适用于: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Azure Data Factory提供了一种高性能、可靠且经济高效的机制,用于将数据从本地 HDFS 大规模迁移到 Azure Blob 存储或Azure Data Lake Storage Gen2。
数据工厂提供了两种基本方法,用于将数据从本地 HDFS 迁移到 Azure。 你可以根据自己的情况选择所需的方法。
- 数据工厂 DistCp 模式(建议):在数据工厂中, 可以使用 DistCp(分布式副本)将 as-is 的文件复制到 Azure Blob 存储(包括 staged copy) 或 Azure Data Lake Store Gen2。 使用与 DistCp 集成的数据工厂可以利用现有的强大群集来实现最佳复制吞吐量。 此外,还能受益于数据工厂提供的灵活计划功能和统一的监视体验。 根据数据工厂配置,复制活动会自动构造 DistCp 命令,将数据提交到 Hadoop 群集,然后监视复制状态。 建议使用数据工厂 DistCp 模式将数据从本地 Hadoop 群集迁移到 Azure。
- 数据工厂本机集成运行时模式:DistCp 并非在所有情况下都适用。 例如,在 Azure 虚拟网络环境中,DistCp 工具不支持通过 Azure ExpressRoute 的 Azure Storage 虚拟网络终结点的专用对等连接。 此外,在某些情况下,你不希望使用现有的 Hadoop 群集作为引擎来迁移数据,因此你不会在群集上施加繁重的负载,这可能影响现有 ETL 作业的性能。 相反,可以使用数据工厂集成运行时的本机功能作为将数据从本地 HDFS 复制到Azure的引擎。
本文提供上述两种方法的以下信息:
- 性能
- 复制复原能力
- 网络安全
- 高级解决方案体系结构
- 实现最佳做法
性能
在数据工厂 DistCp 模式下,吞吐量与单独使用 DistCp 工具时相同。 数据工厂 DistCp 模式可以最大限度地利用现有 Hadoop 群集的容量。 可以使用 DistCp 在群集之间或群集内部进行大规模复制。
DistCp 使用 MapReduce 来影响数据分发、错误处理和恢复以及报告。 它将文件和目录列表扩展成任务映射的输入。 每个任务复制源列表中指定的文件分区。 使用与 DistCp 集成的数据工厂,可以生成管道来充分利用网络带宽、存储 IOPS 和带宽,以最大化环境的数据移动吞吐量。
数据工厂本机集成运行时模式还允许不同级别的并行度。 可以使用并行度来充分利用网络带宽、存储 IOPS 和带宽,以最大化数据移动吞吐量。
- 单个复制活动可以利用可缩放的计算资源。 使用自承载集成运行时可以手动纵向扩展计算机或横向扩展到多个计算机(最多 4 个节点)。 单个复制活动将在所有节点之间对其文件集进行分区。
- 单个复制活动使用多个线程读取和写入数据存储。
- 数据工厂控制流可以同时启动多个复制活动。 例如,可以使用 For Each 循环。
有关详细信息,请参阅复制活动性能指南。
复原能力
在数据工厂 DistCp 模式下,可以使用不同的 DistCp 命令行参数(例如,-i 表示忽略失败;-update 表示当源文件和目标文件的大小不同时写入数据)来实现不同级别的复原能力。
在数据工厂本机集成运行时模式下,在单个复制活动运行中,数据工厂具有内置的重试机制。 它可以处理数据存储或底层网络中特定级别的暂时性故障。
从本地 HDFS 复制到 Blob 存储和从本地 HDFS 复制到 Data Lake Store Gen2 时,数据工厂会在很大程度上自动执行检查点。 如果某个复制活动运行失败或超时,在后续重试时(请确保重试计数 > 1),复制将从上一个失败点继续,而不是从头开始。
网络安全
默认情况下,数据工厂使用通过 HTTPS 协议的加密连接将数据从本地 HDFS 传输到 Blob 存储或Azure Data Lake Storage Gen2。 HTTPS 提供传输中数据加密,并可防止窃听和中间人攻击。
如果你不希望通过公共 Internet 传输数据,可以通过 ExpressRoute 使用专用对等互连链路传输数据,以提高安全性。
解决方案体系结构
此图描绘了如何通过公共 Internet 迁移数据:
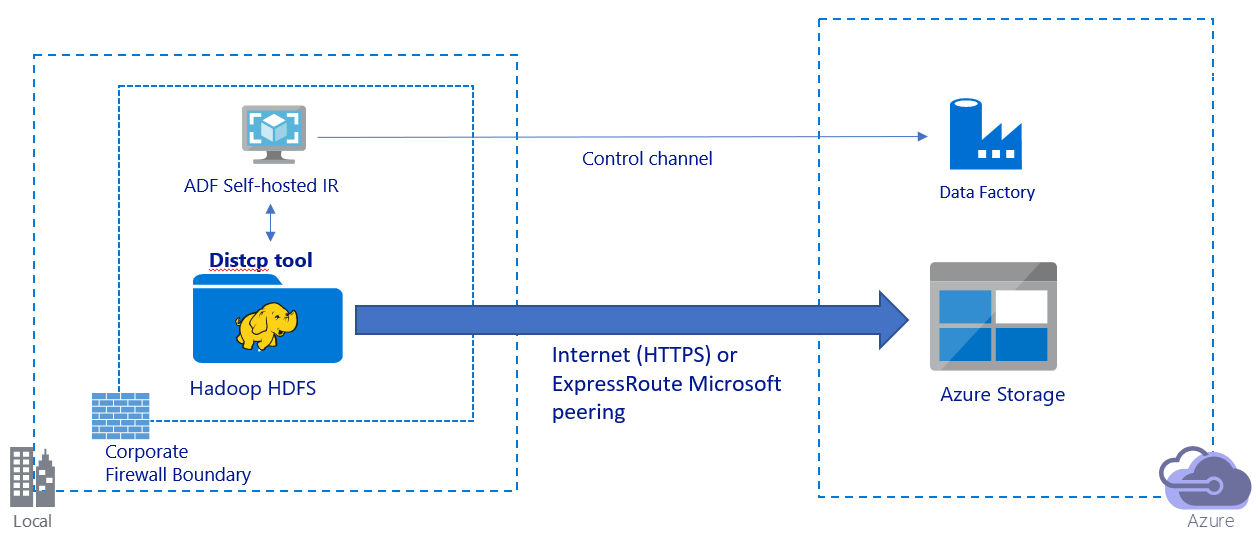
- 在此体系结构中,将通过公共 Internet 使用 HTTPS 安全传输数据。
- 我们建议在公用网络环境中使用数据工厂 DistCp 模式。 可以利用现有的强大群集来实现最佳复制吞吐量。 此外,还能受益于数据工厂提供的灵活计划功能和统一的监视体验。
- 对于此体系结构,必须在企业防火墙后面的Windows计算机上安装数据工厂自承载集成运行时,才能将 DistCp 命令提交到 Hadoop 群集并监视复制状态。 由于该计算机不是用于移动数据的引擎(仅用于控制),因此,该计算机的容量不会影响数据移动吞吐量。
- 支持 DistCp 命令的现有参数。
此图描绘了如何通过专用链路迁移数据:
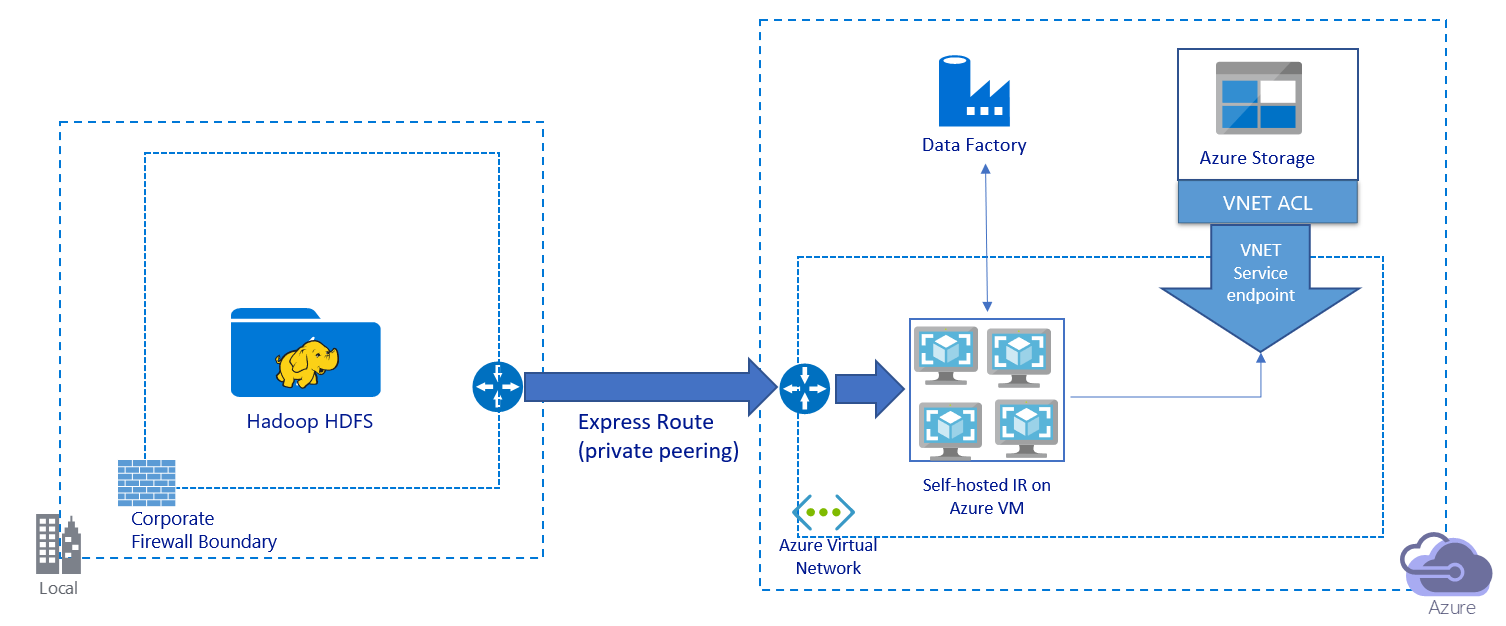
- 在此体系结构中,数据通过 Azure ExpressRoute 的专用对等互连链接进行迁移。 数据永远不会遍历公共 Internet。
- DistCp 工具不支持与 Azure Storage 虚拟网络终结点的 ExpressRoute 专用对等互连。 我们建议通过集成运行时使用数据工厂的本机功能来迁移数据。
- 对于此体系结构,必须在Azure虚拟网络中的Windows VM 上安装数据工厂自承载集成运行时。 可以手动扩展单个 VM 的规模,或增加多个 VM,以充分利用网络和存储的 IOPS 或带宽。
- 对于每个安装了数据工厂自承载集成运行时的 Azure VM,建议配置为 Standard_D32s_v3,即32个虚拟CPU和128 GB内存。 可以在数据迁移过程中监视 VM 的 CPU 和内存使用率,以确定是否需要进一步扩展 VM 来提高性能,或缩减 VM 来降低成本。
- 还可以通过将最多 4 个 VM 节点关联到一个自承载集成运行时进行横向扩展。 针对自承载集成运行时运行的单个复制作业将自动为文件集分区,并利用所有 VM 节点来并行复制文件。 为实现高可用性,我们建议从两个 VM 节点着手,以避免在数据迁移过程中出现单一故障点。
- 使用此体系结构时,可以实现初始快照数据迁移和增量数据迁移。
实现最佳做法
我们建议在实现数据迁移时遵循这些最佳做法。
身份验证和凭据管理
- 若要向 HDFS 进行身份验证,可以使用 Windows(Kerberos)或 Anonymous。
- 支持多种身份验证类型连接到 Azure Blob 存储。 强烈建议对Azure资源使用 托管标识。 基于 Microsoft Entra ID 中自动管理的数据工厂标识,托管标识使你能够在配置管道时,不需要在链接服务定义中提供凭据。 或者,可以使用服务主体、共享访问签名或存储帐户密钥对 Blob 存储进行身份验证。
- 还支持多种身份验证类型来连接到Data Lake Storage Gen2。 强烈建议对 Azure 资源使用 托管标识,但也可以使用 服务主体 或 存储帐户密钥。
- 如果不对Azure资源使用托管标识,我们强烈建议
在 Azure Key Vault 以便更轻松地集中管理和轮换密钥,而无需修改数据工厂链接服务。
初始快照数据迁移
在数据工厂 DistCp 模式下,可以创建一个复制活动来提交 DistCp 命令,并使用不同的参数来控制初始数据迁移行为。
在数据工厂本机集成运行时模式下,我们建议使用数据分区,尤其是在迁移 10 TB 以上的数据时。 若要将数据分区,请使用 HDFS 中的文件夹名称。 然后,每个数据工厂复制作业一次可以复制一个文件夹分区。 可以同时运行多个数据工厂复制作业,以获得更好的吞吐量。
如果网络或数据存储的暂时性问题导致任何复制作业失败,你可以重新运行失败的复制作业,以从 HDFS 中加载特定的分区。 加载其他分区的其他复制作业不受影响。
增量数据迁移
在数据工厂的 DistCp 模式下,可以使用 DistCp 命令行参数 -update 来在源文件和目标文件大小不同时写入数据,以实现增量数据迁移。
在数据工厂本地集成模式下,识别 HDFS 中新文件或改动文件的最高效方法是采用时间分区命名规范。 如果 HDFS 中的数据经过时间分区,并且文件或文件夹名称中包含时间切片信息(例如 /yyyy/mm/dd/file.csv),则管道可以轻松识别要增量复制的文件和文件夹。
或者,如果 HDFS 中的数据未经过时间分区,则数据工厂可使用文件的 LastModifiedDate 值来识别新文件或已更改的文件。 数据工厂扫描 HDFS 中的所有文件,仅复制上次修改时间戳大于某一组值的新文件和已更新的文件。
如果 HDFS 中有大量文件,则初始文件扫描可能需要很长时间,而不管有多少个文件与筛选条件相匹配。 在这种情况下,我们建议先使用用于初始快照迁移的同一分区将数据分区。 然后,文件扫描可以并行进行。
估算价格
请考虑以下管道将数据从 HDFS 迁移到 Azure Blob 存储:
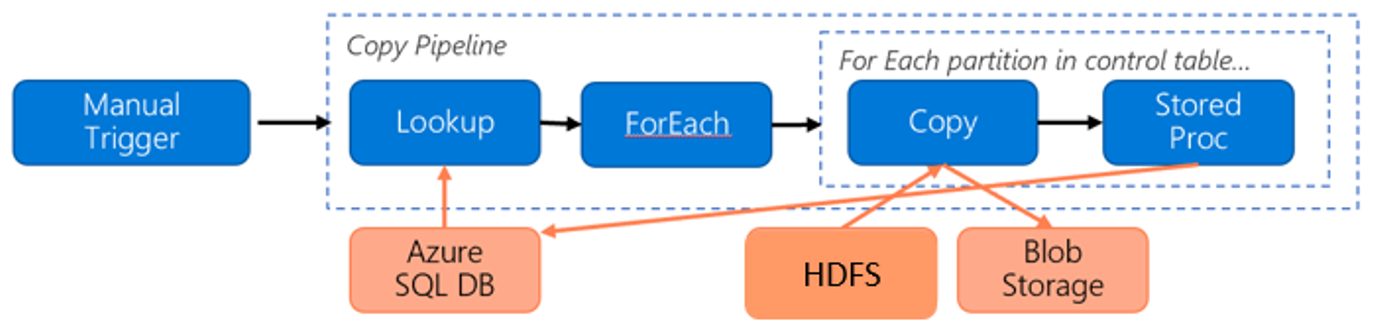
假设以下信息:
- 总数据量为 1 PB。
- 使用数据工厂的本机集成运行时模式来迁移数据。
- 1 PB 划分为 1,000 个分区,每个复制操作移动一个分区。
- 为每个复制活动配置了一个关联到 4 个计算机的自承载 集成运行时,可实现 500 MBps 的吞吐量。
- ForEach 并发性设置为 4,聚合吞吐量为 2 GBps。
- 完成迁移总共需要花费 146 小时。
下面是根据上述假设估算出的价格:
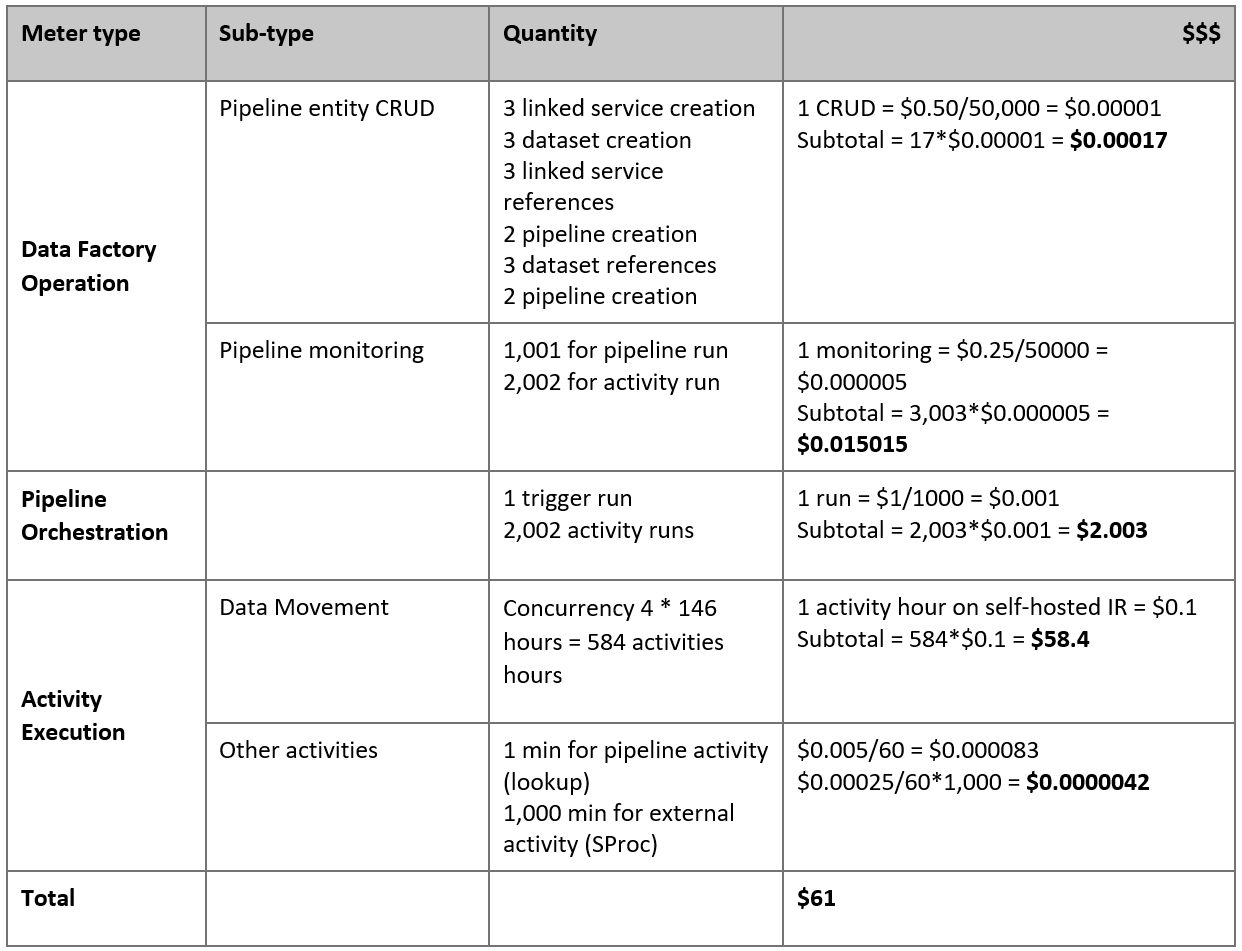
注意
这是一个虚构的定价示例。 您的实际定价依赖于您环境中的实际吞吐量。 不包括安装了自托管集成运行时的 Azure Windows 虚拟机的价格。
其他参考
- HDFS 连接器
- Azure Blob 存储连接器
- Azure Data Lake Storage Gen2 连接器
- 复制操作性能调优指南
- 创建和配置自承载集成运行时
- 自托管集成运行时的高可用性和可伸缩性
- 数据移动安全注意事项
- 在 Azure Key Vault 中存储凭据
- 基于时间分区文件名增量复制文件
- 基于 LastModifiedDate 复制新文件和修改过的文件
- 数据工厂定价页
相关内容
使用 Azure Data Factory