适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
在本教程中,你将创建一个包含管道的Azure Data Factory,该管道将增量数据从SQL Server数据库中的多个表加载到Azure SQL Database。
在本教程中执行以下步骤:
- 准备源和目标数据存储。
- 创建数据工厂。
- 创建自我托管的集成运行时。
- 安装 Integration Runtime。
- 创建链接服务。
- 创建源、接收器和水印数据集。
- 创建、运行和监视管道。
- 查看结果。
- 在源表中添加或更新数据。
- 重新运行和监视管道。
- 查看最终结果。
概述
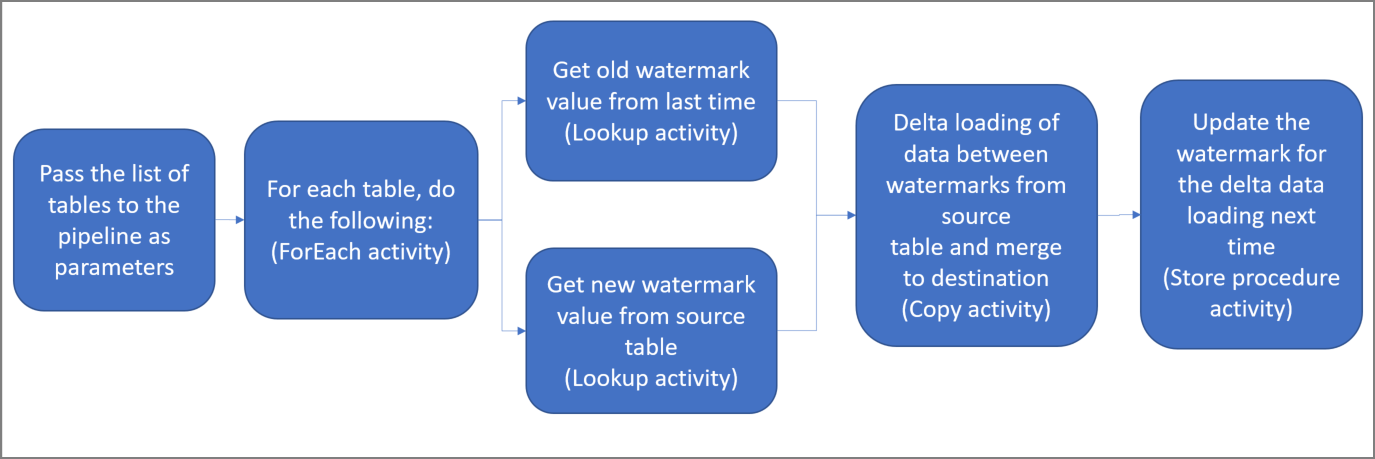
下面是创建此解决方案所要执行的重要步骤:
选择水印列。
为源数据存储中的每个表选择一个列,你可以在其中标识每次运行的新记录或更新记录。 通常,在创建或更新行时,此选定列中的数据(例如 last_modify_time 或 ID)会不断递增。 此列中的最大值用作水印。
准备一个数据存储库以存储水印值。
本教程在 SQL 数据库中存储水印值。
创建包含以下活动的管道:
创建一个 ForEach 活动,用于遍历管道中作为参数传递的源表名称列表。 对于每个源表,它会调用以下活动,为该表执行增量加载。
创建两个 Lookup 活动。 使用第一个 Lookup 活动检索上一个水印值。 使用第二个 Lookup 活动检索新的水印值。 这些水印值将传递给Copy activity。
创建一个Copy activity,从源数据存储复制行,其中水印列的值大于旧水印值且小于或等于新水印值。 然后,它会将源数据存储中的增量数据作为新文件复制到Azure Blob 存储。
创建 StoredProcedure 活动,用于更新下一次运行的管道的水印值。
下面是高级解决方案示意图:
如果没有Azure订阅,请在开始前创建 trial 帐户。
先决条件
- SQL Server。 本教程使用 SQL Server 数据库作为源数据存储。
-
Azure SQL Database。 在 Azure SQL Database 中使用数据库作为接收器数据存储。 如果没有 SQL 数据库,请参阅
在 Azure SQL Database 获取创建一个数据库的步骤。
在 SQL Server 数据库中创建源表
打开 SQL Server Management Studio (SSMS) 或 Visual Studio Code,然后连接到SQL Server数据库。
在 Server Explorer (SSMS) 或 Connections 窗格(Visual Studio Code)中,右键单击数据库并选择 New Query。
对数据库运行以下 SQL 命令,以便创建名为
customer_table和project_table的表:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime ); INSERT INTO customer_table (PersonID, Name, LastModifytime) VALUES (1, 'John','9/1/2017 12:56:00 AM'), (2, 'Mike','9/2/2017 5:23:00 AM'), (3, 'Alice','9/3/2017 2:36:00 AM'), (4, 'Andy','9/4/2017 3:21:00 AM'), (5, 'Anny','9/5/2017 8:06:00 AM'); INSERT INTO project_table (Project, Creationtime) VALUES ('project1','1/1/2015 0:00:00 AM'), ('project2','2/2/2016 1:23:00 AM'), ('project3','3/4/2017 5:16:00 AM');
在Azure SQL Database中创建目标表
打开 SQL Server Management Studio (SSMS) 或 Visual Studio Code,然后连接到SQL Server数据库。
在 Server Explorer (SSMS) 或 Connections 窗格(Visual Studio Code)中,右键单击数据库并选择 New Query。
对数据库运行以下 SQL 命令,以便创建名为
customer_table和project_table的表:create table customer_table ( PersonID int, Name varchar(255), LastModifytime datetime ); create table project_table ( Project varchar(255), Creationtime datetime );
在Azure SQL Database中创建另一个表来存储高水印值
针对数据库运行以下 SQL 命令,创建一个名为
watermarktable的表来存储水印值:create table watermarktable ( TableName varchar(255), WatermarkValue datetime, );将两个源表的初始水印值插入水印表中。
INSERT INTO watermarktable VALUES ('customer_table','1/1/2010 12:00:00 AM'), ('project_table','1/1/2010 12:00:00 AM');
在Azure SQL Database中创建存储过程
运行以下命令,在数据库中创建存储过程。 此存储过程在每次管道运行后更新水印值。
CREATE PROCEDURE usp_write_watermark @LastModifiedtime datetime, @TableName varchar(50)
AS
BEGIN
UPDATE watermarktable
SET [WatermarkValue] = @LastModifiedtime
WHERE [TableName] = @TableName
END
在 Azure SQL Database 中创建数据类型和其他存储过程
运行以下查询,在数据库中创建两个存储过程和两个数据类型。 以便将源表中的数据合并到目标表中。
为了方便入门,我们直接使用这些存储过程通过表变量来传入增量数据,然后将其合并到目标存储中。 请注意,不能将大量的增量行(超过 100 行)存储在表变量中。
如果需要将大量增量行合并到目标存储中,建议先使用复制活动将所有增量数据复制到目标存储中的临时“临时”表中,然后生成自己的存储过程,而无需使用表变量将它们从“暂存”表合并到“最终”表。
CREATE TYPE DataTypeforCustomerTable AS TABLE(
PersonID int,
Name varchar(255),
LastModifytime datetime
);
GO
CREATE PROCEDURE usp_upsert_customer_table @customer_table DataTypeforCustomerTable READONLY
AS
BEGIN
MERGE customer_table AS target
USING @customer_table AS source
ON (target.PersonID = source.PersonID)
WHEN MATCHED THEN
UPDATE SET Name = source.Name,LastModifytime = source.LastModifytime
WHEN NOT MATCHED THEN
INSERT (PersonID, Name, LastModifytime)
VALUES (source.PersonID, source.Name, source.LastModifytime);
END
GO
CREATE TYPE DataTypeforProjectTable AS TABLE(
Project varchar(255),
Creationtime datetime
);
GO
CREATE PROCEDURE usp_upsert_project_table @project_table DataTypeforProjectTable READONLY
AS
BEGIN
MERGE project_table AS target
USING @project_table AS source
ON (target.Project = source.Project)
WHEN MATCHED THEN
UPDATE SET Creationtime = source.Creationtime
WHEN NOT MATCHED THEN
INSERT (Project, Creationtime)
VALUES (source.Project, source.Creationtime);
END
Azure PowerShell
按照 Install 中的说明安装最新的Azure PowerShell模块,并配置 Azure PowerShell。
创建数据工厂
为资源组名称定义一个变量,稍后会在 PowerShell 命令中使用该变量。 将以下命令文本复制到 PowerShell,用双引号指定Azure资源组的名称,然后运行该命令。 示例为
"adfrg"。$resourceGroupName = "ADFTutorialResourceGroup";如果该资源组已存在,请勿覆盖它。 为
$resourceGroupName变量分配另一个值,然后再次运行命令定义一个用于数据工厂位置的变量。
$location = "China East 2"若要创建Azure资源组,请运行以下命令:
New-AzResourceGroup $resourceGroupName $location如果该资源组已存在,请勿覆盖它。 为
$resourceGroupName变量分配另一个值,然后再次运行命令定义一个用于数据工厂名称的变量。
重要
更新数据工厂名称,使之全局唯一。 例如,ADFIncMultiCopyTutorialFactorySP1127。
$dataFactoryName = "ADFIncMultiCopyTutorialFactory";要创建数据工厂,请运行以下 Set-AzDataFactoryV2 cmdlet:
Set-AzDataFactoryV2 -ResourceGroupName $resourceGroupName -Location $location -Name $dataFactoryName
请注意以下几点:
数据工厂的名称必须全局唯一。 如果收到以下错误,请更改名称并重试:
Set-AzDataFactoryV2 : HTTP Status Code: Conflict Error Code: DataFactoryNameInUse Error Message: The specified resource name 'ADFIncMultiCopyTutorialFactory' is already in use. Resource names must be globally unique.若要创建数据工厂实例,用于登录Azure的用户帐户必须是参与者或所有者角色的成员,或者是Azure订阅的管理员。
您可以在以下页面选择感兴趣的区域,然后展开 Analytics 找到 Data Factory:按区域提供的产品,以获取当前数据工厂可用的 Azure 区域列表。 数据工厂使用的数据存储(Azure Storage、SQL 数据库、SQL Managed Instance等)和计算(Azure HDInsight等)可以位于其他区域。
创建自承载集成运行时
在本部分中,你将创建一个自承载集成运行时,并将其与本地计算机与 SQL Server 数据库相关联。 自承载集成运行时是将数据从计算机上的SQL Server复制到Azure SQL Database的组件。
创建一个适用于 Integration Runtime 名称的变量。 使用唯一的名称,并记下它。 本教程后面部分需要使用它。
$integrationRuntimeName = "ADFTutorialIR"创建自我托管的集成运行时。
Set-AzDataFactoryV2IntegrationRuntime -Name $integrationRuntimeName -Type SelfHosted -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName下面是示例输出:
Name : <Integration Runtime name> Type : SelfHosted ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.DataFactory/factories/<DataFactoryName>/integrationruntimes/ADFTutorialIR若要检索所创建的 Integration Runtime 的状态,请运行以下命令。 确认 State 属性的值已设置为 NeedRegistration。
Get-AzDataFactoryV2IntegrationRuntime -name $integrationRuntimeName -ResourceGroupName $resourceGroupName -DataFactoryName $dataFactoryName -Status下面是示例输出:
State : NeedRegistration Version : CreateTime : 9/24/2019 6:00:00 AM AutoUpdate : On ScheduledUpdateDate : UpdateDelayOffset : LocalTimeZoneOffset : InternalChannelEncryption : Capabilities : {} ServiceUrls : {chinae2.frontend.datamovement.azure.cn} Nodes : {} Links : {} Name : ADFTutorialIR Type : SelfHosted ResourceGroupName : <ResourceGroup name> DataFactoryName : <DataFactory name> Description : Id : /subscriptions/<subscription ID>/resourceGroups/<ResourceGroup name>/providers/Microsoft.DataFactory/factories/<DataFactory name>/integrationruntimes/<Integration Runtime name>若要检索用于将自承载集成运行时注册到云中Azure Data Factory服务的身份验证密钥,请运行以下命令:
Get-AzDataFactoryV2IntegrationRuntimeKey -Name $integrationRuntimeName -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName | ConvertTo-Json下面是示例输出:
{ "AuthKey1": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx=", "AuthKey2": "IR@0000000000-0000-0000-0000-000000000000@xy0@xy@yyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyyy=" }复制其中一个密钥(去除双引号),用于注册将在以下步骤中安装到计算机上的自承载集成运行时。
安装集成运行时工具
如果已在计算机上安装 Integration Runtime,请使用“添加或删除程序”将其卸载。
下载自托管集成运行时到本地Windows计算机上。 进行安装。
在 欢迎使用 Microsoft Integration Runtime 安装程序页面上,选择下一步。
在“最终用户许可协议”页上接受许可协议的条款,然后选择“下一步” 。
在“目标文件夹”页上选择“下一步”。
在 准备安装 Microsoft Integration Runtime 页上,选择 安装。
在完成Microsoft Integration Runtime安装程序页上,选择Finish。
在 Register Integration Runtime (自承载) 页上,粘贴在上一部分中保存的密钥,然后选择 注册。
在“新建 Integration Runtime(自托管)节点”页面上,选择“完成”。
成功注册自托管集成运行时后,您会看到以下消息:
在Register Integration Runtime(自承载)页面上,选择启动配置管理器。
将节点连接到云服务后,会看到以下页:
现在,测试与SQL Server数据库的连接。
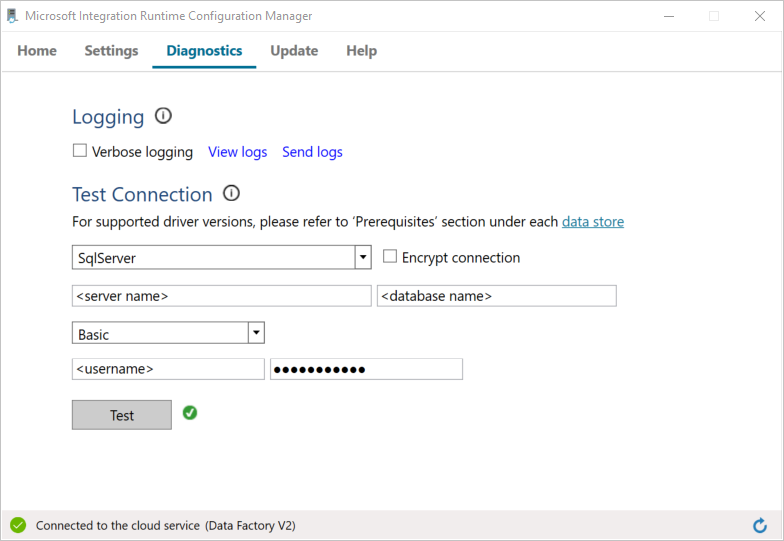
a。 在 Configuration Manager 页上,转到 Diagnostics 选项卡。
b. 选择“SqlServer”作为数据源类型。
c. 输入服务器名称。
d. 输入数据库名称。
e. 选择身份验证模式。
f. 输入用户名。
g. 输入与用户名关联的密码。
h. 选择 Test 以确认集成运行时可以连接到SQL Server。 如果连接成功,则会看到绿色勾号。 如果连接不成功,则会看到错误消息。 修复任何问题,并确保集成运行时可以连接到SQL Server。
注意
记下身份验证类型、服务器、数据库、用户和密码的值。 本教程后面会用到它们。
创建链接服务
可在数据工厂中创建链接服务,将数据存储和计算服务链接到数据工厂。 在本部分中,您将为 SQL Server 数据库和 Azure SQL 数据库创建链接服务。
创建SQL Server链接服务
在此步骤中,将SQL Server数据库链接到数据工厂。
使用以下内容在 C:\ADFTutorials\IncCopyMultiTableTutorial 文件夹中创建一个名为 SqlServerLinkedService.json 的 JSON 文件(如果本地文件夹尚不存在,请创建它们)。 根据用于连接到SQL Server的身份验证选择正确的部分。
重要
根据用于连接到SQL Server的身份验证选择正确的部分。
如果使用 SQL 身份验证,请复制以下 JSON 定义:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=False;data source=<servername>;initial catalog=<database name>;user id=<username>;Password=<password>" }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }如果使用Windows authentication,请复制以下 JSON 定义:
{ "name":"SqlServerLinkedService", "properties":{ "annotations":[ ], "type":"SqlServer", "typeProperties":{ "connectionString":"integrated security=True;data source=<servername>;initial catalog=<database name>", "userName":"<username> or <domain>\\<username>", "password":{ "type":"SecureString", "value":"<password>" } }, "connectVia":{ "referenceName":"<integration runtime name>", "type":"IntegrationRuntimeReference" } } }重要
- 根据用于连接到SQL Server的身份验证选择正确的部分。
- 将 <integration runtime name> 替换为集成运行时的名称。
- 在保存文件之前,请将<servername>、<databasename>、<username>和<password>替换为您的SQL Server数据库中的相应值。
- 如需在用户帐户或服务器名称中使用斜杠字符 (
\),请使用转义字符 (\)。 示例为mydomain\\myuser。
在 PowerShell 中,运行以下 cmdlet 切换到 C:\ADFTutorials\IncCopyMultiTableTutorial 文件夹。
Set-Location 'C:\ADFTutorials\IncCopyMultiTableTutorial'运行 Set-AzDataFactoryV2LinkedService cmdlet 以创建链接服务 AzureStorageLinkedService。 在以下示例中,传递 ResourceGroupName 和 DataFactoryName 参数的值:
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SqlServerLinkedService" -File ".\SqlServerLinkedService.json"下面是示例输出:
LinkedServiceName : SqlServerLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerLinkedService
创建 SQL 数据库链接服务
使用以下内容,在 C:\ADFTutorials\IncCopyMultiTableTutorial 文件夹中创建名为 AzureSQLDatabaseLinkedService.json 的 JSON 文件。 (创建文件夹 ADF(如果尚未存在)。替换<服务器名称>、<数据库名>、<用户名>和<密码>,使用您的SQL Server数据库名、数据库名称、用户名和密码,然后保存该文件。)
{ "name":"AzureSQLDatabaseLinkedService", "properties":{ "annotations":[ ], "type":"AzureSqlDatabase", "typeProperties":{ "connectionString":"integrated security=False;encrypt=True;connection timeout=30;data source=<servername>.database.chinacloudapi.cn;initial catalog=<database name>;user id=<user name>;Password=<password>;" } } }在 PowerShell 中运行 Set-AzDataFactoryV2LinkedService cmdlet,以便创建链接服务 AzureSQLDatabaseLinkedService。
Set-AzDataFactoryV2LinkedService -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "AzureSQLDatabaseLinkedService" -File ".\AzureSQLDatabaseLinkedService.json"下面是示例输出:
LinkedServiceName : AzureSQLDatabaseLinkedService ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlDatabaseLinkedService
创建数据集
在此步骤中,请创建多个数据集,分别表示数据源、数据目标以及用于存储水印的位置。
创建源数据集
在同一文件夹中,创建包含以下内容的名为 SourceDataset.json 的 JSON 文件:
{ "name":"SourceDataset", "properties":{ "linkedServiceName":{ "referenceName":"SqlServerLinkedService", "type":"LinkedServiceReference" }, "annotations":[ ], "type":"SqlServerTable", "schema":[ ] } }管道中的Copy activity使用 SQL 查询来加载数据,而不是加载整个表。
运行 Set-AzDataFactoryV2Dataset cmdlet 以创建数据集 SourceDataset。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SourceDataset" -File ".\SourceDataset.json"下面是该 cmdlet 的示例输出:
DatasetName : SourceDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.SqlServerTableDataset
创建接收器数据集
在同一文件夹中,创建包含以下内容的名为 SinkDataset.json 的 JSON 文件。 tableName 元素由管道在运行时动态设置。 管道中的 ForEach 活动循环访问一个包含表名的列表,每一次迭代都将表名传递到此数据集。
{ "name":"SinkDataset", "properties":{ "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" }, "parameters":{ "SinkTableName":{ "type":"String" } }, "annotations":[ ], "type":"AzureSqlTable", "typeProperties":{ "tableName":{ "value":"@dataset().SinkTableName", "type":"Expression" } } } }运行 Set-AzDataFactoryV2Dataset cmdlet 以创建数据集 SinkDataset。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "SinkDataset" -File ".\SinkDataset.json"下面是该 cmdlet 的示例输出:
DatasetName : SinkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
为水印创建数据集
在此步骤中,创建用于存储高水印值的数据集。
在同一文件夹中,创建包含以下内容的名为 WatermarkDataset.json 的 JSON 文件:
{ "name": " WatermarkDataset ", "properties": { "type": "AzureSqlTable", "typeProperties": { "tableName": "watermarktable" }, "linkedServiceName": { "referenceName": "AzureSQLDatabaseLinkedService", "type": "LinkedServiceReference" } } }运行 Set-AzDataFactoryV2Dataset cmdlet 以创建数据集 WatermarkDataset。
Set-AzDataFactoryV2Dataset -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "WatermarkDataset" -File ".\WatermarkDataset.json"下面是该 cmdlet 的示例输出:
DatasetName : WatermarkDataset ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Structure : Properties : Microsoft.Azure.Management.DataFactory.Models.AzureSqlTableDataset
创建管道
此管道使用表名列表作为参数。 ForEach 活动遍历表名的列表,并执行以下操作:
通过 Lookup 活动检索旧的水印值(初始值或上次迭代中使用的值)。
通过使用Lookup 操作,检索新的水印值(即源表中水印列的最大值)。
使用 Copy activity将这两个水印值之间的数据从源数据库复制到目标数据库。
通过 StoredProcedure 活动将旧水印值更新,以便在下一次迭代的第一步中使用该值。
创建管道
在同一文件夹中,创建包含以下内容的名为 IncrementalCopyPipeline.json 的 JSON 文件:
{ "name":"IncrementalCopyPipeline", "properties":{ "activities":[ { "name":"IterateSQLTables", "type":"ForEach", "dependsOn":[ ], "userProperties":[ ], "typeProperties":{ "items":{ "value":"@pipeline().parameters.tableList", "type":"Expression" }, "isSequential":false, "activities":[ { "name":"LookupOldWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"AzureSqlSource", "sqlReaderQuery":{ "value":"select * from watermarktable where TableName = '@{item().TABLE_NAME}'", "type":"Expression" } }, "dataset":{ "referenceName":"WatermarkDataset", "type":"DatasetReference" } } }, { "name":"LookupNewWaterMarkActivity", "type":"Lookup", "dependsOn":[ ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select MAX(@{item().WaterMark_Column}) as NewWatermarkvalue from @{item().TABLE_NAME}", "type":"Expression" } }, "dataset":{ "referenceName":"SourceDataset", "type":"DatasetReference" }, "firstRowOnly":true } }, { "name":"IncrementalCopyActivity", "type":"Copy", "dependsOn":[ { "activity":"LookupOldWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] }, { "activity":"LookupNewWaterMarkActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "source":{ "type":"SqlServerSource", "sqlReaderQuery":{ "value":"select * from @{item().TABLE_NAME} where @{item().WaterMark_Column} > '@{activity('LookupOldWaterMarkActivity').output.firstRow.WatermarkValue}' and @{item().WaterMark_Column} <= '@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}'", "type":"Expression" } }, "sink":{ "type":"AzureSqlSink", "sqlWriterStoredProcedureName":{ "value":"@{item().StoredProcedureNameForMergeOperation}", "type":"Expression" }, "sqlWriterTableType":{ "value":"@{item().TableType}", "type":"Expression" }, "storedProcedureTableTypeParameterName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" }, "disableMetricsCollection":false }, "enableStaging":false }, "inputs":[ { "referenceName":"SourceDataset", "type":"DatasetReference" } ], "outputs":[ { "referenceName":"SinkDataset", "type":"DatasetReference", "parameters":{ "SinkTableName":{ "value":"@{item().TABLE_NAME}", "type":"Expression" } } } ] }, { "name":"StoredProceduretoWriteWatermarkActivity", "type":"SqlServerStoredProcedure", "dependsOn":[ { "activity":"IncrementalCopyActivity", "dependencyConditions":[ "Succeeded" ] } ], "policy":{ "timeout":"7.00:00:00", "retry":0, "retryIntervalInSeconds":30, "secureOutput":false, "secureInput":false }, "userProperties":[ ], "typeProperties":{ "storedProcedureName":"[dbo].[usp_write_watermark]", "storedProcedureParameters":{ "LastModifiedtime":{ "value":{ "value":"@{activity('LookupNewWaterMarkActivity').output.firstRow.NewWatermarkvalue}", "type":"Expression" }, "type":"DateTime" }, "TableName":{ "value":{ "value":"@{activity('LookupOldWaterMarkActivity').output.firstRow.TableName}", "type":"Expression" }, "type":"String" } } }, "linkedServiceName":{ "referenceName":"AzureSQLDatabaseLinkedService", "type":"LinkedServiceReference" } } ] } } ], "parameters":{ "tableList":{ "type":"array" } }, "annotations":[ ] } }运行 Set-AzDataFactoryV2Pipeline cmdlet 以创建管道 IncrementalCopyPipeline。
Set-AzDataFactoryV2Pipeline -DataFactoryName $dataFactoryName -ResourceGroupName $resourceGroupName -Name "IncrementalCopyPipeline" -File ".\IncrementalCopyPipeline.json"下面是示例输出:
PipelineName : IncrementalCopyPipeline ResourceGroupName : <ResourceGroupName> DataFactoryName : <DataFactoryName> Activities : {IterateSQLTables} Parameters : {[tableList, Microsoft.Azure.Management.DataFactory.Models.ParameterSpecification]}
运行管道
在同一文件夹中创建包含以下内容的名为 Parameters.json 的参数文件:
{ "tableList": [ { "TABLE_NAME": "customer_table", "WaterMark_Column": "LastModifytime", "TableType": "DataTypeforCustomerTable", "StoredProcedureNameForMergeOperation": "usp_upsert_customer_table" }, { "TABLE_NAME": "project_table", "WaterMark_Column": "Creationtime", "TableType": "DataTypeforProjectTable", "StoredProcedureNameForMergeOperation": "usp_upsert_project_table" } ] }使用 Invoke-AzDataFactoryV2Pipeline cmdlet 运行 IncrementalCopyPipeline 管道。 将占位符替换为自己的资源组和数据工厂名称。
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupName -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"
监视管道
登录到 Azure 门户。
选择“所有服务”,使用关键字“数据工厂”进行搜索,然后选择“数据工厂”。
在数据工厂列表中搜索你的数据工厂,然后选择它来打开“数据工厂”页。
在 Data factory 页上,选择 Open Azure Data Factory Studio 磁贴上的 Open,以在单独的选项卡中启动Azure Data Factory。
在Azure Data Factory主页上,选择左侧的 Monitor。
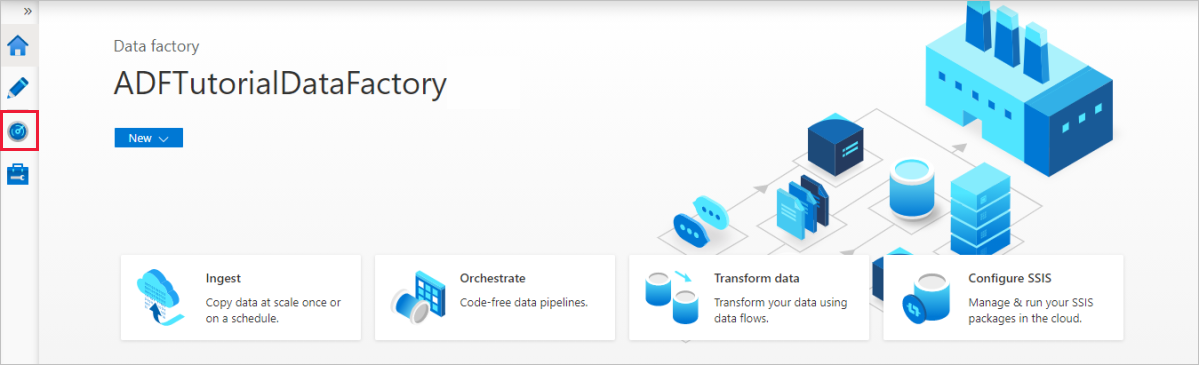
可以看到所有管道运行及其状态。 请注意,在以下示例中,管道运行的状态为“成功”。 选择“参数”列中的链接即可查看传递至管道的参数。 如果出现错误,请查看“错误”列中的链接。

在“操作”列中选择链接时,会看到管道的所有活动运行。
若要回到“管道运行”视图,请选择“所有管道运行”。
查看结果
在SQL Server Management Studio中,针对目标 SQL 数据库运行以下查询,以验证是否已将数据从源表复制到目标表:
查询
select * from customer_table
输出
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 Alice 2017-09-03 02:36:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
查询
select * from project_table
输出
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
查询
select * from watermarktable
输出
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-05 08:06:00.000
project_table 2017-03-04 05:16:00.000
请注意,已更新这两个表的水印值。
向源表中添加更多数据
针对源SQL Server数据库运行以下查询,以更新customer_table中的现有行。 将新行插入到 project_table 中。
UPDATE customer_table
SET [LastModifytime] = '2017-09-08T00:00:00Z', [name]='NewName' where [PersonID] = 3
INSERT INTO project_table
(Project, Creationtime)
VALUES
('NewProject','10/1/2017 0:00:00 AM');
重新运行管道
现在,通过执行以下 PowerShell 命令重新运行管道:
$RunId = Invoke-AzDataFactoryV2Pipeline -PipelineName "IncrementalCopyPipeline" -ResourceGroup $resourceGroupname -dataFactoryName $dataFactoryName -ParameterFile ".\Parameters.json"按照监视管道部分的说明监视管道运行。 当管道状态为“正在进行”时,可以在“操作”下看到另一操作链接,用于取消管道运行。
请选择刷新以刷新列表,直至管道运行成功。
也可选择“操作”下的“查看活动运行”链接,查看与此管道运行相关联的所有活动运行。
查看最终结果
在SQL Server Management Studio中,针对目标数据库运行以下查询,以验证是否已将更新/新数据从源表复制到目标表。
查询
select * from customer_table
输出
===========================================
PersonID Name LastModifytime
===========================================
1 John 2017-09-01 00:56:00.000
2 Mike 2017-09-02 05:23:00.000
3 NewName 2017-09-08 00:00:00.000
4 Andy 2017-09-04 03:21:00.000
5 Anny 2017-09-05 08:06:00.000
请注意 PersonID 为 3 时对应的 Name 和 LastModifytime 的新值。
查询
select * from project_table
输出
===================================
Project Creationtime
===================================
project1 2015-01-01 00:00:00.000
project2 2016-02-02 01:23:00.000
project3 2017-03-04 05:16:00.000
NewProject 2017-10-01 00:00:00.000
请注意,已将 NewProject 条目添加到 project_table。
查询
select * from watermarktable
输出
======================================
TableName WatermarkValue
======================================
customer_table 2017-09-08 00:00:00.000
project_table 2017-10-01 00:00:00.000
请注意,已更新这两个表的水印值。
相关内容
已在本教程中执行了以下步骤:
- 准备源和目标数据存储。
- 创建数据工厂。
- 创建自承载集成运行时 (IR)。
- 安装 Integration Runtime。
- 创建链接服务。
- 创建源、接收器和水印数据集。
- 创建、运行和监视管道。
- 查看结果。
- 在源表中添加或更新数据。
- 重新运行和监视管道。
- 查看最终结果。
转到以下教程,了解如何在 Azure 上使用 Spark 群集转换数据: