适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文概述了如何排查Azure Data Factory中的复制活动性能问题。
运行复制活动后,可以在复制活动监视视图中收集运行结果和性能统计信息。 下图显示了一个示例。
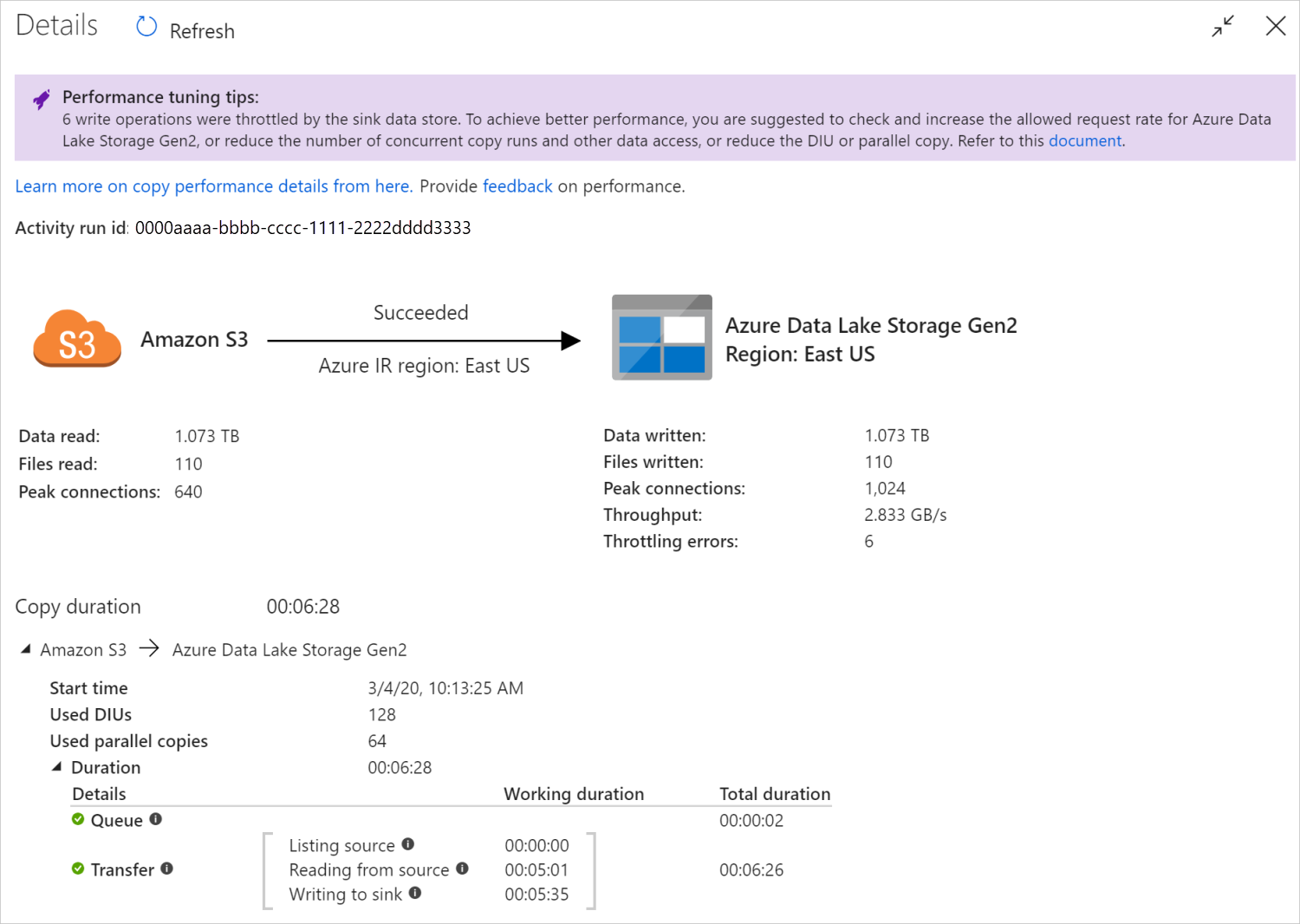
性能优化提示
在某些情况下,运行复制活动时,顶部会显示“性能优化提示”,如上图所示。 这些提示告知服务针对此特定复制运行识别到的瓶颈,并建议如何提高复制吞吐量。 请尝试根据建议进行更改,然后再次运行复制。
作为参考,当前性能优化提示针对以下情况提供了建议:
| 类别 | 性能优化提示 |
|---|---|
| 特定于数据存储 | 将数据加载到 Azure Synapse Analytics:建议(如果未使用)使用 PolyBase 或 COPY 语句。 |
| 将数据从/复制到 Azure SQL Database:当 DTU 使用率过高时,建议升级到更高的层。 | |
| 将数据从/复制到 Azure Cosmos DB:当 RU 使用率过高时,建议升级到更大的 RU。 | |
| 从 SAP 表复制数据:复制大量数据时,建议利用 SAP 连接器的分区选项来启用并行加载并增加最大分区数。 | |
| 从 Amazon Redshift 引入数据:如果未使用 UNLOAD,建议使用它。 | |
| 数据存储限制 | 如果在复制期间数据存储限制了许多读/写操作,则建议检查并增大数据存储允许的请求速率,或减少并发工作负载。 |
| 集成运行时 | 如果您使用自托管 Integration Runtime (IR),并且复制活动在队列中长时间等待,直到 IR 有可用的资源来执行,建议考虑扩展 IR 的容量以增加其可用资源。 |
| 如果您使用的Azure Integration Runtime位于非最佳区域,导致读取和写入速度缓慢,建议配置为使用另一个区域中的 IR。 | |
| 容错 | 如果配置了容错并跳过不兼容的行,导致性能变慢,则建议确保源和接收器数据兼容。 |
| 暂存复制 | 如果配置了分阶段复制,但此方法对于源-接收器对不起作用,则建议删除此方法。 |
| 继续 | 如果复制活动已从上一故障点恢复,但你在完成原始运行后正好更改了 DIU 设置,请注意,新的 DIU 设置不会生效。 |
了解复制活动执行详细信息
复制活动监视视图底部的执行详细信息和持续时间描述了复制活动所要经历的重要阶段(请参阅本文开头的示例),这对于排查复制性能问题特别有用。 复制运行的瓶颈就是持续时间最长的那个运行。 请参阅下表,了解每个阶段的定义,并了解如何利用这些信息在 Azure IR 上排查复制活动问题,以及在自承载 IR 上排查复制活动问题。
| 暂存 | 说明 |
|---|---|
| 排队 | 复制活动在集成运行时中实际启动之前所消逝的时间。 |
| 预复制脚本 | 复制活动在 IR 中启动之后、在接收器数据存储中执行完复制前脚本之前所消逝的时间。 在为数据库接收器配置预复制脚本时应用,例如,将数据写入 Azure SQL Database 时,在复制新数据之前进行清理。 |
| 传输 | 完成前一步骤之后、在 IR 将所有数据从源传输到接收器之前所消逝的时间。 请注意,传输中的子步骤会并行运行,某些操作(例如,分析/生成文件格式)现在未显示。 - 距第一字节的时间: 在前一步骤结束之后、IR 从源数据存储收到第一个字节之前所经过的时间。 适用于不是基于文件的源。 - 列出源代码: 枚举源文件或数据分区所花费的时间。 后者适用于为数据库源配置分区选项,例如,从 Oracle/SAP HANA/Teradata/Netezza/etc 等数据库复制数据时适用。 - 从源中读取: 从源数据存储检索数据所花费的时间。 - 写入接收器: 将数据写入接收器数据存储所花费的时间。 请注意,某些连接器目前没有此指标,包括Azure AI Search、Azure Data Explorer、Azure表存储、Oracle、SQL Server、Common Data Service、Dynamics 365、Dynamics CRM、Salesforce/Salesforce Service Cloud. |
排查 Azure IR 上的复制活动问题
遵循性能优化步骤为方案规划并执行性能测试。
当复制活动性能不符合预期时,若要排查在Azure Integration Runtime上运行的单个复制活动时,如果看到性能优化提示显示在复制监视视图中,请应用建议,然后重试。 否则,请了解复制活动执行详细信息,检查哪个阶段的持续时间最长,并应用以下指导以提升复制性能:
“复制前脚本”的持续时间较长:表示接收器数据库中运行的复制前脚本花费了较长时间来完成。 优化指定的复制前脚本逻辑,以增强性能。 如果在改进脚本方面需要更多的帮助,请与数据库团队联系。
“传输 - 第一个字节的时间”经历了长时间的延迟:源查询需要很长时间才能返回任何数据。 这可能意味着查询处理源需要很长时间,因为源正忙于其他任务,或者查询不是最佳的,或者数据以这样一种方式存储,因此需要很长时间才能检索。 请考虑其他查询是否同时在该源上运行,或者是否有任何可以对查询进行更新,以便它可以更快地检索数据。 如果有一个团队管理数据源,请联系他们来修改查询或检查源性能。
“传输 - 列出源”的工作持续时间较长: 表示枚举源文件或源数据库数据分区的速度缓慢。
从基于文件的源复制数据时,如果对文件夹路径或文件名使用通配符筛选器(
wildcardFolderPath或wildcardFileName),或使用文件上次修改时间筛选器(modifiedDatetimeStart或modifiedDatetimeEnd),请注意,此类筛选器会导致复制活动在客户端中列出指定文件夹下的所有文件,然后应用筛选器。 此类文件枚举可能会变成瓶颈,尤其是只有少量的文件符合筛选规则时。检查是否可以基于按日期时间分区的文件路径或名称复制文件。 这样不会给列表来源端带来负担。
检查是否可以改用数据存储的原生过滤器,特别是针对 Amazon S3/Azure Blob 存储/Azure Files 的“prefix”。 这些筛选器是数据存储服务器端筛选器,拥有更好的性能。
考虑将单个大型数据集拆分为多个小型数据集,并让每个并发运行的复制作业处理一部分数据。 为此,可以使用 Lookup/GetMetadata + ForEach + Copy。 请参阅从多个容器复制文件或将数据从 Amazon S3 迁移到 ADLS Gen2 解决方案模板,其中提供了一般性的示例。
检查服务是否报告了源中的任何限流错误,或者数据存储是否处于高负载状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
在同一个或靠近源数据存储区域中使用 Azure IR。
“传输 - 从源读取”的工作持续时间较长:
采用特定于连接器的数据加载最佳做法(如果适用)。 例如,从 Amazon Redshift 复制数据时,请配置为使用 Redshift UNLOAD。
检查服务是否报告了源中的任何节流错误,或者您的数据存储是否处于高负载状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
检查复制源和接收器模式:
如果复制模式支持 4 个以上的数据集成单位 (DIU) - 请参阅此部分中的详细信息,一般情况下,可以尝试增加 DIU 以获得更好的性能。
否则,请考虑将单个大型数据集拆分为多个小型数据集,并让那些复制作业并发运行,使其各自处理一部分数据。 为此,可以使用 Lookup/GetMetadata + ForEach + Copy。 请参阅从多个容器复制文件、将数据从 Amazon S3 迁移到 ADLS Gen2 或使用控制表进行批量复制解决方案模板,其中提供了一般性的示例。
在同一个或靠近源数据存储区域中使用 Azure IR。
“传输 - 写入接收器”的工作持续时间较长:
采用特定于连接器的数据加载最佳做法(如果适用)。 例如,将数据复制到 Azure Synapse Analytics 时,请使用 PolyBase 或 COPY 语句。
检查该服务是否报告了接收器中的任何限制错误,或者数据存储是否处于高利用率状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
检查复制源和接收器模式:
在同一个或靠近接收器数据存储区域中使用 Azure IR。
排查自承载 IR 中的复制活动的问题
遵循性能优化步骤为方案规划并执行性能测试。
当复制性能不符合预期时,若要排查在Azure Integration Runtime上运行的单个复制活动问题,如果看到性能优化提示显示在复制监视视图中,请应用建议,然后重试。 否则,请了解复制活动执行详细信息,检查哪个阶段的持续时间最长,并应用以下指导以提升复制性能:
“队列”持续时间较长: 表示复制活动在队列中长时间等待,直到Self-hosted IR有资源来执行。 检查 IR 容量和使用率,并根据工作负荷进行纵向或横向扩展。
“传输 - 距第一字节的时间”的工作持续时间较长: 表示源查询花费了较长时间来返回任何数据。 检查并优化查询或服务器。 如需更多帮助,请与数据存储团队联系。
“传输 - 列出源”的工作持续时间较长: 表示枚举源文件或源数据库数据分区的速度缓慢。
检查自托管 IR 服务器是否以较低的延迟连接到源数据存储。 源如果在 Azure 上,您可以使用 此工具 检查自托管 IR 计算机到 Azure 区域的延迟,越低越好。
从基于文件的源复制数据时,如果对文件夹路径或文件名使用通配符筛选器(
wildcardFolderPath或wildcardFileName),或使用文件上次修改时间筛选器(modifiedDatetimeStart或modifiedDatetimeEnd),请注意,此类筛选器会导致复制活动在客户端中列出指定文件夹下的所有文件,然后应用筛选器。 此类文件枚举可能会变成瓶颈,尤其是只有少量的文件符合筛选规则时。检查是否可以基于按日期时间分区的文件路径或名称复制文件。 这样不会给列表来源端带来负担。
检查是否可以改用数据存储的原生过滤器,特别是针对 Amazon S3/Azure Blob 存储/Azure Files 的“prefix”。 这些筛选器是数据存储服务器端筛选器,拥有更好的性能。
考虑将单个大型数据集拆分为多个小型数据集,并让每个并发运行的复制作业处理一部分数据。 为此,可以使用 Lookup/GetMetadata + ForEach + Copy。 请参阅从多个容器复制文件或将数据从 Amazon S3 迁移到 ADLS Gen2 解决方案模板,其中提供了一般性的示例。
检查服务是否报告了源中的任何限流错误,或者数据存储是否处于高负载状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
“传输 - 从源读取”的工作持续时间较长:
检查自托管 IR 服务器是否以较低的延迟连接到源数据存储。 如果你的源位于 Azure中,可以使用此工具检查从自承载 IR 计算机到 Azure 区域的延迟,越低越好。
检查自承载 IR 计算机是否具有足够的入站带宽,可以有效地读取和传输数据。 如果源数据存储位于Azure中,可以使用 此工具检查下载速度。
