通过了解 blob 和容器在生产环境中的存储、组织和使用方式,可以更好地优化成本和性能之间的权衡。
本教程介绍如何生成和直观呈现统计信息,例如一段时间内的数据增长、一段时间内添加的数据、修改的文件数、blob 快照大小、每一层中的访问模式,以及当前和一段时间内数据的分布方式(例如:跨层数据、文件类型、容器中和 blob 类型)。
在本教程中,你将了解如何执行以下操作:
- 生成 Blob 清单报告
- 设置 Synapse 工作区
- 设置 Synapse Studio
- 在 Synapse Studio 中生成分析数据
- 在 Power BI 中可视化结果
先决条件
Azure 订阅 - 创建试用帐户
Azure 存储帐户 - 创建存储帐户
请确保你的用户身份已被分配存储 Blob 数据参与者角色。
生成清单报表
为存储帐户启用 Blob 清单报告。 请参阅启用 Azure 存储 Blob 清单报告。
启用库存报告后,系统可能需要长达 24 小时才会生成第一份报告。
设置 Synapse 工作区
创建 Azure Synapse 工作区。 请参阅创建 Azure Synapse 工作区。
注意
在创建工作区的过程中,将创建具有分层命名空间的存储帐户。 Azure Synapse 将 Spark 表和应用程序日志存储到此帐户。 Azure Synapse 将此帐户称为主存储帐户。 为避免混淆,本文使用“清单报表帐户”一词指代包含清单报表的帐户。
在 Synapse 工作区中,将 Contributor 角色分配给你的用户身份。 请参阅 Azure RBAC:工作区的“所有者”角色。
导航到清单报表帐户,然后将“存储 Blob 数据参与者”角色分配给工作区的系统托管标识,从而向 Synapse 工作区授予存储帐户中清单报表的访问权限。 请参阅使用 Azure 门户分配 Azure 角色。
转到主存储账户,并将 Blob 存储贡献者 角色分配给你的用户标识。
设置 Synapse Studio
在 Synapse Studio 中打开 Synapse 工作区。 请参阅打开 Synapse Studio。
在 Synapse Studio 中,请确保已为你的身份分配 Synapse Administrator 角色。 请参阅 Synapse RBAC: 工作区的 Synapse 管理员角色。
创建 Apache Spark 池。 请参阅创建无服务器 Apache Spark 池。
设置和运行示例笔记本
在本部分中,你将生成将在报表中直观呈现的统计数据。 为了简化本教程,本部分使用示例配置文件和示例 PySpark 笔记本。 笔记本包含在 Azure Synapse Studio 中执行的查询集合。
修改并上传示例配置文件
更新该文件的以下占位符:
将
storageAccountName设置为清单报表帐户的名称。将
destinationContainer设置为保存清单报表的容器的名称。将
blobInventoryRuleName设置为已生成要分析的结果的清单报表规则名称。将
accessKey设置为清单报表帐户的帐户密钥。
将此文件上传到创建 Synapse 工作区时指定的主存储帐户中的容器。
导入 PySpark 示例笔记本
下载 ReportAnalysis.ipynb 示例笔记本。
注意
请确保使用
.ipynb扩展名保存此文件。在 Synapse Studio 中打开 Synapse 工作区。 请参阅打开 Synapse Studio。
在 Synapse Studio 中,选择“开发”选项卡。
选择加号 (+) 以添加一项。
选择“导入”,浏览到下载的示例文件,选择该文件,然后选择“打开”。
此时将显示“属性”对话框。
在“属性”对话框中,选择“配置会话”链接。
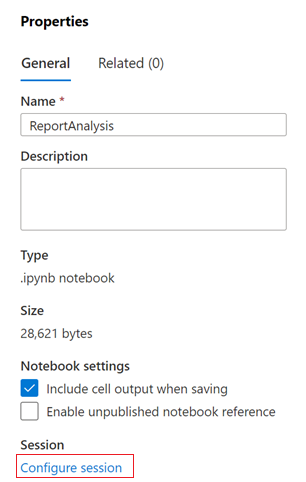
配置会话对话框将打开。
在“配置会话”对话框的“附加到”下拉列表中,选择本文前面创建的 Spark 池。 然后选择“应用”按钮。
修改 Python 笔记本
在 Python 笔记本的第一个单元格中,将
storage_account变量的值设置为主存储帐户的名称。将
container_name变量的值更新为创建 Synapse 工作区时指定的帐户中的容器名称。选择“发布”按钮。
运行 PySpark 笔记本
在 PySpark 笔记本中,选择 全部运行。
启动 Spark 会话需要几分钟时间,处理清单报表也需要几分钟时间。 如果要处理大量清单报表,则第一次运行可能需要一段时间。 后续运行将仅处理自上次运行以来创建的新清单报表。
注意
如果在笔记本运行时对其进行任何更改,请确保使用“发布”按钮发布这些更改。
通过选择“数据”选项卡验证笔记本是否成功运行。
名为 reportdata 的数据库应显示在“数据”窗格的“工作区”选项卡中。 如果未显示此数据库,则可能需要刷新网页。
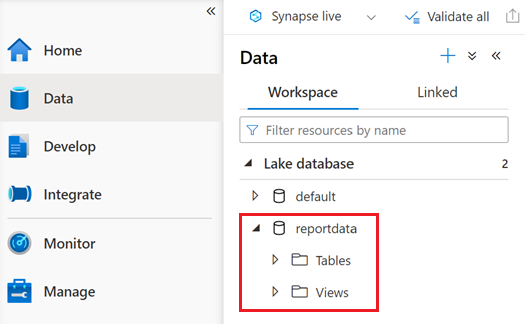
数据库包含一组表。 每个表都包含通过从 PySpark 笔记本运行查询而获得的信息。
若要检查表的内容,请展开 reportdata 数据库的 Tables 文件夹。 然后,右键单击表,依次选择“选择 SQL 脚本”、“选择前 100 行”。
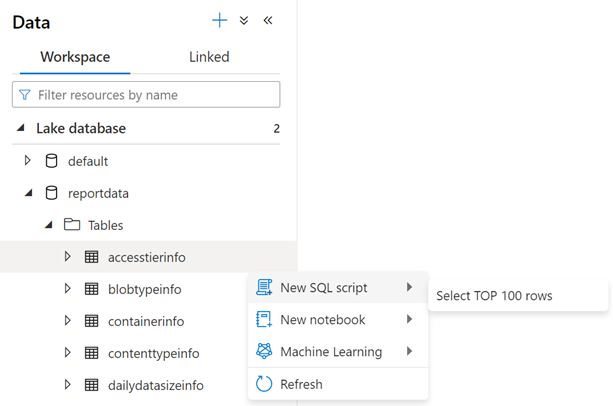
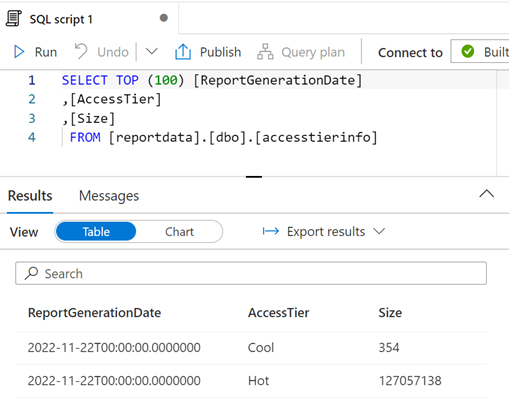
可以根据需要修改查询,然后选择“运行”以查看结果。
可视化数据
下载 ReportAnalysis.pbit 示例报告文件。
打开 Power BI Desktop。 关于安装指南,请参阅获取 Power BI Desktop。
在 Power BI 中,依次选择“文件”、“打开报表”和“浏览报表”。
在“打开”对话框中,将文件类型更改为“Power BI 模板文件(*.pbit)”。

浏览到下载的 ReportAnalysis.pbit 文件的位置,然后选择“打开”。
此时会显示一个对话框,要求你提供 Synapse 工作区名称和数据库名称。
在对话框中,将“synapse_workspace_name”字段设置为工作区名称,并将“database_name”字段设置为 。 然后,选择“加载”按钮。
此时会显示一个报表,该报表提供笔记本检索到的数据的可视化效果。 下图显示了此报表中显示的图表和图形的类型。
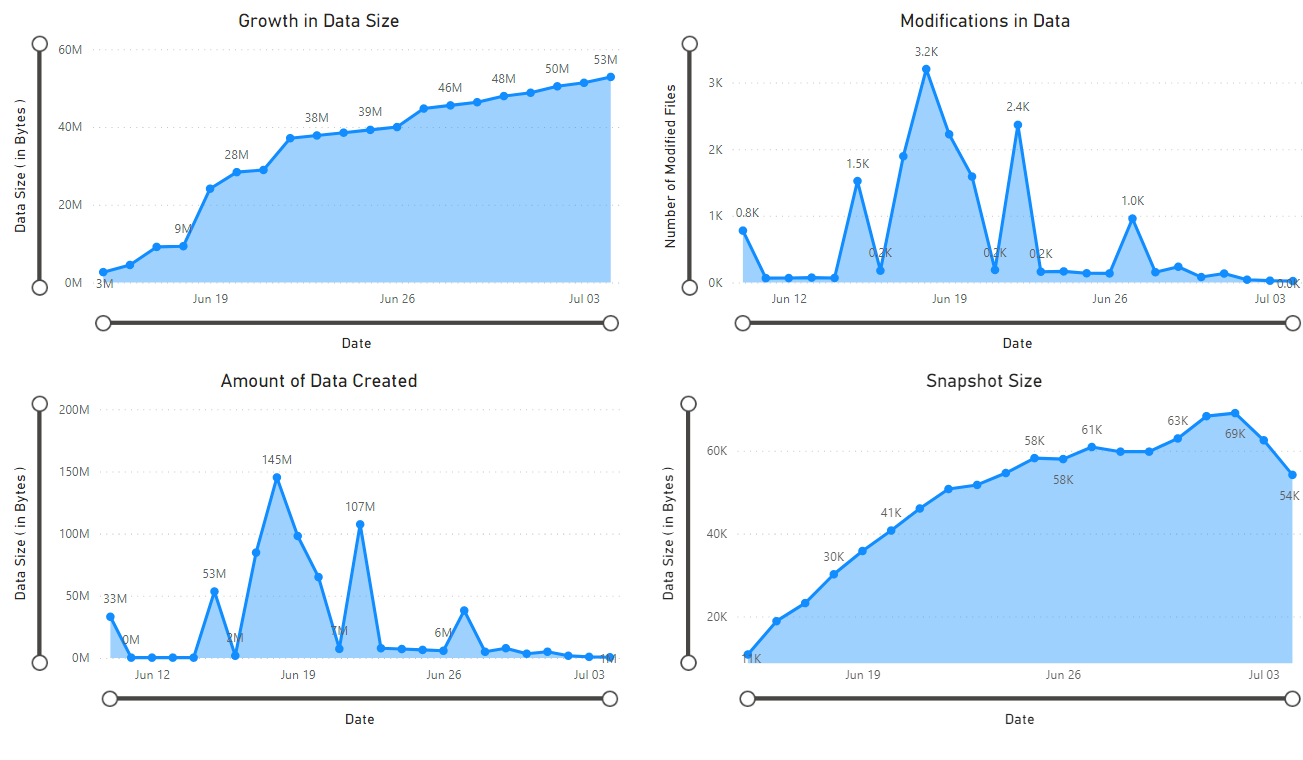
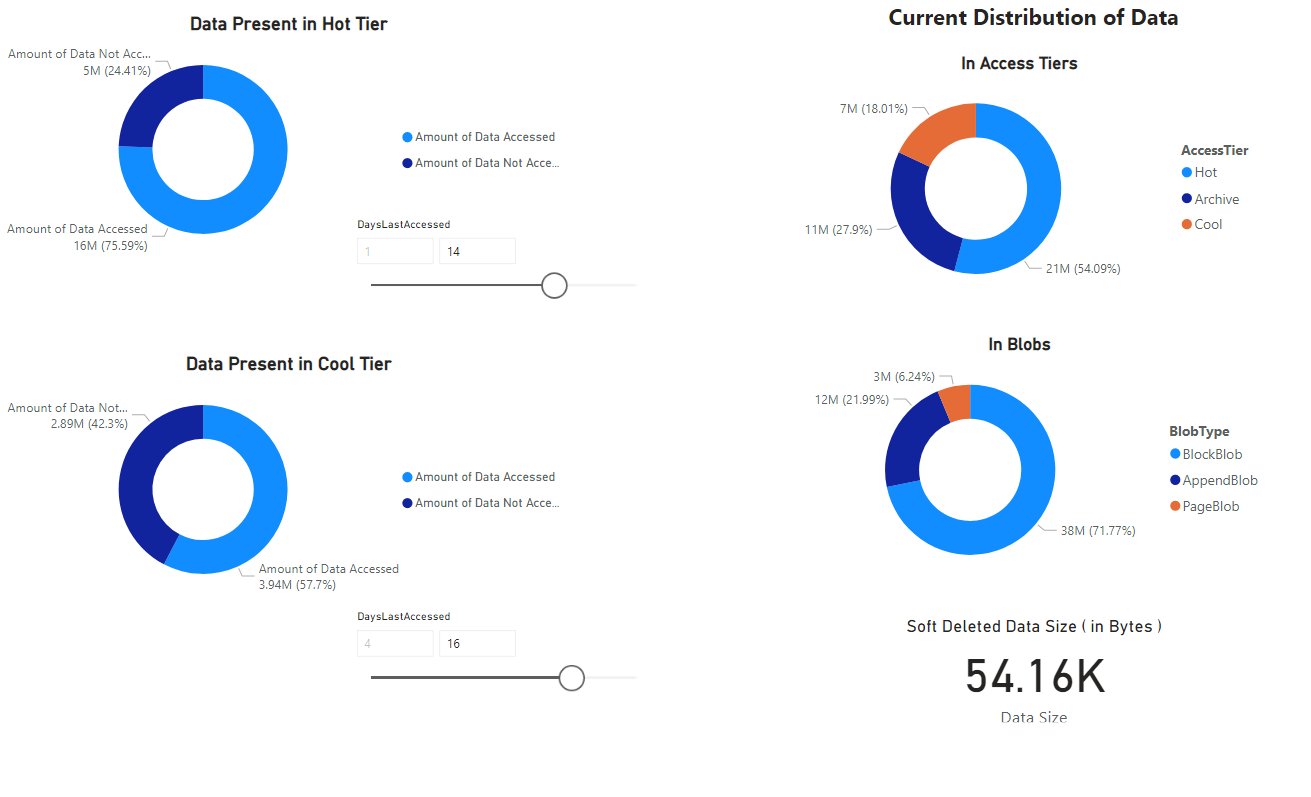
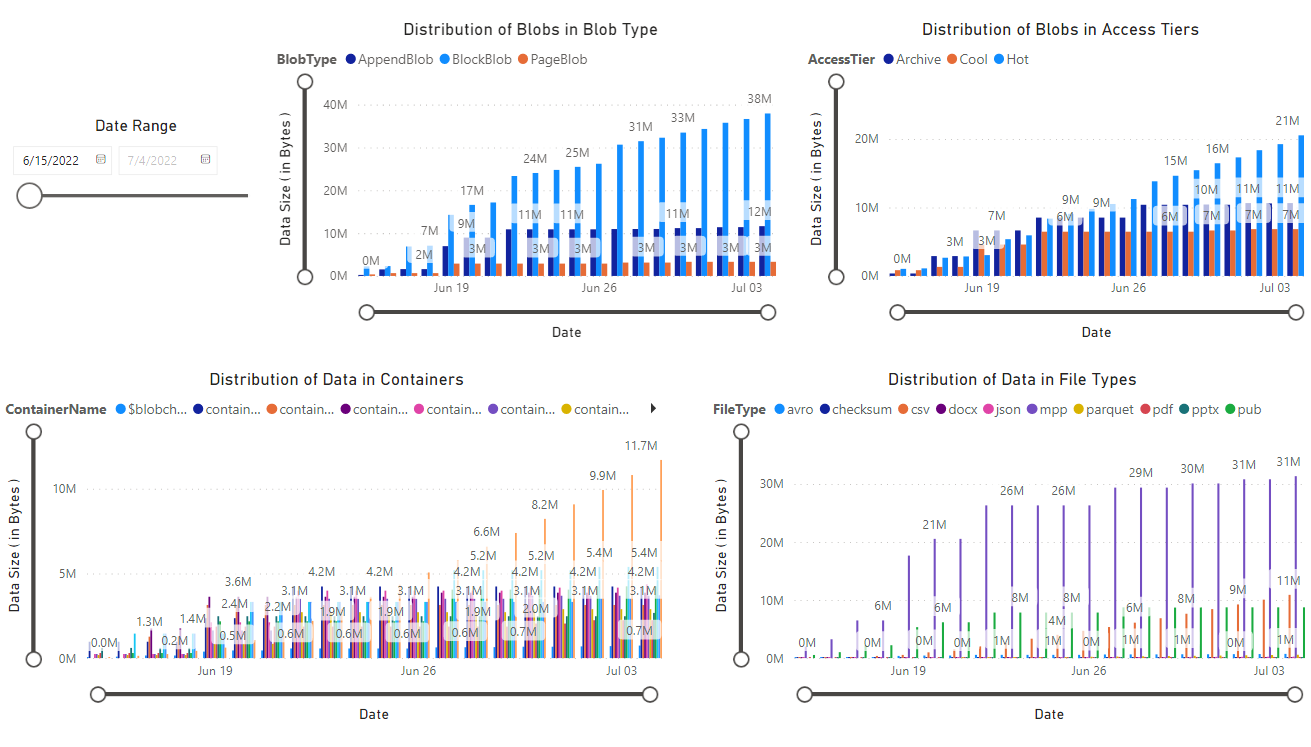
后续步骤
设置 Azure Synapse 管道,使其按固定时间间隔持续运行您的笔记本。 这样,就可以在创建新清单报表时处理它们。 初始运行后,后续的每次运行都将分析增量数据,然后使用该分析的结果更新表。 如需了解指南,请参阅与管道集成。
了解在存储帐户中分析单个容器的方法。 请参阅以下文章:
了解基于 Blob 和容器的分析来优化成本的方法。 请参阅以下文章: