适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文概述了如何使用 Azure Data Factory 或 Synapse 管道中的复制活动,从和向 Azure Synapse Analytics 复制数据,并使用数据流转换 Azure Data Lake Storage Gen2 中的数据。 若要了解Azure Data Factory,请阅读 简介文章。
支持的功能
以下功能支持此Azure Synapse Analytics连接器:
| 支持的功能 | IR | 托管私有终结点 |
|---|---|---|
| Copy activity (源/接收器) | (1) (2) | ✓ |
| 映射数据流(源/汇) | ① | ✓ |
| 查询活动 | (1) (2) | ✓ |
| GetMetadata 活动 | (1) (2) | ✓ |
| 脚本活动 | (1) (2) | ✓ |
| 存储过程活动 | (1) (2) | ✓ |
(1) Azure集成运行时 (2) 自承载集成运行时
对于Copy activity,此Azure Synapse Analytics连接器支持以下功能:
- 使用 SQL 身份验证复制数据,并通过服务主体或托管身份对 Azure 资源进行 Microsoft Entra 应用程序令牌身份验证。
- 作为源,使用 SQL 查询或存储过程检索数据。 还可以选择从 Azure Synapse Analytics 源并行复制,有关详细信息,请参阅 Azure Synapse Analytics 的并行复制 部分。
- 作为数据接收器,使用 COPY 语句、PolyBase 或批量插入来加载数据。 我们建议使用 COPY 语句或 PolyBase 以获得更好的复制性能。 连接器还支持使用 DISTRIBUTION = ROUND_ROBIN 基于源架构自动创建目标表(如果不存在)。
重要
如果使用 Azure Integration Runtime复制数据,请配置 服务器级防火墙规则以便Azure服务可以访问 logical SQL server。 如果使用自承载集成运行时复制数据,请将防火墙配置为允许合适的 IP 范围。 此范围包括用于连接到Azure Synapse Analytics的计算机的 IP。
开始
提示
若要获得最佳性能,请使用 PolyBase 或 COPY 语句将数据加载到Azure Synapse Analytics。 使用 PolyBase 将数据加载到 Azure Synapse Analytics 和 使用 COPY 语句将数据加载到 Azure Synapse Analytics 节中具有详细信息。 有关用例的演练,请参阅使用 Azure Data Factory 在 15 分钟内将 1 TB 加载到 Azure Synapse Analytics。
若要使用管道执行复制活动,可以使用以下工具或 SDK 之一:
使用 UI 创建Azure Synapse Analytics链接服务
使用以下步骤在 Azure 门户 UI 中创建Azure Synapse Analytics链接服务。
浏览到Azure Data Factory或 Synapse 工作区中的“管理”选项卡并选择“链接服务”,然后单击“新建”:
搜索 Synapse 并选择Azure Synapse Analytics连接器。
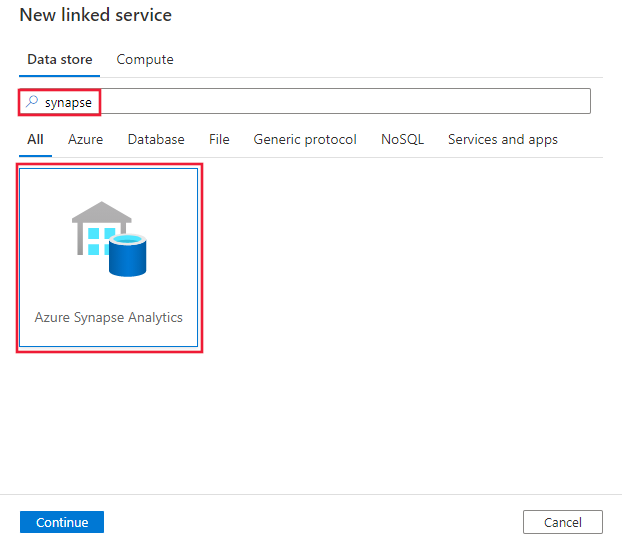
配置服务详细信息、测试连接并创建新的链接服务。
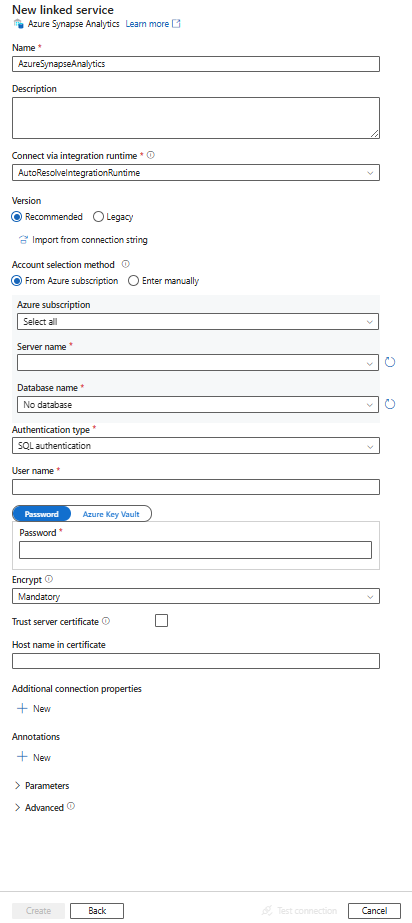
连接器配置详细信息
下面将提供有关定义特定于 Azure Synapse Analytics 连接器的 Azure 数据工厂和 Synapse 管道实体属性的详细信息。
连接的服务属性
Azure Synapse Analytics连接器 Recommended 版本支持 TLS 1.3。 请参阅这个 部分,将 Azure Synapse Analytics 连接器版本从 传统版本升级。 有关属性详细信息,请参阅相应部分。
提示
在Azure门户中,为 Azure Synapse 中的 serverless SQL 池创建链接服务时:
- 对于“帐户选择方法”,请选择“手动输入”。
- 粘贴无服务器终结点的完全限定域名。 可以在 Synapse 工作区的 Azure 门户“概述”页中找到此信息,该页位于 Serverless SQL 终结点下的属性中。 例如,
myserver-ondemand.sql-azuresynapse.azure.cn。 - 对于“数据库名称”,请提供无服务器 SQL 池中的数据库名称。
提示
如果遇到错误代码为“UserErrorFailedToConnectToSqlServer”的错误,并显示“数据库的会话限制为 XXX 且已达到。”,请将 Pooling=false添加到connection string,然后重试。
建议的版本
应用 Recommended 版本时,Azure Synapse Analytics 链接的服务支持这些通用属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureSqlDW。 | 是 |
| 服务器 | 要连接到的 SQL Server 实例的名称或网络地址。 | 是 |
| 数据库 | 数据库的名称。 | 是 |
| 认证类型 | 用于身份验证的类型。 允许的值为 SQL(默认值)、ServicePrincipal、SystemAssignedManagedIdentity、UserAssignedManagedIdentity。 转到有关特定属性和先决条件的相关身份验证部分。 | 是 |
| 加密 | 指示客户端和服务器之间发送的所有数据是否需要 TLS 加密。 选项:必需(对于 true,默认值)/可选(对于 false)/严格。 | 否 |
| trustServerCertificate | 指示是否在绕过验证信任的证书链时加密通道。 | 否 |
| 证书中的主机名称 | 验证连接的服务器证书时要使用的主机名。 如果未指定,则服务器名称用于证书验证。 | 否 |
| connectVia | 用于连接到数据存储的集成运行时。 可以使用 Azure Integration Runtime 或自托管的 integration runtime(如果数据存储位于专用网络中)。 如果未指定,则使用默认Azure Integration Runtime。 | 否 |
有关其他连接属性,请查看下表:
| 属性 | 描述 | 必需 |
|---|---|---|
| 应用意图 | 连接到服务器时的应用程序工作负载类型。 允许的值为 ReadOnly 和 ReadWrite。 |
否 |
| connectTimeout | 在终止尝试并生成错误之前等待与服务器建立连接的时间(以秒为单位)。 | 否 |
| 连接重试次数 (connectRetryCount) | 识别空闲连接失败后尝试的重新连接次数。 该值应为介于 0 到 255 之间的整数。 | 否 |
| connectRetryInterval | 识别空闲连接失败后,每次重新连接尝试之间的时间(以秒为单位)。 该值应为介于 1 到 60 之间的整数。 | 否 |
| loadBalanceTimeout | 在连接被断开之前,连接在连接池中存在的最短时间(以秒为单位)。 | 否 |
| commandTimeout | 在终止尝试执行命令并生成错误之前的默认等待时间(以秒为单位)。 | 否 |
| integratedSecurity | 允许的值为 true 或 false。 指定 false 时,指示是否在连接中指定了 userName 和密码。 指定 true 时,指示当前Windows帐户凭据是否用于身份验证。 |
否 |
| failoverPartner | 主服务器关闭时要连接到的伙伴服务器的名称或地址。 | 否 |
| 最大池大小 | 特定连接的连接池中允许的最大连接数。 | 否 |
| minPoolSize | 特定连接的连接池中允许的最小连接数。 | 否 |
| multipleActiveResultSets | 允许的值为 true 或 false。 指定 true 时,应用程序可维护多重活动结果集 (MARS)。 指定 false 时,应用程序必须先处理或取消从某一批处理生成的所有结果集,然后才能对该连接执行任何其他批处理。 |
否 |
| multiSubnetFailover | 允许的值为 true 或 false。 如果你的应用程序要连接到不同子网上的 AlwaysOn 可用性组 (AG),那么将此属性设置为 true 会加快检测和连接到当前活动服务器。 |
否 |
| 数据包大小 | 用于与服务器实例通信的网络数据包的大小(字节数)。 | 否 |
| 池化 | 允许的值为 true 或 false。 指定 true 时,连接将共用。 指定 false 时,每次请求连接时都会显式打开连接。 |
否 |
SQL 身份验证
若要使用 SQL 身份验证,除了前面部分所述的通用属性,还指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| userName | 用于连接到服务器的用户名。 | 是 |
| 密码 | 对应于用户名的密码。 将此字段标记为 SecureString 以安全存储它。 或者,可以引用存储在 Azure Key Vault 中的机密。 | 是 |
示例:使用 SQL 身份验证
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
服务主体身份验证
要使用服务主体身份验证,除了上一部分中描述的通用属性外,还需要指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalCredential | 服务主体凭据。 指定应用程序的密钥。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| 租户 | 请指定您的应用程序所归属的租户信息(域名或租户 ID)。 可以通过将鼠标悬停在Azure门户右上角来检索它。 | 是 |
| azureCloudType | 对于服务主体身份验证,请指定注册Microsoft Entra应用程序的Azure云环境的类型。 默认情况下,使用数据工厂或 Synapse 管道的云环境。 |
否 |
还需要执行以下步骤:
从 Azure 门户创建Microsoft Entra应用程序。 记下应用程序名称,以及以下定义链接服务的值:
- 应用程序 ID
- 应用程序密钥
- 租户 ID
在Azure门户中为服务器预配Microsoft Entra管理员(如果尚未这样做)。 Microsoft Entra管理员可以是Microsoft Entra用户或Microsoft Entra组。 如果授予具有托管标识的组管理员角色,则可跳过步骤 3 和 4。 管理员将拥有对数据库的完全访问权限。
为服务主体 创建包含的数据库用户 。 使用 SSMS 等工具连接到您希望从中或向其复制数据的数据仓库,使用至少具有 ALTER ANY USER 权限的 Microsoft Entra 标识。 运行以下 T-SQL:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;像通常对 SQL 用户或其他用户所做的那样向服务主体授予所需的权限。 运行以下代码,或者参考此处的更多选项。 如果要使用 PolyBase 加载数据,请了解所需的数据库权限。
EXEC sp_addrolemember db_owner, [your application name];在 Azure Data Factory 或 Synapse 工作区中配置Azure Synapse Analytics链接服务。
使用服务主体身份验证的链接服务示例
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.chinacloudapi.cn,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.partner.onmschina.cn>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Azure资源身份验证的系统分配托管标识
数据工厂或 Synapse 工作区可以与用于表示 Azure 资源的 系统分配的托管标识相关联。 可以使用此托管标识进行Azure Synapse Analytics身份验证。 指定资源可使用此标识从/向数据仓库访问和复制数据。
若要使用系统分配的托管标识身份验证,请指定上一部分所述的通用属性,然后按照以下步骤操作。
在Azure门户中为服务器预配Microsoft Entra管理员(如果尚未这样做)。 Microsoft Entra管理员可以是Microsoft Entra用户或Microsoft Entra组。 如果您为具有系统分配托管标识的组授予了管理员角色,请跳过步骤 3 和步骤 4。 管理员将拥有对数据库的完全访问权限。
为系统分配的托管标识创建包含的数据库用户。 使用 SSMS 等工具连接到您希望从中或向其复制数据的数据仓库,使用至少具有 ALTER ANY USER 权限的 Microsoft Entra 标识。 运行以下 T-SQL。
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;为系统分配的托管标识授予所需的权限,就像通常为 SQL 用户和其他用户所做的那样。 运行以下代码,或者参考此处的更多选项。 如果要使用 PolyBase 加载数据,请了解所需的数据库权限。
EXEC sp_addrolemember db_owner, [your_resource_name];配置Azure Synapse Analytics链接服务。
示例:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
用户分配的托管标识身份验证
可将数据工厂或 Synapse 工作区与表示资源的用户分配的托管标识关联。 可以使用此托管标识进行Azure Synapse Analytics身份验证。 指定资源可使用此标识从/向数据仓库访问和复制数据。
要使用用户分配的托管身份身份验证,除了上一节中描述的通用属性外,还要指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 凭据 | 将用户分配的托管标识指定为凭据对象。 | 是 |
还需要执行以下步骤:
在Azure门户中为服务器预配Microsoft Entra管理员(如果尚未这样做)。 Microsoft Entra管理员可以是Microsoft Entra用户或Microsoft Entra组。 如果为具有用户分配的托管标识的组授予管理员角色,请跳过步骤 3。 管理员将拥有对数据库的完全访问权限。
为用户分配的托管标识创建包含的数据库用户。 使用 SSMS 等工具连接到您希望从中或向其复制数据的数据仓库,使用至少具有 ALTER ANY USER 权限的 Microsoft Entra 标识。 运行以下 T-SQL。
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;创建一个或多个用户分配的托管标识,并为用户分配的托管标识授予所需的权限,就像通常为 SQL 用户和其他用户所做的那样。 运行以下代码,或者参考此处的更多选项。 如果要使用 PolyBase 加载数据,请了解所需的数据库权限。
EXEC sp_addrolemember db_owner, [your_resource_name];为数据工厂分配一个或多个用户分配的托管标识,并为每个用户分配的托管标识创建凭据。
配置Azure Synapse Analytics链接服务。
示例
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
旧版本
应用 Legacy 版本时,Azure Synapse Analytics链接服务支持这些泛型属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | type 属性必须设置为 AzureSqlDW。 | 是 |
| connectionString | 指定用于连接 Azure Synapse Analytics 实例的 connectionString 属性所需的信息。 将此字段标记为 SecureString 以安全存储它。 还可以将密码/服务主体密钥放在Azure Key Vault中,如果是 SQL 身份验证,则会将 password 配置从connection string中拉取出来。 更多信息请参见文章“在 Azure Key Vault 中存储凭据”。 |
是 |
| connectVia | 用于连接到数据存储的集成运行时。 可以使用 Azure Integration Runtime 或自托管的 integration runtime(如果数据存储位于专用网络中)。 如果未指定,则使用默认Azure Integration Runtime。 | 否 |
有关各种身份验证类型,请参阅以下部分,分别了解特定属性和先决条件:
旧版的 SQL 身份验证
要使用 SQL 身份验证,请指定前面部分所述的通用属性。
旧版本的服务主体身份验证
要使用服务主体身份验证,除了上一部分中描述的通用属性外,还需要指定以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalKey | 指定应用程序的密钥。 将此字段标记为 SecureString 以安全地存储它,或引用存储在 Azure Key Vault 中的机密。 | 是 |
| 租户 | 指定应用程序所在的租户的信息(例如域名或租户 ID)。 通过将鼠标悬停在Azure门户右上角来检索它。 | 是 |
| azureCloudType | 对于服务主体身份验证,请指定注册Microsoft Entra应用程序的Azure云环境的类型。 默认情况下,使用数据工厂或 Synapse 管道的云环境。 |
否 |
还需要按照服务主体身份验证中的步骤授予相应的权限。
旧版本的系统分配的托管标识身份验证
若要使用系统分配的托管标识身份验证,请按照系统分配的托管标识身份验证中的推荐版本步骤进行操作。
遗留版本的用户指定的托管标识身份验证
若要使用用户分配的托管标识身份验证,请按照用户分配的托管标识身份验证,按照推荐的版本执行相同的步骤。
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。
Azure Synapse Analytics数据集支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 AzureSqlDWTable。 | 是 |
| 架构 | 架构的名称。 | 对于源为“No”,对于接收器为“Yes” |
| 表 | 表/视图的名称。 | 对于源为“No”,对于接收器为“Yes” |
| tableName | 具有架构的表/视图的名称。 此属性支持后向兼容性。 对于新的工作负荷,请使用 schema 和 table。 |
对于源为“No”,对于接收器为“Yes” |
数据集属性示例
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
复制活动属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供Azure Synapse Analytics源和接收器支持的属性列表。
Azure Synapse Analytics 作为源
提示
若要使用数据分区高效地从 Azure Synapse Analytics 加载数据,请参阅从 Azure Synapse Analytics 并行复制以获取更多信息。
若要从 Azure Synapse Analytics 复制数据,请将复制活动源中的 type 属性设置为 SqlDWSource。 复制活动 source 部分支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 SqlDWSource。 | 是 |
| sqlReaderQuery | 使用自定义 SQL 查询读取数据。 示例:select * from MyTable。 |
否 |
| sqlReaderStoredProcedureName | 从源表读取数据的存储过程的名称。 最后一个 SQL 语句必须是存储过程中的 SELECT 语句。 | 否 |
| 存储过程参数 | 存储过程的参数。 允许的值为名称或值对。 参数的名称和大小写必须与存储过程的参数名称和大小写一致。 |
否 |
| 隔离级别 | 指定 SQL 源的事务锁定行为。 允许的值为:ReadCommitted、ReadUncommitted、RepeatableRead、Serializable、Snapshot 。 如果未指定,则使用数据库的默认隔离级别。 有关详细信息,请参阅 system.data.isolationlevel。 | 否 |
| 分区选项 | 指定用于从Azure Synapse Analytics加载数据的数据分区选项。 允许值包括:None(默认值)、PhysicalPartitionsOfTable 和 DynamicRange 。 当启用分区选项(即,不为 None)时,复制活动中的 parallelCopies 设置将控制从 Azure Synapse Analytics 中并发加载数据的并行度。 |
否 |
| 分区设置 | 指定数据分区的设置组。 当分区选项不是 None 时适用。 |
否 |
在 partitionSettings 下: |
||
| partitionColumnName | 以整数类型、日期类型或日期/时间类型(、int、smallint、bigint、date、smalldatetime、datetime 或 datetime2)指定源列的名称,范围分区将使用它进行并行复制。 如果未指定,系统会自动检测表的索引或主键并将其用作分区列。当分区选项是 DynamicRange 时适用。 如果使用查询来检索源数据,请在 WHERE 子句中挂接 ?DfDynamicRangePartitionCondition 。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
| partitionUpperBound | 分区范围拆分的分区列的最大值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
| partitionLowerBound | 用于分区范围拆分的分区列的最小值。 此值用于决定分区步幅,不用于筛选表中的行。 将对表或查询结果中的所有行进行分区和复制。 如果未指定,复制活动会自动检测该值。 当分区选项是 DynamicRange 时适用。 有关示例,请参阅从 SQL 数据库进行并行复制部分。 |
否 |
请注意以下几点:
- 在源中使用存储过程检索数据时,请注意,如果存储过程旨在当传入不同的参数值时返回不同的架构,则从 UI 导入架构时,或通过自动创建表的功能将数据复制到 SQL 数据库时,可能会遇到故障或出现意外的结果。
示例:使用 SQL 查询
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例:使用存储过程
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
示例存储过程:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics 作为汇集
Azure Data Factory和 Synapse 管道支持将数据加载到Azure Synapse Analytics的三种方法。
- 使用 COPY 语句
- 使用 PolyBase
- 使用批量插入
加载数据最快且最具扩展性的方法是通过 COPY 语句 或 PolyBase。
若要将数据复制到 Azure Synapse Analytics,请将复制活动中的接收器类型设置为 SqlDWSink。 在复制活动的 sink 节中支持以下属性:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动接收器的 type 属性必须设置为 SqlDWSink。 | 是 |
| allowPolyBase | 指示是否使用 PolyBase 将数据加载到Azure Synapse Analytics。
allowCopyCommand 和 allowPolyBase 不能同时为 true。 有关约束和详细信息,请参阅 使用 PolyBase 将数据加载到 Azure Synapse Analytics 部分。 允许的值为 True 和 False(默认值)。 |
否。 使用 PolyBase 时适用。 |
| polyBaseSettings |
allowPolybase 属性设置为 true 时可以指定的一组属性。 |
否。 使用 PolyBase 时适用。 |
| 允许复制命令 | 指示是否使用 COPY 语句将数据加载到Azure Synapse Analytics。
allowCopyCommand 和 allowPolyBase 不能同时为 true。 有关约束和详细信息,请参阅 使用 COPY 语句将数据加载到 Azure Synapse Analytics 部分。 允许的值为 True 和 False(默认值)。 |
否。 使用 COPY 时适用。 |
| 复制命令设置 |
allowCopyCommand 属性设置为 TRUE 时可以指定的一组属性。 |
否。 使用 COPY 时适用。 |
| writeBatchSize |
每批要插入到 SQL 表中的行数。 允许的值为 integer(行数)。 默认情况下,该服务根据行大小动态确定适当的批大小。 |
否。 在使用批量插入时适用。 |
| writeBatchTimeout | 插入、更新插入和存储过程操作在超时之前完成的等待时间。 允许的值是指时间跨度。 例如,“00:30:00”表示 30 分钟。 如果未指定值,则超时默认为“00:30:00”。 |
否。 在使用批量插入时适用。 |
| preCopyScript | 在每次运行时,在将数据写入 Azure Synapse Analytics 之前,指定一个用于复制活动的 SQL 查询。 使用此属性清理预加载的数据。 | 否 |
| 表格选项 | 指定是否根据源架构自动创建接收器表(如果接收器表不存在)。 允许的值为:none(默认值)、autoCreate。 |
否 |
| 禁用指标收集 | 该服务收集指标,例如Azure Synapse Analytics DWU 进行复制性能优化和建议,这引入了额外的主数据库访问。 如果你担心此行为,请指定 true 将其关闭。 |
否(默认值为 false) |
| maxConcurrentConnections | 活动运行期间与数据存储建立的并发连接的上限。 仅在要限制并发连接时指定一个值。 | 否 |
| WriteBehavior | 指定复制活动在将数据加载到 Azure Synapse Analytics 时的写入行为。 允许的值为 Insert 和 Upsert。 默认情况下,服务使用 insert 来加载数据。 |
否 |
| upsertSettings | 指定用于写入行为的设置组。 当 WriteBehavior 选项为 Upsert 时应用。 |
否 |
在 upsertSettings 下: |
||
| 密钥 | 请指定用于唯一行标识的列名称。 可使用单个键,也可使用一系列键。 如果未指定,将使用主键。 | 否 |
| interimSchemaName | 指定用于创建临时表的临时架构。 注意:用户需要具有创建和删除表的权限。 默认情况下,临时表将与接收器表共享相同的架构。 | 否 |
示例 1:Azure Synapse Analytics接收器
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
示例 2:更新或插入数据
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
从Azure Synapse Analytics并行复制
复制活动中的Azure Synapse Analytics连接器提供内置的数据分区来并行复制数据。 可以在复制活动的“源”表中找到数据分区选项。
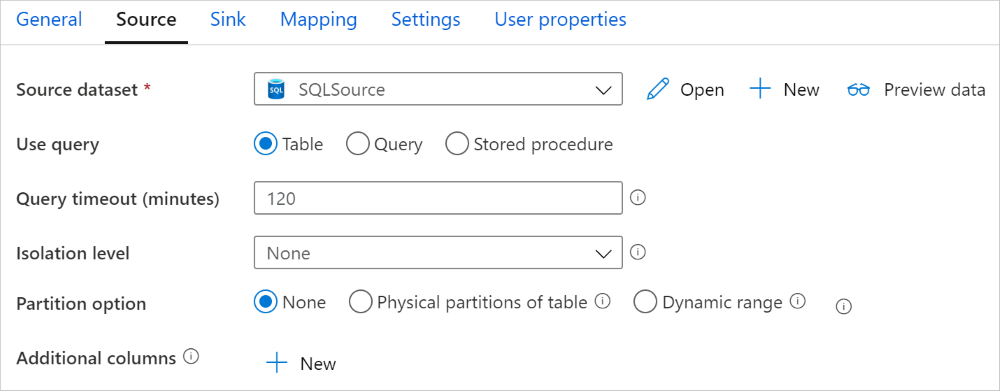
启用分区复制时,复制活动针对Azure Synapse Analytics源运行并行查询,按分区加载数据。 可通过复制活动中的 parallelCopies 设置来控制并行度。 例如,如果将 parallelCopies 设置为 4,则服务会根据指定的分区选项和设置同时生成并运行四个查询,并且每个查询从Azure Synapse Analytics检索一部分数据。
建议启用并行复制并使用数据分区,特别是在从 Azure Synapse Analytics 加载大量数据时。 下面是适用于不同方案的建议配置。 将数据复制到基于文件的数据存储中时,建议将数据作为多个文件写入文件夹(仅指定文件夹名称),在这种情况下,性能优于写入单个文件。
| 场景 | 建议的设置 |
|---|---|
| 从具有物理分区的大型表中进行完整数据加载。 |
分区选项:表的物理分区。 在执行期间,该服务将自动检测物理分区并按分区复制数据。 若要检查表是否有物理分区,可参考此查询。 |
| 从不包含物理分区的大型表中加载完整数据,其中有一个用于数据分区的整数或日期时间列。 |
分区选项:动态范围分区。 分区列(可选):指定用于对数据进行分区的列。 如果未指定,将使用索引或主键列。 分区上限和分区下限(可选):请指定是否要确定分区步幅。 这不适用于筛选表中的行,表中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测这些值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 |
| 通过使用自定义查询,在没有物理分区的情况下,通过整数或日期/日期时间列进行数据分区,加载大量数据。 |
分区选项:动态范围分区。 查询: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>。分区列:指定用于对数据进行分区的列。 分区上限和分区下限(可选):请指定是否要确定分区步幅。 这不适用于筛选表中的行,查询结果中的所有行都将进行分区和复制。 如果未指定,复制活动会自动检测该值。 例如,如果分区列“ID”的值范围为 1 至 100,并且将此值的下限设置为 20、上限设置为 80,并行复制设置为 4,服务将按 4 个分区(分区的 ID 范围分别为 <=20、[21, 50]、[51, 80] 和 >=81)检索数据。 下面是针对不同场景的更多示例查询: 1.查询整个表: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2.使用列选择和附加的 where 子句筛选器从表中查询: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3.使用子查询进行查询: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4.在子查询中使用分区查询: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
使用分区选项加载数据的最佳做法:
- 选择独特的列作为分区列(如主键或唯一键),以避免数据倾斜。
- 如果表具有内置分区,请使用名为“表的物理分区”分区选项来提升性能。
- 如果使用Azure Integration Runtime复制数据,则可以设置更大的“Data Integration Units (DIU)”(>4)以利用更多的计算资源。 检查此处适用的方案。
- “复制并行度”可控制分区数量,将此数字设置得太大有时会损害性能,建议将此数字设置按以下公式计算的值:(DIU 或自承载 IR 节点数)*(2 到 4)。
- 请注意,Azure Synapse Analytics 一次最多可以执行 32 个查询,设置“复制并行度”过大可能会导致 Synapse 节流问题。
示例:从包含物理分区的大型表进行完整加载
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
示例:使用动态范围分区进行查询
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
检查物理分区的示例查询
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
如果表具有物理分区,则会看到“HasPartition”为“是”。
使用 COPY 语句将数据加载到 Azure Synapse Analytics
使用 COPY 语句是将数据加载到吞吐量较高的Azure Synapse Analytics的简单灵活方法。 若要了解更多详细信息,请参阅使用 COPY 语句批量加载数据
- 如果源数据位于 Azure Blob 或 Azure Data Lake Storage Gen2 中,并且 format 是 COPY 语句兼容的,则可以使用复制活动直接调用 COPY 语句来让Azure Synapse Analytics从源中提取数据。 有关详细信息,请参阅 使用 COPY 语句直接复制 。
- 如果源数据存储和格式最初不被支持通过 COPY 语句,请改用 使用 COPY 语句进行分阶段复制 功能。 暂存复制功能也能提供更高的吞吐量。 它自动将数据转换为 COPY 语句兼容格式,将数据存储在 Azure Blob 存储中,然后调用 COPY 语句将数据加载到Azure Synapse Analytics。
提示
将 COPY 语句与 Azure Integration Runtime 一起使用时,有效的 Data Integration Units (DIU) 始终为 2。 优化 DIU 不会影响性能,因为从存储加载数据由Azure Synapse引擎提供支持。
使用COPY语句来直接进行复制
Azure Synapse Analytics COPY 语句直接支持Azure Blob 和Azure Data Lake Storage Gen2。 如果源数据满足本节中所述的条件,请使用 COPY 语句直接从源数据存储复制到Azure Synapse Analytics。 否则,请使用COPY 语句进行暂存复制。 该服务会检查设置,如果不满足条件,复制活动运行将会失败。
源链接服务和格式使用以下类型和身份验证方法:
支持的源数据存储类型 支持的格式 支持的源身份验证类型 Azure Blob 带分隔符的文本 帐户密钥身份验证、共享访问签名身份验证、服务主体身份验证(使用 ServicePrincipalKey)、系统分配的托管标识身份验证 Parquet 帐户密钥身份验证、共享访问签名身份验证 ORC 帐户密钥身份验证、共享访问签名身份验证 Azure Data Lake Storage Gen2 带分隔符的文本
Parquet
ORC帐户密钥身份验证、服务主体身份验证(使用 ServicePrincipalKey)、共享访问签名身份验证、系统分配的托管标识身份验证 重要
- 对存储链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。
- 如果您的 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用托管身份验证,并且勾选“允许信任的 Microsoft 服务通过”选项。请参阅 使用 VNet 服务终结点对 Azure 存储的影响。
格式设置为如下所示:
- 对于“Parquet”: 可以为“无压缩”、“Snappy”或
compression。 - 对于 ORC:
compression可以为无压缩、zlib或Snappy。 - 对于带分隔符的文本:
-
rowDelimiter显式设置为单字符或“\r\n”,不支持默认值。 -
nullValue保留默认值或设置为空字符串 ("")。 -
encodingName保留默认值或设置为 utf-8 或 utf-16。 -
escapeChar必须与quoteChar相同,且不能为空。 -
skipLineCount保留默认值或设置为 0。 -
compression可以为无压缩或GZip。
-
- 对于“Parquet”: 可以为“无压缩”、“Snappy”或
如果源是文件夹,则必须将复制活动中的
recursive设置为 true,并且wildcardFilename需要为*或*.*。wildcardFolderPath、wildcardFilename(*或*.*除外)、modifiedDateTimeStart、modifiedDateTimeEnd、prefix、enablePartitionDiscovery和additionalColumns均未指定。
复制活动中的 allowCopyCommand 下支持以下 COPY 语句设置:
| 属性 | 描述 | 必需 |
|---|---|---|
| 默认值 | 指定Azure Synapse Analytics中每个目标列的默认值。 属性中的默认值将覆盖数据仓库中设置的 DEFAULT 约束,标识列不能有默认值。 | 否 |
| 附加选项 | 将直接在 COPY 语句的“With”子句中传递给 Azure Synapse Analytics COPY 语句的其他选项。 根据需要将值括在引号中,以符合 COPY 语句要求。 | 否 |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
使用 COPY 语句进行分阶段复制
当源数据与 COPY 语句原生不兼容时,请通过使用临时暂存的 Azure Blob 或 Azure Data Lake Storage Gen2 进行数据复制(不能使用 Azure Premium Storage)。 在这种情况下,该服务会自动转换数据,以满足 COPY 语句的数据格式要求。 然后,它会调用 COPY 语句将数据加载到Azure Synapse Analytics。 最后,它会从存储中清理临时数据。 若要详细了解如何通过暂存方式复制数据,请参阅暂存复制。
若要使用此功能,请创建一个 Azure Blob Storage 链接服务或 Azure Data Lake Storage Gen2 链接服务,并将 account 密钥或系统托管标识身份验证引用Azure存储帐户作为临时存储。
重要
- 对过渡链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。 您还需要在您的暂存 Azure Blob Storage 或 Azure Data Lake Storage Gen2 账户中,为 Azure Synapse Analytics 工作区的托管标识授予权限。 要了解如何授予此权限,请参阅向工作区托管标识授予权限。
- 如果你的过渡环境中 Azure Storage 配置了 VNet 服务终结点,则必须在存储帐户上使用启用“允许受信任的 Microsoft 服务”的托管标识身份验证,请参阅使用 VNet 服务终结点对 Azure Storage 的影响。
重要
如果您的暂存 Azure Storage 配置了托管专用终结点并启用了存储防火墙,则必须使用托管身份验证并向 Synapse SQL Server 授予存储 Blob 数据读取权限,以确保它在 COPY 语句加载期间能够访问暂存文件。
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
使用 PolyBase 将数据加载到 Azure Synapse Analytics
使用 PolyBase是将数据加载到吞吐量较高的Azure Synapse Analytics的有效方法。 使用 PolyBase 而非默认 BULKINSERT 机制可以实现吞吐量的巨大增加。
- 如果源数据位于 Azure Blob 或 Azure Data Lake Storage Gen2,并且 format 与 PolyBase 兼容,则可以使用复制活动直接调用 PolyBase 来让Azure Synapse Analytics从源中提取数据。 有关详细信息,请参阅 使用 PolyBase 直接复制 。
- 如果您的源数据存储和格式未被 PolyBase 初始支持,请使用 PolyBase 的暂存复制 功能作为替代。 暂存复制功能也能提供更高的吞吐量。 它会自动将数据转换为 PolyBase 兼容的格式,将数据存储在 Azure Blob 存储中,然后调用 PolyBase 将数据加载到Azure Synapse Analytics。
提示
详细了解有关如何使用 PolyBase 的最佳做法。 将 PolyBase 与 Azure Integration Runtime 一起使用时,对于直接或暂存存储到 Synapse 的有效 Data Integration Units (DIU)始终为 2。 优化 DIU 不会影响性能,因为从存储加载数据的功能由 Synapse 引擎提供支持。
在复制活动中的 polyBaseSettings 下支持以下 PolyBase 设置:
| 属性 | 描述 | 必需 |
|---|---|---|
| rejectValue | 指定在查询失败之前可以拒绝的行数或百分比。 在 允许的值为 0(默认值)、1、2 等。 |
否 |
| 拒绝类型 | 指定 rejectValue 选项是文本值还是百分比。 允许的值为 Value(默认值)和 Percentage。 |
否 |
| 拒绝样本值 | 确定在 PolyBase 重新计算被拒绝行的百分比之前要检索的行数。 允许的值为 1、2 等。 |
如果 rejectType 是 percentage,则为“是” |
| useTypeDefault | 指定在 PolyBase 从文本文件中检索数据时如何处理带分隔符的文本文件中的缺失值。 从 CREATE EXTERNAL FILE FORMAT (Transact-SQL) 的 Arguments 部分详细了解此属性。 允许的值为 True 和 False(默认值)。 |
否 |
使用 PolyBase 直接复制
Azure Synapse Analytics PolyBase 直接支持Azure Blob 和Azure Data Lake Storage Gen2。 如果源数据符合本节中所述的条件,请使用 PolyBase 直接从源数据存储复制到Azure Synapse Analytics。 否则,请改用使用 PolyBase 的分阶段复制。
如果不满足要求,服务会检查设置,并自动回退到 BULKINSERT 机制以进行数据移动。
源链接的服务使用以下类型和身份验证方法:
支持的源数据存储类型 支持的源身份验证类型 Azure Blob 帐户密钥身份验证、系统分配的托管标识身份验证 Azure Data Lake Storage Gen2 帐户密钥身份验证、系统分配的托管标识身份验证 重要
- 对存储链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。
- 如果您的 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用托管身份验证,并且勾选“允许信任的 Microsoft 服务通过”选项。请参阅 使用 VNet 服务终结点对 Azure 存储的影响。
源数据格式为 Parquet、ORC 或带分隔符的文本,具有以下配置:
- 文件夹路径不包含通配符筛选器。
- 文件名为空或指向单个文件。 如果在复制活动中指定通配符文件名,该通配符只能是
*或*.*。 -
rowDelimiter为 default、 \n、 \r\n 或 \r。 - 将
nullValue保留为默认值或设置为“空字符串”(“”),并将 保留为默认值或设置为 true。 -
encodingName保留为默认值或设置为 utf-8。 -
quoteChar、escapeChar和skipLineCount未指定。 PolyBase 支持跳过标头行,可将其配置为firstRowAsHeader。 -
compression可以为“无压缩”、 或“Deflate”。
如果源是文件夹,则必须将复制活动中的
recursive设置为 true。未指定
wildcardFolderPath、wildcardFilename、modifiedDateTimeStart、modifiedDateTimeEnd、prefix、enablePartitionDiscovery和additionalColumns。
注意
如果源是一个文件夹,请注意,PolyBase 将从该文件夹及其所有子文件夹中检索文件,并且它不会从文件名以下划线 (_) 或句点 (.) 开头的文件中检索数据,如此处 - LOCATION 参数所述。
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
使用 PolyBase 的分阶段复制
当源数据与 PolyBase 不兼容时,请通过 Azure Blob 或 Azure Data Lake Storage Gen2 临时暂存来复制数据(不能使用 Azure Premium Storage)。 在这种情况下,该服务会自动转换数据,以满足 PolyBase 的数据格式要求。 然后,它会调用 PolyBase 将数据加载到Azure Synapse Analytics。 最后,它会从存储中清理临时数据。 若要详细了解如何通过暂存方式复制数据,请参阅暂存复制。
若要使用此功能,请创建一个Azure Blob Storage链接服务或Azure Data Lake Storage Gen2链接服务,并将 Azure帐户密钥或托管标识身份验证称为临时存储。
重要
- 对过渡链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。 您还需要在您的暂存 Azure Blob Storage 或 Azure Data Lake Storage Gen2 账户中,为 Azure Synapse Analytics 工作区的托管标识授予权限。 要了解如何授予此权限,请参阅向工作区托管标识授予权限。
- 如果你的过渡环境中 Azure Storage 配置了 VNet 服务终结点,则必须在存储帐户上使用启用“允许受信任的 Microsoft 服务”的托管标识身份验证,请参阅使用 VNet 服务终结点对 Azure Storage 的影响。
重要
如果暂存Azure Storage配置了托管专用终结点并启用了存储防火墙,则必须使用托管标识身份验证并向 Synapse SQL Server授予存储 Blob 数据读取者权限,以确保它可以在 PolyBase 加载期间访问暂存的文件。
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
有关使用 PolyBase 的最佳做法
除了Azure Synapse Analytics中提到的最佳做法外,以下部分还提供最佳做法。
所需数据库权限
若要使用 PolyBase,将数据加载到 Azure Synapse Analytics 的用户必须对目标数据库具有 “CONTROL”权限。 一种实现方法是将该用户添加为 db_owner 角色的成员。 了解如何在 Azure Synapse Analytics 概述中执行此操作。
行大小和数据类型限制
PolyBase 负载限制为小于 1 MB 的行。 不能用它加载到 VARCHR(MAX)、NVARCHAR 或 VARBINARY(MAX)。 有关详细信息,请参阅 Azure Synapse Analytics 服务容量限制。
如果数据源中的行大于 1 MB,可能需要将源表垂直拆分为多个小型表。 确保每行的最大大小不超过该限制。 然后,可以使用 PolyBase 加载较小的表,并在Azure Synapse Analytics中合并在一起。
或者,对于具有此类较大列的数据,可以通过不采用 PolyBase 并关闭“允许 PolyBase”设置来加载数据。
Azure Synapse Analytics资源类
若要实现最佳吞吐量,请将更大的资源类分配给通过 PolyBase 将数据加载到Azure Synapse Analytics的用户。
排查 PolyBase 问题
加载到“小数”列
如果源数据采用文本格式或其他不兼容 PolyBase 的存储(使用分阶段复制和 PolyBase),并且它包含要加载到 Azure Synapse Analytics 小数列中的空值,则可能会出现以下错误:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
解决方法是在 PolyBase 设置的复制活动接收器中取消选择“使用类型默认值”选项(设为 false)。 “USE_TYPE_DEFAULT”是一项 PolyBase 本地设置,它指定 PolyBase 从文本文件中检索数据时,如何处理带分隔符的文本文件中的缺失值。
检查 Azure Synapse Analytics 中的 tableName 属性
下表举例说明如何在 JSON 数据集中指定 tableName 属性。 其中显示了架构和表名称的多个组合。
| DB 架构 | 表名称 | tableName JSON 属性 |
|---|---|---|
| dbo | MyTable | MyTable 或 dbo.MyTable 或 [dbo].[MyTable] |
| dbo1 | MyTable | dbo1.MyTable 或 [dbo1].[MyTable] |
| dbo | My.Table | [My.Table] 或 [dbo].[My.Table] |
| dbo1 | My.Table | [dbo1].[My.Table] |
如果看到以下错误,问题可能与为 tableName 属性指定的值有关。 有关为 tableName JSON 属性指定值的正确方法,请参阅上表。
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
具有默认值的列
目前,PolyBase 功能只接受与目标表中数量相同的列。 例如,某个表包含四列,其中一列定义了默认值。 输入数据仍需包含四列。 包含三列的输入数据集生成类似于以下消息的错误:
All columns of the table must be specified in the INSERT BULK statement.
NULL 值是特殊形式的默认值。 如果列是可为 null 的,那么该列的 Blob 中的输入数据可能为空。 但输入数据集中不能缺少该数据。 PolyBase 在 Azure Synapse Analytics 中在缺失值位置插入 NULL。
外部文件访问失败
如果收到以下错误,请确保使用托管标识身份验证,并向Azure Synapse工作区的托管标识授予存储 Blob 数据读取者权限。
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
有关详细信息,请参阅工作区创建后向受管理标识授予权限。
映射数据流属性
在映射数据流中转换数据时,可以从Azure Synapse Analytics读取和写入表。 有关详细信息,请参阅映射数据流中的源转换和汇聚转换。
源转换
特定于Azure Synapse Analytics的设置在源转换的 Source Options 选项卡中可用。
输入 选择将源指向某个表(等效于 Select * from <table-name>),还是输入自定义 SQL 查询。
启用暂存 强烈建议在生产工作负荷中使用此选项,特别是当数据来源于 Azure Synapse Analytics 时。 当你从管道中使用 Azure Synapse Analytics 源执行 data flow activity 时,系统会提示选择暂存位置存储帐户,并使用该帐户进行暂存数据加载。 从Azure Synapse Analytics加载数据是最快的机制。
- 对存储链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。
- 如果您的 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用托管身份验证,并且勾选“允许信任的 Microsoft 服务通过”选项。请参阅 使用 VNet 服务终结点对 Azure 存储的影响。
- 使用 Azure Synapse serverless SQL 池作为源时,不支持启用暂存。
查询:如果在“输入”字段中选择“查询”,请为源输入 SQL 查询。 此设置会替代在数据集中选择的任何表。 此处不支持 Order By 子句,但你可以设置完整的 SELECT FROM 语句。 还可以使用用户定义的表函数。 select * from udfGetData() 是 SQL 中可返回表的 UDF。 此查询将生成可以在数据流中使用的源表。 使用查询也是一种减少用于测试或查找的行数的好方法。
SQL 示例:Select * from MyTable where customerId > 1000 and customerId < 2000
批大小:输入批大小,以将大型数据分成多个读取操作。 在数据流中,会使用此设置来设置 Spark 分栏式缓存。 这是选项字段,如果留空,它将使用 Spark 默认值。
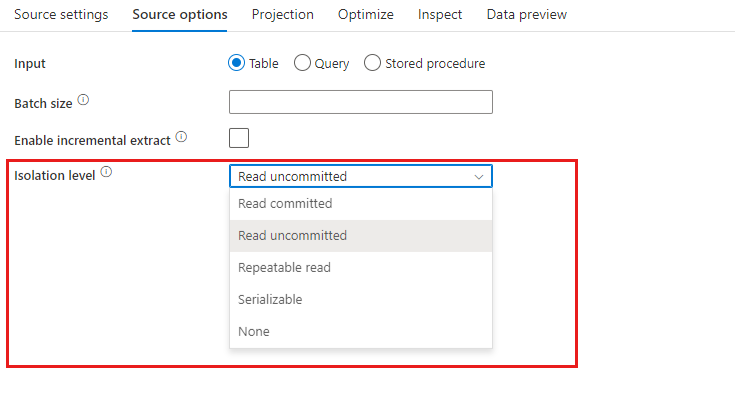
隔离级别: 映射数据流中 SQL 源的默认设置为“读取未提交的内容”。 你可以将此处的隔离级别更改为以下值之一:
- 读取已提交的内容
- 读取未提交的内容
- 可重复的读取
- 可序列化
- 无(忽略隔离级别)
接收器转换
特定于Azure Synapse Analytics的设置在汇聚转换的 Settings 选项卡中可用。
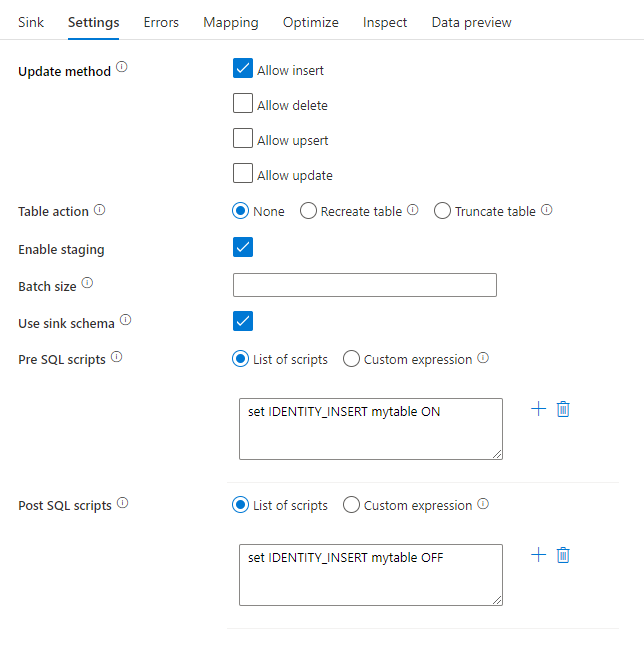
更新方法: 确定数据库目标上允许哪些操作。 默认设置为仅允许插入。 要更新、插入更新或删除行,必须进行 alter-row 变换来标记要执行这些操作的行。 对于更新、更新插入和删除操作,必须设置一个或多个键列,以确定要更改的行。
表操作: 确定在写入之前是否从目标表重新创建或删除所有行。
- 无:不会对表进行任何操作。
- 重新创建:将删除表并重新创建表。 创建新表时,如果是动态创建,这是必需的。
- 截断:将删除目标表格中的所有行。
启用暂存: 这允许使用复制命令加载到 Azure Synapse Analytics SQL 池中,建议用于大多数 Synapse 接收器。 暂存存储在 Execute Data Flow 活动中配置。
- 对存储链接服务使用托管标识身份验证时,请分别了解 Azure Blob 和 Azure Data Lake Storage Gen2 所需的配置。
- 如果您的 Azure 存储配置了 VNet 服务终结点,则必须在存储帐户上启用托管身份验证,并且勾选“允许信任的 Microsoft 服务通过”选项。请参阅 使用 VNet 服务终结点对 Azure 存储的影响。
批大小:控制每个 Bucket 中写入的行数。 较大的批大小可提高压缩比并改进内存优化,但在缓存数据时可能会导致内存不足异常。
使用接收器架构:默认情况下,将在接收器架构下创建临时表作为过渡。 可以选择取消选中“使用汇聚架构”选项,转而在“选择用户数据库架构”中指定架构名称。数据工厂将在所指定的架构名称下创建一个暂存表,用于加载上游数据,并在完成后自动清理这些数据。 请确保已在数据库中创建表权限,并更改对架构的权限。

预处理和后处理 SQL 脚本:输入将在数据写入接收器数据库之前(预处理)和之后(后处理)执行的多行 SQL 脚本
提示
- 建议将包含多个命令的单个批处理脚本拆分为多个批处理。
- 只有返回简单更新计数的数据定义语言 (Data Definition Language, DDL) 和数据操作语言 (Data Manipulation Language, DML) 语句可作为批处理的一部分运行。 在执行批量操作中了解详情
行处理时出错
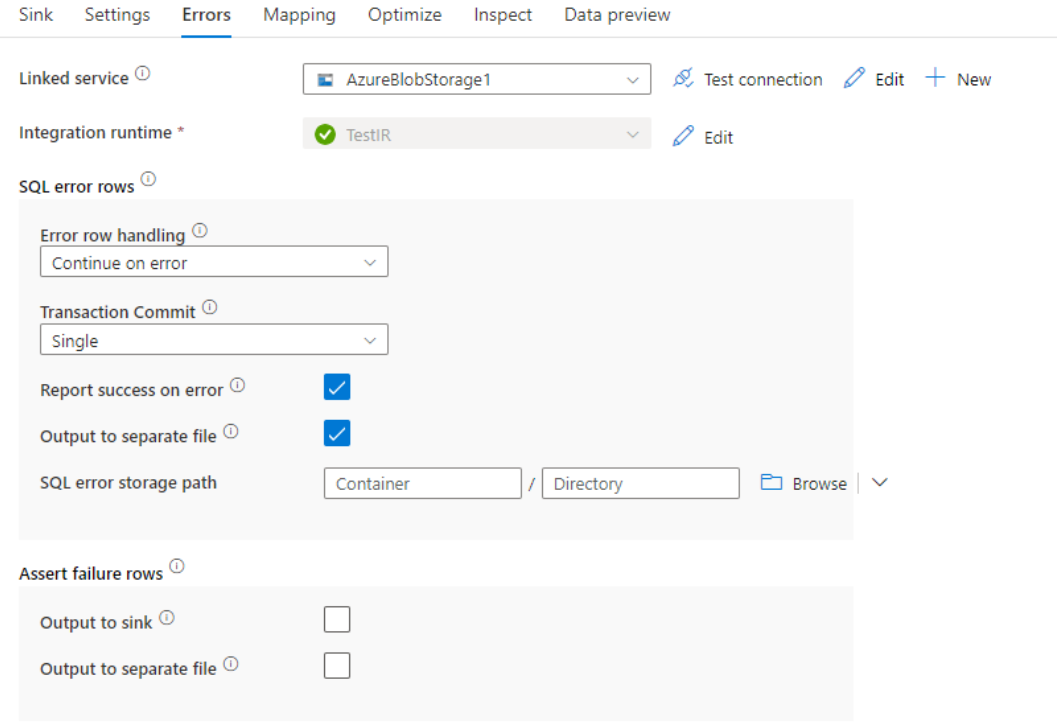
写入Azure Synapse Analytics时,由于目标设置的约束,某些数据行可能会失败。 一些常见错误包括:
- 字符串或二进制数据在表中会被截断
- 无法在列中插入 NULL 值
- 在将值转换成数据类型时失败
默认情况下,遇到第一个错误时,数据流运行会失败。 你可以选择“继续忽略错误”,这允许即使各行存在错误,数据流也能完成。 该服务提供了不同的选项来处理这些错误记录。
事务提交:选择是在单个事务中写入数据,还是分批写入数据。 单个事务将提供更好的性能,且事务完成之前,其他人将看不到任何写入的数据。 批处理事务的性能较差,但适用于大型数据集。
输出被拒绝的数据: 如果启用,则可以将错误行输出到您选择的Azure Blob Storage或Azure Data Lake Storage Gen2帐户中的csv文件中。 这会写入包含三个附加列的错误行:SQL 操作(例如插入或更新)、数据流错误代码,以及有关行的错误消息。
出错时报告成功:如果已启用,则即使发现了错误行,也会将数据流标记为成功。
查找活动属性
若要了解有关属性的详细信息,请查看 Lookup 活动。
GetMetadata 活动属性
若要了解有关属性的详细信息,请查看 GetMetadata 活动
Azure Synapse Analytics的数据类型映射
当您从Azure Synapse Analytics复制数据到Azure Synapse Analytics或从中复制数据时,以下映射用于将Azure Synapse Analytics的数据类型转换为Azure Data Factory的临时数据类型。 使用 Synapse 管道从/向Azure Synapse Analytics复制数据时也使用这些映射,因为管道也在Azure Synapse中实现Azure Data Factory。 若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
提示
请参阅 Azure Synapse Analytics 中的 Table 数据类型 一文,以了解 Azure Synapse Analytics 支持的数据类型以及不支持的数据类型的解决方法。
| Azure Synapse Analytics数据类型 | 数据工厂临时数据类型 |
|---|---|
| bigint | Int64 |
| 二进制 | Byte[] |
| 比特 | 布尔 |
| 字符型 | 字符串、Char[] |
| 日期 | 日期时间 |
| 日期时间 | 日期时间 |
| datetime2 | 日期时间 |
| 日期时间偏移量 (Datetimeoffset) | DateTimeOffset |
| 十进制 | 十进制 |
| FILESTREAM 属性 (varbinary(max)) | Byte[] |
| Float | 双精度 |
| 图像 | Byte[] |
| int(整数) | Int32 |
| 钱 | 十进制 |
| nchar | 字符串、Char[] |
| 数字 | 十进制 |
| nvarchar | 字符串、Char[] |
| 真实 | Single |
| 行版本号 (rowversion) | Byte[] |
| smalldatetime | 日期时间 |
| smallint | Int16 |
| smallmoney | 十进制 |
| 时间 | TimeSpan |
| tinyint | 字节 |
| 唯一标识符 (uniqueidentifier) | Guid |
| varbinary | Byte[] |
| varchar | 字符串、Char[] |
升级Azure Synapse Analytics版本
在升级 Azure Synapse Analytics 版本时,在 编辑链接服务 页面上,选择 版本 下的 推荐,并参考 推荐版本的链接服务属性 来配置链接服务。
建议版本和旧版本之间的差异
下表显示了使用推荐版本和旧版Azure Synapse Analytics之间的差异。
| 建议的版本 | 旧版本 |
|---|---|
支持 TLS 1.3 通过 encrypt 作为 strict。 |
不支持 TLS 1.3。 |
相关内容
有关复制活动支持作为源和接收器的数据存储的列表,请参阅支持的数据存储和格式。