Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article contains information about how to troubleshoot the most frequent problems with serverless SQL pool in Azure Synapse Analytics.
To learn more about Azure Synapse Analytics, check the topics in the Overview.
Synapse Studio
Synapse Studio is an easy-to-use tool that you can use to access your data by using a browser without a need to install database access tools. Synapse Studio isn't designed to read a large set of data or full management of SQL objects.
Serverless SQL pool is grayed out in Synapse Studio
If Synapse Studio can't establish a connection to serverless SQL pool, you'll notice that serverless SQL pool is grayed out or shows the status Offline.
Usually, this problem occurs for one of two reasons:
- Your network prevents communication to the Azure Synapse Analytics back-end. The most frequent case is that TCP port 1443 is blocked. To get serverless SQL pool to work, unblock this port. Other problems could prevent serverless SQL pool from working too. For more information, see the Troubleshooting guide.
- You don't have permission to sign in to serverless SQL pool. To gain access, an Azure Synapse workspace administrator must add you to the workspace administrator role or the SQL administrator role. For more information, see Azure Synapse access control.
WebSocket connection closed unexpectedly
Your query might fail with the error message Websocket connection was closed unexpectedly. This message means that your browser connection to Synapse Studio was interrupted, for example, because of a network issue.
- To resolve this issue, rerun your query.
- Try the MSSQL extension for Visual Studio Code or SQL Server Management Studio for the same queries instead of Synapse Studio for further investigation.
- If this message occurs often in your environment, get help from your network administrator. You can also check firewall settings, and check the Troubleshooting guide.
- If the issue continues, create a support ticket through the Azure portal.
Serverless databases aren't shown in Synapse Studio
If you don't see the databases that are created in serverless SQL pool, check to see if your serverless SQL pool started. If serverless SQL pool is deactivated, the databases won't show. Execute any query, for example, SELECT 1, on serverless SQL pool to activate it and make the databases appear.
Synapse Serverless SQL pool shows as unavailable
Incorrect network configuration is often the cause of this behavior. Make sure the ports are properly configured. If you use a firewall or private endpoints, check these settings too.
Finally, make sure the appropriate roles are granted and haven't been revoked.
Unable to create new database as the request will use the old/expired key
This error is caused by changing workspace customer managed key used for encryption. You can choose to re-encrypt all the data in the workspace with the latest version of the active key. To-re-encrypt, change the key in the Azure portal to a temporary key and then switch back to the key you wish to use for encryption. Learn here how to manage the workspace keys.
Synapse serverless SQL pool is unavailable after transferring a subscription to a different Microsoft Entra tenant
If you moved a subscription to another Microsoft Entra tenant, you might experience some issues with serverless SQL pool. Create a support ticket and Azure support will contact you to resolve the issue.
Storage access
If you get errors while you try to access files in Azure storage, make sure that you have permission to access data. You should be able to access publicly available files. If you try to access data without credentials, make sure that your Microsoft Entra identity can directly access the files.
If you have a shared access signature key that you should use to access files, make sure that you created a server-level or database-scoped credential that contains that credential. The credentials are required if you need to access data by using the workspace managed identity and custom service principal name (SPN).
Can't read, list, or access files in Azure Data Lake Storage
If you use a Microsoft Entra login without explicit credentials, make sure that your Microsoft Entra identity can access the files in storage. To access the files, your Microsoft Entra identity must have the Blob Data Reader permission, or permissions to List and Read access control lists (ACL) in ADLS. For more information, see Query fails because file can't be opened.
If you access storage by using credentials, make sure that your managed identity or SPN has the Data Reader or Contributor role or specific ACL permissions. If you used a shared access signature token, make sure that it has rl permission and that it hasn't expired.
If you use a SQL login and the OPENROWSET function without a data source, make sure that you have a server-level credential that matches the storage URI and has permission to access the storage.
Query fails because file can't be opened
If your query fails with the error File cannot be opened because it does not exist or it is used by another process and you're sure that both files exist and aren't used by another process, serverless SQL pool can't access the file. This problem usually happens because your Microsoft Entra identity doesn't have rights to access the file or because a firewall is blocking access to the file.
By default, serverless SQL pool tries to access the file by using your Microsoft Entra identity. To resolve this issue, you must have proper rights to access the file. The easiest way is to grant yourself a Storage Blob Data Contributor role on the storage account you're trying to query.
For more information, see:
- Microsoft Entra ID access control for storage
- Control storage account access for serverless SQL pool in Synapse Analytics
Alternative to Storage Blob Data Contributor role
Instead of granting yourself a Storage Blob Data Contributor role, you can also grant more granular permissions on a subset of files.
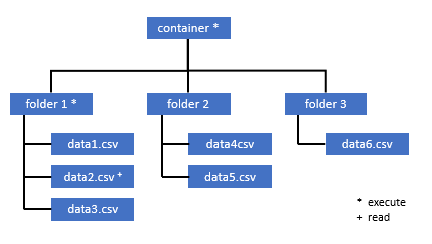
All users who need access to some data in this container also must have EXECUTE permission on all parent folders up to the root (the container).
Learn more about how to set ACLs in Azure Data Lake Storage Gen2.
Note
Execute permission on the container level must be set within Azure Data Lake Storage Gen2. Permissions on the folder can be set within Azure Synapse.
If you want to query data2.csv in this example, the following permissions are needed:
- Execute permission on container
- Execute permission on folder1
- Read permission on data2.csv
Sign in to Azure Synapse with an admin user that has full permissions on the data you want to access.
In the data pane, right-click the file and select Manage access.
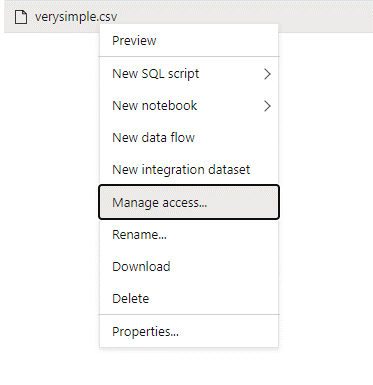
Select at least Read permission. Enter the user's UPN or object ID, for example,
user@contoso.com. Select Add.Grant read permission for this user.

Note
For guest users, this step needs to be done directly with Azure Data Lake because it can't be done directly through Azure Synapse.
Content of directory on the path can't be listed
This error indicates that the user who's querying Azure Data Lake can't list the files in storage. There are several scenarios where this error might happen:
- The Microsoft Entra user who's using Microsoft Entra pass-through authentication doesn't have permission to list the files in Data Lake Storage.
- The Microsoft Entra ID or SQL user who's reading data by using a shared access signature key or workspace managed identity and that key or identity doesn't have permission to list the files in storage.
- The user who's accessing Dataverse data who doesn't have permission to query data in Dataverse. This scenario might happen if you use SQL users.
- The user who's accessing Delta Lake might not have permission to read the Delta Lake transaction log.
The easiest way to resolve this issue is to grant yourself the Storage Blob Data Contributor role in the storage account you're trying to query.
For more information, see:
- Microsoft Entra ID access control for storage
- Control storage account access for serverless SQL pool in Synapse Analytics
Content of Dataverse table can't be listed
If you're using the Azure Synapse Link for Dataverse to read the linked DataVerse tables, you need to use Microsoft Entra account to access the linked data using the serverless SQL pool. For more information, see Azure Synapse Link for Dataverse with Azure Data Lake.
If you try to use a SQL login to read an external table that is referencing the DataVerse table, you'll get the following error: External table '???' is not accessible because content of directory cannot be listed.
Dataverse external tables always use Microsoft Entra passthrough authentication. You can't configure them to use a shared access signature key or workspace managed identity.
Content of Delta Lake transaction log can't be listed
The following error is returned when serverless SQL pool can't read the Delta Lake transaction log folder:
Content of directory on path 'https://.....core.chinacloudapi.cn/.../_delta_log/*.json' cannot be listed.
Make sure the _delta_log folder exists. Maybe you're querying plain Parquet files that aren't converted to Delta Lake format. If the _delta_log folder exists, make sure you have both Read and List permission on the underlying Delta Lake folders. Try to read json files directly by using FORMAT='csv'. Put your URI in the BULK parameter:
select top 10 *
from openrowset(BULK 'https://.....core.chinacloudapi.cn/.../_delta_log/*.json',FORMAT='csv', FIELDQUOTE = '0x0b', FIELDTERMINATOR ='0x0b',ROWTERMINATOR = '0x0b')
with (line varchar(max)) as logs
If this query fails, the caller doesn't have permission to read the underlying storage files.
Query execution
You might get errors during the query execution in the following cases:
- The caller can't access some objects.
- The query can't access external data.
- The query contains some functionalities that aren't supported in serverless SQL pools.
Query fails because it can't be executed due to current resource constraints
Your query might fail with the error message This query cannot be executed due to current resource constraints. This message means serverless SQL pool can't execute at this moment. Here are some troubleshooting options:
- Make sure data types of reasonable sizes are used.
- If your query targets Parquet files, consider defining explicit types for string columns because they'll be VARCHAR(8000) by default. Check inferred data types.
- If your query targets CSV files, consider creating statistics.
- To optimize your query, see Performance best practices for serverless SQL pool.
Query timeout expired
The error Query timeout expired is returned if the query executed more than 30 minutes on serverless SQL pool. This limit for serverless SQL pool can't be changed.
- Try to optimize your query by applying best practices.
- Try to materialize parts of your queries by using create external table as select (CETAS).
- Check if there's a concurrent workload running on serverless SQL pool because the other queries might take the resources. In that case, you might split the workload on multiple workspaces.
Invalid object name
The error Invalid object name 'table name' indicates that you're using an object, such as a table or view, that doesn't exist in the serverless SQL pool database. Try these options:
List the tables or views and check if the object exists. Use SQL Server Management Studio or Visual Studio Code, because Synapse Studio might show some tables that aren't available in serverless SQL pool.
If you see the object, check that you're using some case-sensitive/binary database collation. Maybe the object name doesn't match the name that you used in the query. With a binary database collation,
Employeeandemployeeare two different objects.If you don't see the object, maybe you're trying to query a table from a lake or Spark database. The table might not be available in the serverless SQL pool because:
- The table has some column types that can't be represented in serverless SQL pool.
- The table has a format that isn't supported in serverless SQL pool. Examples are Avro or ORC.
String or binary data would be truncated
This error happens if the length of your string or binary column type (for example VARCHAR, VARBINARY, or NVARCHAR) is shorter than the actual size of data that you are reading. You can fix this error by increasing the length of the column type:
- If your string column is defined as the
VARCHAR(32)type and the text is 60 characters, use theVARCHAR(60)type (or longer) in your column schema. - If you're using the schema inference (without the
WITHschema), all string columns are automatically defined as theVARCHAR(8000)type. If you're getting this error, explicitly define the schema in aWITHclause with the largerVARCHAR(MAX)column type to resolve this error. - If your table is in the Lake database, try to increase the string column size in the Spark pool.
- Try to
SET ANSI_WARNINGS OFFto enable serverless SQL pool to automatically truncate the VARCHAR values, if this won't impact your functionalities.
Unclosed quotation mark after the character string
In rare cases, where you use the LIKE operator on a string column or some comparison with the string literals, you might get the following error:
Unclosed quotation mark after the character string
This error might happen if you use the Latin1_General_100_BIN2_UTF8 collation on the column. Try to set Latin1_General_100_CI_AS_SC_UTF8 collation on the column instead of the Latin1_General_100_BIN2_UTF8 collation to resolve the issue. If the error is still returned, raise a support request through the Azure portal.
Couldn't allocate tempdb space while transferring data from one distribution to another
The error Could not allocate tempdb space while transferring data from one distribution to another is returned when the query execution engine can't process data and transfer it between the nodes that are executing the query. It's a special case of the generic query fails because it can't be executed due to current resource constraints error. This error is returned when the resources allocated to the tempdb database are insufficient to run the query.
Apply best practices before you file a support ticket.
Query fails with an error handling an external file (max errors count reached)
If your query fails with the error message error handling external file: Max errors count reached, it means that there's a mismatch of a specified column type and the data that needs to be loaded.
To get more information about the error and which rows and columns to look at, change the parser version from 2.0 to 1.0.
Example
If you want to query the file names.csv with this Query 1, Azure Synapse serverless SQL pool returns with the following error: Error handling external file: 'Max error count reached'. File/External table name: [filepath]. For example:
The names.csv file contains:
Id,first name,
1, Adam
2,Bob
3,Charles
4,David
5,Eva
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
)
AS [result]
Cause
As soon as the parser version is changed from version 2.0 to 1.0, the error messages help to identify the problem. The new error message is now Bulk load data conversion error (truncation) for row 1, column 2 (Text) in data file [filepath].
Truncation tells you that your column type is too small to fit your data. The longest first name in this names.csv file has seven characters. The according data type to be used should be at least VARCHAR(7). The error is caused by this line of code:
[Text] VARCHAR (1) COLLATE Latin1_General_BIN2
Changing the query accordingly resolves the error. After debugging, change the parser version to 2.0 again to achieve maximum performance.
For more information about when to use which parser version, see Use OPENROWSET using serverless SQL pool in Synapse Analytics.
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='2.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Text] VARCHAR (7) COLLATE Latin1_General_BIN2
)
AS [result]
Can't bulk load because the file couldn't be opened
The error Cannot bulk load because the file could not be opened is returned if a file is modified during the query execution. Usually, you might get an error like Cannot bulk load because the file {file path} could not be opened. Operating system error code 12. (The access code is invalid.)
The serverless SQL pools can't read files that are being modified while the query is running. The query can't take a lock on the files. If you know that the modification operation is append, you can try to set the following option: {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}.
For more information, see how to query append-only files or create tables on append-only files.
Query fails with data conversion error
Your query might fail with the error message Bulk load data conversion error (type mismatches or invalid character for the specified code page) for row n, column m [columnname] in the data file [filepath]. This message means your data types didn't match the actual data for row number n and column m.
For instance, if you expect only integers in your data, but in row n there's a string, this error message is the one you'll get.
To resolve this problem, inspect the file and the data types you chose. Also check if your row delimiter and field terminator settings are correct. The following example shows how inspecting can be done by using VARCHAR as the column type.
For more information on field terminators, row delimiters, and escape quoting characters, see Query CSV files.
Example
If you want to query the file names.csv:
Id, first name,
1,Adam
2,Bob
3,Charles
4,David
five,Eva
With the following query:
Query 1:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] SMALLINT,
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Azure Synapse serverless SQL pool returns the error Bulk load data conversion error (type mismatch or invalid character for the specified code page) for row 6, column 1 (ID) in data file [filepath].
It's necessary to browse the data and make an informed decision to handle this problem. To look at the data that causes this problem, the data type needs to be changed first. Instead of querying the ID column with the data type SMALLINT, VARCHAR(100) is now used to analyze this issue.
With this slightly changed Query 2, the data can now be processed to return the list of names.
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
You might observe that the data has unexpected values for ID in the fifth row. In such circumstances, it's important to align with the business owner of the data to agree on how corrupt data like this example can be avoided. If prevention isn't possible at the application level, reasonable-sized VARCHAR might be the only option here.
Tip
Try to make VARCHAR() as short as possible. Avoid VARCHAR(MAX) if possible because it can impair performance.
The query result doesn't look as expected
Your query might not fail, but you might see that your result set isn't as expected. The resulting columns might be empty or unexpected data might be returned. In this scenario, it's likely that a row delimiter or field terminator was incorrectly chosen.
To resolve this problem, take another look at the data and change those settings. Debugging this query is easy, as shown in the following example.
Example
If you want to query the file names.csv with the query in Query 1, Azure Synapse serverless SQL pool returns with a result that looks odd:
In names.csv:
Id,first name,
1, Adam
2, Bob
3, Charles
4, David
5, Eva
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =';',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
| ID | Firstname |
| ------------- |------------- |
| 1,Adam | NULL |
| 2,Bob | NULL |
| 3,Charles | NULL |
| 4,David | NULL |
| 5,Eva | NULL |
There seems to be no value in the column Firstname. Instead, all values ended up being in the ID column. Those values are separated by a comma. The problem was caused by this line of code because it's necessary to choose the comma instead of the semicolon symbol as field terminator:
FIELDTERMINATOR =';',
Changing this single character solves the problem:
FIELDTERMINATOR =',',
The result set created by Query 2 now looks as expected:
Query 2:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK '[FILE-PATH OF CSV FILE]',
FORMAT = 'CSV',
PARSER_VERSION='1.0',
FIELDTERMINATOR =',',
FIRSTROW = 2
)
WITH (
[ID] VARCHAR(100),
[Firstname] VARCHAR (25) COLLATE Latin1_General_BIN2
)
AS [result]
Returns:
| ID | Firstname |
| ------------- |------------- |
| 1 | Adam |
| 2 | Bob |
| 3 | Charles |
| 4 | David |
| 5 | Eva |
Column of type isn't compatible with external data type
If your query fails with the error message Column [column-name] of type [type-name] is not compatible with external data type […], it's likely that a PARQUET data type was mapped to an incorrect SQL data type.
For instance, if your Parquet file has a column price with float numbers (like 12.89) and you tried to map it to INT, this error message is the one you'll get.
To resolve this issue, inspect the file and the data types you chose. This mapping table helps to choose a correct SQL data type. As a best practice, specify mapping only for columns that would otherwise resolve into the VARCHAR data type. Avoiding VARCHAR when possible leads to better performance in queries.
Example
If you want to query the file taxi-data.parquet with this Query 1, Azure Synapse serverless SQL pool returns the following error:
The file taxi-data.parquet contains:
|PassengerCount |SumTripDistance|AvgTripDistance |
|---------------|---------------|----------------|
| 1 | 2635668.66000064 | 6.72731710678951 |
| 2 | 172174.330000005 | 2.97915543404919 |
| 3 | 296384.390000011 | 2.8991352022851 |
| 4 | 12544348.58999806| 6.30581582240281 |
| 5 | 13091570.2799993 | 111.065989028627 |
Query 1:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance INT,
AVGTripDistance FLOAT
)
AS [result]
Column 'SumTripDistance' of type 'INT' is not compatible with external data type 'Parquet physical type: DOUBLE', please try with 'FLOAT'. File/External table name: '<filepath>taxi-data.parquet'.
This error message tells you that data types aren't compatible and comes with the suggestion to use FLOAT instead of INT. The error is caused by this line of code:
SumTripDistance INT,
With this slightly changed Query 2, the data can now be processed and shows all three columns:
Query 2:
SELECT
*
FROM
OPENROWSET(
BULK '<filepath>taxi-data.parquet',
FORMAT='PARQUET'
) WITh
(
PassengerCount INT,
SumTripDistance FLOAT,
AVGTripDistance FLOAT
)
AS [result]
Query references an object that isn't supported in distributed processing mode
The error The query references an object that is not supported in distributed processing mode indicates that you've used an object or function that can't be used while you query data in Azure Storage or Azure Cosmos DB analytical storage.
Some objects, like system views, and functions can't be used while you query data stored in Azure Data Lake or Azure Cosmos DB analytical storage. Avoid using the queries that join external data with system views, load external data in a temp table, or use some security or metadata functions to filter external data.
WaitIOCompletion call failed
The error message WaitIOCompletion call failed indicates that the query failed while waiting to complete the I/O operation that reads data from the remote storage, Azure Data Lake.
The error message has the following pattern: Error handling external file: 'WaitIOCompletion call failed. HRESULT = ???'. File/External table name...
Make sure that your storage is placed in the same region as serverless SQL pool. Check the storage metrics and verify there are no other workloads on the storage layer, such as uploading new files, that could saturate I/O requests.
The field HRESULT contains the result code. The following error codes are the most common along with their potential solutions.
This error code means the source file isn't in storage.
There are reasons why this error code can happen:
- The file was deleted by another application.
- In this common scenario, the query execution starts, it enumerates the files, and the files are found. Later, during the query execution, a file is deleted. For example, it could be deleted by Databricks, Spark, or Azure Data Factory. The query fails because the file isn't found.
- This issue can also occur with the Delta format. The query might succeed on retry because there's a new version of the table and the deleted file isn't queried again.
- An invalid execution plan is cached.
- As a temporary mitigation, run the command
DBCC FREEPROCCACHE. If the problem persists, create a support ticket.
- As a temporary mitigation, run the command
Incorrect syntax near NOT
The error Incorrect syntax near 'NOT' indicates there are some external tables with columns that contain the NOT NULL constraint in the column definition.
- Update the table to remove NOT NULL from the column definition.
- This error can sometimes also occur transiently with tables created from a CETAS statement. If the problem doesn't resolve, you can try dropping and re-creating the external table.
Partition column returns NULL values
If your query returns NULL values instead of partitioning columns or can't find the partition columns, you have a few possible troubleshooting steps:
- If you use tables to query a partitioned dataset, tables don't support partitioning. Replace the table with the partitioned views.
- If you use the partitioned views with the OPENROWSET that queries partitioned files by using the FILEPATH() function, make sure you correctly specified the wildcard pattern in the location and used the proper index for referencing the wildcard.
- If you're querying the files directly in the partitioned folder, the partitioning columns aren't the parts of the file columns. The partitioning values are placed in the folder paths and not the files. For this reason, the files don't contain the partitioning values.
Insert value to batch for column type DATETIME2 failed
The error Inserting value to batch for column type DATETIME2 failed indicates that the serverless pool can't read the date values from the underlying files. The datetime value stored in the Parquet or Delta Lake file can't be represented as a DATETIME2 column.
Inspect the minimum value in the file by using Spark, and check that some dates are less than 0001-01-03. If you stored the files by using the higher Spark version that still uses legacy datetime storage format, the datetime values before are written by using the Julian calendar that isn't aligned with the proleptic Gregorian calendar used in serverless SQL pools.
There might be a two-day difference between the Julian calendar used to write the values in Parquet (in some Spark versions) and the proleptic Gregorian calendar used in serverless SQL pool. This difference might cause conversion to a negative date value, which is invalid.
Try to use Spark to update these values because they're treated as invalid date values in SQL. The following sample shows how to update the values that are out of SQL date ranges to NULL in Delta Lake:
from delta.tables import *
from pyspark.sql.functions import *
deltaTable = DeltaTable.forPath(spark,
"abfss://my-container@myaccount.dfs.core.chinacloudapi.cn/delta-lake-data-set")
deltaTable.update(col("MyDateTimeColumn") < '0001-02-02', { "MyDateTimeColumn": null } )
This change removes the values that can't be represented. The other date values might be properly loaded but incorrectly represented because there's still a difference between Julian and proleptic Gregorian calendars. You might see unexpected date shifts even for the dates before 1900-01-01 if you use Spark 3.0 or older versions.
Consider migrating to Spark 3.1 or higher and switching to the proleptic Gregorian calendar. The latest Spark versions use by default a proleptic Gregorian calendar that's aligned with the calendar in serverless SQL pool. Reload your legacy data with the higher version of Spark, and use the following setting to correct the dates:
spark.conf.set("spark.sql.legacy.parquet.int96RebaseModeInWrite", "CORRECTED")
Query failed because of a topology change or compute container failure
This error might indicate that some internal process issue happened in serverless SQL pool. File a support ticket with all necessary details that could help the Azure support team investigate the issue.
Describe anything that might be unusual compared to the regular workload. For example, perhaps there was a large number of concurrent requests or a special workload or query started executing before this error happened.
Wildcard expansion timed out
As described in the Query folders and multiple files section, Serverless SQL pool supports reading multiple files/folders by using wildcards. There's a maximum limit of 10 wildcards per query. You must be aware that this functionality comes at a cost. It takes time for the serverless pool to list all the files that can match the wildcard. This introduces latency and this latency can increase if the number of files you're trying to query is high. In this case you can run into the following error:
"Wildcard expansion timed out after X seconds."
There are several mitigation steps that you can do to avoid this:
- Apply best practices described in Best Practices Serverless SQL Pool.
- Try to reduce the number of files you're trying to query, by compacting files into larger ones. Try to keep your file sizes above 100 MB.
- Make sure that filters over partitioning columns are used wherever possible.
- If you're using delta file format, use the optimize write feature in Spark. This can improve the performance of queries by reducing the amount of data that needs to be read and processed. How to use optimize write is described in Using optimize write on Apache Spark.
- To avoid some of the top-level wildcards by effectively hardcoding the implicit filters over partitioning columns use dynamic SQL.
Missing column when using automatic schema inference
You can easily query files without knowing or specifying schema, by omitting WITH clause. In that case column names and data types will be inferred from the files. Have in mind that if you're reading number of files at once, the schema will be inferred from the first file service gets from the storage. This can mean that some of the columns expected are omitted, all because the file used by the service to define the schema did not contain these columns. To explicitly specify the schema, use OPENROWSET WITH clause. If you specify schema (by using external table or OPENROWSET WITH clause) default lax path mode will be used. That means that the columns that don't exist in some files will be returned as NULLs (for rows from those files). To understand how path mode is used, check the following documentation and sample.
Configuration
Serverless SQL pools enable you to use T-SQL to configure database objects. There are some constraints:
- You can't create objects in
masterandlakehouseor Spark databases. - You must have a master key to create credentials.
- You must have permission to reference data that's used in the objects.
Can't create a database
If you get the error CREATE DATABASE failed. User database limit has been already reached., you've created the maximal number of databases that are supported in one workspace. For more information, see Constraints.
- If you need to separate the objects, use schemas within the databases.
- If you need to reference Azure Data Lake storage, create lakehouse databases or Spark databases that will be synchronized in serverless SQL pool.
Creating or altering table failed because the minimum row size exceeds the maximum allowable table row size of 8060 bytes
Any table can have up to 8 KB size per row (not including off-row VARCHAR(MAX)/VARBINARY(MAX) data). If you create a table where the total size of cells in the row exceeds 8060 bytes, you'll get the following error:
Msg 1701, Level 16, State 1, Line 3
Creating or altering table '<table name>' failed because the minimum row size would be <???>,
including <???> bytes of internal overhead.
This exceeds the maximum allowable table row size of 8060 bytes.
This error also might happen in the Lake database if you create a Spark table with the column sizes that exceed 8060 bytes, and the serverless SQL pool can't create a table that references the Spark table data.
As a mitigation, avoid using the fixed size types like CHAR(N) and replace them with variable size VARCHAR(N) types, or decrease the size in CHAR(N). See 8 KB rows group limitation in SQL Server.
Create a master key in the database or open the master key in the session before performing this operation
If your query fails with the error message Please create a master key in the database or open the master key in the session before performing this operation., it means that your user database has no access to a master key at the moment.
Most likely, you created a new user database and haven't created a master key yet.
To resolve this problem, create a master key with the following query:
CREATE MASTER KEY [ ENCRYPTION BY PASSWORD ='strongpasswordhere' ];
Note
Replace 'strongpasswordhere' with a different secret here.
CREATE statement isn't supported in the master database
If your query fails with the error message Failed to execute query. Error: CREATE EXTERNAL TABLE/DATA SOURCE/DATABASE SCOPED CREDENTIAL/FILE FORMAT is not supported in master database., it means that the master database in serverless SQL pool doesn't support the creation of:
- External tables.
- External data sources.
- Database scoped credentials.
- External file formats.
Here's the solution:
Create a user database:
CREATE DATABASE <DATABASE_NAME>Execute a CREATE statement in the context of <DATABASE_NAME>, which failed earlier for the
masterdatabase.Here's an example of the creation of an external file format:
USE <DATABASE_NAME> CREATE EXTERNAL FILE FORMAT [SynapseParquetFormat] WITH ( FORMAT_TYPE = PARQUET)
Can't create Microsoft Entra login or user
If you get an error while you're trying to create a new Microsoft Entra login or user in a database, check the login you used to connect to your database. The login that's trying to create a new Microsoft Entra user must have permission to access the Microsoft Entra domain and check if the user exists. Be aware that:
- SQL logins don't have this permission, so you'll always get this error if you use SQL authentication.
- If you use a Microsoft Entra login to create new logins, check to see if you have permission to access the Microsoft Entra domain.
Azure Cosmos DB
Serverless SQL pools enable you to query Azure Cosmos DB analytical storage by using the OPENROWSET function. Make sure that your Azure Cosmos DB container has analytical storage. Make sure that you correctly specified the account, database, and container name. Also, make sure that your Azure Cosmos DB account key is valid. For more information, see Prerequisites.
Can't query Azure Cosmos DB by using the OPENROWSET function
If you can't connect to your Azure Cosmos DB account, look at the prerequisites. Possible errors and troubleshooting actions are listed in the following table.
| Error | Root cause |
|---|---|
| Syntax errors: - Incorrect syntax near OPENROWSET.- ... isn't a recognized BULK OPENROWSET provider option.- Incorrect syntax near .... |
Possible root causes: - Not using Azure Cosmos DB as the first parameter. - Using a string literal instead of an identifier in the third parameter. - Not specifying the third parameter (container name). |
| There was an error in the Azure Cosmos DB connection string. | - The account, database, or key isn't specified. - An option in a connection string isn't recognized. - A semicolon ( ;) is placed at the end of a connection string. |
| Resolving Azure Cosmos DB path has failed with the error "Incorrect account name" or "Incorrect database name." | The specified account name, database name, or container can't be found, or analytical storage hasn't been enabled to the specified collection. |
| Resolving Azure Cosmos DB path has failed with the error "Incorrect secret value" or "Secret is null or empty." | The account key isn't valid or is missing. |
UTF-8 collation warning is returned while reading Azure Cosmos DB string types
Serverless SQL pool returns a compile-time warning if the OPENROWSET column collation doesn't have UTF-8 encoding. You can easily change the default collation for all OPENROWSET functions running in the current database by using the T-SQL statement:
ALTER DATABASE CURRENT COLLATE Latin1_General_100_CI_AS_SC_UTF8;
Latin1_General_100_BIN2_UTF8 collation provides the best performance when you filter your data by using string predicates.
Missing rows in Azure Cosmos DB analytical store
Some items from Azure Cosmos DB might not be returned by the OPENROWSET function. Be aware that:
- There's a synchronization delay between the transactional and analytical store. The document you entered in the Azure Cosmos DB transactional store might appear in the analytical store after two to three minutes.
- The document might violate some schema constraints.
Query returns NULL values in some Azure Cosmos DB items
Azure Synapse SQL returns NULL instead of the values that you see in the transaction store in the following cases:
- There's a synchronization delay between the transactional and analytical store. The value that you entered in the Azure Cosmos DB transactional store might appear in the analytical store after two to three minutes.
- There might be a wrong column name or path expression in the WITH clause. The column name (or path expression after the column type) in the WITH clause must match the property names in the Azure Cosmos DB collection. Comparison is case sensitive. For example,
productCodeandProductCodeare different properties. Make sure that your column names exactly match the Azure Cosmos DB property names. - The property might not be moved to the analytical storage because it violates some schema constraints, such as more than 1,000 properties or more than 127 nesting levels.
- If you use well-defined schema representation, the value in the transactional store might have a wrong type. Well-defined schema locks the types for each property by sampling the documents. Any value added in the transactional store that doesn't match the type is treated as a wrong value and not migrated to the analytical store.
- If you use full-fidelity schema representation, make sure that you're adding the type suffix after the property name like
$.price.int64. If you don't see a value for the referenced path, maybe it's stored under a different type path, for example,$.price.float64. For more information, see Query Azure Cosmos DB collections in the full-fidelity schema.
Column isn't compatible with external data type
The error Column 'column name' of the type 'type name' is not compatible with the external data type 'type name'. is returned if the specified column type in the WITH clause doesn't match the type in the Azure Cosmos DB container. Try to change the column type as it's described in the section Azure Cosmos DB to SQL type mappings or use the VARCHAR type.
Resolve: Azure Cosmos DB path has failed with error
If you get the error Resolving Azure Cosmos DB path has failed with error 'This request is not authorized to perform this operation'. check to see if you used private endpoints in Azure Cosmos DB. To allow serverless SQL pool to access an analytical store with private endpoints, you must configure private endpoints for the Azure Cosmos DB analytical store.
Azure Cosmos DB performance issues
If you experience some unexpected performance issues, make sure that you applied best practices, such as:
- Make sure that you placed the client application, serverless pool, and Azure Cosmos DB analytical storage in the same region.
- Make sure that you use the WITH clause with optimal data types.
- Make sure that you use Latin1_General_100_BIN2_UTF8 collation when you filter your data by using string predicates.
- If you have repeating queries that might be cached, try to use CETAS to store query results in Azure Data Lake Storage.
Delta Lake
There are some limitations that you might see in Delta Lake support in serverless SQL pools:
- Make sure that you're referencing the root Delta Lake folder in the OPENROWSET function or external table location.
- The root folder must have a subfolder named
_delta_log. The query fails if there's no_delta_logfolder. If you don't see that folder, you're referencing plain Parquet files that must be converted to Delta Lake by using Apache Spark pools. - Don't specify wildcards to describe the partition schema. The Delta Lake query automatically identifies the Delta Lake partitions.
- The root folder must have a subfolder named
- Delta Lake tables that are created in the Apache Spark pools are automatically available in serverless SQL pool, but the schema isn't updated (public preview limitation). If you add columns in the Delta table using a Spark pool, the changes won't be shown in serverless SQL pool database.
- External tables don't support partitioning. Use partitioned views on the Delta Lake folder to use the partition elimination. See known issues and workarounds later in the article.
- Serverless SQL pools don't support time travel queries. Use Apache Spark pools in Synapse Analytics to read historical data.
- Serverless SQL pools don't support updating Delta Lake files. You can use serverless SQL pool to query the latest version of Delta Lake. Use Apache Spark pools in Synapse Analytics to update Delta Lake.
- You can't store query results to storage in Delta Lake format by using the CETAS command. The CETAS command supports only Parquet and CSV as the output formats.
- Serverless SQL pools in Synapse Analytics are compatible with Delta reader version 1.
- Serverless SQL pools in Synapse Analytics don't support the datasets with the BLOOM filter. The serverless SQL pool ignores the BLOOM filters.
- Delta Lake support isn't available in dedicated SQL pools. Make sure that you use serverless SQL pools to query Delta Lake files.
- For more information about known issues with serverless SQL pools, see Azure Synapse Analytics known issues.
Serverless support Delta 1.0 version
Serverless SQL pools are reading only Delta Lake 1.0 version. Serverless SQL pools is a Delta reader with level 1, and doesn't support the following features:
- Column mappings are ignored - serverless SQL pools will return original column names.
- Delete vectors are ignored and the old version of deleted/updated rows will be returned (possibly wrong results).
- The following Delta Lake features are not supported: V2 checkpoints, timestamp without timezone, VACUUM protocol check
Delete vectors are ignored
If your Delta lake table is configured to use Delta writer version 7, it will store deleted rows and old versions of updated rows in Delete Vectors (DV). Since serverless SQL pools have Delta reader 1 level, they'll ignore the delete vectors and probably produce wrong results when reading unsupported Delta Lake version.
Column rename in Delta table is not supported
The serverless SQL pool doesn't support querying Delta Lake tables with the renamed columns. Serverless SQL pool can't read data from the renamed column.
The value of a column in the Delta table is NULL
If you're using Delta data set that requires a Delta reader version 2 or higher, and uses the features that are unsupported in version 1 (for example - renaming columns, dropping columns, or column mapping), the values in the referenced columns might not be shown.
JSON text isn't properly formatted
This error indicates that serverless SQL pool can't read the Delta Lake transaction log. You'll probably see the following error:
Msg 13609, Level 16, State 4, Line 1
JSON text is not properly formatted. Unexpected character '' is found at position 263934.
Msg 16513, Level 16, State 0, Line 1
Error reading external metadata.
Make sure that your Delta Lake dataset isn't corrupted. Verify that you can read the content of the Delta Lake folder by using Apache Spark pool in Azure Synapse. This way you'll ensure that the _delta_log file isn't corrupted.
Workaround
Try to create a checkpoint on the Delta Lake dataset by using Apache Spark pool and rerun the query. The checkpoint aggregates transactional JSON log files and might solve the issue.
If the dataset is valid, create a support ticket and provide more information:
- Don't make any changes like adding or removing the columns or optimizing the table because this operation might change the state of the Delta Lake transaction log files.
- Copy the content of the
_delta_logfolder into a new empty folder. Do not copy the.parquet datafiles. - Try to read the content that you copied in the new folder and verify that you're getting the same error.
- Send the content of the copied
_delta_logfile to Azure support.
Now you can continue using the Delta Lake folder with Spark pool. You'll provide copied data to Microsoft support if you're allowed to share this information. The Azure team will investigate the content of the delta_log file and provide more information about possible errors and workarounds.
Resolve Delta logs failed
The following error indicates that serverless SQL pool can't resolve Delta logs: Resolving Delta logs on path '%ls' failed with error: Cannot parse json object from log folder.
The most common cause is that last_checkpoint_file in _delta_log folder is larger than 200 bytes due to the checkpointSchema field added in Spark 3.3.
There are two options available to circumvent this error:
- Modify appropriate config in Spark notebook and generate a new checkpoint, so that
last_checkpoint_filegets re-created. In case you're using Azure Databricks, the config modification is the following:spark.conf.set("spark.databricks.delta.checkpointSchema.writeThresholdLength", 0); - Downgrade to Spark 3.2.1.
Our engineering team is currently working on a full support for Spark 3.3.
Delta table created in Spark is not shown in serverless pool
Note
Replication of Delta tables that are created in Spark is still in public preview.
If you created a Delta table in Spark, and it isn't shown in the serverless SQL pool, check the following:
- Wait some time (usually 30 seconds) because the Spark tables are synchronized with delay.
- If the table didn't appear in the serverless SQL pool after some time, check the schema of the Spark Delta table. Spark tables with complex types or the types that aren't supported in serverless aren't available. Try to create a Spark Parquet table with the same schema in a lake database and check would that table appears in the serverless SQL pool.
- Check the workspace Managed Identity access Delta Lake folder that is referenced by the table. Serverless SQL pool uses workspace Managed Identity to get the table column information from the storage to create the table.
Lake database
The Lake database tables that are created using Spark or Synapse designer are automatically available in serverless SQL pool for querying. You can use serverless SQL pool to query the Parquet, CSV, and Delta Lake tables that are created using Spark pool, and add other schemas, views, procedures, table-value functions, and Microsoft Entra users in db_datareader role to your Lake database. Possible issues are listed in this section.
A table created in Spark is not available in serverless pool
Tables that are created might not be immediately available in serverless SQL pool.
- The tables will be available in serverless pools with some delay. You might need to wait 5-10 minutes after creation of a table in Spark to see it in serverless SQL pool.
- Only the tables that reference Parquet, CSV, and Delta formats are available in serverless SQL pool. Other table types aren't available.
- A table that contains some unsupported column types won't be available in serverless SQL pool.
- Accessing Delta Lake tables in Lake databases is in public preview. Check other issues listed in this section or in the Delta Lake section.
An external table created in Spark is showing unexpected results in serverless pool
It can happen that there's a mismatch between the source Spark external table and the replicated external table on the serverless pool. This can happen if the files used in creating Spark external tabless are without extensions. To get the proper results, make sure all files are with extensions such as .parquet.
Operation isn't allowed for a replicated database
This error is returned if you're trying to modify a Lake database, create external tables, external data sources, database scoped credentials or other objects in your Lake database. These objects can be created only on SQL databases.
The Lake databases are replicated from the Apache Spark pool and managed by Apache Spark. Therefore, you can't create objects like in SQL Databases by using T-SQL language.
Only the following operations are allowed in the Lake databases:
- Creating, dropping, or altering views, procedures, and inline table-value functions (iTVF) in the schemas other than
dbo. - Creating and dropping the database users from Microsoft Entra ID.
- Adding or removing database users from
db_datareaderschema.
Other operations aren't allowed in Lake databases.
Note
If you are creating a view, procedure, or function in dbo schema (or omitting schema and using the default one that is usually dbo), you will get the error message.
Delta tables in Lake databases are not available in serverless SQL pool
Make sure that your workspace Managed Identity has read access on the ADLS storage that contains Delta folder. The serverless SQL pool reads the Delta Lake table schema from the Delta logs that are placed in ADLS and uses the workspace Managed Identity to access the Delta transaction logs.
Try to set up a data source in some SQL Database that references your Azure Data Lake storage using Managed Identity credential, and try to create external table on top of data source with Managed Identity to confirm that a table with the Managed Identity can access your storage.
Delta tables in Lake databases do not have identical schema in Spark and serverless pools
Serverless SQL pools enable you to access Parquet, CSV, and Delta tables that are created in Lake database using Spark or Synapse designer. Accessing the Delta tables is still in public preview, and currently serverless will synchronize a Delta table with Spark at the time of creation but won't update the schema if the columns are added later using the ALTER TABLE statement in Spark.
This is a public preview limitation. Drop and re-create the Delta table in Spark (if it's possible) instead of altering tables to resolve this issue.
Query timeout or performance degradation on a table
When the original table in Spark or Dataverse is modified, the corresponding tables in the serverless pool are automatically recreated. This process results in the loss of existing statistics on the table. Without these statistics, queries on the table may experience delays or even timeouts.
If you encounter this issue, consider setting up a job to recreate statistics on the tables after changes in Spark/Dataverse or on a regular schedule.
Performance
Serverless SQL pool assigns the resources to the queries based on the size of the dataset and query complexity. You can't change or limit the resources that are provided to the queries. There are some cases where you might experience unexpected query performance degradations and you might have to identify the root causes.
Query duration is very long
If you have queries with a query duration longer than 30 minutes, the query slowly returning results to the client are slow. Serverless SQL pool has a 30-minute limit for execution. Any more time is spent on result streaming. Try the following workarounds:
- If you use Synapse Studio, try to reproduce the issues with some other application like SQL Server Management Studio or Visual Studio Code.
- If your query is slow when executed by using SQL Server Management Studio, Visual Studio Code, Power BI, or some other application, check networking issues and best practices.
- Put the query in the CETAS command and measure the query duration. The CETAS command stores the results to Azure Data Lake Storage and doesn't depend on the client connection. If the CETAS command finishes faster than the original query, check the network bandwidth between the client and serverless SQL pool.
Query is slow when executed by using Synapse Studio
If you use Synapse Studio, try using a desktop client such as SQL Server Management Studio or Visual Studio Code. Synapse Studio is a web client that connects to serverless SQL pool by using the HTTP protocol, which is generally slower than the native SQL connections used in SQL Server Management Studio or Visual Studio Code.
Query is slow when executed by using an application
Check the following issues if you experience slow query execution:
- Make sure that the client applications are collocated with the serverless SQL pool endpoint. Executing a query across the region can cause extra latency and slow streaming of result set.
- Make sure that you don't have networking issues that can cause the slow streaming of result set
- Make sure that the client application has enough resources (for example, not using 100% CPU).
- Make sure that the storage account or Azure Cosmos DB analytical storage is placed in the same region as your serverless SQL endpoint.
See best practices for collocating the resources.
High variations in query durations
If you're executing the same query and observing variations in the query durations, several reasons might cause this behavior:
- Check if this is the first execution of a query. The first execution of a query collects the statistics required to create a plan. The statistics are collected by scanning the underlying files and might increase the query duration. In Synapse Studio, you'll see the "global statistics creation" queries in the SQL request list that are executed before your query.
- Statistics might expire after some time. Periodically, you might observe an impact on performance because the serverless pool must scan and rebuild the statistics. You might notice another "global statistics creation" queries in the SQL request list that are executed before your query.
- Check if there's some workload that's running on the same endpoint when you executed the query with the longer duration. The serverless SQL endpoint equally allocates the resources to all queries that are executed in parallel, and the query might be delayed.
Connections
Serverless SQL pool enables you to connect by using the TDS protocol and by using the T-SQL language to query data. Most of the tools that can connect to SQL Server or Azure SQL Database can also connect to serverless SQL pool.
SQL pool is warming up
Following a longer period of inactivity, serverless SQL pool will be deactivated. The activation happens automatically on the first next activity, such as the first connection attempt. The activation process might take a bit longer than a single connection attempt interval, so the error message is displayed. Retrying the connection attempt should be enough.
As a best practice, for the clients that support it, use ConnectionRetryCount and ConnectRetryInterval connection string keywords to control the reconnect behavior.
If the error message persists, file a support ticket through the Azure portal.
Can't connect from Synapse Studio
See the Synapse Studio section.
Can't connect to the Azure Synapse pool from a tool
Some tools might not have an explicit option that you can use to connect to the Azure Synapse serverless SQL pool. Use an option that you would use to connect to SQL Server or SQL Database. The connection dialog doesn't need to be branded as "Synapse" because the serverless SQL pool uses the same protocol as SQL Server or SQL Database.
Even if a tool enables you to enter only a logical server name and predefines the database.chinacloudapi.cn domain, put the Azure Synapse workspace name followed by the -ondemand suffix and the database.chinacloudapi.cn domain.
Security
Make sure that a user has permissions to access databases, permissions to execute commands, and permissions to access Azure Data Lake or Azure Cosmos DB storage.
Can't access Azure Cosmos DB account
You must use a read-only Azure Cosmos DB key to access your analytical storage, so make sure that it didn't expire or that it isn't regenerated.
If you get the error "Resolving Azure Cosmos DB path has failed with error", make sure that you configured a firewall.
Can't access lakehouse or Spark database
If a user can't access a lakehouse or Spark database, the user might not have permission to access and read the database. A user with CONTROL SERVER permission should have full access to all databases. As a restricted permission, you might try to use CONNECT ANY DATABASE and SELECT ALL USER SECURABLES.
SQL user can't access Dataverse tables
Dataverse tables access storage by using the caller's Microsoft Entra identity. A SQL user with high permissions might try to select data from a table, but the table wouldn't be able to access Dataverse data. This scenario isn't supported.
Microsoft Entra service principal sign-in failures when SPI creates a role assignment
If you want to create a role assignment for a service principal identifier (SPI) or Microsoft Entra app by using another SPI, or you've already created one and it fails to sign in, you'll probably receive the following error: Login error: Login failed for user '<token-identified principal>'.
For service principals, login should be created with an application ID as a security ID (SID) not with an object ID. There's a known limitation for service principals, which prevents Azure Synapse from fetching the application ID from Microsoft Graph when it creates a role assignment for another SPI or app.
Solution 1
Go to the Azure portal > Synapse Studio > Manage > Access control and manually add Synapse Administrator or Synapse SQL Administrator for the desired service principal.
Solution 2
You must manually create a proper login with SQL code:
use master
go
CREATE LOGIN [<service_principal_name>] FROM EXTERNAL PROVIDER;
go
ALTER SERVER ROLE sysadmin ADD MEMBER [<service_principal_name>];
go
Solution 3
You can also set up a service principal Azure Synapse admin by using PowerShell. You must have the Az.Synapse module installed.
The solution is to use the cmdlet New-AzSynapseRoleAssignment with -ObjectId "parameter". In that parameter field, provide the application ID instead of the object ID by using the workspace admin Azure service principal credentials.
PowerShell script:
$spAppId = "<app_id_which_is_already_an_admin_on_the_workspace>"
$SPPassword = "<application_secret>"
$tenantId = "<tenant_id>"
$secpasswd = ConvertTo-SecureString -String $SPPassword -AsPlainText -Force
$cred = New-Object -TypeName System.Management.Automation.PSCredential -ArgumentList $spAppId, $secpasswd
Connect-AzAccount -ServicePrincipal -Credential $cred -Tenant $tenantId -Environment AzureChinaCloud
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<app_id_to_add_as_admin>" [-Debug]
Note
In this case, the synapse data studio UI will not display the role assignment added by the above method, so it is recommended to add the role assignment to both object ID and application ID at the same time so that it can be displayed on the UI as well.
New-AzSynapseRoleAssignment -WorkspaceName "<workspaceName>" -RoleDefinitionName "Synapse Administrator" -ObjectId "<object_id_to_add_as_admin>" [-Debug]
Validation
Connect to the serverless SQL endpoint and verify that the external login with SID (app_id_to_add_as_admin in the previous sample) is created:
SELECT name, convert(uniqueidentifier, sid) AS sid, create_date
FROM sys.server_principals
WHERE type in ('E', 'X');
Or, try to sign in on the serverless SQL endpoint by using the set admin app.
Constraints
Some general system constraints might affect your workload:
| Property | Limitation |
|---|---|
| Maximum number of Azure Synapse workspaces per subscription | See limits. |
| Maximum number of databases per serverless pool | 100 (not including databases synchronized from Apache Spark pool). |
| Maximum number of databases synchronized from Apache Spark pool | Not limited. |
| Maximum number of databases objects per database | The sum of the number of all objects in a database can't exceed 2,147,483,647. See Limitations in SQL Server database engine. |
| Maximum identifier length in characters | 128. See Limitations in SQL Server database engine. |
| Maximum query duration | 30 minutes. |
| Maximum size of the result set | Up to 400 GB shared between concurrent queries. |
| Maximum concurrency | Not limited and depends on the query complexity and amount of data scanned. One serverless SQL pool can concurrently handle 1,000 active sessions that are executing lightweight queries. The numbers will drop if the queries are more complex or scan a larger amount of data, so in that case consider decreasing concurrency and execute queries over a longer period of time if possible. |
| Maximum size of External Table name | 100 characters. |
Can't create a database in serverless SQL pool
Serverless SQL pools have limitations, and you can't create more than 100 databases per workspace. If you need to separate objects and isolate them, use schemas.
If you get the error CREATE DATABASE failed. User database limit has been already reached you've created the maximum number of databases that are supported in one workspace.
You don't need to use separate databases to isolate data for different tenants. All data is stored externally on a data lake and Azure Cosmos DB. The metadata like table, views, and function definitions can be successfully isolated by using schemas. Schema-based isolation is also used in Spark where databases and schemas are the same concepts.