本教程介绍了如何使用 Azure Blob 存储清单和 Azure Databricks 收集有关容器的统计信息。
本教程中,您将学习如何:
- 生成清单报表
- 创建 Azure Databricks 工作区和笔记本
- 读取 blob 清单文件
- 获取 Blob、快照和版本的数量和总大小
- 按 Blob 类型和内容类型获取 Blob 数目
先决条件
Azure 订阅 - 创建试用帐户
Azure 存储帐户 - 创建存储帐户
请确保你的用户标识分配有存储 Blob 数据参与者角色。
生成清单报表
为存储帐户启用 blob 清单报表。 请参阅启用 Azure 存储 blob 清单报表。
请使用以下配置设置:
| 设置 | 价值 |
|---|---|
| 规则名称 | blobinventory |
| 集装箱 | <你的容器名称> |
| 清单的对象类型 | Blob |
| Blob 类型 | 块 blob、页 blob 和追加 blob |
| 子类型 | 包括 blob 版本,包括快照,包括已删除的 blob |
| Blob 清单字段 | 全部 |
| 清单频率 | Daily |
| 导出格式 | CSV |
为生成的第一个报表启用库存报表后,可能需要等待 24 个小时。
配置 Azure Databricks
在本部分中,你将创建 Azure Databricks 工作区和笔记本。 在本教程中,稍后你需要将代码段粘贴到笔记本单元格中,然后运行它们来收集容器统计信息。
创建 Azure Databricks 工作区。 请参阅创建 Azure Databricks 工作区。
创建新的笔记本。 请参阅创建笔记本。
选择 Python 作为笔记本的默认语言。
读取 blob 清单文件
将以下代码块复制并粘贴到第一个单元格中,但目前请勿运行此代码。
from pyspark.sql.types import StructType, StructField, IntegerType, StringType import pyspark.sql.functions as F storage_account_name = "<storage-account-name>" storage_account_key = "<storage-account-key>" container = "<container-name>" blob_inventory_file = "<blob-inventory-file-name>" hierarchial_namespace_enabled = False if hierarchial_namespace_enabled == False: spark.conf.set("fs.azure.account.key.{0}.blob.core.chinacloudapi.cn".format(storage_account_name), storage_account_key) df = spark.read.csv("wasbs://{0}@{1}.blob.core.chinacloudapi.cn/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true') else: spark.conf.set("fs.azure.account.key.{0}.dfs.core.chinacloudapi.cn".format(storage_account_name), storage_account_key) df = spark.read.csv("abfss://{0}@{1}.dfs.core.chinacloudapi.cn/{2}".format(container, storage_account_name, blob_inventory_file), header='true', inferSchema='true')在此代码块中,替换以下值:
将
<storage-account-name>占位符值替换为存储帐户的名称。将
<storage-account-key>占位符值替换为你的存储帐户的帐户密钥。将
<container-name>占位符值替换为存放着清单报表的容器。将
<blob-inventory-file-name>占位符替换为清单文件的完全限定名称(例如:2023/02/02/02-16-17/blobinventory/blobinventory_1000000_0.csv)。如果你的帐户具有分层命名空间,请将
hierarchical_namespace_enabled变量设置为True。
单击“运行”按钮以运行此单元格中的代码。
获取 blob 计数和大小
在一个新单元格中粘贴以下代码:
print("Number of blobs in the container:", df.count()) print("Number of bytes occupied by blobs in the container:", df.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])单击运行按钮以运行该单元格。
笔记本将显示容器中 blob 的数目以及容器中 blob 占用的字节数。

获取快照计数和大小
在一个新单元格中粘贴以下代码:
from pyspark.sql.functions import * print("Number of snapshots in the container:", df.where(~(col("Snapshot")).like("Null")).count()) dfT = df.where(~(col("Snapshot")).like("Null")) print("Number of bytes occupied by snapshots in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])单击运行按钮以运行该单元格。
笔记本将显示快照的数目以及 blob 快照占用的总字节数。

获取版本计数和大小
在一个新单元格中粘贴以下代码:
from pyspark.sql.functions import * print("Number of versions in the container:", df.where(~(col("VersionId")).like("Null")).count()) dfT = df.where(~(col("VersionId")).like("Null")) print("Number of bytes occupied by versions in the container:", dfT.agg({'Content-Length': 'sum'}).first()['sum(Content-Length)'])按 Shift + Enter 来运行该单元格。
笔记本将显示 blob 版本数和 blob 版本占用的总字节数。

按 blob 类型获取 blob 计数
在一个新单元格中粘贴以下代码:
display(df.groupBy('BlobType').count().withColumnRenamed("count", "Total number of blobs in the container by BlobType"))按 Shift + Enter 来运行该单元格。
笔记本将按类型显示 blob 类型的数目。

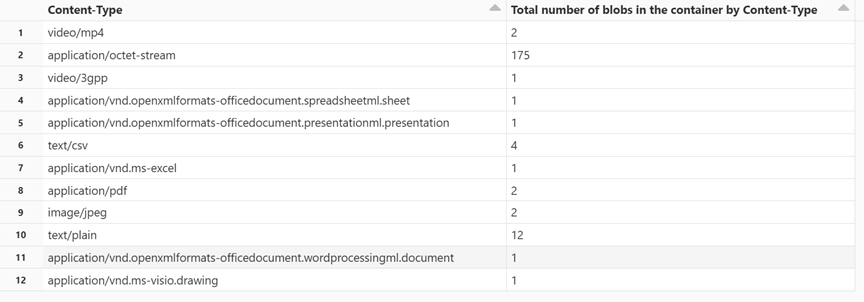
按内容类型获取 blob 计数
在一个新单元格中粘贴以下代码:
display(df.groupBy('Content-Type').count().withColumnRenamed("count", "Total number of blobs in the container by Content-Type"))按 Shift + Enter 来运行该单元格。
笔记本将显示与每种内容类型关联的 blob 的数目。
终止群集
为避免不必要的计费,请终止计算资源。 请参阅终止计算资源。
后续步骤
了解如何使用 Azure Synapse 计算每个容器的 blob 计数和 blob 总大小。 请参阅使用 Azure 存储清单计算每个容器的 blob 计数和总大小
了解如何生成描述容器和 Blob 的统计信息并将其可视化。 请参阅教程:分析 blob 清单报表
了解基于 Blob 和容器的分析来优化成本的方法。 请参阅以下文章: