适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
Azure 数据工厂提供高性能、稳健且经济高效的机制,用于将数据从 Amazon S3 大规模迁移到 Azure Blob 存储或 Azure Data Lake Storage Gen2。 本文提供面向数据工程师和开发人员的以下信息:
- 性能
- 复制复原能力
- 网络安全
- 高级解决方案体系结构
- 实施最佳实践
性能
ADF 提供了可在不同级别实现并行度的无服务器体系结构,支持开发人员生成管道,以充分利用网络带宽以及存储 IOPS 和带宽将环境的数据移动吞吐量最大化。
客户已成功将由数亿个文件组成的 PB 级数据从 Amazon S3 迁移到 Azure Blob 存储,同时保持 2 GBps 或更高的吞吐量。
图中显示了 A W S S3 存储中的多个文件分区,以及关联的复制操作到 Azure Blob 存储 A D L S Gen2。
上图演示了如何通过不同的并行度实现极佳的数据移动速度:
- 单个复制活动可以利用可缩放的计算资源:在使用 Azure Integration Runtime 时,能够以无服务器方式为每个复制活动指定最多 256 个 DIU;在使用自承载集成运行时时,可以手动纵向扩展计算机或横向扩展为多台计算机(最多 4 个节点),并且单个复制活动会在所有节点之间将其文件集分区。
- 单个复制活动使用多个线程读取和写入数据存储。
- ADF 控制流可以并行启动多个复制活动(例如,使用 For Each 循环)。
复原能力
在单个复制活动运行中,ADF 具有内置的重试机制,因此,它可以处理数据存储或底层网络中特定级别的暂时性故障。
执行从 S3 到 Blob 以及从 S3 到 ADLS Gen2 的二元复制时,ADF 会自动执行检查点设置。 如果某个复制活动运行失败或超时,则在后续重试时,复制将从上一个失败点继续,而不是从头开始。
网络安全
ADF 默认通过 HTTPS 协议使用加密的连接将数据从 Amazon S3 传输到 Azure Blob 存储或 Azure Data Lake Storage Gen2。 HTTPS 提供传输中数据加密,并可防止窃听和中间人攻击。
或者,如果你不希望通过公共 Internet 传输数据,可以通过 AWS Direct Connect 与 Azure ExpressRoute 之间的专用对等互连链路传输数据,以实现更高的安全性。 请参阅下一部分中的解决方案体系结构来了解如何实现此目的。
解决方案体系结构
通过公共 Internet 迁移数据:
图示显示了通过互联网 (HTTP) 从 AWS S3 存储经由 Azure 数据工厂中的 Azure Integration Runtime 迁移到 Azure 存储的过程。该运行时与数据工厂之间有一个控制通道。
- 在此体系结构中,将通过公共 Internet 使用 HTTPS 安全传输数据。
- 源 Amazon S3 和目标 Azure Blob 存储或 Azure Data Lake Storage Gen2 同时配置为允许来自所有网络 IP 地址的流量。 请参阅本页后面提到的第二种架构,了解如何将网络访问限制到特定的 IP 范围。
- 可以轻松地以无服务器方式增大计算力,以充分利用网络和存储带宽,获得环境的最佳吞吐量。
- 可以使用此体系结构实现初始快照迁移和增量数据迁移。
通过专用链路迁移数据:
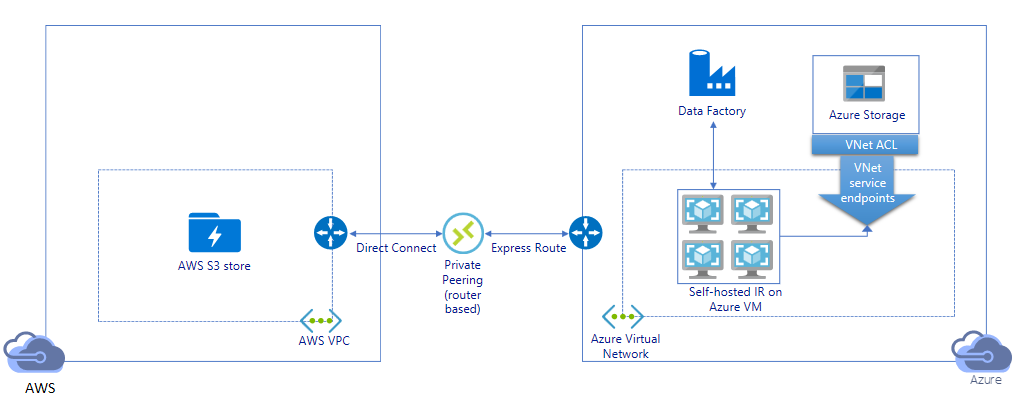
- 在此体系结构中,数据迁移是通过 AWS Direct Connect 与 Azure Express Route 之间的专用对等互连链路完成的,因此,数据永远不会遍历公共 Internet。 它需要使用 AWS VPC 和 Azure 虚拟网络。
- 需要在 Azure 虚拟网络中的 Windows VM 上安装 ADF 自承载集成运行时才能实现此体系结构。 可以手动纵向扩展自承载 IR VM 或横向扩展为多台 VM(最多 4 个节点),以充分利用网络和存储 IOPS/带宽。
- 可以使用此体系结构实现初始快照数据迁移和增量数据迁移。
实施最佳实践
身份验证和凭据管理
- 若要对 Amazon S3 帐户进行身份验证,必须使用 IAM 帐户的访问密钥。
- 支持使用多种身份验证类型连接到 Azure Blob 存储。 强烈建议使用 Azure 资源托管标识:托管标识构建在 Microsoft Entra ID 中自动管理的 ADF 标识基础之上,使你无需在链接服务定义中提供凭据即可配置管道。 或者,可以使用服务主体、共享访问签名或存储帐户密钥对 Azure Blob 存储进行身份验证。
- 也支持使用多种身份验证类型连接到 Azure Data Lake Storage Gen2。 强烈建议使用 Azure 资源托管标识,不过,也可以使用服务主体或存储帐户密钥。
- 如果不使用 Azure 资源托管标识,则强烈建议在 Azure 密钥保管库中存储凭据,以便更轻松地集中管理和轮换密钥,而无需修改 ADF 链接服务。
初始快照数据迁移
建议使用数据分区,尤其是在迁移 100 TB 以上的数据时。 要将数据分区,请使用“前缀”设置按名称筛选 Amazon S3 中的文件夹和文件,然后,每个 ADF 复制作业一次可以复制一个分区。 可以并发运行多个 ADF 复制作业,以获得更好的吞吐量。
如果网络或数据存储的暂时性问题导致任何复制作业失败,你可以重新运行失败的复制作业,以再次从 AWS S3 中重载特定的分区。 加载其他分区的所有其他复制作业将不会受到影响。
增量数据迁移
识别 AWS S3 中新文件或已更改文件的最高效方法是使用时间分区命名约定 - 如果 AWS S3 中的数据已使用文件或文件夹名称中的时间片信息(例如 /yyyy/mm/dd/file.csv)进行时间分区,则管道可以轻松识别要增量复制的文件/文件夹。
或者,如果 AWS S3 中的数据未经过时间分区,则 ADF 可按文件的 LastModifiedDate 来识别新文件或更改的文件。 ADF 的工作原理是扫描 AWS S3 中的所有文件,仅复制上次修改时间戳大于特定值的新文件和更新文件。 请注意,如果 S3 中存在大量文件,则初始文件扫描可能需要很长时间,而无论多少个文件与筛选条件相匹配。 在这种情况下,建议先将数据分区,并使用同一“前缀”设置进行初始快照迁移,以便可以并行执行文件扫描。
对于需要在 Azure 虚拟机上自托管集成运行时的场景
无论是通过专用链路迁移数据,还是想要在 Amazon S3 防火墙中允许特定的 IP 范围,都需要在 Azure Windows VM 上安装自承载集成运行时。
- 建议先对每个 Azure VM 使用以下配置:Standard_D32s_v3 大小,32 个 vCPU,128 GB 内存。 可以在数据迁移过程中持续监视 IR VM 的 CPU 和内存利用率,以确定是否需要进一步纵向扩展 VM 来提高性能,或纵向缩减 VM 来节省成本。
- 还可以通过将最多 4 个 VM 节点关联到单个自承载 IR 进行横向扩展。 针对自承载 IR 运行的单个复制作业将自动对文件集分区,并使用所有 VM 节点来并行复制文件。 为实现高可用性,建议从两个 VM 节点开始,以避免在数据迁移过程中出现单一故障点。
速率限制
最佳做法是使用有代表性的示例数据集执行性能 POC,以便确定适当的分区大小。
起始使用单个分区和默认 DIU 设置的单个复制活动。 逐渐增大 DIU 设置,直到达到网络的带宽限制或数据存储的 IOPS/带宽限制,或者达到单个复制活动允许的最大 DIU 数目 (256)。
接下来,逐渐增加并发复制活动的数目,直到达到环境限制。
遇到 ADF 复制活动报告的限速错误时,请在 ADF 中减小并发数或 DIU 设置,或考虑提高网络和数据存储的带宽/IOPS 限制。
估算价格
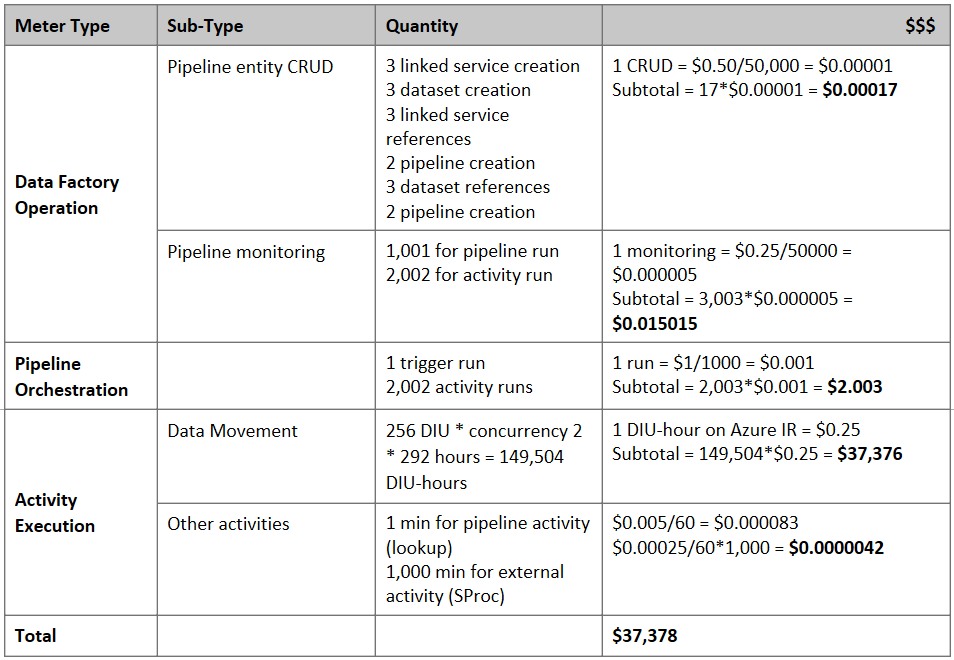
注意
这是一个虚构的定价示例。 您的具体价格取决于环境中的实际吞吐量。
假设构造了以下管道用于将数据从 S3 迁移到 Azure Blob 存储:
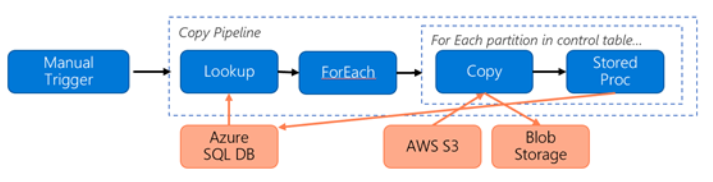
假设条件如下:
- 总数据量为 2 PB
- 使用第一种解决方案体系结构通过 HTTPS 迁移数据
- 2 PB 被划分为 1KB 的分区,每个副本移动一个分区
- 为每个复制操作配置了 DIU=256,可实现 1 GBps 的吞吐量
- ForEach 并发数设置为 2,聚合吞吐量为 2 GB每秒
- 完成迁移总共需要花费 292 小时
下面是根据上述假设估算的价格:
其他参考
- Amazon 简单存储服务连接器
- Azure Blob 存储连接器
- Azure Data Lake Storage Gen2 连接器
- 复制活动性能优化指南
- 创建和配置自承载集成运行时
- 自承载集成运行时的高可用性和可伸缩性
- 数据移动安全注意事项
- 在 Azure 密钥保管库中存储凭据
- 基于时间分区文件名增量复制文件
- 根据 LastModifiedDate 复制新的和已更改的文件
- ADF 定价页
模板
此处是一个模板,用于将由数亿个文件组成的 PB 级数据从 Amazon S3 迁移到 Azure Data Lake Storage Gen2。