适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
将数据从源复制到目标存储时,复制活动提供一定程度的容错,以防止数据移动过程中因出现故障而中断。 例如,你要将数百万行从源复制到目标存储,其中,在目标数据库中创建了主键,但源数据库没有定义任何主键。 当你将重复行从源复制到目标时,将在目标数据库上遇到 PK 冲突故障。 目前,复制活动提供了两种处理此类错误的方法:
- 如果遇到任何故障,你可以中止复制活动。
- 可以通过启用容错以跳过不兼容的数据,继续复制其余部分。 例如,在这种情况下,跳过重复的行。 此外,还可以通过在复制活动中启用会话日志来记录跳过的数据。 有关更多详细信息,可以参阅复制活动中的会话日志。
复制二进制文件
服务在复制二进制文件时支持以下容错方案。 在以下情况下,可以选择中止复制活动或继续复制其余内容:
- 服务要复制的文件同时被其他应用程序删除。
- 某些特定文件夹或文件不允许服务访问,因为这些文件或文件夹的 ACL 需要比配置的连接信息更高的权限级别。
- 如果启用数据一致性验证设置,则不会验证一个或多个文件在源和目标存储之间是否一致。
通过用户界面启用容错
若要使用 UI 在管道中的Copy activity中配置容错,请完成以下步骤:
如果尚未为管道创建复制活动,请在管道活动窗格中搜索Copy,然后将“复制数据”活动拖至管道画布。
如果尚未选择画布上的新“复制数据”活动,请选择它及其“设置”选项卡,以配置容错。
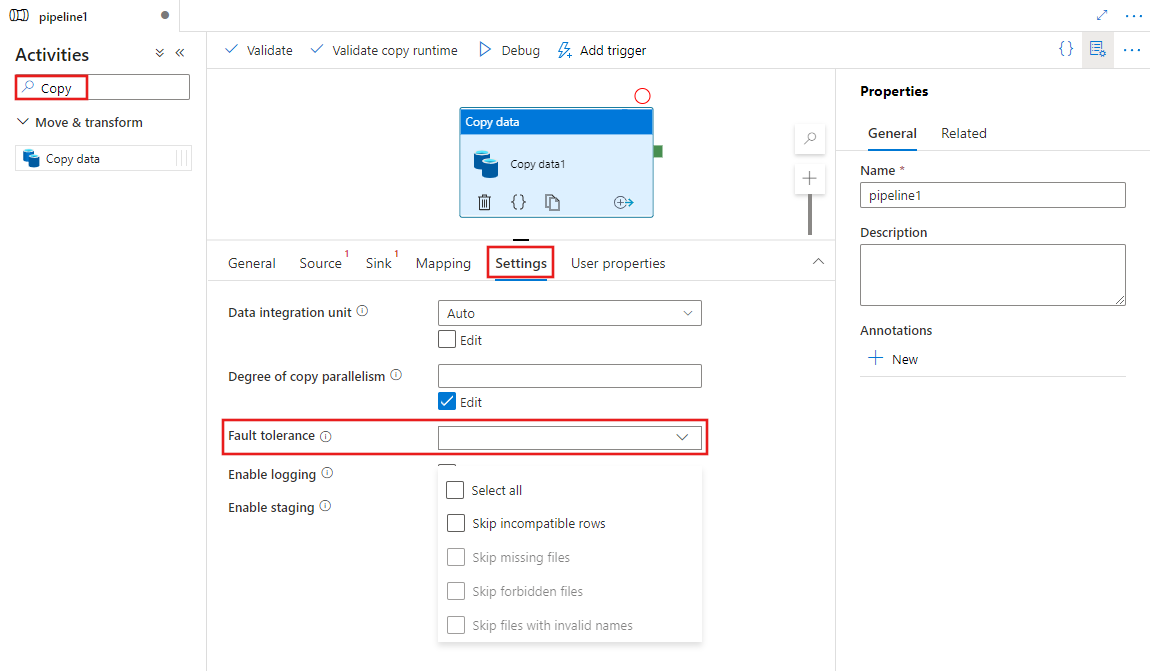
配置
在存储存储之间复制二进制文件时,可以启用容错,如下所示:
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| 属性 | 说明 | 允许的值 | 必须 |
|---|---|---|---|
| skipErrorFile | 一组属性,用于指定在数据移动过程中要跳过的失败类型。 | 否 | |
| 文件缺失 | skipErrorFile 属性包中的一个键值对,用于确定在服务执行复制操作时,是否要跳过被其他应用程序删除的文件。 -True:跳过其他应用程序正在删除的文件,复制剩余文件。 -False:在数据移动过程中,一旦从源存储中删除任何文件则中止复制活动。 默认情况下,该属性设置为 True。 |
True(默认值) 假 |
否 |
| fileForbidden | SkipErrorFile 属性包中的键值对之一,用于确定当特定文件或文件夹的 ACL 需要比配置的连接更高的权限级别时,是否要跳过这些文件。 -True:希望通过跳过文件来复制剩余的内容。 -False:如果遇到文件夹或文件的权限问题,希望中止复制活动。 |
真 False(默认值) |
否 |
| 数据不一致性 | SkipErrorFile 属性包中的一个键值对,用于确定是否要跳过源和目标存储之间不一致的数据。 -True:要通过跳过不一致的数据来复制其余内容。 -False:找到不一致的数据后要中止复制活动。 请注意,仅当你将 validateDataConsistency 设置为 True 时,此属性才有效。 |
真 False(默认值) |
否 |
| 无效文件名 | skipErrorFile 属性包中的一个键值对,用于确定当目标存储的文件名无效时是否要跳过特定文件。 -True:要通过跳过文件名无效的文件来复制其余内容。 -False:要在文件具有无效文件名时中止复制活动。 请注意,将二进制文件从任何存储复制到 ADLS Gen2 或仅将二进制文件从 AWS S3 复制到任何存储时,此属性有效。 |
真 False(默认值) |
否 |
| 日志设置 | 当要记录跳过的对象名称时可以指定的一组属性。 | 否 | |
| 链接服务名称 |
AzureBlobStorage 或 AzureBlobFS 类型链接服务的名称,指代用于存储日志文件的实例。 |
否 | |
| 路径 | 日志文件的路径。 | 指定用于存储日志文件的路径。 如果未提供路径,服务会为用户创建一个容器。 | 否 |
注意
以下是复制二进制文件时在复制活动中启用容错的先决条件。 若要在从源存储中删除特定文件时跳过这些文件,必须满足以下条件:
- 源数据集和接收器数据集必须是二进制格式,且不能指定压缩类型。
- 支持的数据存储类型Azure Blob 存储、Azure Data Lake Storage Gen2、Azure Files、文件系统、FTP、SFTP、Amazon S3、Google Cloud Storage 和 HDFS。
- 仅当在源数据集中指定多个文件(可以是文件夹、通配符或文件列表)时,复制活动才能跳过特定错误文件。 若要将源数据集中的单个文件指定为复制到目标,则如果出现任何错误,复制活动会失败。
若要在源存储中禁止访问特定文件时跳过这些文件,必须满足以下条件:
- 源数据集和接收器数据集必须是二进制格式,且不能指定压缩类型。
- 支持的数据存储类型Azure Blob 存储、Azure Data Lake Storage Gen2、Azure Files、SFTP、Amazon S3 和 HDFS。
- 仅当在源数据集中指定多个文件(可以是文件夹、通配符或文件列表)时,复制活动才能跳过特定错误文件。 若要将源数据集中的单个文件指定为复制到目标,则如果出现任何错误,复制活动会失败。
若要在验证特定文件在源存储和目标存储之间是否不一致时跳过这些文件,必须满足以下条件:
- 可从此处的数据一致性文档获取更多详细信息。
监控
复制活动的输出
可以通过每次复制活动运行的输出获取被读取、写入和跳过的文件数。
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
复制活动的会话日志
如果配置为记录跳过的文件名称,可以通过此路径找到日志文件:https://[your-blob-account].blob.core.chinacloudapi.cn/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv。
日志文件只能是 csv 文件。 日志文件的架构如下所示:
| 列 | 说明 |
|---|---|
| 时间戳 | 跳过文件时的时间戳。 |
| 级别 | 此项的日志级别。 显示文件跳过的项目将处于“警告”级别。 |
| 操作名称 | 对每个文件进行的拷贝活动的操作行为。 它将为“FileSkip”,以指定要跳过的文件。 |
| 操作项 | 要跳过的文件名。 |
| 消息 | 更多信息说明为何要跳过该文件。 |
日志文件的示例如下所示:
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.chinacloudapi.cn/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
在上面的日志中,你可以看到已跳过 bigfile.csv,因为在服务复制此文件时,其他应用程序已将它删除。 已跳过 3_nopermission.txt,因为由于权限问题,系统不允许服务访问它。
复制表格数据
支持的方案
Copy activity支持三种检测、跳过和记录不兼容表格数据的方案:
源数据类型与接收端原生类型不兼容。
例如:将数据从 Blob 存储中的 CSV 文件复制到具有架构定义的包含三个 INT 类型列的 SQL 数据库。 包含数值数据的 CSV 文件行(如 123,456,789)成功复制到接收器存储。 但是,包含非数字值的行(如 123,456, abc )检测为不兼容,并被跳过。
源与接收器之间的列数不匹配。
例如:使用包含六个列的架构定义,将数据从 Blob 存储中的 CSV 文件复制到 SQL 数据库。 包含六个列的 CSV 文件行会成功复制到接收器存储。 包含多于六列的 CSV 文件行将检测为不兼容,并被跳过。
写入 SQL Server/Azure SQL Database/Azure Cosmos DB 时的主键违例。
例如:将数据从 SQL 服务器复制到 SQL 数据库。 接收器 SQL 数据库中定义了主键,但源 SQL 服务器中未定义此类主键。 源中的重复行无法复制到接收器。 Copy activity仅将源数据的第一行复制到接收器中。 包含重复主键值的后续源行会被检测为不兼容,并被跳过。
注意
- 若要使用 PolyBase 将数据加载到Azure Synapse Analytics,请在复制活动中通过“polyBaseSettings”指定拒绝策略来配置 PolyBase 的本机容错设置。 您依然可以像正常情况下一样,将不兼容 PolyBase 的行重定向到 Blob 或 ADLS,如下所示。
- 将复制活动配置为调用 AmazonRedShift 卸载时,此功能不适用。
- 当复制活动配置为调用 SQL 接收器中的存储过程或使用更新插入将数据写入 SQL 接收器时,此功能不适用。
配置
下面的 JSON 定义示例用于配置在复制活动中跳过不兼容行:
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| 属性 | 说明 | 允许的值 | 必须 |
|---|---|---|---|
| 启用跳过不兼容行 | 指定是否在复制期间跳过不兼容的行。 | 真 False(默认值) |
否 |
| 日志设置 | 若要记录不兼容行,可以指定的一组属性。 | 否 | |
| 链接服务名称 | \ |
AzureBlobStorage 或 AzureBlobFS 类型链接服务的名称,指代用于存储日志文件的实例。 |
否 |
| 路径 | 包含已跳过行的日志文件的路径。 | 指定要用于记录不兼容数据的路径。 如果未提供路径,服务会为用户创建一个容器。 | 否 |
监视跳过的行
复制活动运行完成后,可以在复制活动输出中看到跳过的行数:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
如果配置为记录不兼容的行,可以通过此路径找到日志文件:https://[your-blob-account].blob.core.chinacloudapi.cn/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv。
日志文件将是 csv 文件。 日志文件的架构如下所示:
| 列 | 说明 |
|---|---|
| 时间戳 | 跳过不兼容行的时间戳 |
| 级别 | 此项的日志级别。 如果此项显示跳过的行,它将处于“警告”级别 |
| 操作名称 | 对每一行的复制活动的操作行为进行分析。 将其命名为“TabularRowSkip”以指定已跳过特定不兼容行。 |
| 操作项 | 源数据存储中被跳过的行。 |
| 消息 | 进一步说明为何该特定行不兼容的信息。 |
下面的示例展示了日志文件内容:
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
在上面的示例日志文件中,你可以看到由于源到目标存储的类型转换问题,跳过了一行“data1, data2, data3”。 由于源到目标存储中出现 PK 冲突问题,另一行“data4, data5, data6”已被跳过。
复制表格数据(旧版):
以下方法是仅用于复制表格数据时启用容错能力的传统方法。 如果你正在创建新的管道或活动,建议你从此处开始。
配置
下面的 JSON 定义示例用于配置在复制活动中跳过不兼容行:
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| 属性 | 说明 | 允许的值 | 必须 |
|---|---|---|---|
| 启用跳过不兼容行 | 指定是否在复制期间跳过不兼容的行。 | 真 False(默认值) |
否 |
| 重定向不兼容的行设置 | 若要记录不兼容行,可以指定的一组属性。 | 否 | |
| 链接服务名称 | Azure Storage 的链接服务,用于存储包含跳过的行的日志。 |
AzureStorage 或 AzureDataLakeStore 类型链接服务的名称,指代要用于存储日志文件的实例。 |
否 |
| 路径 | 包含跳过行的日志文件的路径。 | 指定要用于记录不兼容数据的路径。 如果未提供路径,服务会为用户创建一个容器。 | 否 |
监视跳过的行
复制活动运行完成后,可以在复制活动输出中看到跳过的行数:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.chinacloudapi.cn//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
如果配置为记录不兼容的行,可以通过此路径找到日志文件:https://[your-blob-account].blob.core.chinacloudapi.cn/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv。
日志文件只能是 csv 文件。 所跳过的原始数据必要时将以逗号作为列分隔符进行记录。 除了日志文件中的原始源数据外,我们还另外添加两列“ErrorCode”和“ErrorMessage”,可从中查看不兼容的根本原因。 ErrorCode 和 ErrorMessage 将用双引号引起来。
下面的示例展示了日志文件内容:
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
相关内容
请参阅其他复制活动文章: