适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
本文介绍如何使用 Azure 数据工厂或 Synapse Analytics 管道通过 Open Hub 将 SAP Business Warehouse (BW) 中的数据复制到 Azure Data Lake Storage Gen2。 可以使用类似的过程将数据复制到其他受支持的接收器数据存储。
提示
有关如何从 SAP BW 复制数据的一般信息,包括 SAP BW Open Hub 集成和增量提取流程,请参阅使用 Azure 数据工厂通过 Open Hub 复制 SAP Business Warehouse 中的数据。
先决条件
Azure 数据工厂或 Synapse 工作区:如果你没有所需的数据工厂或工作区,请遵循创建数据工厂或创建 Synapse 工作区的步骤进行操作。
目标类型为“数据库表”的 SAP BW Open Hub 目标 (OHD):若要创建 OHD 或检查你的 OHD 是否已针对服务集成正确进行配置,请参阅本文的 SAP BW Open Hub 目标配置部分。
SAP BW 用户需要以下权限:
- 远程函数调用 (RFC) 和 SAP BW 的授权。
- 对 S_SDSAUTH 授权对象的“执行”活动的权限。
一个自承载集成运行时 (IR) 和 SAP .NET 连接器 3.0。 遵循以下安装步骤:
安装并注册自承载集成运行时 3.13 或更高版本。 (本文稍后会介绍此过程。)
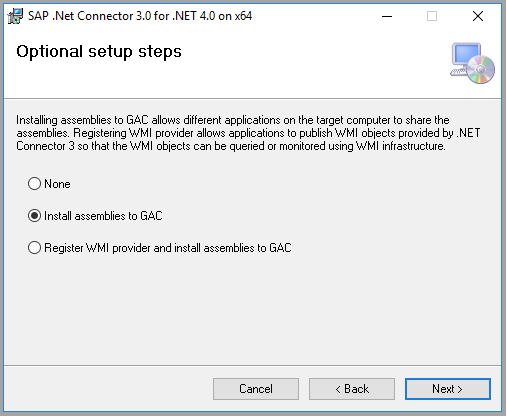
从 SAP 网站下载 64 位 SAP Connector for Microsoft .NET 3.0,并将其安装到自承载 IR 所在的同一台计算机上。 在安装期间,请务必在“可选安装步骤”对话框中选择“将程序集安装到 GAC”,如下图所示:
从 SAP BW Open Hub 执行完整复制
在 Azure 门户中,转到你的服务。 在“打开 Azure 数据工厂工作室”或“打开 Synapse Studio”磁贴上选择“打开”,在单独的选项卡中打开服务 UI 。
在主页上,选择“引入”以打开“复制数据”工具。
在“属性”页上,在“任务类型”下选择“内置复制任务”,在“任务节奏或任务计划”下选择“现在运行一次”,然后选择“下一步”。
在“源数据存储”页上,选择“+ 新建连接”。 从连接器库中选择“SAP BW Open Hub”,然后选择“继续”。 若要筛选连接器,可在搜索框中键入 SAP。
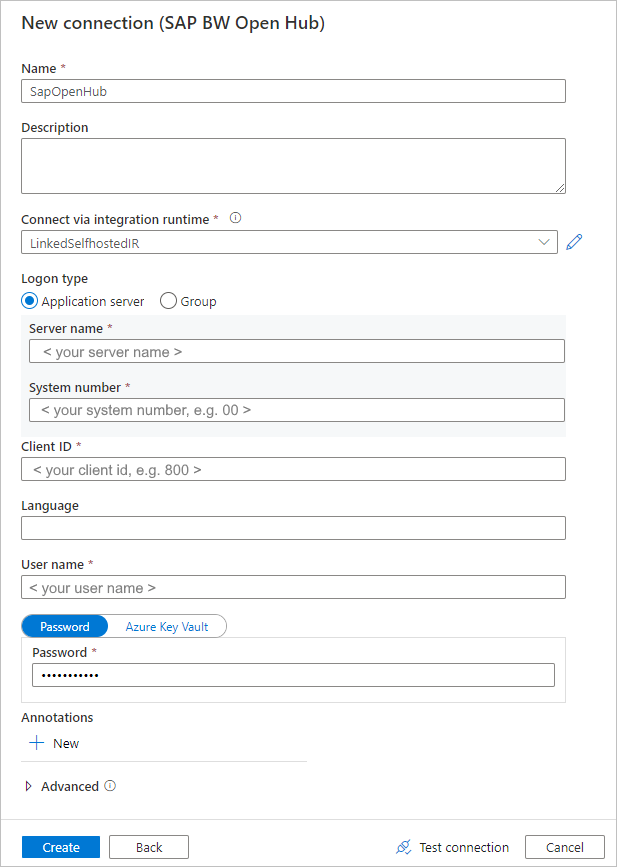
在“新建连接 (SAP BW Open Hub)”页上,按照以下步骤创建新连接。
在“通过集成运行时进行连接”列表中,选择一个现有的自承载 IR。 如果你没有自承载 IR,请创建一个。
若要创建新的自承载 IR,请依次选择“+新建”、“自承载”。 输入名称,然后选择“下一步”。 选择“快速安装”以在当前计算机上安装,或遵循提供的“手动设置”步骤。
如先决条件中所述,请确保在运行自承载 IR 的同一台计算机上安装 SAP Connector for Microsoft .NET 3.0。
填写 SAP BW 的“服务器名称”、“系统编号”、“客户端 ID”、“语言”(如果不是“EN”)、“用户名”和“密码”。
选择“测试连接”以验证设置,然后选择“创建” 。
在“源数据存储”页上的“连接”块中选择新创建的连接 。
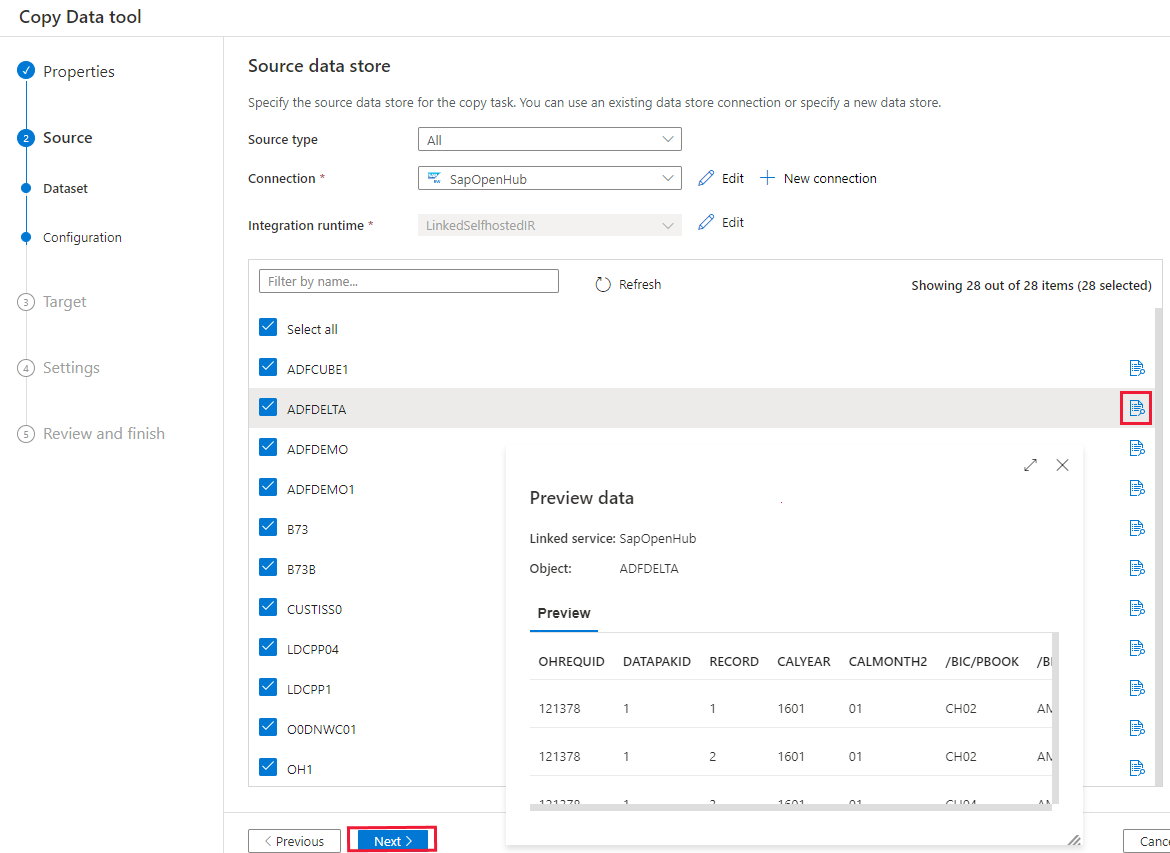
在选择 Open Hub 目标的部分中,浏览 SAP BW 中可用的 Open Hub 目标。 通过选择每个行末尾的预览按钮,可以预览每个目标中的数据。 选择要从中复制数据的 OHD,然后选择“下一步”。
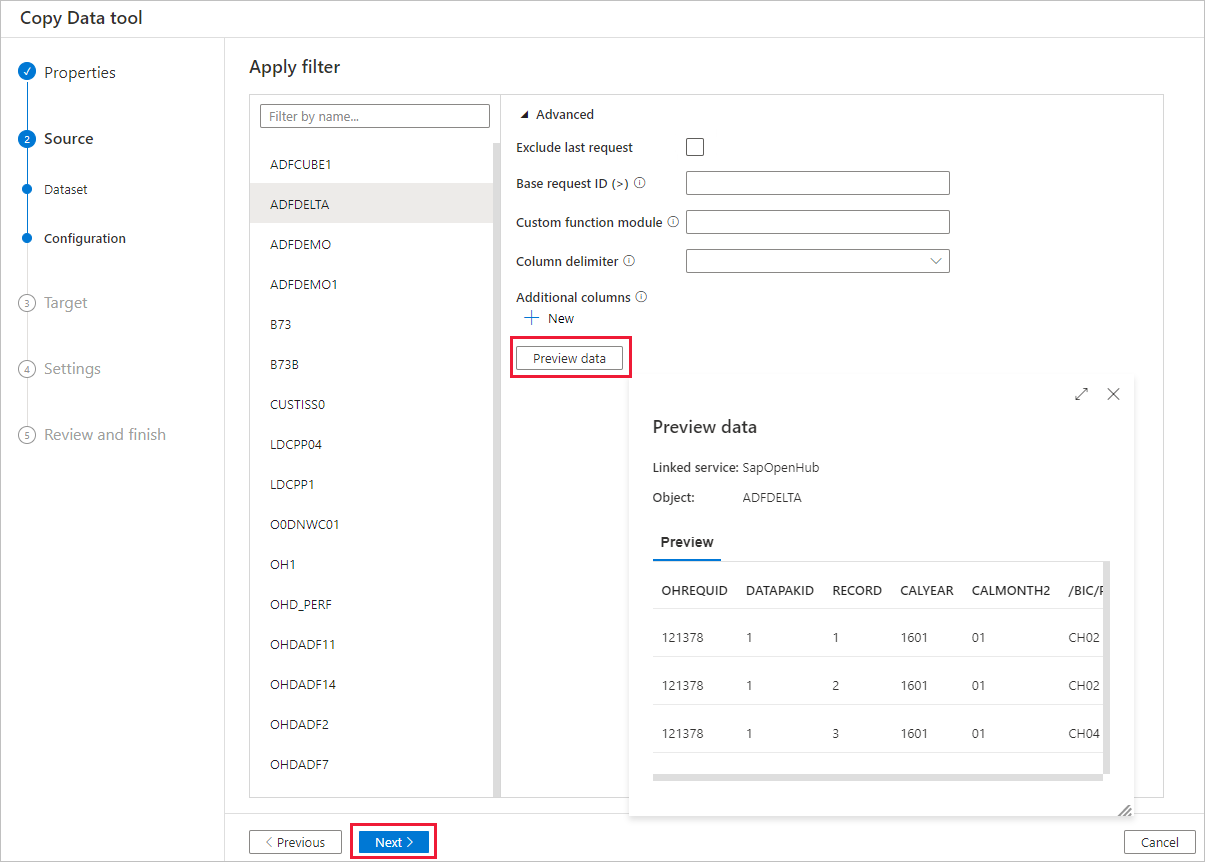
如果需要,请指定筛选器。 如果 OHD 仅包含来自具有单一请求 ID 的单一数据传输过程 (DTP) 执行中的数据,或者确定 DTP 已完成并且想要复制数据,请清除“高级”部分中的“排除最后一个请求”复选框 。 可以通过选择“预览数据”按钮来预览数据。
请在本文的 SAP BW Open Hub 目标配置部分详细了解这些设置。 然后,选择“下一步” 。
在“目标数据存储”页中,选择“+ 新建连接”“Azure Data Lake Storage Gen2”“继续”。
在“新建连接(Azure Data Lake Storage Gen2)”页中,按以下步骤操作来创建连接。
- 在“名称”下拉列表中,选择支持 Data Lake Storage Gen2 的帐户。
- 选择“创建”以创建连接。
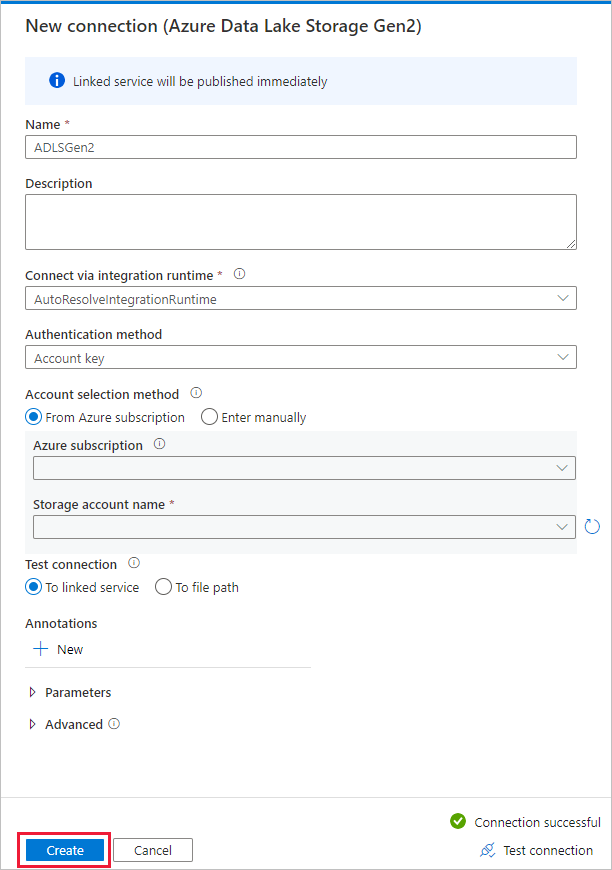
在“目标数据存储”页上的“连接”部分中选择新创建的连接,然后输入“copyfromopenhub”作为输出文件夹名称。 然后,选择“下一步” 。
在“文件格式设置”页上,选择“下一步”以使用默认设置。
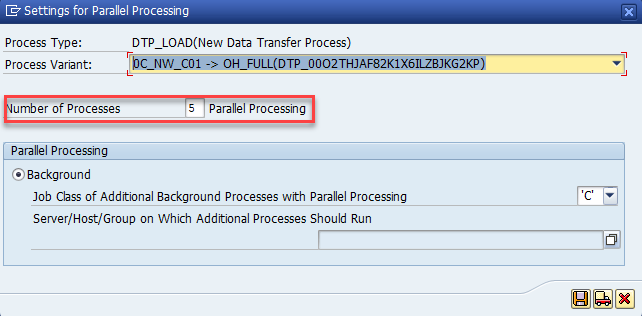
在“设置”页上,指定“任务名称”,然后展开“高级”。 为“复制并行度”输入一个值(例如 5),表示从 SAP BW 加载数据的并行度。 然后,选择“下一步” 。

在“摘要”页上复查设置。 然后,选择“下一步” 。
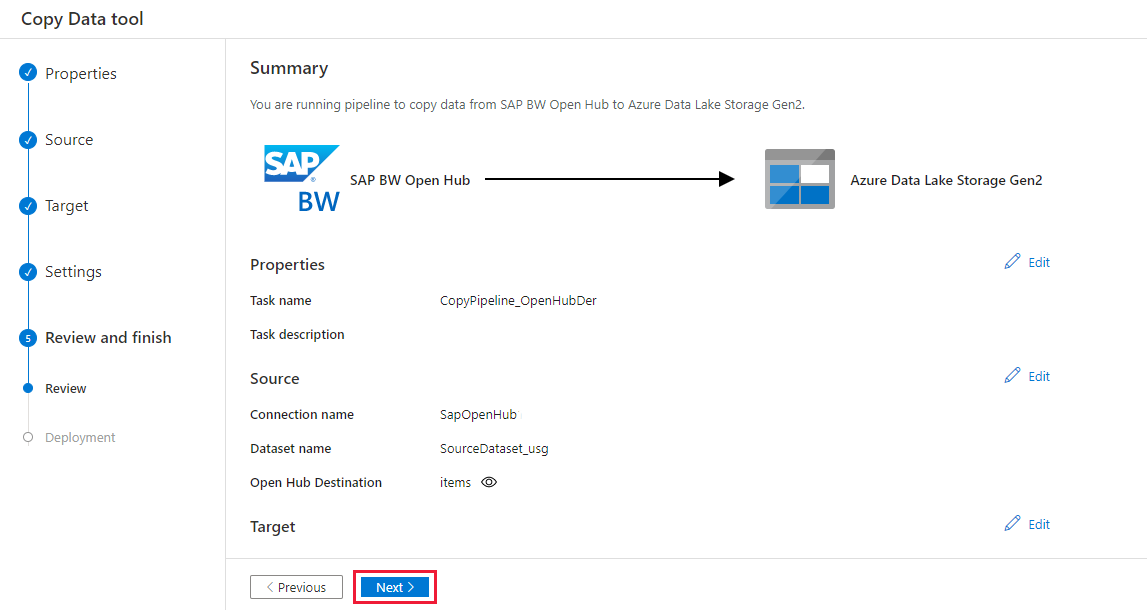
在“部署”页上,选择“监视”以监视管道。
请注意,页面左侧的“监视”选项卡已自动选择。 可以使用“管道运行”页中“管道名称”列下的链接来查看活动详细信息以及重新运行该管道。
若要查看与管道运行关联的活动运行,请选择“管道名称”列下面的链接。 该管道只包含一个活动(复制活动),因此只显示了一个条目。 若要切换回到管道运行视图,请选择顶部的“所有管道运行”链接。 选择“刷新”可刷新列表。

若要监视每个复制活动的执行详细信息,请选择“详细信息”链接,也就是活动监视视图中每个复制活动的同一行中的眼镜图标。 提供的详细信息包括从源复制到接收器的数据量、数据吞吐量、执行步骤和持续时间,以及使用的配置。
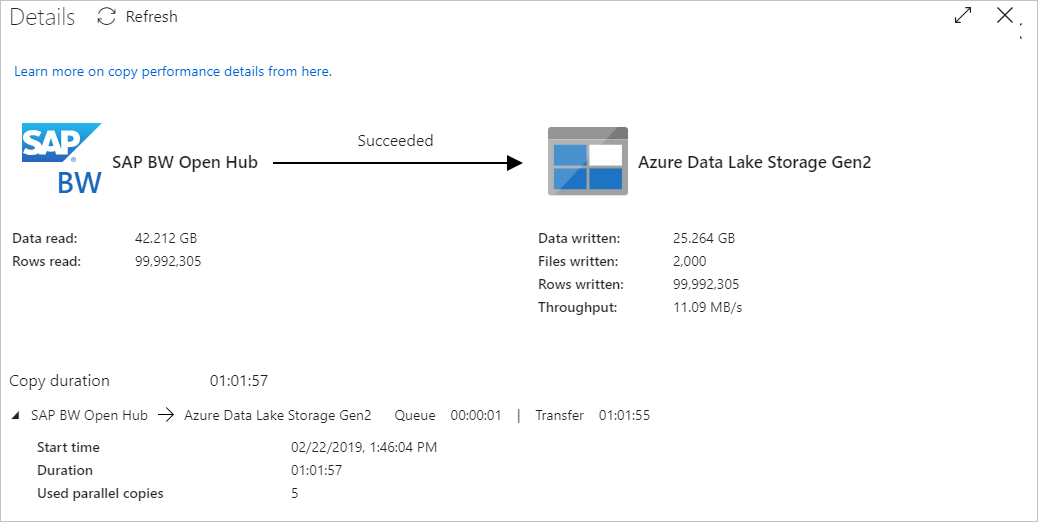
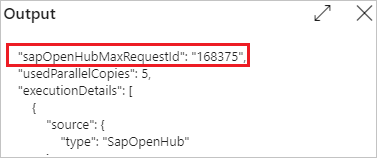
要查看每个复制活动的“最大请求 ID”,请返回活动监控视图并在每个复制活动的同一行中选择“输出”。

从 SAP BW Open Hub 执行增量复制
提示
请参阅 SAP BW Open Hub 连接器增量提取流,了解 SAP BW Open Hub 连接器如何从 SAP BW 复制增量数据。 此文还可帮助你了解基本的连接器配置。
现在,让我们继续配置从 SAP BW Open Hub 执行的增量复制。
增量复制使用基于请求 ID 的“高水印”机制。 该 ID 是由 DTP 在 SAP BW Open Hub 目标中自动生成的。 下图演示了此工作流:

在主页上,选择“发现更多”部分中的“管道模板”以使用内置模板 。
搜索 SAP BW,找到并选择“从 SAP BW 增量复制到 Azure Data Lake Storage Gen2”模板。 此模板将数据复制到 Azure Data Lake Storage Gen2。 可以使用类似的工作流将数据复制到其他接收器类型。
在模板的主页上,选择或创建以下三个连接,然后选择窗口右下角的“使用此模板”。
- Azure Blob 存储:在本演练中,我们将使用 Azure Blob 存储来存储高水印,即最大复制请求 ID。
- SAP BW Open Hub:这是要从中复制数据的源。 有关详细配置,请参考前面的完整复制演练。
- Azure Data Lake Storage Gen2:这是要将数据复制到的接收器。 有关详细配置,请参考前面的完整复制演练。
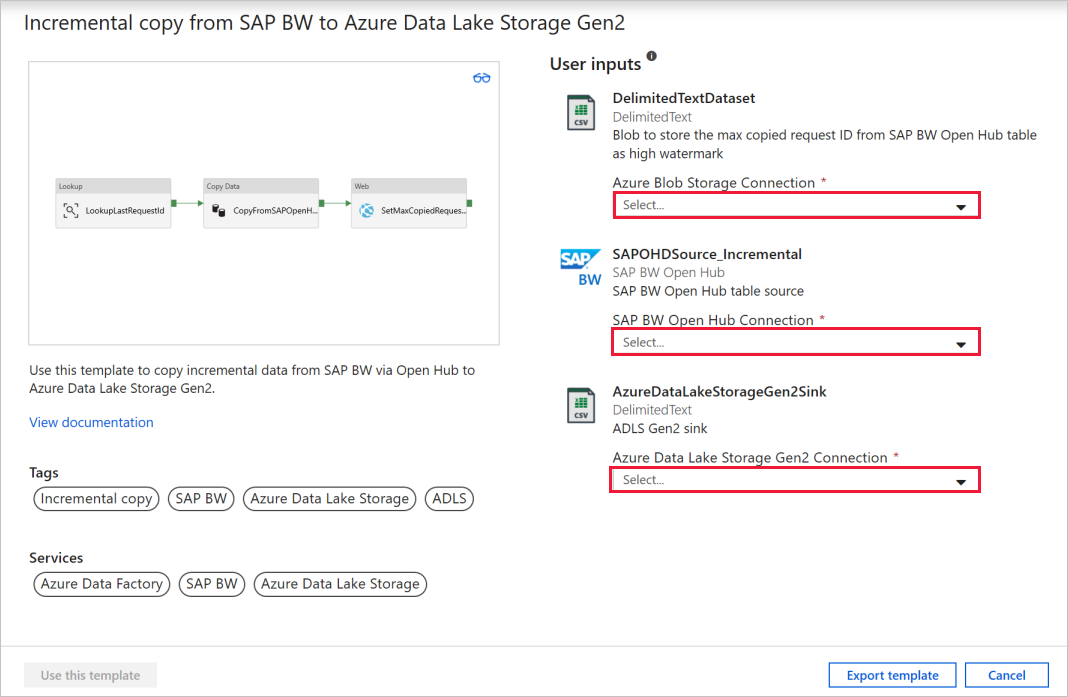
此模板生成包含以下三个活动的管道,并在成功时将这些管道链接到一起:“查找”、“复制数据”和“Web”。
转到管道的“参数”选项卡。 你将看到需要提供的所有配置。
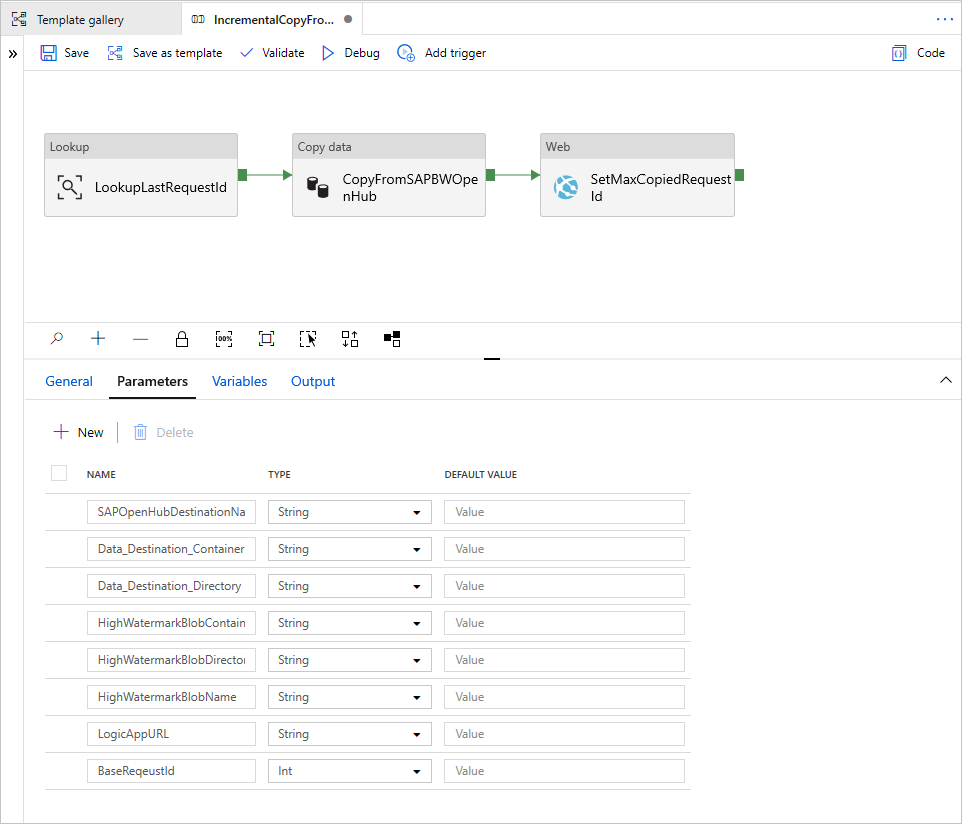
SAPOpenHubDestinationName:指定要从中复制数据的 Open Hub 表名称。
Data_Destination_Container:指定要将数据复制到的目标 Azure Data Lake Storage Gen2 容器。 如果该容器不存在,则复制活动将在执行期间创建一个容器。
Data_Destination_Directory:指定要将数据复制到的 Azure Data Lake Storage Gen2 容器下的文件夹路径。 如果该路径不存在,则复制活动将在执行期间创建一个路径。
HighWatermarkBlobContainer:指定用于存储高水印值的容器。
HighWatermarkBlobDirectory:指定用于存储高水印值的容器下的文件夹路径。
HighWatermarkBlobName:指定用于存储高水印值的 Blob 名称,例如
requestIdCache.txt。 在 Blob 存储中,转到 HighWatermarkBlobContainer+HighWatermarkBlobDirectory+HighWatermarkBlobName 的相应路径,例如“container/path/requestIdCache.txt” 。 创建包含内容 0 的 Blob。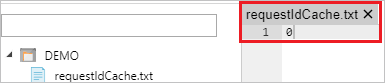
LogicAppURL:在此模板中,我们将使用 WebActivity 来调用 Azure 逻辑应用,以便在 Blob 存储中设置高水印值。 或者,可以使用 Azure SQL 数据库来存储该值。 使用存储过程活动来更新该值。
必须先创建逻辑应用,如下图所示。 然后,粘贴 HTTP POST URL。
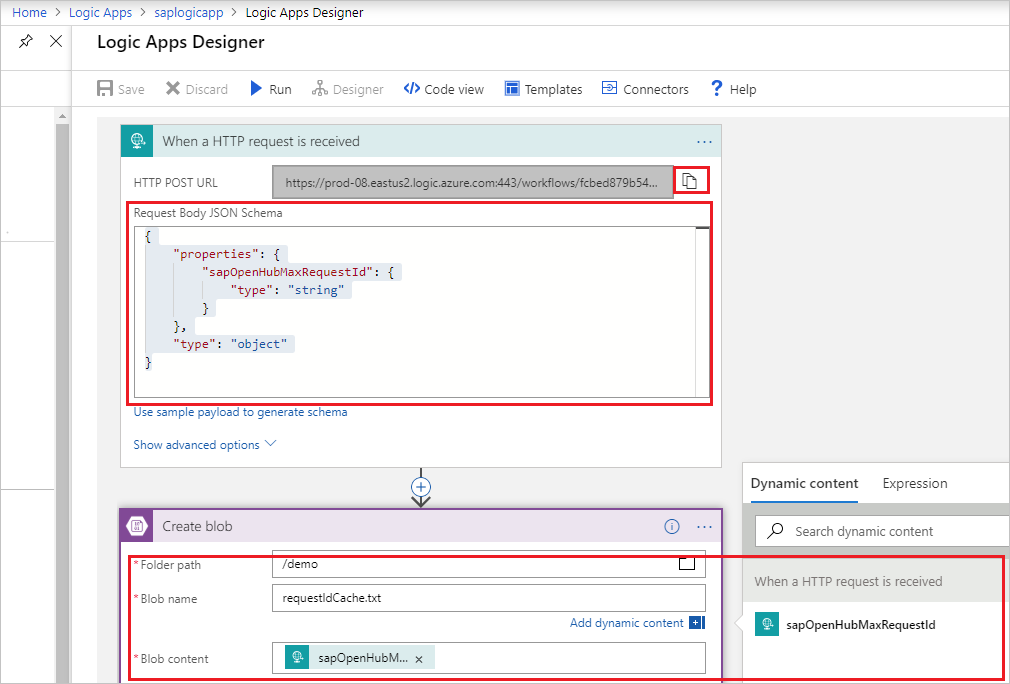
转到 Azure 门户。 选择一个新的“逻辑应用”服务。 选择“+空白逻辑应用”转到“逻辑应用设计器”。
创建“收到 HTTP 请求时”触发器。 按如下所示指定 HTTP 请求正文:
{ "properties": { "sapOpenHubMaxRequestId": { "type": "string" } }, "type": "object" }添加“创建 Blob”操作。 对于“文件夹路径”和“Blob 名称”,请使用前面在 HighWatermarkBlobContainer+HighWatermarkBlobDirectory 和 HighWatermarkBlobName 中配置的相同值。
选择“保存” 。 然后,复制“HTTP POST URL”的值以便在管道中使用。
提供管道参数后,选择“调试”“完成”以调用一个运行来验证配置 。 或者,选择“发布”以发布所有更改,然后选择“添加触发器”以执行运行。
SAP BW Open Hub 目标配置
本部分介绍如何在 SAP BW 端进行配置,以使用 SAP BW Open Hub 连接器来复制数据。
在 SAP BW 中配置增量提取
如果需要历史副本和增量副本,或者只需要增量副本,请在 SAP BW 中配置增量提取。
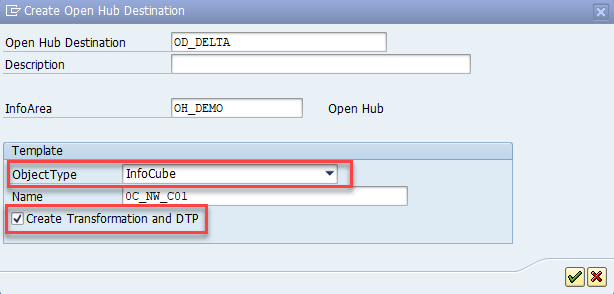
创建 Open Hub 目标。 可以在 SAP Transaction RSA1 中创建 OHD,这会自动创建所需的转换和数据传输过程。 使用以下设置:
- 对象类型:可以使用任何对象类型。 此处我们使用 InfoCube 作为示例。
- 目标类型:选择“数据库表”。
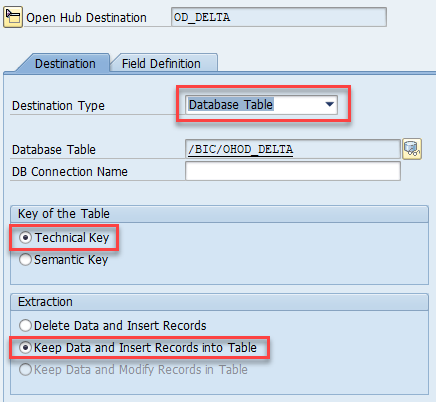
- 表键:选择“技术键”。
- 提取:选择“保留数据并将记录插入到表中”。
可能提高 DTP 的并行运行 SAP 工作进程数:
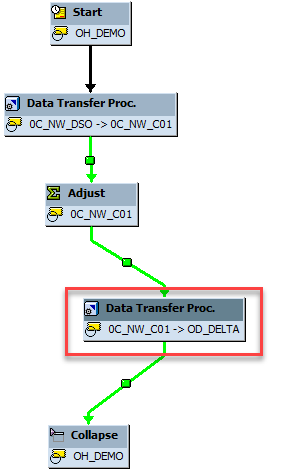
在进程链中计划 DTP。
仅当所需的行未压缩时,针对多维数据集的增量 DTP 才能正常工作。 在对 Open Hub 表运行 DTP 之前,请确保 BW 多维数据集压缩未运行。 为此,最简单的方法是将 DTP 集成到现有的进程链中。 在以下示例中,DTP(针对 OHD)已插入到进程链中的“调整”(聚合汇总)与“折叠”(多维数据集压缩)步骤之间。
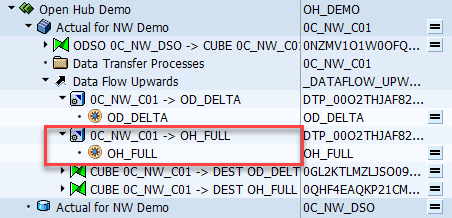
在 SAP BW 中配置完整提取
除了增量提取以外,还可以配置同一 SAP BW InfoProvider 的完整提取。 若要执行完整复制而不是增量复制,或者要重新同步增量提取,则你通常会这样做。
不能对同一个 OHD 使用多个 DTP。 因此,在执行增量提取之前,必须先创建一个附加的 OHD。
对于满负载 OHD,请选择不同于增量提取的选项:
在 OHD 中:将“提取”选项设置为“删除数据并插入记录”。 否则,在 BW 进程链中重复 DTP 时,会多次提取数据。
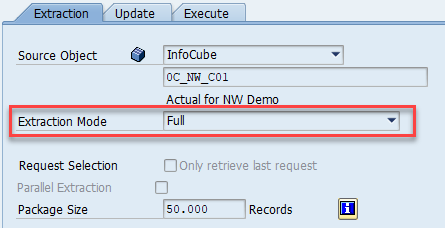
在 DTP 中:将“提取模式”设置为“完整”。 在创建 OHD 后,必须紧接着将自动创建的 DTP 从“增量”更改为“完整”,如下图所示:
在 BW Open Hub 连接器中:禁用“排除最后一个请求”。 否则不会提取任何内容。
你通常会手动运行完整 DTP。 或者,可为完整 DTP 创建一个进程链。 它通常是一个与现有进程链不相关的独立链。 对于任一做法,请确保在使用复制活动开始提取之前已完成 DTP。 否则,只会复制部分数据。
首次运行增量提取
从技术上讲,首次增量提取属于完整提取。 默认情况下,SAP BW Open Hub 连接器在复制数据时会排除最后一个请求。 对于首次增量提取,在后续 DTP 在具有不同请求 ID 的表中生成增量数据之前,复制活动不会提取任何数据。 可通过两种方式来避免这种情况:
- 针对首次增量提取禁用“排除最后一个请求”选项。 在首次启动增量提取之前,确保已完成首次增量 DTP。
- 使用下一部分所述的重新同步增量提取的过程。
重新同步增量提取
出现以下情况时,会更改 SAP BW 多维数据集中的数据,但增量 DTP 将忽略此类情况:
- SAP BW 选择性删除行(使用任何筛选条件)
- SAP BW 请求删除(错误的请求)
SAP Open Hub 目标不是受数据市场控制的数据目标(自 2015 年开始已包含在所有 SAP BW 支持包中)。 因此,无需更改 OHD 中的数据即可删除多维数据集中的数据。 然后,必须将多维数据集的数据与服务重新同步:
- 在服务中运行完整提取(使用 SAP 中的完整 DTP)。
- 删除增量 DTP 的 Open Hub 表中的所有行。
- 将增量 DTP 的状态设置为“已提取”。
然后,所有后续增量 DTP 和增量提取都会按预期方式工作。
若要将增量 DTP 的状态设置为“已提取”,可以使用以下选项来手动运行增量 DTP:
没有数据传输;源中的增量状态:已提取
相关内容
了解 SAP BW Open Hub 连接器支持: