适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
本文介绍如何Azure Data Factory复制活动执行从源数据到接收器数据的架构映射和数据类型映射。
架构映射
默认映射
默认情况下,复制活动会以区分大小写的方式按列名称将源数据映射到接收器。 如果接收器不存在(例如,在将数据写入到文件的情况下),则源字段名称将持久保存为接收器名称。 如果接收器已存在,则必须包含从源复制的所有列。 此类默认映射支持灵活的架构以及从源到接收器因执行而异的架构偏差 - 源数据存储返回的所有数据都可复制到接收器。
如果源是无标题行的文本文件,则需要显式映射,因为源不包含列名。
显式映射
你还可以指定显式映射,以便根据需要自定义从源到接收器的列/字段映射。 使用显式映射时,可以只将部分源数据复制到接收器,或将源数据映射到名称不同的接收器,或重塑表格/分层数据。 Copy activity:
- 从源中读取数据并确定源架构。
- 应用已定义的映射。
- 将数据写入接收器。
了解有关以下方面的详细信息:
可在“创作 UI”->“复制活动”->“映射”选项卡上配置映射,也可以采用编程方式在“复制活动”->translator 属性中指定映射。 以下属性在 translator ->mappings 数组 -> 对象 ->source 和 sink 中受支持,后者指向用于映射数据的特定列/字段。
| 房产 | 描述 | 必需 |
|---|---|---|
| 名字 | 源或输出列/字段的名称。 适用于表格源和接收器。 | 是 |
| ordinal | 列索引。 从 1 开始。 在使用带分隔符的文本但没有标头行时应用,为必填项。 |
否 |
| 路径 | 要提取或映射的每个字段的 JSON 路径表达式。 适用于分层源和接收器,例如Azure Cosmos DB、MongoDB 或 REST 连接器。 对于根对象下的字段,JSON 路径以根 $ 开头;对于 collectionReference 属性选择的数组内的字段,JSON 路径从没有 $ 的数组元素开始。 |
否 |
| 类型 | 源或接收器列的临时数据类型。 通常无需指定或更改此属性。 详细了解数据类型映射。 | 否 |
| 区域性 | 源或接收器列的区域性。 当类型为 Datetime 或 Datetimeoffset 时应用。 默认值为 en-us。通常无需指定或更改此属性。 详细了解数据类型映射。 |
否 |
| 格式 | 当类型为 Datetime 或 Datetimeoffset 时要使用的格式字符串。 请参阅自定义日期和时间格式字符串,了解如何设置日期时间格式。 通常无需指定或更改此属性。 详细了解数据类型映射。 |
否 |
除 translator 外,mappings 下还支持以下属性:
| 房产 | 描述 | 必需 |
|---|---|---|
| collectionReference | 从分层源(如 Azure Cosmos DB、MongoDB 或 REST 连接器)复制数据时适用。 若要进行迭代操作,以同一模式从数组字段中的对象提取数据并按行和对象进行转换,请指定要进行交叉应用的该数组的 JSON 路径。 |
否 |
表格源到表格接收器
例如,将数据从 Salesforce 复制到Azure SQL Database并显式映射三列:
在“复制活动”->“映射”选项卡上,单击“导入架构”按钮以导入源架构和目标架构。
映射所需字段并排除/删除其余字段。

可以在复制活动有效负载(请参阅 translator)中将相同的映射配置为以下内容:
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "SalesforceSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "name": "Id" },
"sink": { "name": "CustomerID" }
},
{
"source": { "name": "Name" },
"sink": { "name": "LastName" }
},
{
"source": { "name": "LastModifiedDate" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
若要从没有标题行的带分隔符的文本文件复制数据,则这些列将按序号而不是名称来呈现。
{
"name": "CopyActivityTabularToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "DelimitedTextSource" },
"sink": { "type": "SqlSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "ordinal": "1" },
"sink": { "name": "CustomerID" }
},
{
"source": { "ordinal": "2" },
"sink": { "name": "LastName" }
},
{
"source": { "ordinal": "3" },
"sink": { "name": "ModifiedDate" }
}
]
}
},
...
}
分层源到表格接收器
将数据从分层源复制到表格接收器时,复制活动支持以下功能:
- 从对象和数组中提取数据。
- 从数组中交叉应用具有相同模式的多个对象,在这种情况下,可以将一个 JSON 对象转换为表格结果中的多个记录。
对于更高级的分层到表格转换,可以使用 Data Flow。
例如,如果源 MongoDB 文档的内容如下:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
而你需要按以下格式通过平展数组中数据(order_pd 和 order_price)的方式将其复制到带标题行的文本文件中,并使用常见的根信息(编号、日期和城市)进行交叉联接:
| 订单号 | 订单日期 | order_pd | 订单价格 | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | 西雅图 |
| 01 | 20170122 | P2 | 13 | 西雅图 |
| 01 | 20170122 | P3 | 231 | 西雅图 |
可在数据工厂创作 UI 上定义此类映射:
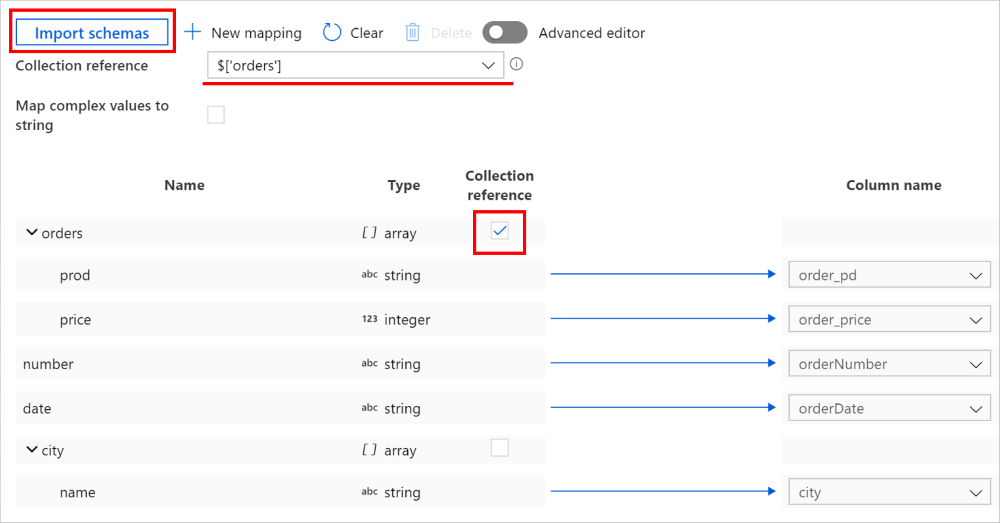
在“复制活动”->“映射”选项卡上,单击“导入架构”按钮以导入源架构和目标架构。 由于服务在导入架构时会对前几个对象采样,因此如果没有显示任何字段,你可以将其添加到层次结构中的正确层上:将鼠标指针悬停在现有字段名称上,然后选择添加节点、对象或数组。
选择要从中遍历和提取数据的数组。 它将自动填充为集合引用。 请注意,此类操作只支持单个数组。
将所需字段映射到接收器。 服务自动确定分层端对应的 JSON 路径。
注意
对于标记为集合引用的数组为空且选中此复选框的记录,将跳过整个记录。
还可以切换到“高级编辑器”,在这种情况下,可以直接查看和编辑字段的 JSON 路径。 如果选择在此视图中添加新映射,请指定 JSON 路径。
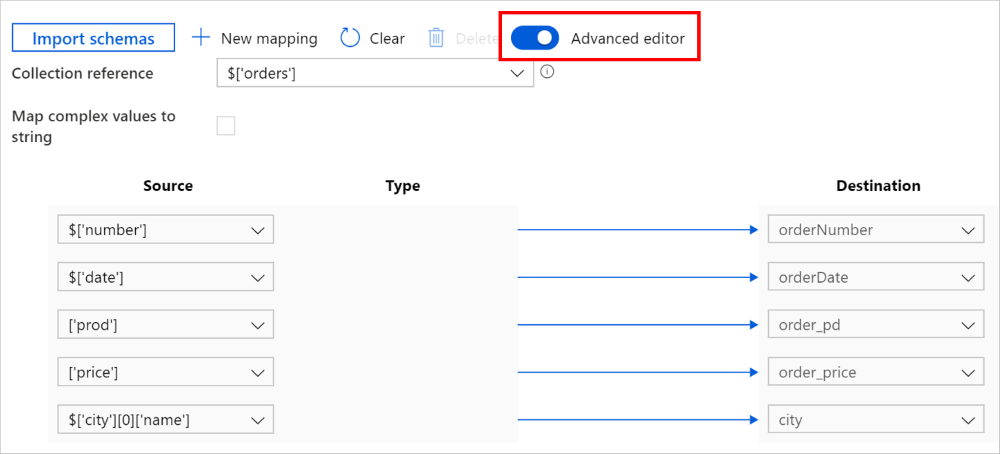
可以在复制活动有效负载(请参阅 translator)中将相同的映射配置为以下内容:
{
"name": "CopyActivityHierarchicalToTabular",
"type": "Copy",
"typeProperties": {
"source": { "type": "MongoDbV2Source" },
"sink": { "type": "DelimitedTextSink" },
"translator": {
"type": "TabularTranslator",
"mappings": [
{
"source": { "path": "$['number']" },
"sink": { "name": "orderNumber" }
},
{
"source": { "path": "$['date']" },
"sink": { "name": "orderDate" }
},
{
"source": { "path": "['prod']" },
"sink": { "name": "order_pd" }
},
{
"source": { "path": "['price']" },
"sink": { "name": "order_price" }
},
{
"source": { "path": "$['city'][0]['name']" },
"sink": { "name": "city" }
}
],
"collectionReference": "$['orders']"
}
},
...
}
表格/分层源到分层接收器
用户体验流类似于分层源到表格接收器。
将数据从表格源复制到分层接收器时,不支持写入到对象内的数组。
将数据从分层源复制到分层接收器时,还可以通过选择对象/数组并映射到接收器而不触及内部字段,来保留整个层的分层结构。
对于更高级的数据重塑转换,可以使用 Data Flow。
参数化映射
若要创建模板化管道以动态复制大量对象,请确定你是可以利用默认映射,还是需要为相应的对象定义显式映射。
如果需要显式映射,可执行以下操作:
在管道级别定义一个对象类型的参数,例如
mapping。将映射参数化:在“复制活动”->“映射”选项卡上,选择添加动态内容并选择上面的参数。 活动有效负载将如下所示:
{ "name": "CopyActivityHierarchicalToTabular", "type": "Copy", "typeProperties": { "source": {...}, "sink": {...}, "translator": { "value": "@pipeline().parameters.mapping", "type": "Expression" }, ... } }构造要传递给映射参数的值。 它应该是
translator定义的整个对象,请参阅显式映射部分中的示例。 例如,对于表格源到表格接收器的复制,值应该是{"type":"TabularTranslator","mappings":[{"source":{"name":"Id"},"sink":{"name":"CustomerID"}},{"source":{"name":"Name"},"sink":{"name":"LastName"}},{"source":{"name":"LastModifiedDate"},"sink":{"name":"ModifiedDate"}}]}。
数据类型映射
Copy activity 执行源类型到汇集类型映射的流程如下:
- 将源数据的本机数据类型转换为 Azure Data Factory 和 Synapse 管道所使用的中间数据类型。
- 根据需要自动转换临时数据类型,使之匹配相应的接收器类型(适用于默认映射和显式映射)。
- 从临时数据类型转换为接收器原生数据类型。
Copy activity目前支持以下中间数据类型:布尔、字节、字节数组、Datetime、DatetimeOffset、Decimal、Double、GUID、Int16、Int32、Int64、SByte、Single、String、Timespan、UInt16、UInt32和UInt64。
从源到接收器支持在临时类型之间进行以下数据类型转换。
| 源\接收器 | 布尔 | 字节数组 | 日期/时间 | 小数 | 浮点数 | GUID | 整数 | 字符串 | TimeSpan |
|---|---|---|---|---|---|---|---|---|---|
| 布尔 | ✓ | ✓ | ✓ | ✓ | |||||
| 字节数组 | ✓ | ✓ | |||||||
| 日期/时间 | ✓ | ✓ | |||||||
| 小数 | ✓ | ✓ | ✓ | ✓ | |||||
| 浮点数 | ✓ | ✓ | ✓ | ✓ | |||||
| GUID | ✓ | ✓ | |||||||
| 整数 | ✓ | ✓ | ✓ | ✓ | |||||
| 字符串 | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ | |
| TimeSpan | ✓ | ✓ |
(1) 日期/时间包括 DateTime、DateTimeOffset、日期和时间。
(2) 浮点数包括 Single 和 Double。
(3) 整数包括 SByte、Byte、Int16、UInt16、Int32、UInt32、Int64 和 UInt64。
注意
- 在表格数据之间进行复制时,目前支持此类数据类型转换。 不支持分层源/接收器,这意味着在源和接收器临时类型之间没有系统定义的数据类型转换。
- 此功能适用于最新的数据集模型。 如果在 UI 中未看到此选项,请尝试创建一个新数据集。
复制活动支持以下用于数据类型转换的属性(对于程序编写,位于 translator 部分下):
| 房产 | 描述 | 必需 |
|---|---|---|
| typeConversion | 实现新的数据类型转换体验。 考虑到后向兼容性,默认值为 false。 对于自 2020 年 6 月末以来通过数据工厂创作 UI 创建的新复制活动,默认情况下会启用此数据类型转换以实现最佳体验。你可以在适用方案的“复制活动”->“映射”选项卡上查看以下类型的转换设置。 若要以编程方式创建管道,需要将 typeConversion 属性显式设置为 true 以启用它。对于在此功能发布之前创建的现有复制活动,你不会在创作 UI 上看到有关后向兼容的类型转换选项。 |
否 |
| typeConversionSettings | 一组类型转换设置。 当 typeConversion 设置为 true 时应用。 以下属性都属于此组。 |
否 |
在 typeConversionSettings 下 |
||
| allowDataTruncation | 复制期间使用不同类型将源数据转换为接收器数据(例如,从小数转换为整数,从 DatetimeOffset 转换为 Datetime)时,允许数据截断。 默认值为 true。 |
否 |
| treatBooleanAsNumber | 将布尔值视为数字,例如,将 true 视为 1。 默认值为 false。 |
否 |
| dateFormat | 在日期和字符串之间转换时设置字符串格式,例如 yyyy-MM-dd。 请参阅自定义日期和时间格式字符串,了解详细信息。 |
否 |
| dateTimeFormat | 在日期(不包含时区偏移)和字符串之间进行转换时的格式字符串,例如 yyyy-MM-dd HH:mm:ss.fff。 请参阅自定义日期和时间格式字符串,了解详细信息。 |
否 |
| dateTimeOffsetFormat | 在日期(包含时区偏移)和字符串之间进行转换时的格式字符串,例如 yyyy-MM-dd HH:mm:ss.fff zzz。 请参阅自定义日期和时间格式字符串,了解详细信息。 |
否 |
| timeSpanFormat | 在时间段和字符串之间进行转换时的格式字符串,例如 dd\.hh\:mm。 请参阅自定义 TimeSpan 格式字符串,了解详细信息。 |
否 |
| timeFormat | 在时间与字符串之间转换时设置字符串格式,例如 HH:mm:ss.fff。 请参阅自定义日期和时间格式字符串,了解详细信息。 |
否 |
| 区域性 | 转换数据类型时要使用的区域文化信息,例如 en-us 或 fr-fr。 |
否 |
Example:
{
"name": "CopyActivity",
"type": "Copy",
"typeProperties": {
"source": {
"type": "ParquetSource"
},
"sink": {
"type": "SqlSink"
},
"translator": {
"type": "TabularTranslator",
"typeConversion": true,
"typeConversionSettings": {
"allowDataTruncation": true,
"treatBooleanAsNumber": true,
"dateTimeFormat": "yyyy-MM-dd HH:mm:ss.fff",
"dateTimeOffsetFormat": "yyyy-MM-dd HH:mm:ss.fff zzz",
"timeSpanFormat": "dd\.hh\:mm",
"culture": "en-gb"
}
}
},
...
}
旧模型
注意
为实现后向兼容性,照旧支持下述可将源列/字段映射到接收器的模型。 建议使用架构映射中提到的新模型。 创作 UI 已切换为生成新模型。
备用列映射(旧模型)
可以指定复制活动 ->translator ->columnMappings,以便在表格形式的数据之间进行映射。 在这种情况下,输入和输出数据集都需要“structure”部分。 列映射支持将源数据集“structure”中的所有列或列子集映射到接收器数据集“structure”中的所有列。 以下是导致异常的错误条件:
- 源数据存储查询结果中没有输入数据集“structure”部分中指定的列名称。
- 接收器数据存储(如果具有预定义架构)没有输出数据集“structure”部分中指定的列名称。
- 接收器数据集“structure”中的列数量多于或少于映射中指定的数量。
- 重复的映射。
在以下示例中,输入数据集有一个结构,并且它指向本地 Oracle 数据库中的表。
{
"name": "OracleDataset",
"properties": {
"structure":
[
{ "name": "UserId"},
{ "name": "Name"},
{ "name": "Group"}
],
"type": "OracleTable",
"linkedServiceName": {
"referenceName": "OracleLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SourceTable"
}
}
}
在本示例中,输出数据集包含一个结构,并指向 Salesfoce 中的表。
{
"name": "SalesforceDataset",
"properties": {
"structure":
[
{ "name": "MyUserId"},
{ "name": "MyName" },
{ "name": "MyGroup"}
],
"type": "SalesforceObject",
"linkedServiceName": {
"referenceName": "SalesforceLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "SinkTable"
}
}
}
以下 JSON 定义管道中的复制活动。 使用 translator -columnMappings 属性将源中的列映射到接收器中的列。
{
"name": "CopyActivity",
"type": "Copy",
"inputs": [
{
"referenceName": "OracleDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "SalesforceDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": { "type": "OracleSource" },
"sink": { "type": "SalesforceSink" },
"translator":
{
"type": "TabularTranslator",
"columnMappings":
{
"UserId": "MyUserId",
"Group": "MyGroup",
"Name": "MyName"
}
}
}
}
如果使用语法 "columnMappings": "UserId: MyUserId, Group: MyGroup, Name: MyName" 指定列映射,则仍然按原样支持它。
备用架构映射(旧模型)
可以指定复制活动 ->translator ->schemaMapping,以便在分层形状数据和表格形状数据之间映射,例如,从 MongoDB/REST 复制到文本文件,并从 Oracle 复制到 MongoDB 的Azure Cosmos DB。 复制活动 translator 部分支持以下属性:
| 房产 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动转换器的 type 属性必须设置为:TabularTranslator | 是 |
| schemaMapping | 键值对的集合,代表从源端到接收器端的映射关系。 - 键:代表源。 对于表格源,指定数据集结构中定义的列名称;对于分层源,指定要提取和映射的每个字段的 JSON 路径表达式。 - 值:代表汇聚。 对于表格接收器,指定数据集结构中定义的列名称;对于分层接收器,指定要提取和映射的每个字段的 JSON 路径表达式。 在使用分层数据时,对于根对象下的字段,JSON 路径以根 $ 开头;对于按 collectionReference 属性选择的数组中的字段,JSON 路径以数组元素开头。 |
是 |
| collectionReference | 若要进行迭代操作,以同一模式从数组字段中的对象提取数据并按行和对象进行转换,请指定要进行交叉应用的该数组的 JSON 路径。 仅当分层数据为源时,才支持此属性。 | 否 |
示例:从 MongoDB 复制到 Oracle:
例如,如果 MongoDB 文档的内容如下:
{
"id": {
"$oid": "592e07800000000000000000"
},
"number": "01",
"date": "20170122",
"orders": [
{
"prod": "p1",
"price": 23
},
{
"prod": "p2",
"price": 13
},
{
"prod": "p3",
"price": 231
}
],
"city": [ { "name": "Seattle" } ]
}
希望按以下格式将其复制到 Azure SQL 表中,方法是将数组 (order_pd 和 order_price) 展平,并与通用根信息 (数字、日期和城市) 进行交叉连接。
| 订单号 | 订单日期 | order_pd | 订单价格 | city |
|---|---|---|---|---|
| 01 | 20170122 | P1 | 23 | 西雅图 |
| 01 | 20170122 | P2 | 13 | 西雅图 |
| 01 | 20170122 | P3 | 231 | 西雅图 |
将架构映射规则配置为以下复制活动 JSON 示例:
{
"name": "CopyFromMongoDBToOracle",
"type": "Copy",
"typeProperties": {
"source": {
"type": "MongoDbV2Source"
},
"sink": {
"type": "OracleSink"
},
"translator": {
"type": "TabularTranslator",
"schemaMapping": {
"$.number": "orderNumber",
"$.date": "orderDate",
"prod": "order_pd",
"price": "order_price",
"$.city[0].name": "city"
},
"collectionReference": "$.orders"
}
}
}
相关内容
请参阅关于复制活动的其他文章: