适用于: Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
Azure CLI ml 扩展 v2(当前版本)Python SDK azure-ai-ml v2(当前版本)
大数据需要一种服务,可以协调和实施过程,将这些巨大的原始数据存储转换为可操作的业务洞察。 Azure 数据工厂 托管的云服务可以处理这些复杂的混合提取-转换-加载 (ETL)、提取-加载-转换 (ELT) 和数据集成项目。
使用 Azure 数据工厂可以创建管道来协调多个数据转换并将其作为单个单元进行管理。 批处理终结点是这类处理工作流中的理想步骤。
本文介绍如何凭借 Web 调用活动和 REST API 在 Azure 数据工厂活动中使用批处理终结点。
提示
在 Fabric 中使用数据管道时,可以使用 Azure 机器学习活动直接调用批处理终结点。 尽量使用 Fabric 进行数据编排,以充分利用最新功能。 Azure 数据工厂中的 Azure 机器学习活动只能处理 Azure 机器学习 V1 中的资产。
先决条件
一个部署为批处理终结点的模型。 使用在批处理部署中使用 MLflow 模型所创建的心脏病分类器。
一个 Azure 数据工厂资源。 若要创建数据工厂,请按照快速入门:使用 Azure 门户创建数据工厂中的步骤操作。
创建数据工厂后,在 Azure 门户中浏览到该数据工厂,然后选择“启动工作室”:


对批处理终结点进行身份验证
Azure 数据工厂可以使用 Web 调用活动来调用批处理终结点的 REST API。 Batch 终结点支持用于授权的 Microsoft Entra ID,并且向 API 发出的请求需要正确的身份验证处理。 有关详细信息,请参阅 Azure 数据工厂和 Azure Synapse Analytics 中的 Web 活动。
可以使用服务主体或托管标识对批处理终结点进行身份验证。 使用托管标识,因为它简化了机密的使用。
可以使用 Azure 数据工厂托管标识来与批处理终结点通信。 在这种情况下,只需确保已使用托管标识部署 Azure 数据工厂资源。
关于管道
在此示例中,你将在 Azure 数据工厂中创建一个管道,该管道可以针对某些数据调用给定的批处理终结点。 管道使用 REST 与 Azure 机器学习批处理终结点通信。 有关如何使用批处理终结点的 REST API 的详细信息,请阅读为批处理终结点创建作业和输入数据。
该管道如下所示:

该管道包含以下活动:
运行批处理终结点:一个 Web 活动,使用批处理终结点 URI 来调用该终结点。 它将传递数据所在的输入数据 URI 和预期输出文件。
等待作业:这是一个循环活动,用于检查已创建作业的状态并等待其完成,完成后将显示为“已完成”或“失败”。 此活动使用以下活动:
- 检查状态:这是一个 Web 活动,用于查询在“运行批处理终结点”活动中作为响应返回的作业资源状态。
- 等待:一个等待活动,用于控制作业状态的轮询频率。 默认值为 120(2 分钟)。
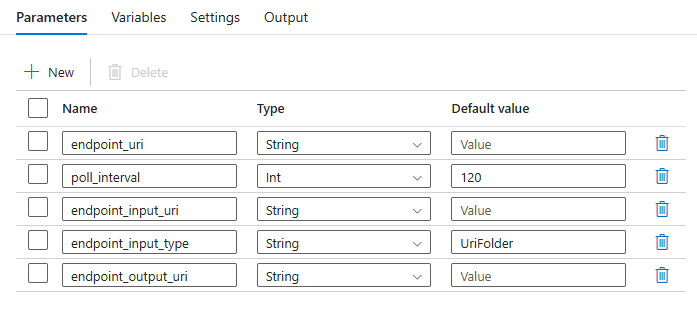
需要为管道配置以下参数:
| 参数 | 说明 | 示例值 |
|---|---|---|
endpoint_uri |
端点评分 URI | https://<endpoint_name>.<region>.inference.studio.ml.azure.cn/jobs |
poll_interval |
等待检查作业已完成状态所需的秒数。 默认为 120。 |
120 |
endpoint_input_uri |
终结点的输入数据。 支持多个数据输入类型。 确保用于执行作业的托管标识有权访问基础位置。 或者,如果使用数据存储,请确保已在其中注明凭据。 | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
要提供的输入数据的类型。 目前,批处理终结点支持文件夹 (UriFolder) 和文件 (UriFile)。 默认为 UriFolder。 |
UriFolder |
endpoint_output_uri |
终结点的输出数据文件。 它必须是连接到机器学习工作区的数据存储中的输出文件的路径。 不支持其他类型的 URI。 可以使用名为 workspaceblobstore 的默认 Azure 机器学习数据存储。 |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

警告
请记住,endpoint_output_uri 应是尚不存在的文件的路径。 否则,作业将失败,并显示“路径已存在”错误。
创建管道
若要在现有 Azure 数据工厂中创建此管道并调用批处理终结点,请执行以下步骤:
确保运行批处理终结点的计算资源有权限挂载由 Azure 数据工厂作为输入提供的数据。 调用终结点的实体仍会授予访问权限。
在这种情况下,Azure 数据工厂是调用终结点的实体。 但是,运行批处理终结点的计算需要具有装载 Azure 数据工厂提供的存储帐户的权限。 有关详细信息,请参阅访问存储服务。
打开 Azure 数据工厂工作室。 选择铅笔图标以打开作者窗格,然后在工厂资源下选择加号。
选择“管道”>“从管道模板导入”。
将管道模板 .zip 文件下载到本地计算机,然后在导入对话框中将其选中。
管道的预览将显示在门户中。 选择“使用此模板” 。
为您创建的管道名称为Run-BatchEndpoint。
配置批处理部署的参数:
警告
在向批处理终结点提交作业之前,请确保为其配置了默认部署。 创建的管道将调用终结点。 需要创建和配置默认部署。
提示
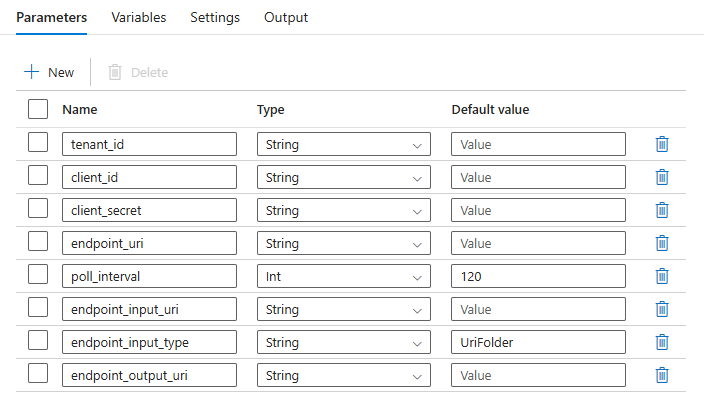
为了获得最佳可重用性,请使用创建的管道作为模板,并使用执行管道活动从其他 Azure 数据工厂管道内部调用它。 在这种情况下,请不要在内部管道中配置参数,而要将它们作为参数从外部管道传递,如下图所示:
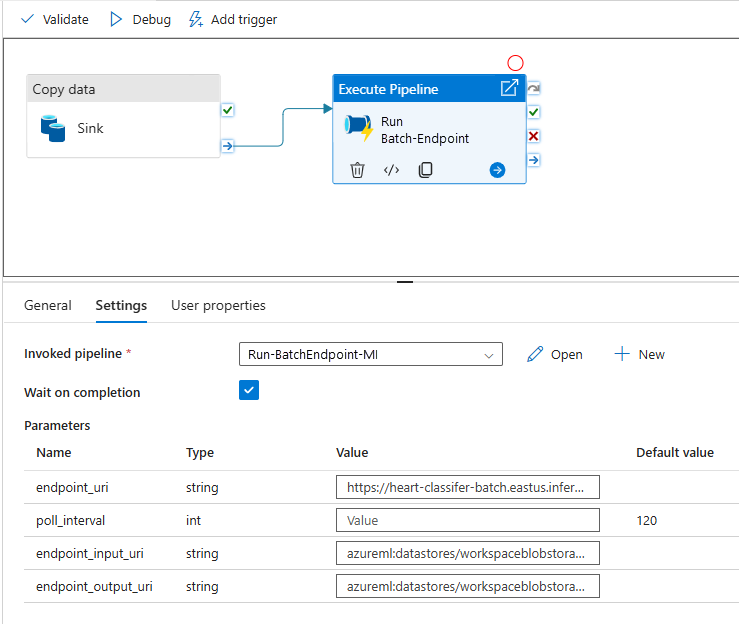
该管道现在可供使用。
限制
使用 Azure 机器学习批处理部署时,请考虑以下限制:
数据输入
- 仅支持 Azure 机器学习数据存储或 Azure 存储帐户(Azure Blob 存储、Azure Data Lake Storage Gen2)作为输入。 如果输入数据位于另一个源中,请在执行批处理作业之前使用 Azure 数据工厂复制活动将数据接收到兼容存储中。
- 批处理终结点作业无法浏览嵌套的文件夹。 它们不适用于嵌套的文件夹结构。 如果你的数据分布在多个文件夹中,则必须扁平化结构。
- 确保您在部署中提供的评分脚本可以处理符合作业期望的数据格式。 如果模型为 MLflow,请参阅在批处理部署中部署 MLflow 模型了解支持的文件类型的限制。
数据输出
- 仅支持已注册的 Azure 机器学习数据存储。 在 Azure 机器学习中注册 Azure 数据工厂用作数据存储的存储帐户。 使用这种方法,可以将数据写回正在读取的同一存储帐户。
- 仅支持 Azure Blob 存储帐户用于输出。 例如,批量部署作业不支持 Azure Data Lake Storage Gen2 作为输出。 如果需要将数据输出到其他位置或接收器,请在运行批处理作业后使用 Azure 数据工厂复制活动。