本文介绍Azure 流分析输入连接的常见问题、如何排查这些问题以及如何更正这些问题。 涉及的问题包括:由格式错误的事件导致的反序列化错误、事件中心接收器限制、分区数量变更以及 IoT 中心 读取器限制。
许多故障排除步骤要求为流分析作业启用资源日志。 如果没有启用资源日志,请参阅使用资源日志对 Azure 流分析进行故障排除。
任务未接收输入事件
检查输入端和输出端的连接情况。 对每个输入和输出使用 “测试连接 ”按钮。
检查输入数据:
确保在输入预览中选择时间范围。 选择 “选择时间范围”,然后在测试查询之前输入示例持续时间。
格式不正确的输入事件会导致反序列化错误
当流分析作业的输入流包含格式不正确的消息时,会发生反序列化问题。 例如,JSON 对象中缺少括号或大括号或时间字段中的时间戳格式不正确可能会导致格式不正确的消息。
当流分析作业从输入收到格式不正确的消息时,它会删除该消息,并发出警告通知。 你的 Stream Analytics 作业的 输入 磁贴上会出现警告符号。 只要作业处于运行状态,警告符号就存在。
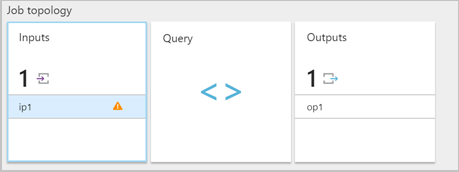
启用资源日志以查看导致错误的错误和消息(有效负载)的详细信息。 反序列化错误可能由多种原因导致。 有关特定反序列化错误的详细信息,请参阅 输入数据错误。 如果未启用资源日志,Azure门户中会显示一条简短通知。
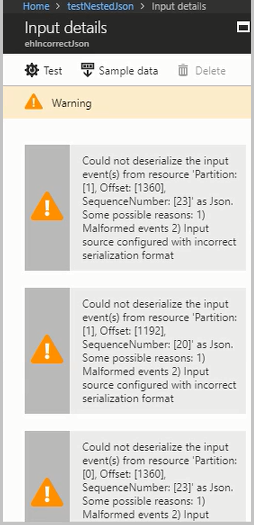
如果消息有效负载大于 32 KB 或采用二进制格式,请运行GitHub示例存储库中可用的CheckMalformedEvents.cs代码。 此代码读取分区 ID 偏移量并打印位于该偏移量中的数据。
输入反序列化错误的其他常见原因包括:
- 一个值大于
9223372036854775807的整数列。 - 字符串而不是对象数组或行分隔对象。 有效示例:
[{'a':1}]. 无效示例:"'a' :1". - 事件中心以 Avro 格式捕获 Blob,用作作业中的输入。
- 单个输入事件中的两个仅大小写不同的列,例如
column1和COLUMN1。
事件中心分区数更改
当事件中心的分区计数在流分析作业运行时发生更改时,作业失败并出现以下错误:
Microsoft.Streaming.Diagnostics.Exceptions.InputPartitioningChangedException
若要解决此问题,请停止并重启流分析作业,以便它可以检测新的分区计数。
作业超过 Event Hubs 接收器的最大数量限制
使用事件中心的最佳做法是使用多个使用者组实现作业可伸缩性。 特定输入的流分析作业中的读取器数会影响单个使用者组中的读取器数。
接收器的精确数量基于横向扩展拓扑逻辑的内部实现详细信息。 该数字不会在外部公开。 作业启动或升级时,读取器数量可能会发生变化。
当接收方数超过最大值时,将显示以下错误消息。 该消息包含使用者组下与事件中心的现有连接列表。 该标记AzureStreamAnalytics指示连接来自Azure流式处理服务。
The streaming job failed: Stream Analytics job has validation errors: Job will exceed the maximum amount of Event Hubs Receivers.
The following information may be helpful in identifying the connected receivers: Exceeded the maximum number of allowed receivers per partition in a consumer group which is 5. List of connected receivers –
AzureStreamAnalytics_a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1_1,
AzureStreamAnalytics_a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1_1,
AzureStreamAnalytics_a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1_1,
AzureStreamAnalytics_a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1_1,
AzureStreamAnalytics_a0a0a0a0-bbbb-cccc-dddd-e1e1e1e1e1e1_1.
注释
在作业升级期间读取器数发生更改时,将暂时性警告写入审核日志。 流分析作业会自动从这些暂时性问题中恢复。
若要在事件中心实例中添加新的使用者组,请执行以下步骤:
登录到 Azure 门户。
找到事件中心。
在 “实体 ”标题下,选择 “事件中心”。
按名称选择事件中心。
在 “事件中心实例 ”页上的 “实体 ”标题下,选择 “使用者组”。 已列出一个名为 $Default 的使用者群组。
选择 “+ 使用者”组 以添加新的使用者组。
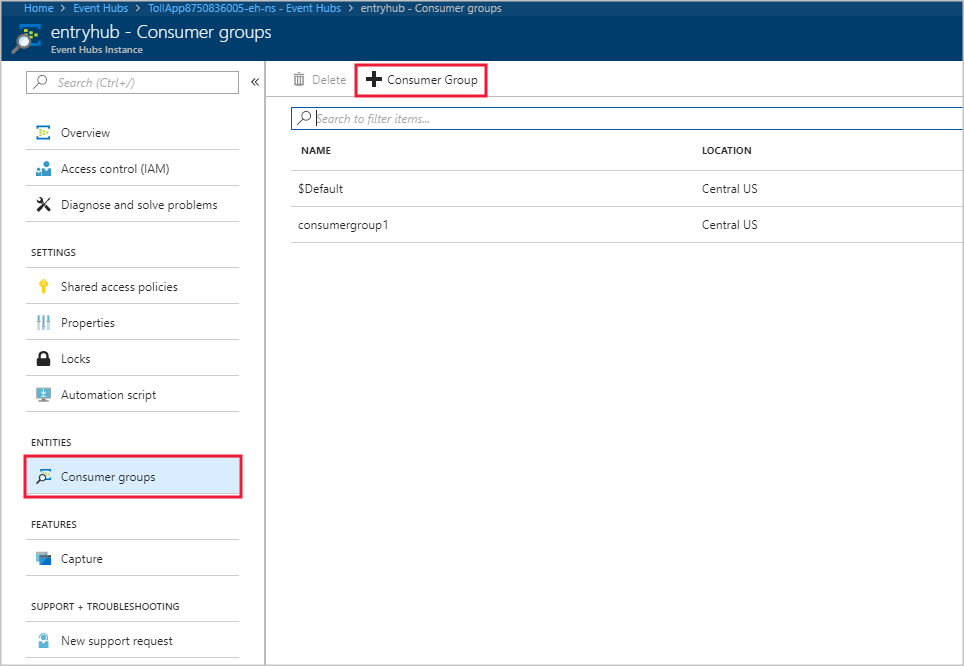
在流分析作业中创建输入以指向事件中心时,你在其中指定了使用者组。 如果未指定使用者组,事件中心将使用 $Default 。 创建使用者组后,在流分析作业中编辑事件中心输入并指定新使用者组的名称。
每个分区的读取器数超过事件中心限制
如果流式处理查询语法多次引用事件中心输入的相同资源,则作业引擎可以为每个来自同一使用者组的查询使用多个读取器。 如果对同一使用者组的引用过多,则作业可能会超过 5 个限制并引发错误。 在这些情况下,你可以通过在多个消费者组中使用多个输入来进一步细分。
每个分区的读取器数量超过 Event Hubs 五个读取器限制的场景包括:
多个
SELECT语句:如果使用SELECT多个引用 同一 事件中心输入的语句,则每个SELECT语句都会导致创建新的接收方。UNION:使用UNION时,可能会有多个输入指向同一事件中心和使用者组。SELF JOIN:使用SELF JOIN操作时,可以多次引用 同一 事件中心。
以下最佳做法可帮助缓解每个分区的读取器数超过事件中心限制为 5 的情况。
使用 WITH 子句将查询拆分为多个步骤
该 WITH 子句指定一个临时命名结果集,查询中的 FROM 子句可以引用该结果集。 在单个WITH语句的执行作用域中定义SELECT子句。
例如,不要使用此查询:
SELECT foo
INTO output1
FROM inputEventHub
SELECT bar
INTO output2
FROM inputEventHub
…
使用此查询:
WITH data AS (
SELECT * FROM inputEventHub
)
SELECT foo
INTO output1
FROM data
SELECT bar
INTO output2
FROM data
…
确保输入绑定到不同的使用者组
对于三个或多个输入连接到同一事件中心使用者组的查询,请创建单独的使用者组。 此任务需要创建其他流分析输入。
为不同的消费者组创建单独的输入
可以为同一事件中心创建具有不同使用者组的单独输入。 在下面的 UNION 查询示例中,InputOne 和 InputTwo 指向同一个 Event Hubs 源。 任何查询都可以具有具有不同使用者组的单独输入。 查询 UNION 只是一个示例。
WITH
DataOne AS
(
SELECT * FROM InputOne
),
DataTwo AS
(
SELECT * FROM InputTwo
),
SELECT foo FROM DataOne
UNION
SELECT foo FROM DataTwo
每个分区的读取器数超过IoT 中心限制
流分析作业使用与Azure IoT 中心中内置的事件中心兼容的终结点来连接和读取IoT 中心中的事件。 如果每个分区的读取器超出IoT 中心的限制,则可以使用事件中心的解决方案来解决此问题。 可以通过IoT 中心门户终结点会话或通过 IoT 中心 SDK 为内置终结点创建使用者组。
获取帮助
如需进一步帮助,请尝试Microsoft Azure 流分析 问答页面。