适用对象:
![]() Mongodb
Mongodb
重要
你是否正在寻找一种数据库解决方案,以应对需要高扩展性、99.999% 可用性服务级别协议(SLA)、即时自动扩展和跨多个区域的自动故障转移的场景? 请考虑使用 Azure Cosmos DB for NoSQL。
本迁移指南属于将数据库从 MongoDB 迁移到适用于 MongoDB 的 Azure Cosmos DB API 的系列。 关键迁移步骤是 预迁移、迁移和 迁移后,如下所示。
使用 Azure Databricks 进行数据迁移
Azure Databricks 是一种适用于 Apache Spark 的平台即服务 (PaaS) 产品/服务。 它提供一种对大规模数据集执行脱机迁移的方法。 可以使用 Azure Databricks 将数据库从 MongoDB 脱机迁移到 Azure Cosmos DB for MongoDB。
本教程介绍以下操作:
创建 Azure Databricks 工作区和计算
添加依赖项
创建和运行 Scala 或 Python 笔记本
优化迁移性能
排查迁移期间可能观察到的速率限制错误
先决条件
要完成本教程,需要:
- 完成预迁移 步骤,例如估算吞吐量并选择分片密钥。
- 创建 Azure Cosmos DB for MongoDB 帐户。
创建 Azure Databricks 工作区
可以按照说明 创建 Azure Databricks 工作区。 可以使用可用的默认 计算或创建新的计算资源 来运行笔记本。 请务必选择至少支持 Spark 3.0 的 Databricks 运行时。
添加依赖项
将 MongoDB Connector for Spark 库添加到计算资源中,以便连接至本机 MongoDB 和 Azure Cosmos DB for MongoDB 终结点。 在计算中,选择“ 库>安装新>Maven”,然后添加 org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 Maven 坐标。
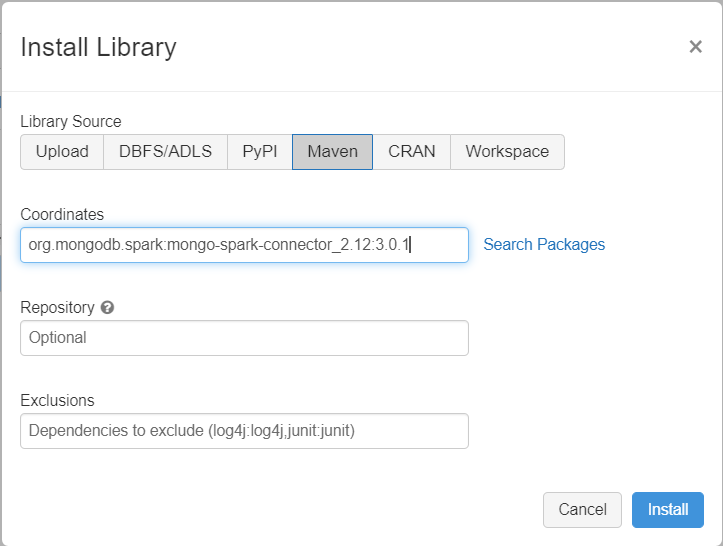
选择 “安装”,然后在安装完成后重启计算。
注释
请确保在安装适用于 Spark 的 MongoDB 连接器库之后重启 Databricks 群集。
之后,可以创建 Scala 或 Python 笔记本进行迁移。
创建用于迁移的 Scala 笔记本
在 Databricks 中创建 Scala 笔记本。 运行以下代码之前,请确保为变量输入正确的值:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.cn:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
创建用于迁移的 Python 笔记本
在 Databricks 中创建 Python 笔记本。 运行以下代码之前,请确保为变量输入正确的值:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.cn:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
优化迁移性能
可以通过以下配置调整迁移性能:
Spark 群集中的工作程序和核心数:工作程序越多,意味着执行任务的计算分片越多。
maxBatchSize:
maxBatchSize值控制将数据保存到目标 Azure Cosmos DB 集合中的速率。 但是,如果 maxBatchSize 对于集合吞吐量太高,则可能会导致速率限制错误。你需要根据 Spark 群集中的执行程序数量调整工作器的数量和 maxBatchSize 的值,这可能是写入的每个文档的大小(这就是 RU 成本高的原因),以及目标集合吞吐量限制。
小窍门
maxBatchSize = 集合吞吐量/(1 个文档的 RU 成本 * Spark 工作器数量 * 每个工作器的 CPU 核心数)
MongoDB Spark 分区程序和 partitionKey:使用的默认分区程序为 MongoDefaultPartitioner,默认 partitionKey 为 _id。 可以通过将值
MongoSamplePartitioner分配给输入配置属性spark.mongodb.input.partitioner来更改分区器。 同样地,可以通过将相应的字段名称分配给输入配置属性spark.mongodb.input.partitioner.partitionKey来更改 partitionKey。 合适的 partitionKey 有助于避免数据倾斜(为同一分区键值写入的大量记录)。在数据传输过程中禁用索引: 对于大量数据迁移,请考虑禁用索引,特别是目标集合上的通配符索引。 索引会增加写入每个文档的 RU 成本。 释放这些 RU 有助于提高数据传输速率。 迁移数据后,可以启用索引。
故障排除
超时错误(错误代码 50)
可能会看到针对 Azure Cosmos DB for MongoDB 数据库的操作错误代码 50。 以下情况可能会导致超时错误:
- 分配给数据库的吞吐量较低:确保为目标集合分配足够的吞吐量。
- 大数据量导致数据过度倾斜。 如果有大量的数据要迁移到给定的表中,但存在重大的数据倾斜,那么即使在你的表中预配了多个请求单位,你仍可能会遇到速率限制。 请求单位平均分配在物理分区之间,严重的数据倾斜可能会导致对单个分片的请求出现瓶颈。 数据倾斜意味着相同的分区键值有大量的记录。
速率限制(错误代码 16500)
您可能会看到针对 Azure Cosmos DB for MongoDB 数据库操作的 16500 错误码。 这些错误是速率限制错误,可以在禁用服务器端重试功能的旧帐户或帐户上观察到。
- 启用服务器端重试:启用服务器端重试 (SSR) 功能,并让服务器自动重试速率受限的操作。
迁移后优化
迁移数据后,你可以连接到 Azure Cosmos DB 并管理数据。 还可以遵循其他迁移后步骤,例如优化索引策略、更新默认一致性级别或为 Azure Cosmos DB 帐户配置多区域分发。 有关详细信息,请参阅迁移后优化一文。
更多资源
- 尝试为迁移到 Azure Cosmos DB 进行容量规划?
- 如果只知道现有数据库群集中的 vCore 和服务器数量,请阅读使用 vCore 或 vCPU 估算请求单位
- 若知道当前数据库工作负载的典型请求速率,请阅读使用 Azure Cosmos DB 容量计划工具估算请求单位