堆转储包含应用程序的内存快照,包括创建转储时变量的值。 因此,它们可用于诊断运行时发生的问题。
Services
可以为以下服务启用堆转储:
- Apache hcatalog - tempelton
- Apache hive - hiveserver2、元数据存储、Derbyserver
- mapreduce - jobhistoryserver
- Apache yarn - resourcemanager、nodemanager、timelineserver
- Apache hdfs - datanode、secondarynamenode、namenode
还可以为 HDInsight 运行的映射和化简进程启用堆转储。
了解堆转储配置
启动服务时,通过将选项(有时称为“选择”或“参数”)传递给 JVM 来启用堆转储。 对于大多数 Apache Hadoop 服务,可以修改用于启动服务的 shell 脚本来传递这些选项。
在每个脚本中, 都有导出 *_OPTS,其中包含传递给 JVM 的选项。 例如,在 hadoop-env.sh 脚本中,以 export HADOOP_NAMENODE_OPTS= NameNode 服务开头的行包含选项。
映射和化简过程略有不同,因为这些作是 MapReduce 服务的子进程。 每个映射或化简进程在子容器中运行,并且有两个条目包含 JVM 选项。 两者都包含在 mapred-site.xml中:
- mapreduce.admin.map.child.java.opts
- mapreduce.admin.reduce.child.java.opts
注释
建议使用 Apache Ambari 修改脚本和 mapred-site.xml 设置,因为 Ambari 处理跨群集中的节点复制更改。 有关特定步骤,请参阅 “使用 Apache Ambari ”部分。
启用堆转储
在发生 OutOfMemoryError 时,以下选项将启用堆内存转储:
-XX:+HeapDumpOnOutOfMemoryError
+ 表示此选项已启用。 默认值处于禁用状态。
警告
默认情况下,HDInsight 上的 Hadoop 服务未启用堆转储,因为转储文件可能很大。 如果您启用这些选项进行故障排除,请记住在复现问题并收集转储文件后禁用它们。
转储位置
转储文件的默认位置是当前工作目录。 可以使用以下选项控制文件存储位置:
-XX:HeapDumpPath=/path
例如,使用 -XX:HeapDumpPath=/tmp 会使得转储存储在 /tmp 目录中。
脚本
还可以在 OutOfMemoryError 发生时触发脚本。 例如,触发通知,以便知道错误已发生。 使用以下选项在 OutOfMemoryError 上触发脚本:
-XX:OnOutOfMemoryError=/path/to/script
注释
由于 Apache Hadoop 是分布式系统,因此使用的任何脚本都必须放置在服务运行所在的群集中的所有节点上。
该脚本还必须位于服务运行方式的帐户可访问的位置,并且必须提供执行权限。 例如,你可能希望将脚本存储在 /usr/local/bin 中,并使用 chmod go+rx /usr/local/bin/filename.sh 来授予读取和执行权限。
使用 Apache Ambari
若要修改服务的配置,请使用以下步骤:
在网络浏览器中,转到
https://CLUSTERNAME.azurehdinsight.cn,其中CLUSTERNAME是您群集的名称。使用左侧的列表,选择要修改的服务区域。 例如 ,HDFS。 在中心区域中,选择“ 配置 ”选项卡。

使用 筛选器... 条目,输入 选择。 仅显示包含此文本的项目。
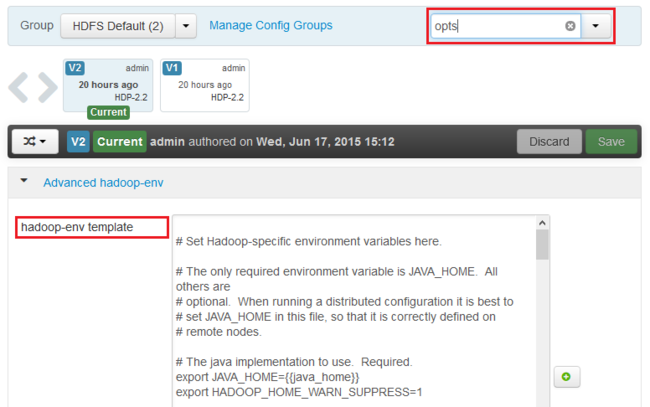
找到您要为其启用堆转储的服务的*_OPTS条目,然后添加您希望启用的选项。 在下图中,我已添加到
-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/HADOOP_NAMENODE_OPTS条目: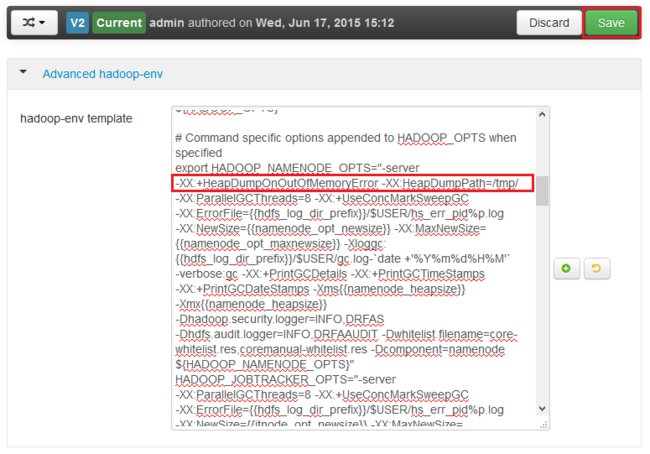
注释
为映射或化简子进程启用堆转储时,查找名为 mapreduce.admin.map.child.java.opts 和 mapreduce.admin.reduce.child.java.opts 的字段。
使用 “保存 ”按钮保存更改。 可以输入描述更改的简短说明。
应用更改后,需要重新启动 图标会出现在一个或多个服务旁边。
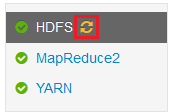
选择需要重启的每个服务,并使用 “服务作 ”按钮 打开维护模式。 维护模式可防止重启服务时从服务生成警报。
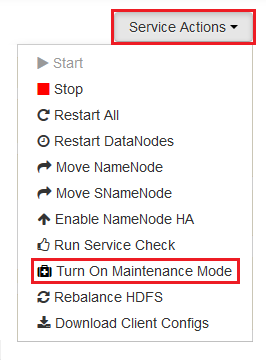
启用维护模式后,使用服务的 “重启” 按钮 重启所有受影响的项目
注释
对于其他服务, “重启 ”按钮的条目可能有所不同。
重新启动服务后,使用“服务操作”按钮“关闭维护模式”。 此 Ambari 将恢复对服务的警报监控。