
}
}
]
}
}
},
从新的 EventSource 通道收集
若要将诊断更新为从新的 EventSource 通道(表示要部署的新应用程序)收集日志,请执行之前描述的相同的步骤,其中描述了现有群集的诊断设置。
在使用 EtwEventSourceProviderConfiguration PowerShell 命令应用配置更新之前,请更新 template.json 文件中的 New-AzResourceGroupDeployment 节,添加新 EventSource 通道的条目。 事件源的名称定义为 Visual Studio 生成的 ServiceEventSource.cs 文件中代码的一部分。
例如,如果事件源名为 My-Eventsource,请添加以下代码,将来自 My-Eventsource 的事件放入名为 MyDestinationTableName 的表中。
{
"provider": "My-Eventsource",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "MyDestinationTableName"
}
}
若要收集性能计数器或事件日志,请参考使用 Azure 资源管理器模板创建具有监视和诊断功能的 Windows 虚拟机中提供的示例修改资源管理器模板。 然后,重新发布资源管理器模板。
收集性能计数器
若要从群集中收集性能指标,请将性能计数器添加到群集的资源管理器模板中的“WadCfg > DiagnosticMonitorConfiguration”。 有关修改 以收集特定性能计数器的步骤,请参阅WadCfg。 有关我们建议收集的性能计数器的列表,请参考性能指标。
如果使用 Application Insights 接收器,如以下部分所述,并且希望这些指标显示在 Application Insights 中,请确保在“接收器”部分中添加接收器名称,如上所示。 这将自动向你的 Application Insights 资源发送单独配置的性能计数器。
将日志发送到 Application Insights
使用 WAD 配置 Application Insights
警告
不再支持用于 Service Fabric SDK 的 Application Insights。
可通过两种方式将数据从 WAD 发送到 Azure Application Insights,这一过程是通过向 WAD 配置添加 Application Insights 接收器实现的,不管是通过 Azure 门户还是通过 Azure 资源管理器模板。
在 Azure 门户中创建群集时添加 Application Insights 检测密钥
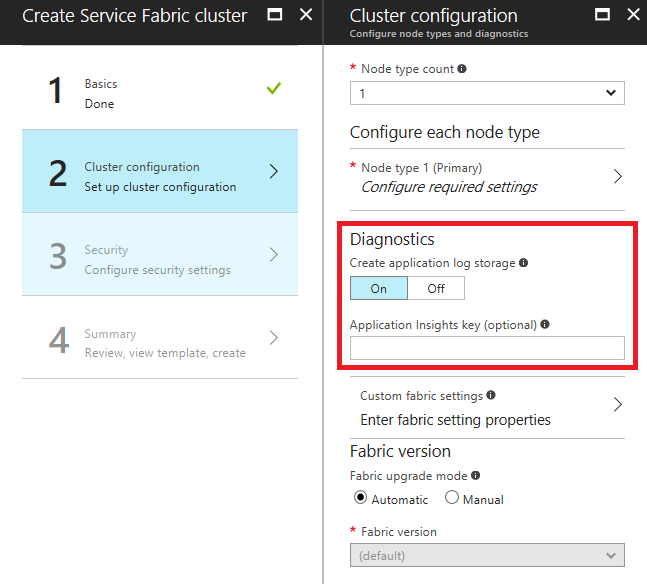
创建群集时,如果诊断处于“打开”状态,则输入 Application Insights 检测密钥的可选字段会显示。 如果在此处粘贴 Application Insights 密钥,则系统会在用于部署群集的资源管理器模板中自动配置 Application Insights 接收器。
将 Application Insights 接收器添加到资源管理器模板
在 Resource Manager 模板的“WadCfg”中,通过包含以下两项更改来添加“接收器”:
在声明完
DiagnosticMonitorConfiguration后,直接添加接收器配置:"SinksConfig": { "Sink": [ { "name": "applicationInsights", "ApplicationInsights": "***ADD INSTRUMENTATION KEY HERE***" } ] }在
DiagnosticMonitorConfiguration中添加接收器,具体方法是在DiagnosticMonitorConfiguration的WadCfg中添加以下代码行(紧靠声明的EtwProviders前面):"sinks": "applicationInsights"
在上面的两个代码片段中,名称“applicationInsights”用于描述接收器。 不一定非要使用此名称;只要将接收器包含在“sinks”中,就可以将名称设置为任何字符串。
目前,群集中的日志在 Application Insights 日志查看器中显示为跟踪。 由于来自平台的大部分跟踪信息都是“参考”级别,因此,还可以考虑将接收器配置更改为只发送类型为“警告”或“错误”的日志。此操作可通过将“通道”添加到接收器完成,如本文所示。
注意
如果在门户或资源管理器模板中使用错误的 Application Insights 密钥,则必须手动更改密钥并更新/重新部署群集。
后续步骤
正确配置 Azure 诊断后,将看到来自 ETW 和 EventSource 日志的存储表中的数据。 如果选择使用 Azure Monitor 日志、Kibana 或其他不在资源管理器模板中直接配置的任何数据分析和可视化平台,请确保设置所选平台以读入这些存储表中的数据。 对于 Azure Monitor 日志这样做相对简单,事件和日志分析中有相关介绍。 Application Insights 则有点特殊,由于它可以被配置为诊断扩展配置中的一部分,所以如果选择使用 AI 请参考相应的文章。
注意
目前没有任何方法可以筛选或清理已发送到表的事件。 如果未实施某个过程从表中删除事件,该表会不断增大。 目前,在监视器示例中有一个运行数据整理服务的示例,建议为自己编写一个,除非有需要存储超过 30 或 90 天日志的的理由。