Apache Spark 助手分析 Spark 运行的命令和代码,并提供笔记本运行的实时建议。 Spark 顾问具有内置模式,可帮助用户避免常见错误、提供代码优化建议、执行错误分析以及查找故障的根本原因。
内置建议
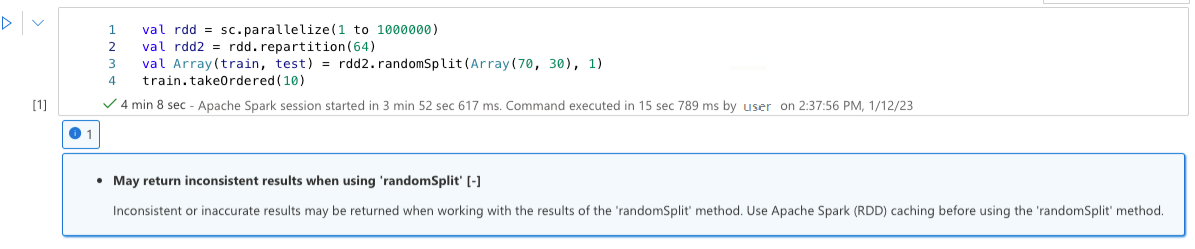
使用“randomSplit”时可能会返回不一致的结果
使用“randomSplit”方法的结果时,可能会返回不一致或不准确的结果。 使用“randomSplit”方法之前,请使用 Apache Spark (RDD) 缓存。
方法 randomSplit() 等效于对数据帧多次执行 sample(),其中每个样本在分区内重新提取、分区和排序数据帧。 跨分区和排序顺序的数据分布对于 randomSplit() 和 sample()都很重要。 如果数据重新提取时发生更改,则可能会出现重复项,或者在拆分中缺失值,并且使用相同种子的相同样本可能会产生不同的结果。
这些不一致可能不会在每次运行时发生,但为了完全消除这些不一致,请缓存数据帧、对列重新分区,或应用聚合函数(如 groupBy)。
表/视图名称已被使用
视图已与创建的表同名,或者已存在与已创建视图同名的表。 在查询或应用程序中使用此名称时,无论最初创建的是哪一个,返回的都将仅是视图。 若要避免冲突,请重命名表或视图。
无法识别提示
所选查询包含无法识别的提示。 验证提示拼写是否正确。
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
找不到指定的关系名称
找不到提示中指定的关系。 验证这些关系是否拼写正确并在提示范围内可访问。
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
查询中的提示可防止应用另一个提示
所选查询包含阻止应用另一个提示的提示。
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
启用“spark.advise.divisionExprConvertRule.enable”以减少舍入错误传播
此查询包含具有 Double 类型的表达式。 建议启用配置“spark.advise.divisionExprConvertRule.enable”,这有助于减少除法表达式并减少舍入错误传播。
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
启用“spark.advise.nonEqJoinConvertRule.enable”以提高查询性能
由于查询中的“Or”条件,此查询包含非常耗时的联接。 建议启用配置“spark.advise.nonEqJoinConvertRule.enable”,这有助于将“Or”条件触发的联接转换为 SMJ 或 BHJ 来加速此查询。
使用小型文件压缩优化增量表
此查询的对象是包含许多小型文件的增量表。 若要提高查询的性能,请在 delta 表上运行 OPTIMIZE 命令。 可在 本文中找到更多详细信息。
使用 ZOrder 优化 Delta 表
此查询位于 Delta 表上,其中包含高度选择性的筛选器。 若要提高查询的性能,请在 delta 表上运行 OPTIMIZE ZORDER BY 命令。 可在 本文中找到更多详细信息。
用户体验
Apache Spark 顾问在 Notebook 单元输出中实时显示建议,包括信息、警告和错误。
信息
警告

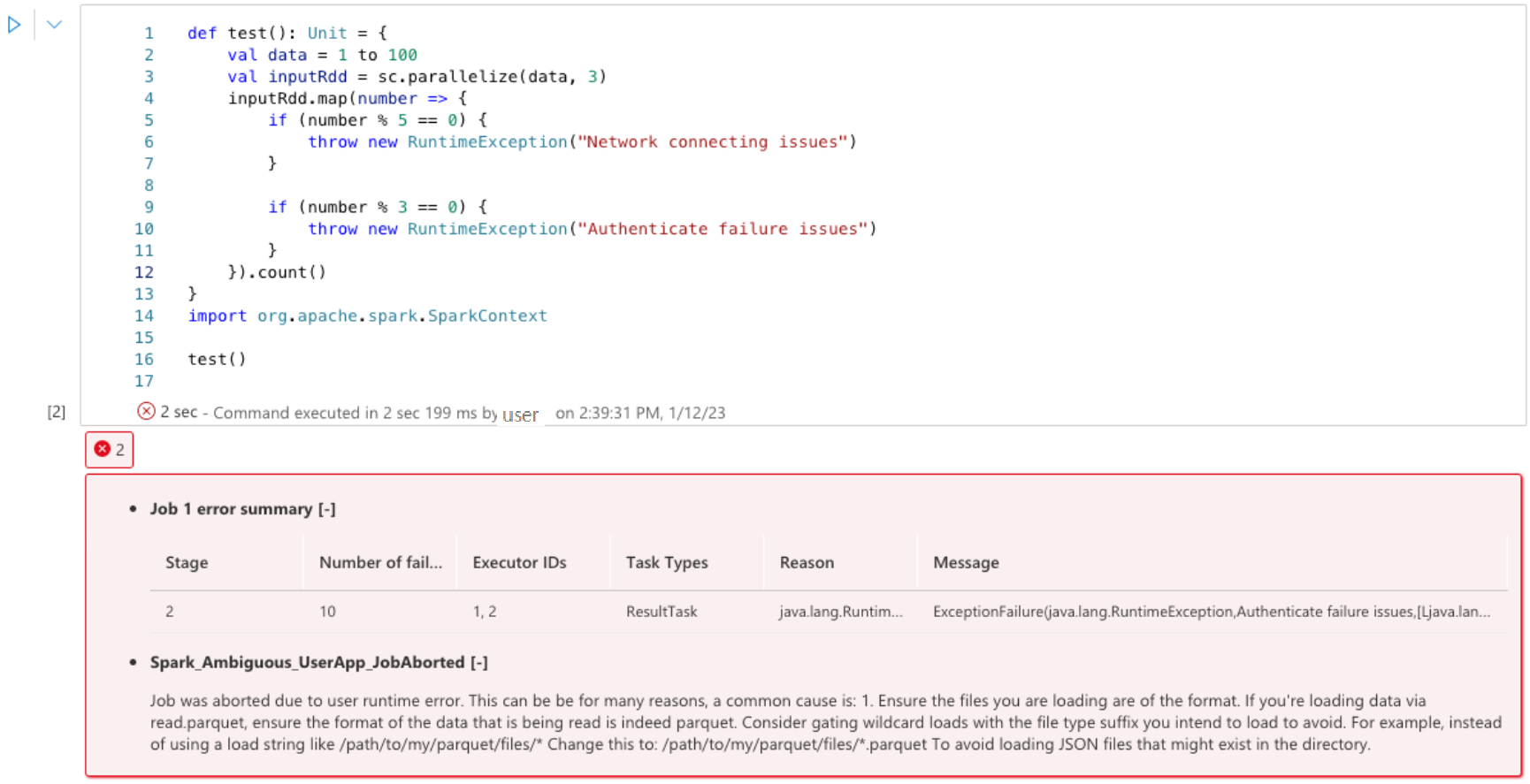
错误
后续步骤
有关监视 Apache Spark 应用程序的详细信息,请参阅 使用 Synapse Studio 监视 Apache Spark 应用程序 的文章。
有关创建笔记本的详细信息,请参阅 如何使用 Synapse 笔记本