本文介绍如何使用 Log Ingestion API 将 Azure Synapse Analytics 中的 Apache Spark 诊断数据发送到 Azure Log Analytics 目标。
Azure Synapse Apache Spark 诊断输出提供了统一的配置模型,用于向所有受支持的目标收集 Spark 诊断数据。 对于Azure Log Analytics,建议使用日志引入 API。
本文介绍如何配置发出器属性、将 Apache Spark 日志、事件日志和指标路由到Log Analytics,以及如何查询引入的数据以进行监视和故障排除。
从数据收集器 API 迁移
如果当前正在 Azure Synapse Analytics 中使用 HTTP 数据收集器 API,请迁移到 日志引入 API,以符合最新的 Azure Monitor 引入体系结构和最佳做法。
新模型中的关键更改:
- 架构定义通过 数据收集规则(DCR)显式定义,与以前的自由格式有效负载方法相比,提供可预测的架构验证和更一致的查询结果。
- 引入流通过 数据收集终结点(DCE) 和 DCR 映射进行路由,提供比将数据直接发布到数据收集器 API 终结点更受控且更可靠的引入路径。
- 身份验证同时支持使用 客户端密码 的服务主体身份验证和 基于证书的身份验证。
- 发出器类型从
AzureLogAnalytics更改为AzureLogIngestion. - 迁移通常涉及创建 DCR 和 DCE 资源、更新 Azure Synapse Apache Spark 池配置(例如 Spark 配置或诊断设置),以及验证数据已成功引入到 Azure Log Analytics 中的自定义表中。
日志引入 API 概述
对于 Azure Synapse Analytics 中的 Apache Spark 诊断,日志引入 API 提供结构化引入模型,用于将身份验证、架构定义、路由和数据传送到 Azure Log Analytics。
关键组件
| 组件 | Purpose |
|---|---|
| 应用注册凭据 | 提供用于通过客户端机密或证书来验证 Log Ingestion API 请求的 Microsoft Entra 应用标识。 |
| Log Analytics的表 | 提供存储用于查询和监控的已摄取 Spark 诊断信息的目标自定义表。 |
| 数据收集规则 (DCR) | 定义用于引入的输入流、架构映射和可选转换。 |
| 数据收集终结点 (DCE) | 提供客户端用于通过基于 DCR 的路由发送数据的引入终结点 URI(dceUri)。 |
只有为日志引入 API 配置的用户创建的 DCR 可用于编程引入。
分步配置
步骤 1。 准备 Log Analytics 工作区
需要 Log Analytics 工作区才能接收 Spark 诊断。 它是 Azure Monitor Logs 的基本存储和查询单元。
如果你没有,请在 Azure 门户中创建一个 Log Analytics 工作区。
重要
完成以下步骤后,在 Log Analytics 工作区所在的同一区域中创建数据收集终结点(DCE)和数据收集规则(DCR)资源。
步骤 2。 创建数据收集终结点 (DCE)
在 Azure 门户中创建数据收集终结点(DCE)。 DCE 提供在 Spark 属性中为日志引入 API 配置的终结点 URI。 DCE 的区域必须与 Log Analytics 工作区的区域相同。
用户可以根据需要根据自己的方案创建一个或多个表类型,logseventsmetrics并且每个表类型都有自己的相应的 DCR 配置和流名称。 仅创建和配置实际需要的表类型。
在 Azure 门户中,转到左侧导航窗格中的 Monitor。
在 “设置”下,选择 “数据收集终结点”,然后选择“ 创建”。
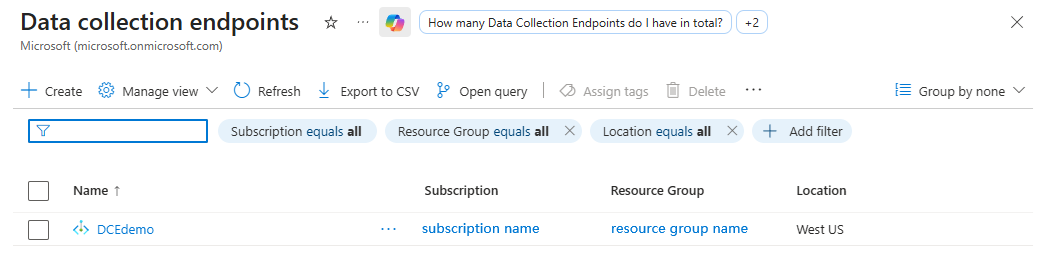
创建终结点,然后记下 DCE 名称(例如
DCEdemo)。

步骤 3。 准备示例 JSON 架构
创建自定义日志表时,必须配置数据收集规则(DCR)。 根据 DCR 中指定的数据流定义,系统会在 Log Analytics 工作区中自动生成相应的表架构。
以下预定义的 JSON 架构示例分别映射到特定的数据类型。 下载适合你的方案的示例,并在创建关联的自定义表和 DCR 时上传它。
- Spark 事件日志 - 事件表 JSON 架构示例
- Spark 驱动程序和执行程序日志 - 日志表 JSON 架构示例
- Spark 指标 - 指标表 JSON 架构示例
步骤 4. 创建自定义表 (直接引入)
使用 Log Ingestion API 选项在 Log Analytics 工作区中创建自定义表,并将 JSON 架构示例上传到关联的 DCR。 必须执行此步骤才能设置 Spark 诊断的目标,并确保引入的数据符合预期架构。 为了成功引入,Log Analytics 工作区、DCE 和 DCR 的区域必须相同。
在 Azure 门户中,打开Log Analytics工作区(例如,loganalyticsworkspacedemo)。
选择“创建表>”。
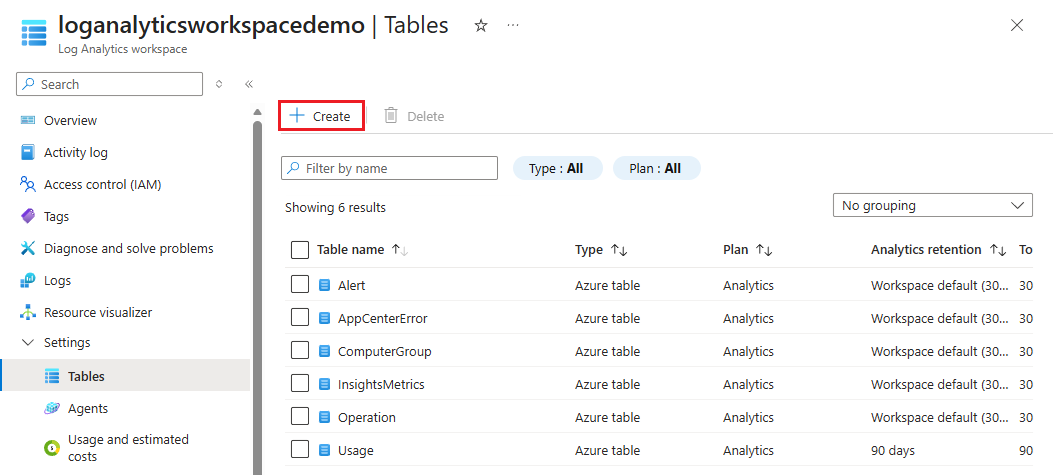
输入表设置:
- 表名称:例如,SparkLogTest(会自动添加后缀“_CL”)。
- 表格计划:分析
- 数据收集规则:创建新的 DCR(例如 SparkLogTestrule)。
- 数据收集终结点:从 “创建数据收集终结点”步骤( 例如 DCEdemo)中选择 DCE。
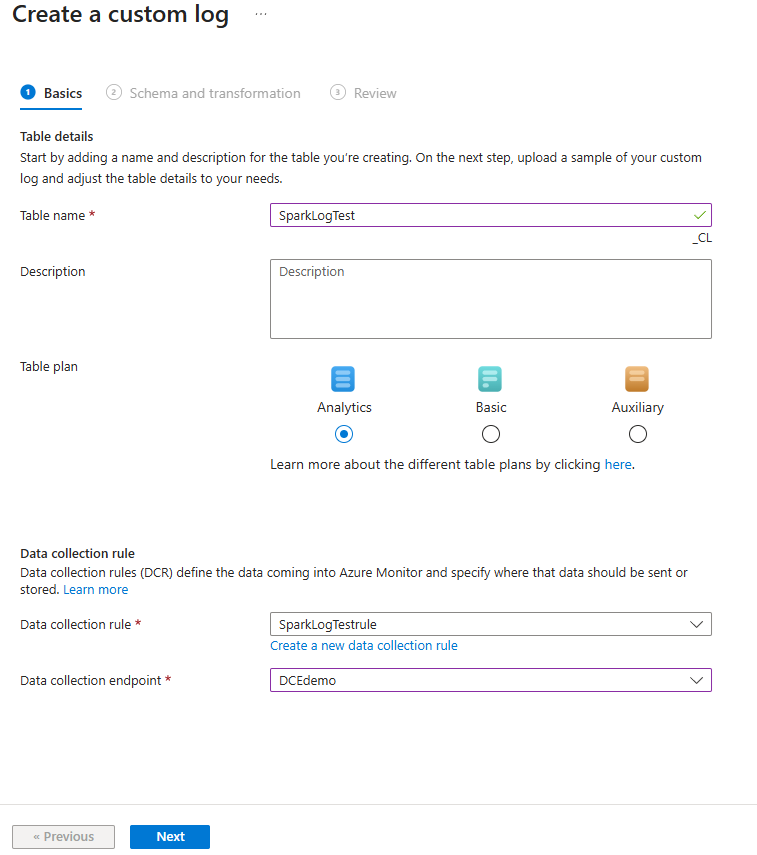
选择“下一步”。
在 架构和转换中,上传 JSON 架构示例。 无需配置 DCR 转换,因为架构在客户端上完全稳定。


步骤 5. 准备服务主体并收集 DCR 标识符
在 Microsoft Entra ID 中注册应用。

记录 TenantId、 ClientId 和 ClientSecret (如果使用客户端机密身份验证)。 在步骤 6 的 Spark 配置中使用这些值。
在每个表的 DCR 资源上为应用授予 监控指标发布者 角色。 关于角色分配步骤,请参阅使用 Azure 门户分配 Azure 角色。
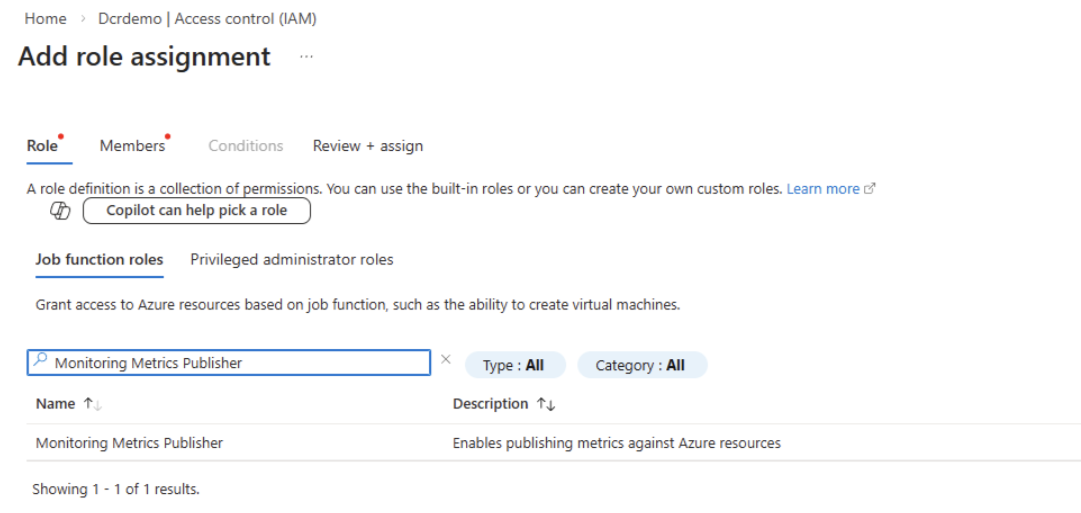
检索 流名称和DCR ID。 您可以从 Azure 门户中 数据收集规则 (DCR) 资源的 JSON 视图中,检索您创建的每个表的 DCR ID 和 流名称。
流名称格式始终为:
Custom-<Log Analytics table name>。 例如,如果表名称为AppLogs_CL,则流名称将为:Custom-AppLogs_CL在下一步中,你将使用这些流名称在 Spark 配置中配置相应的
logStream、eventStreammetricStream值和 logDcr、eventDcr、metricDcr 值。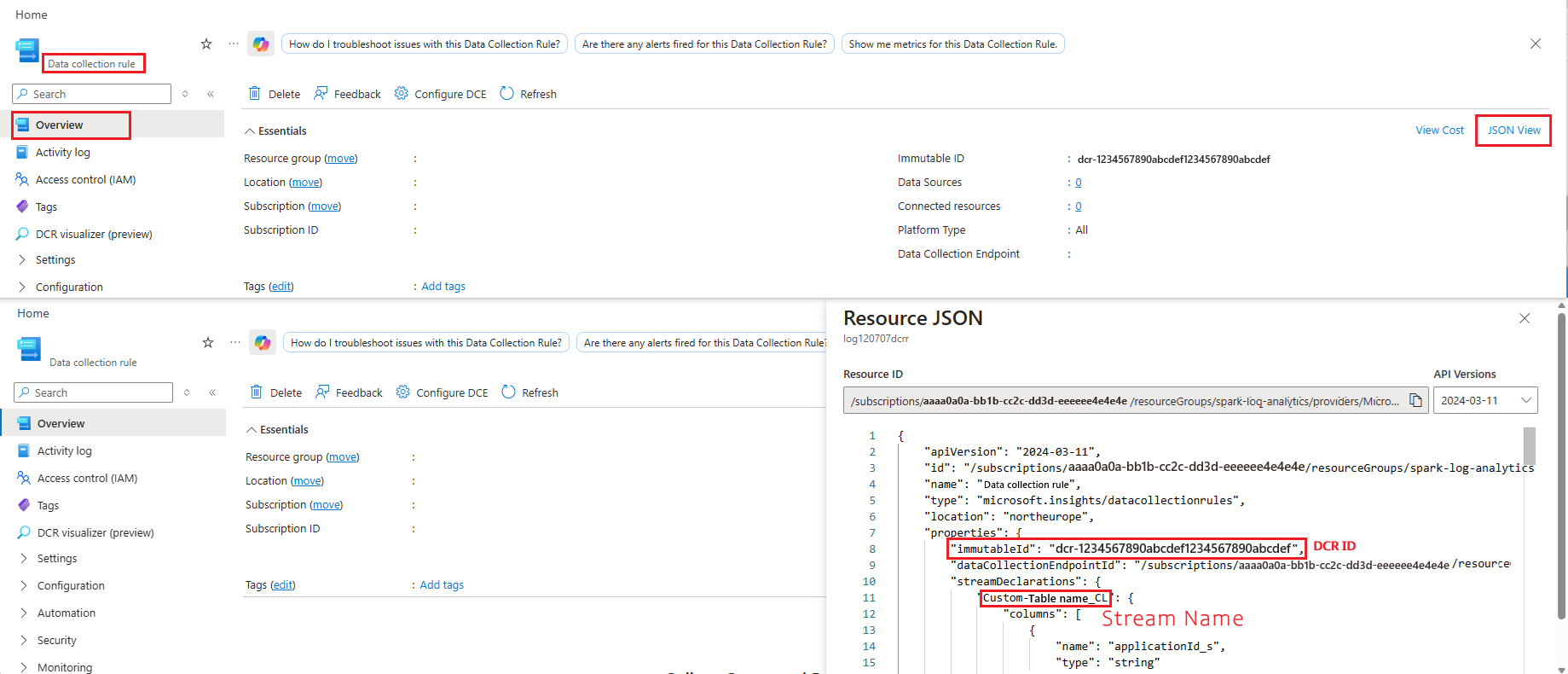



步骤 6。 配置 Spark 属性
若要配置 Spark,请在Azure Synapse Analytics中创建 Apache Spark 配置,并选择以下身份验证选项之一。 只对给定的发射器使用一个选项。
Azure Synapse Analytics 中的 Apache Spark 配置用于存储笔记本和 Spark 作业定义在运行时使用的 Spark 设置和库。 有关创建步骤,请参阅 “管理 Apache Spark 配置”。
- 如果希望使用客户端机密进行更简单的设置,请选择选项 1。
- 如果你的组织需要在 Azure 密钥保管库 中使用基于证书的身份验证和集中式证书管理,请选择选项 2。
- 如果使用基于证书的身份验证,并且想要通过 Synapse 链接服务从Azure 密钥保管库检索证书(工作区 MSI 访问密钥保管库),请选择选项 3。
在任一选项中,都可以单击“ 导入 ”按钮快速加载配置 YAML 文件。
选项 1:使用服务主名称和客户端密钥进行配置
使用此选项快速设置服务主体凭据和客户端密码。
创建 Apache Spark 配置。
将具有相应值的以下 Spark 属性 添加到环境项目,或选择功能区中的 “导入 ”以下载已包含所需属性 的示例 yaml 文件。
spark.synapse.diagnostic.emitters: <EMITTER_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.cn spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID> spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret: <SP_CLIENT_SECRET>保存并发布更改。
选项 2:使用服务主体证书身份验证进行配置
当你的组织需要基于证书的身份验证时,请使用此选项。
在开始之前,请确保使用证书创建服务主体。 有关详细信息,请参阅 使用 Azure CLI 创建包含证书的服务主体。
创建 Apache Spark 配置。
将具有相应值的以下 Spark 属性 添加到环境项目,或选择功能区中的 “导入 ”以下载已包含所需属性 的示例 yaml 文件。
spark.synapse.diagnostic.emitters: "<EMITTER_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: "AzureLogIngestion" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: "DriverLog,ExecutorLog,EventLog,Metrics" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: "https://<DCE_NAME>.<REGION>.ingest.monitor.azure.cn" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: "<LOG_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: "<LOG_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: "<EVENT_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: "<EVENT_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: "<METRIC_DCR_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: "<METRIC_STREAM_NAME>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: "<SP_TENANT_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: "<SP_CLIENT_ID>" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: "https://<KEYVAULT_NAME>.vault.azure.cn/" spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: "<SP_CERT_NAME>"保存并发布更改。
选项 3:使用链接服务进行配置
注释
在此选项中,您需要向工作区托管身份授予读取证书的权限。 有关详细信息,请参阅使用 Azure 基于角色的访问控制提供对密钥保管库密钥、证书和机密的访问权限。
若要在 Synapse Studio 中配置密钥保管库链接服务以存储服务主体证书,请执行以下步骤:
执行上一个部分(选项 2)中的所有步骤。
在 Synapse Studio 中创建密钥保管库链接服务:
a. 转到 Synapse Studio>Manage>Linked services,然后选择New。
b. 在搜索框中,搜索 Azure 密钥保管库。
c. 输入链接服务的名称。
d. 选择密钥保管库,然后选择“ 创建”。
将
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService项添加到 Apache Spark 配置。将具有相应值的以下 Spark 属性 添加到 spark 配置,或选择功能区中的 “导入 ”以下载已包含所需属性 的示例 yaml 文件。
spark.synapse.diagnostic.emitters: <EMITTER_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type: AzureLogIngestion
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories: DriverLog,ExecutorLog,EventLog,Metrics
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri: https://<DCE_NAME>.<REGION>.ingest.monitor.azure.cn
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr: <LOG_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream: <LOG_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr: <EVENT_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream: <EVENT_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr: <METRIC_DCR_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream: <METRIC_STREAM_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId: <SP_TENANT_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId: <SP_CLIENT_ID>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault: https://<KEYVAULT_NAME>.vault.azure.cn/
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName: <SP_CERT_NAME>
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService: <AZURE_KEY_VAULT_LINKED_SERVICE>
有关 Apache Spark 配置的列表,请参阅 可用的 Apache Spark 配置
步骤 7. 将 Apache Spark 配置附加到笔记本或 Spark 作业定义,或将其设置为工作区默认值
根据范围使用以下方法之一:
- 需要目标推出、测试或按项控制时,将 Apache Spark 配置附加到特定的笔记本或 Spark 作业定义。
- 如果希望跨工作区应用一致的 Spark 诊断设置,请将 Apache Spark 配置设置为工作区默认值。
若要将配置应用到笔记本或 Spark 作业定义,请执行以下操作:
- 在 Azure Synapse Analytics Studio 中,转到你的笔记本或 Spark 作业定义。
- 选择或配置与笔记本或 Spark 作业定义关联的 Apache Spark 目标池。
- 确保所需的 Spark 配置(例如,日志引入设置)应用于 Apache Spark 池或会话。
- 启动或运行 Spark 会话,使配置生效。
若要在工作区或 Apache Spark 池级配置相关设置,请执行以下操作:
- 在 Azure Synapse Studio 中导航至“管理”。
- 转到 Apache Spark 池并选择目标 Apache Spark 池。
- 配置所需的 Spark 设置(例如诊断或日志引入相关属性)。
- 保存配置。 这些设置将应用于在此池中创建的所有新 Spark 会话。
步骤 8。 提交 Apache Spark 应用程序并查看日志和指标
操作方法如下:
将 Apache Spark 应用程序提交到上一步中配置的 Apache Spark 池。 可以使用以下任何一个方法来实现此操作:
- 在 Synapse Studio 中运行笔记本。
- 在 Synapse Studio 中,通过 Apache Spark 作业定义提交一个 Apache Spark 批处理作业。
- 运行包含 Apache Spark 活动的管道。
转到指定的 Log Analytics 工作区,然后在 Apache Spark 应用程序开始运行时查看应用程序指标和日志。
编写自定义应用程序日志
可以使用 Apache Log4j 库编写自定义日志。
Scala 的示例:
%%spark
val logger = org.apache.log4j.LogManager.getLogger("com.contoso.LoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
//log exception
try {
1/0
} catch {
case e:Exception =>logger.warn("Exception", e)
}
// run job for task level metrics
val data = sc.parallelize(Seq(1,2,3,4)).toDF().count()
PySpark 的示例:
%%pyspark
logger = sc._jvm.org.apache.log4j.LogManager.getLogger("com.contoso.PythonLoggerExample")
logger.info("info message")
logger.warn("warn message")
logger.error("error message")
使用 Kusto 查询数据
下面是查询 Apache Spark 事件的示例:
SparkEventTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and Event_s== "EventName"
| order by TimeGenerated desc
| limit 100
下面是查询 Apache Spark 应用程序驱动程序和执行程序日志的示例:
SparkLogTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and Message contains "SampleMessage"
| order by TimeGenerated desc
| limit 100
下面是查询 Apache Spark 指标的示例:
SparkMetricsTest_CL
| where workspaceName_s == "{SynapseWorkspace}" and name_s== "{MetricsName}"
| order by TimeGenerated desc
| limit 100
创建和管理警报
用户可以进行查询,以按设置的频率评估指标和日志,并根据结果触发警报。 有关详细信息,请参阅使用 Azure Monitor 创建、查看和管理日志警报。
启用了数据外泄防护功能的 Synapse 工作区
创建 Synapse 工作区并启用 数据外泄保护 后。
若要启用此功能,需要在工作区批准的Microsoft Entra租户中创建Azure Monitor专用链接范围(AMPLS)的托管专用终结点连接请求。
可以按照以下步骤创建到 Azure Monitor 专用链接范围 (AMPLS) 的托管专用终结点连接:
- 如果没有现有的 AMPLS,可按照 Azure Monitor 专用链接连接设置创建一个。
- 在 Azure 门户中导航到 AMPLS,在 Azure Monitor Resources 页上,选择 Add 以将连接添加到Azure Log Analytics工作区。
- 转到 Synapse Studio > 管理 > 托管专用终结点,选择 新建 按钮,选择 Azure Monitor 专用链接范围,然后 继续。
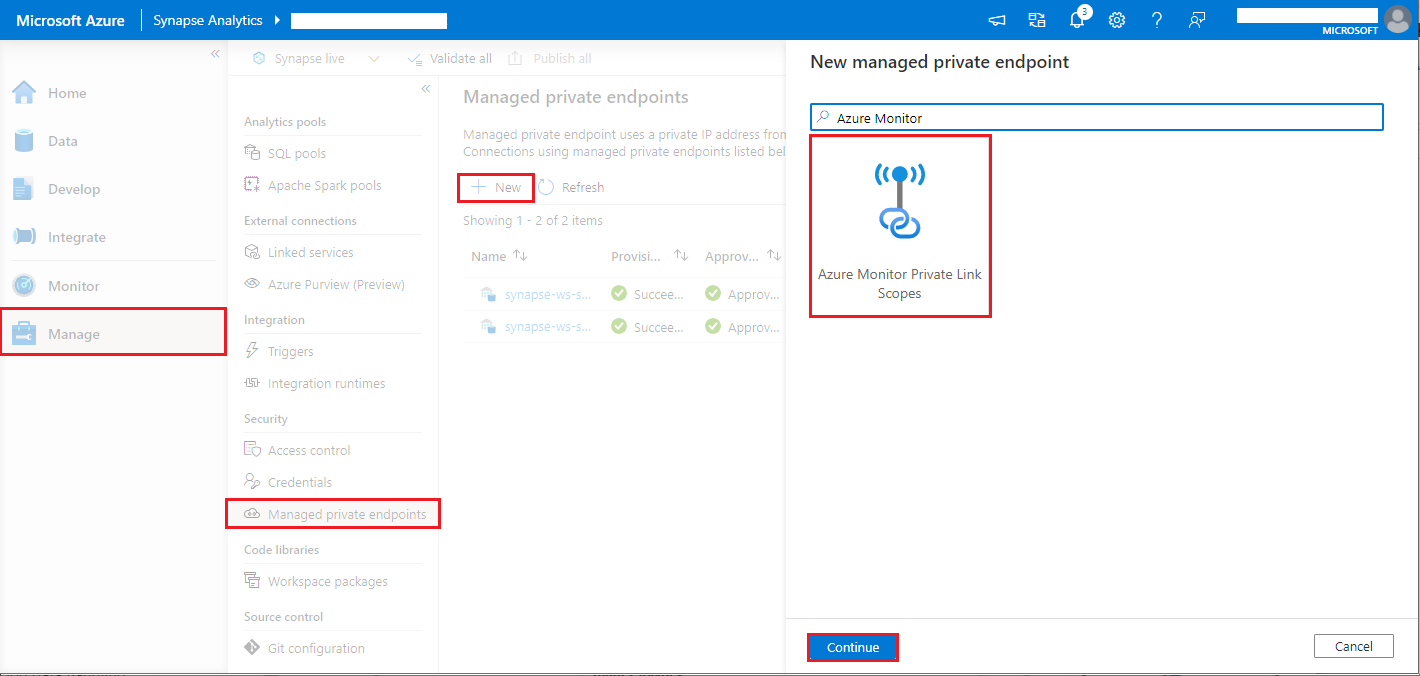
- 选择创建的 Azure Monitor 专用链接范围,然后选择“创建”按钮。
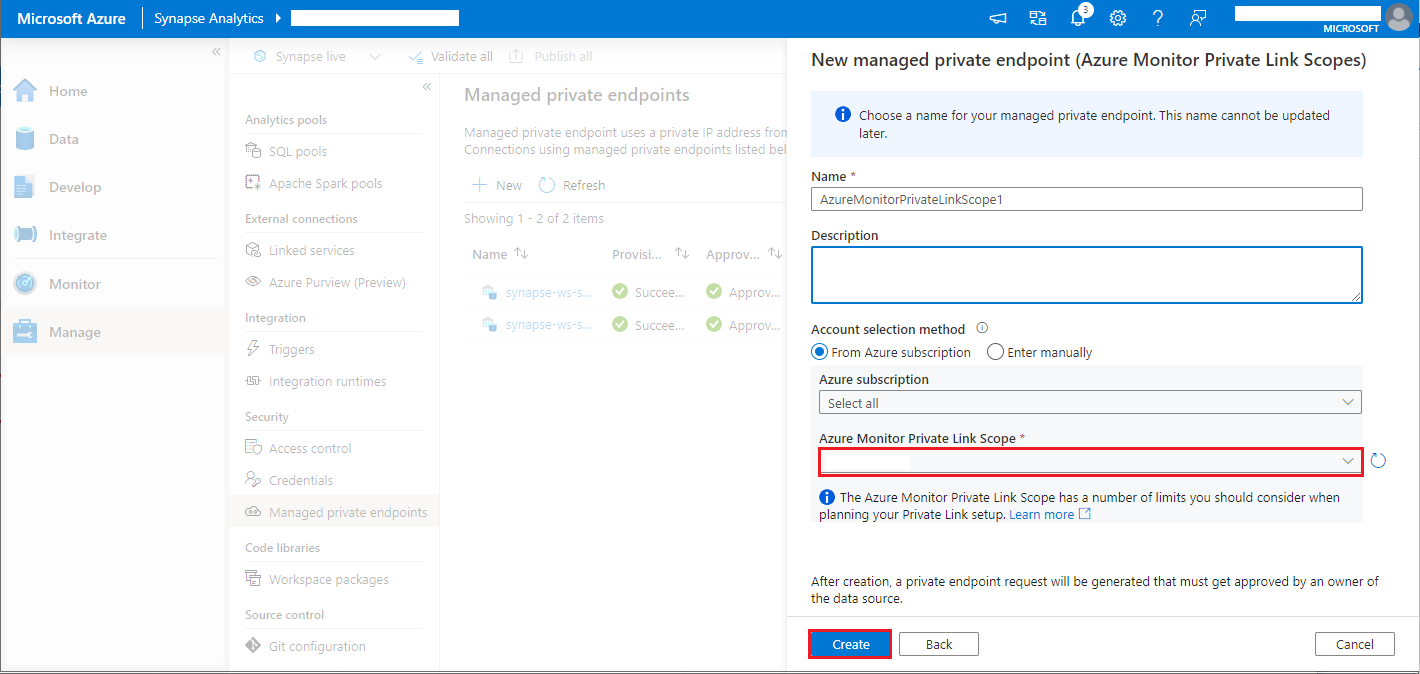
- 等待几分钟,以完成专用终结点预配。
- 再次导航到 Azure 门户中的 AMPLS,在专用终结点连接页上,选择已预配的连接,然后单击批准。
可用的配置
| 配置 | 说明 |
|---|---|
spark.synapse.diagnostic.emitters |
诊断发射器的目标地址名称以逗号分隔。 例如,MyDest1,MyDest2。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.type |
内置目标类型。 若要通过日志引入 API 启用 Azure Log Analytics,请将此值设置为 AzureLogIngestion。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.categories |
以逗号分隔的选定日志类别。 可用的值包括 DriverLog、ExecutorLog、EventLog、Metrics。 如果未设置,则默认值为所有类别。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.dceUri |
通过数据收集规则(DCR)路由数据时用于引入的数据收集终结点 (DCE) URI。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logDcr |
用于将 Spark 日志路由到目标的 Data Collection Rule (DCR) 资源 ID。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.logStream |
在 Spark 日志的数据收集规则(DCR)中定义的流名称。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventDcr |
用于路由 Spark 事件日志的数据收集规则 (DCR) 资源 ID。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.eventStream |
在 Spark 事件日志的数据收集规则(DCR)中定义的流名称。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricDcr |
用于路由 Spark 指标的 DCR(数据收集规则)资源 ID。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.metricStream |
在 Spark 指标的数据收集规则(DCR)中定义的流名称。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.tenantId |
用于身份验证的 Microsoft Entra 租户 ID。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.clientId |
Microsoft Entra ID 中注册的客户端(应用程序)ID。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.secret |
与Microsoft Entra ID应用程序关联的客户端密码,与租户 ID 和客户端 ID 一起使用,以便在发送诊断数据时对发出器进行身份验证。 此设置与基于证书的身份验证互斥-配置客户端密码或证书,但不能同时配置这两者。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault |
存储身份验证证书的Azure 密钥保管库 URI。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.certificateName |
存储在Azure 密钥保管库中用于身份验证的证书的名称。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.certificate.keyVault.linkedService |
Synapse 中 Azure 密钥保管库 链接服务的名称。 指定后,工作区托管标识使用此链接服务从Azure 密钥保管库检索证书。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.eventName.match |
逗号分隔的 Spark 侦听器事件名称;可以指定要收集的事件。 例如,SparkListenerApplicationStart,SparkListenerApplicationEnd。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.loggerName.match |
逗号分隔的 Log4j 记录器名称;可以指定要收集的日志。 例如,org.apache.spark.SparkContext,org.example.Logger。 |
spark.synapse.diagnostic.emitter.<EMITTER_NAME>.filter.metricName.match |
以逗号分隔的 Spark 指标名称后缀;您可以指定要收集哪些指标。 例如,jvm.heap.used。 |
注释
身份验证方式互斥:请配置 一种secret(纯文本)或 certificate.keyVault + certificate.keyVault.certificateName(可选配合 certificate.keyVault.linkedService 使用)。
日志引入目标secret从 Azure 密钥保管库 检索客户端(无论是否关联服务)。 如果需要将凭据保留在密钥保管库中,请使用基于证书的路径。