在 Azure 门户 -> 数据工厂或 Synapse 工作区 -> 概述页中查看自承载 IR 的 CPU 和内存使用率趋势。 如果 CPU 使用率较高或可用内存不足,请考虑对 IR 进行纵向或横向扩展。
采用特定于连接器的数据加载最佳做法(如果适用)。 例如:
从 Oracle 复制数据时,Netezza, Teradata、SAP HANA、SAP Table 和 SAP Open Hub),使数据分区选项能够并行复制数据。
从 HDFS复制数据时,请配置为使用 DistCp。
从 Amazon Redshift 复制数据时,请配置为使用 Redshift UNLOAD。
检查服务是否报告了源中的任何节流错误,或者您的数据存储是否处于高负载状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
检查复制源和接收器模式:
如果从启用分区选项的数据存储复制数据,请考虑逐步优化并行副本。 过多的并行复制甚至可能会损害性能。
否则,请考虑将单个大型数据集拆分为多个小型数据集,并让那些复制作业并发运行,使其各自处理一部分数据。 为此,可以使用 Lookup/GetMetadata + ForEach + Copy。 请参阅从多个容器复制文件、将数据从 Amazon S3 迁移到 ADLS Gen2 或使用控制表进行批量复制解决方案模板,其中提供了一般性的示例。
“传输 - 写入接收器”的工作持续时间较长:
采用特定于连接器的数据加载最佳做法(如果适用)。 例如,将数据复制到 Azure Synapse Analytics 时,请使用 PolyBase 或 COPY 语句。
检查自承载 IR 计算机是否以较低的延迟连接到接收器数据存储。 如果接收器位于Azure中,则可以使用 此工具检查自承载 IR 计算机到Azure区域的延迟,越好越好。
检查自承载 IR 计算机是否具有足够的出站带宽,可以有效地传输和写入数据。 如果接收器数据存储位于Azure中,则可以使用 此工具来检查上传速度。
在 Azure 门户 ->您的数据工厂或 Synapse 工作区 ->概述页面中检查自托管 IR 的 CPU 和内存使用趋势。 如果 CPU 使用率较高或可用内存不足,请考虑对 IR 进行纵向或横向扩展。
检查该服务是否报告了接收器中的任何限制错误,或者数据存储是否处于高利用率状态。 如果是,请减少数据存储上的工作负荷,或者尝试联系数据存储管理员来提高限流或增加资源的可用性。
请考虑逐步调整并行复制。 过多的并行复制甚至可能会损害性能。
连接器和 IR 性能
本部分探讨特定连接器类型或集成运行时的一些性能故障排除指南。
活动执行时间因AZURE IR 与 Azure 虚拟网络 IR 而异
当数据集基于不同的Integration Runtime时,活动执行时间会有所不同。
症状:只需在数据集中切换“链接服务”下拉列表就可以执行相同的管道活动,但运行时间会明显不同。 当数据集基于托管的虚拟网络集成运行时,平均所需时间比基于默认集成运行时的时间要长。
Cause:检查管道运行的详细信息,可以看到速度较慢的管道在托管虚拟网络IR上运行,而速度正常的管道在Azure IR上运行。 根据设计,托管虚拟网络 IR 的排队时间比 Azure IR 更长,因为我们没有为每个服务实例保留一个计算节点。因此,每次复制活动启动时都需要进行预热,这主要发生在虚拟网络联接上,而不是 Azure IR。
将数据加载到 Azure SQL Database 时性能低
Symptoms:将数据复制到 Azure SQL 数据库的过程变慢。
cause:问题的根本原因主要由Azure SQL Database端的瓶颈触发。 下面是一些可能的原因:
Azure SQL Database 层级不足。
Azure SQL Database DTU 使用率接近 100%。 可以监视性能,并考虑升级Azure SQL Database层。
索引未正确设置。 请在加载数据之前先删除所有索引,并在加载完成之后再重新创建索引。
WriteBatchSize 不够大,无法容纳架构行大小。 若要解决此问题,请尝试增大该属性。
使用的是存储过程,而不是批量插入,这会使性能更差。
分析大型Excel文件时超时或性能降低
表现:
创建Excel数据集并从连接/存储、预览数据、列表或刷新工作表导入架构时,如果excel文件大小较大,可能会遇到超时错误。
使用复制活动将数据从大型Excel文件(>= 100 MB)复制到其他数据存储时,可能会遇到性能缓慢或 OOM 问题。
原因:
对于导入架构、预览数据以及在 Excel 数据集上列出工作表等操作, 超时时间固定为 100 秒。 对于大型Excel文件,这些操作可能不会在超时值内完成。
复制活动将整个Excel文件读取到内存中,然后找到指定的工作表和单元格来读取数据。 此行为是由服务使用的基础 SDK 导致的。
解决方法:
对于导入架构,你可以生成一个较小的示例文件(原始文件的一部分),并选择“从示例文件导入架构”而不是“从连接/存储导入架构”。
若要列出工作表,可以改为在工作表下拉框中选择“编辑”并输入工作表名称/索引。
若要将大型excel文件(>100 MB)复制到其他存储中,可以使用Data Flow Excel源,它支持流式读取,性能更佳。
读取大型 JSON/Excel/XML 文件的 OOM 问题
Symptoms:读取大型 JSON/Excel/XML 文件时,在活动执行期间遇到内存不足(OOM)问题。
原因:
- 如果读取的是大型 XML 文件:读取大型 XML 文件时出现内存不足问题是有意这样设计的。 原因是整个 XML 文件必须作为单个对象读取到内存中,然后再推断架构并检索数据。
- 对于大型Excel文件:读取大型Excel文件的 OOM 问题是设计造成的。 原因是使用的 SDK (POI/NPOI) 必须将整个 Excel 文件读取到内存中,然后再推断架构并获取数据。
- 如果读取的是大型 JSON 文件:当 JSON 文件是单个对象时,读取大型 JSON 文件出现内存不足问题是有意这样设计的。
建议做法:采用以下其中一个选项来解决此问题。
- 选项 1:使用性能强(CPU 性能强/内存容量大)的电脑注册联机自承载集成运行时,通过复制活动读取大型文件中的数据。
- 选项 2:使用优化的内存和大型群集(例如,48 个核心),通过映射数据流活动读取大型文件中的数据。
- 选项 3:将大型文件拆分成多个小文件,然后使用复制或映射数据流活动读取文件夹。
- Option-4:如果在复制 XML/Excel/JSON 文件夹时遇到卡住或 OOM 问题,请使用管道中的 foreach 活动和复制/映射数据流活动来单独处理每个文件或子文件夹。
- 选项 5:其他:
其他参考资料
这里是一些支持的数据存储的性能监测和调优参考资料:
- Azure Blob 存储:Blob 存储的可扩展性和性能目标和 Blob 存储的性能和可扩展性清单。
- Azure表存储:表存储的可缩放性和性能目标和表存储的性能和可伸缩性清单。
- Azure SQL Database:可以监视性能并检查数据库事务单位(DTU)百分比。
- Azure Synapse Analytics,其功能以数据仓库单位(DWU)来衡量。 请参阅 Azure Synapse Analytics 中的 管理计算能力(总览)。
- Azure Cosmos DB:Azure Cosmos DB性能级别。
- SQL Server:监控和优化性能。
- 本地文件服务器:文件服务器性能优化。
相关内容
请参阅其他复制活动文章: