了解如何访问 Azure HDInsight 中 Apache Hadoop 群集上的 Apache Hadoop YARN (又一个资源协商程序)应用程序的日志。
什么是 Apache YARN?
YARN 通过将资源管理与应用程序计划/监视分离,支持多个编程模型(Apache Hadoop MapReduce 是其中一个)。 YARN 使用全局 ResourceManager (RM)、每个工作器节点 NodeManagers (NM)和每个应用程序 ApplicationMasters (AM)。 每个应用程序的应用程序管理器 (AM) 协商资源(CPU、内存、磁盘、网络),以便与 RM 一起运行您的应用程序。 RM 与 NM 合作,以授予这些资源,这些资源将作为 容器授予。 AM 负责跟踪 RM 分配给它的容器的进度。 应用程序可能需要许多容器,具体取决于应用程序的性质。
每个应用程序可能包含多个 应用程序尝试。 如果应用程序失败,可能会以新尝试的形式重试它。 每次尝试都在容器中运行。 从某种意义上说,容器为 YARN 应用程序完成的基本工作单元提供上下文。 在容器上下文中完成的所有工作都在给定容器的单个工作器节点上完成。 请参阅 Hadoop:编写 YARN 应用程序或 Apache Hadoop YARN以获取进一步参考。
若要缩放群集以支持更大的处理吞吐量,可以使用自动缩放或使用几种不同的语言手动缩放群集。
YARN Timeline Server (YARN 时间线服务器)
Apache Hadoop YARN Timeline Server 提供有关已完成应用程序的通用信息
YARN Timeline Server 包括以下类型的数据:
- 应用程序 ID,应用程序的唯一标识符
- 启动应用程序的用户
- 有关尝试完成应用程序的信息
- 任何给定应用程序尝试使用的容器
YARN 应用程序和日志
在调试有问题的 Hadoop 应用程序时,应用程序日志(和相关容器日志)至关重要。 YARN 提供了一个很好的框架,用于使用日志聚合收集、聚合和存储应用程序日志。
日志聚合功能使访问应用程序日志更具确定性。 它跨工作器节点上的所有容器聚合日志,并将它们存储为每个工作器节点的一个聚合日志文件。 应用程序完成后,日志存储在默认文件系统上。 应用程序可以使用数百或数千个容器,但单个工作器节点上运行的所有容器的日志始终聚合到单个文件。 因此,应用程序只使用每个工作器节点一个日志。 默认情况下,日志聚合在 HDInsight 群集 3.0 及更高版本上启用。 聚合日志位于群集的默认存储中。 以下路径是日志的 HDFS 路径:
/app-logs/<user>/logs/<applicationId>
在路径中, user 是启动应用程序的用户的名称。
applicationId这是 YARN RM 分配给应用程序的唯一标识符。
聚合日志不可直接读取,因为它们以 TFile容器索引的二进制格式写入。 使用 YARN ResourceManager 日志或 CLI 工具将这些日志视为感兴趣的应用程序或容器的纯文本。
ESP 群集中的 Yarn 日志
必须将两个配置添加到 Ambari 中的自定义 mapred-site 配置。
在网络浏览器中,转到
https://CLUSTERNAME.azurehdinsight.cn,其中CLUSTERNAME是您群集的名称。从 Ambari UI 导航到 MapReduce2>配置>高级>自定义 mapred-site。
添加以下 属性集之一 :
设置 1
mapred.acls.enabled=true mapreduce.job.acl-view-job=*设置 2
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>保存更改并重启所有受影响的服务。
YARN CLI 工具
使用 ssh 命令连接到群集。 请编辑以下命令,将 CLUSTERNAME 替换为群集名称,然后输入该命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.cn使用以下命令列出当前正在运行的 Yarn 应用程序的所有应用程序 ID:
yarn top请注意位于
APPLICATIONID列中的应用程序ID,以下载其日志。YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC Server可以通过运行以下命令之一,以纯文本形式查看这些日志:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>运行这些命令时,请指定 <applicationId>、<user-who-started-the-application>、<containerId> 和 <worker-node-address> 信息。
其他示例命令
使用以下命令下载所有应用程序主机的 Yarn 容器日志。 此步骤创建以文本格式命名
amlogs.txt的日志文件。yarn logs -applicationId <application_id> -am ALL > amlogs.txt使用以下命令仅下载最新应用程序主服务器的 Yarn 容器日志:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txt使用以下命令下载前两个应用程序主机的 YARN 容器日志:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txt使用以下命令下载所有 Yarn 容器日志:
yarn logs -applicationId <application_id> > logs.txt要下载特定容器的 yarn 日志,请使用以下命令:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN ResourceManager 用户界面 (UI)
YARN ResourceManager UI 在群集头节点上运行。 它通过 Ambari Web UI 进行访问。 使用以下步骤查看 YARN 日志:
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn。 将 CLUSTERNAME 替换为 HDInsight 群集的名称。从左侧的服务列表中,选择 YARN。
从“ 快速链接” 下拉列表中,选择其中一个群集头节点,然后选择
ResourceManager Log。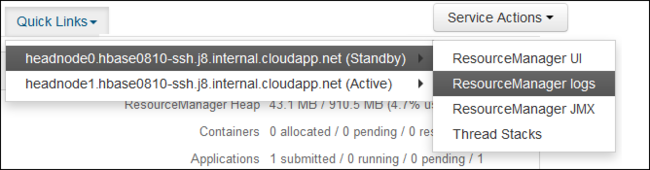
你会看到一系列指向 YARN 日志的链接。