适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
机器学习项目采用自动化机器学习 (AutoML) 来训练、调整和获取最佳模型,此过程将自动使用你指定用于分类、回归和时序预测的目标指标。
AutoML 的一大挑战是,来自数据仓库或事务数据库的原始数据将是一个巨大的数据集,可能有 10 GB 之多。 大型数据集需要更长的时间来训练模型,因此我们建议在训练 Azure 机器学习模型之前优化数据处理。 本教程将介绍如何使用 Azure 数据工厂将数据集分区为机器学习数据集的 AutoML 文件。
AutoML 项目包含以下三种数据处理方案:
在训练模型之前将大数据分区到 AutoML 文件。
Pandas 数据帧通常用于在训练模型之前处理数据。 Pandas 数据帧非常适合小于 1 GB 的数据,但如果数据大于 1 GB,Pandas 数据帧处理数据的速度便会放缓。 有时可能会收到提示内存不足的错误消息。 建议为机器学习选择 Parquet 文件格式,因为它是二进制纵栏式格式。
数据工厂映射数据流是采用直观设计的数据转换,可以将数据工程师从编写代码中解放出来。 映射数据流是处理大型数据的一种有效方法,因为管道使用横向扩展的 Spark 群集。
拆分训练数据集和测试数据集。
训练数据集将用于训练模型。 测试数据集将用于评估机器学习项目中的模型。 用于映射数据流的有条件拆分活动会拆分训练数据和测试数据。
删除不符合条件的数据。
可能想要删除不符合条件的数据,如行数为 0 的 Parquet 文件。 在本教程中,我们将使用聚合活动获取行计数。 行计数将是删除不符合条件的数据的条件。
准备工作
使用以下 Azure SQL 数据库表。
CREATE TABLE [dbo].[MyProducts](
[ID] [int] NULL,
[Col1] [char](124) NULL,
[Col2] [char](124) NULL,
[Col3] datetime NULL,
[Col4] int NULL
)
将数据格式转换为 Parquet
以下数据流可将 SQL 数据库表转换为 Parquet 文件格式:
- 源数据集:SQL 数据库的事务表。
- 接收器数据集:采用 Parquet 格式的 Blob 存储。
基于行计数删除不符合条件的数据
假设我们需要删除行计数小于 2 的数据。
使用聚合活动获取行计数。 使用基于 Col2 的“分组”,然后通过
count(1)“聚合”以获取行计数。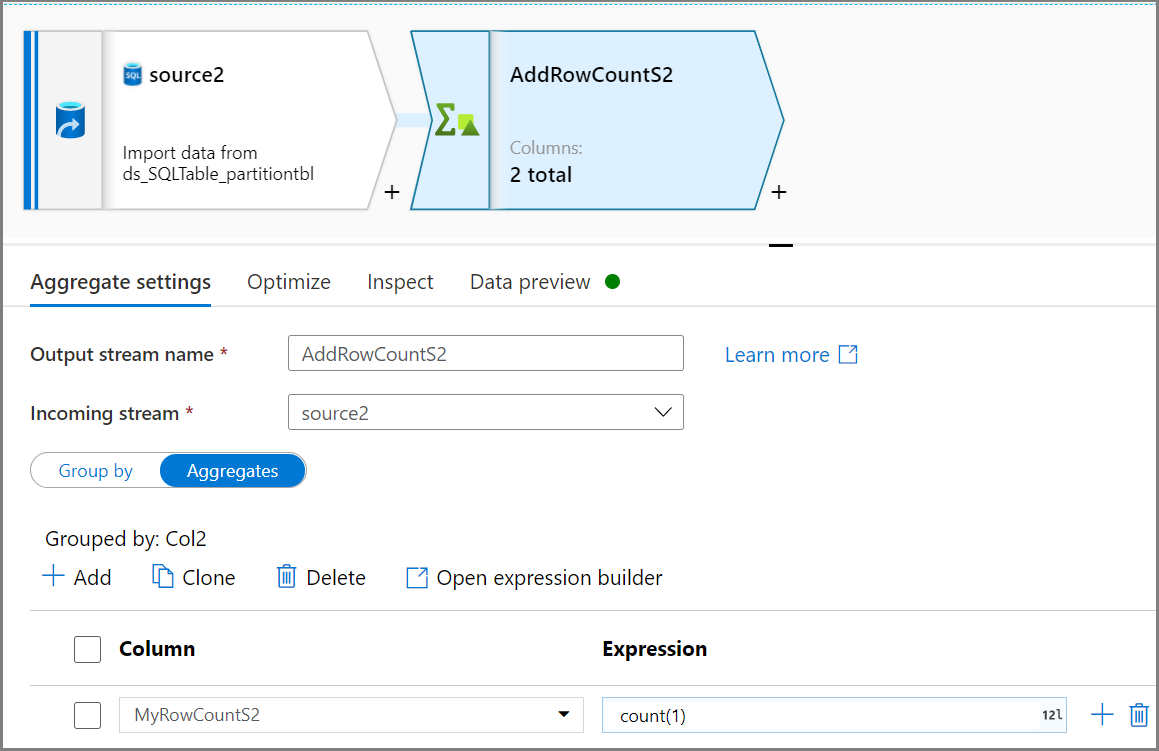
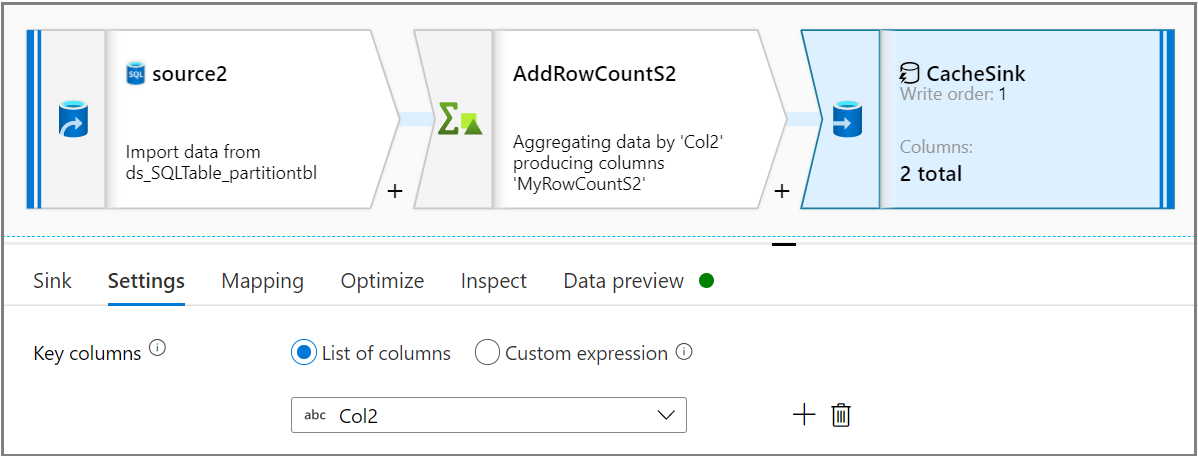
使用接收器活动,在“接收器”选项卡上,选择“缓存”作为“接收器类型”。然后在“设置”选项卡上的“键列”下拉列表中,选择所需的列 。
使用派生列活动在源流中添加行计数列。 在“派生列的设置”选项卡上,使用
CacheSink#lookup表达式从 CacheSink 中获取行计数。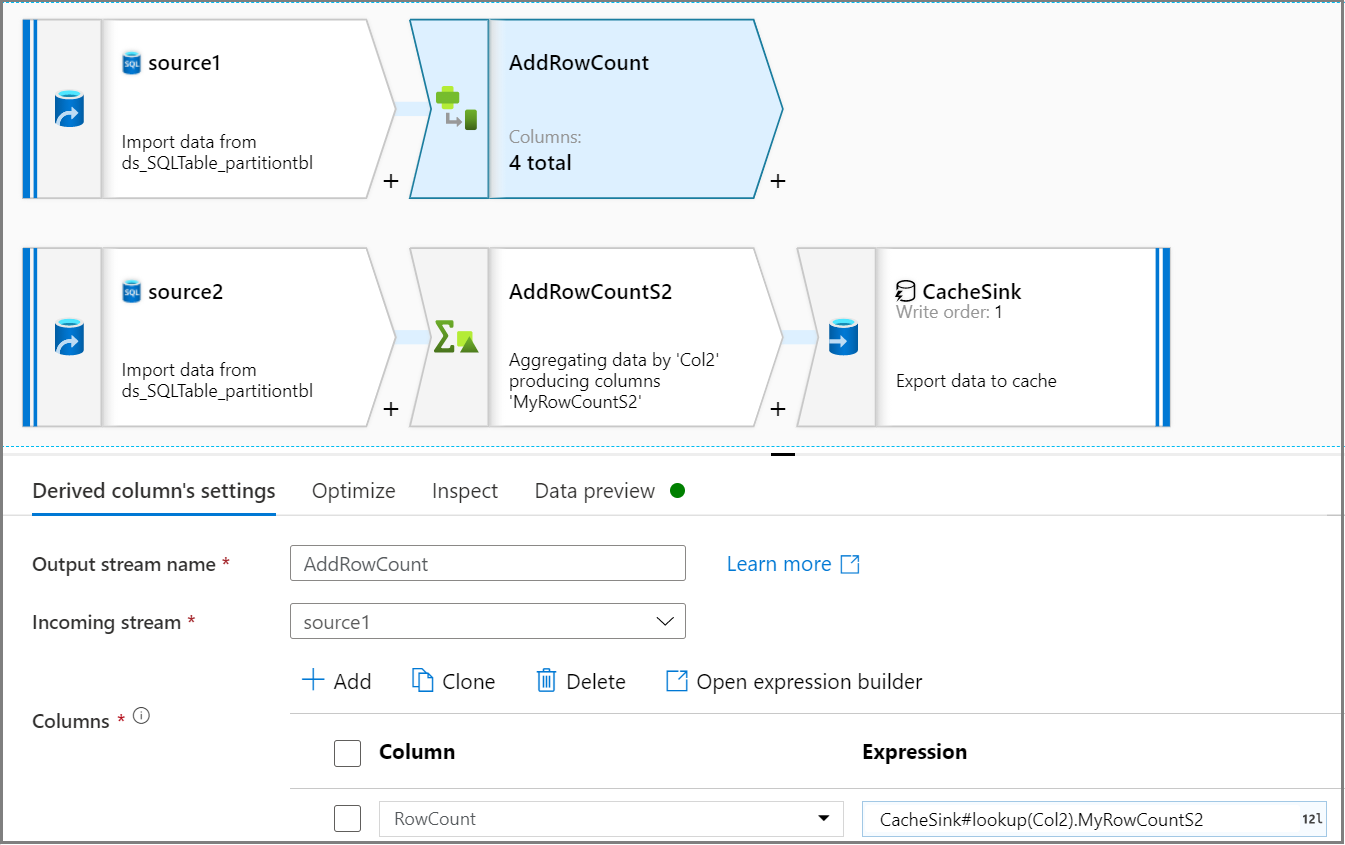
使用有条件拆分活动可删除不符合条件的数据。 在此示例中采用基于 Col2 列的行计数。 条件是删除行计数小于 2 的数据,因此将删除两行(ID = 2 和 ID = 7)。 你需要将不符合条件的数据保存到 blob 存储,以便进行数据管理。
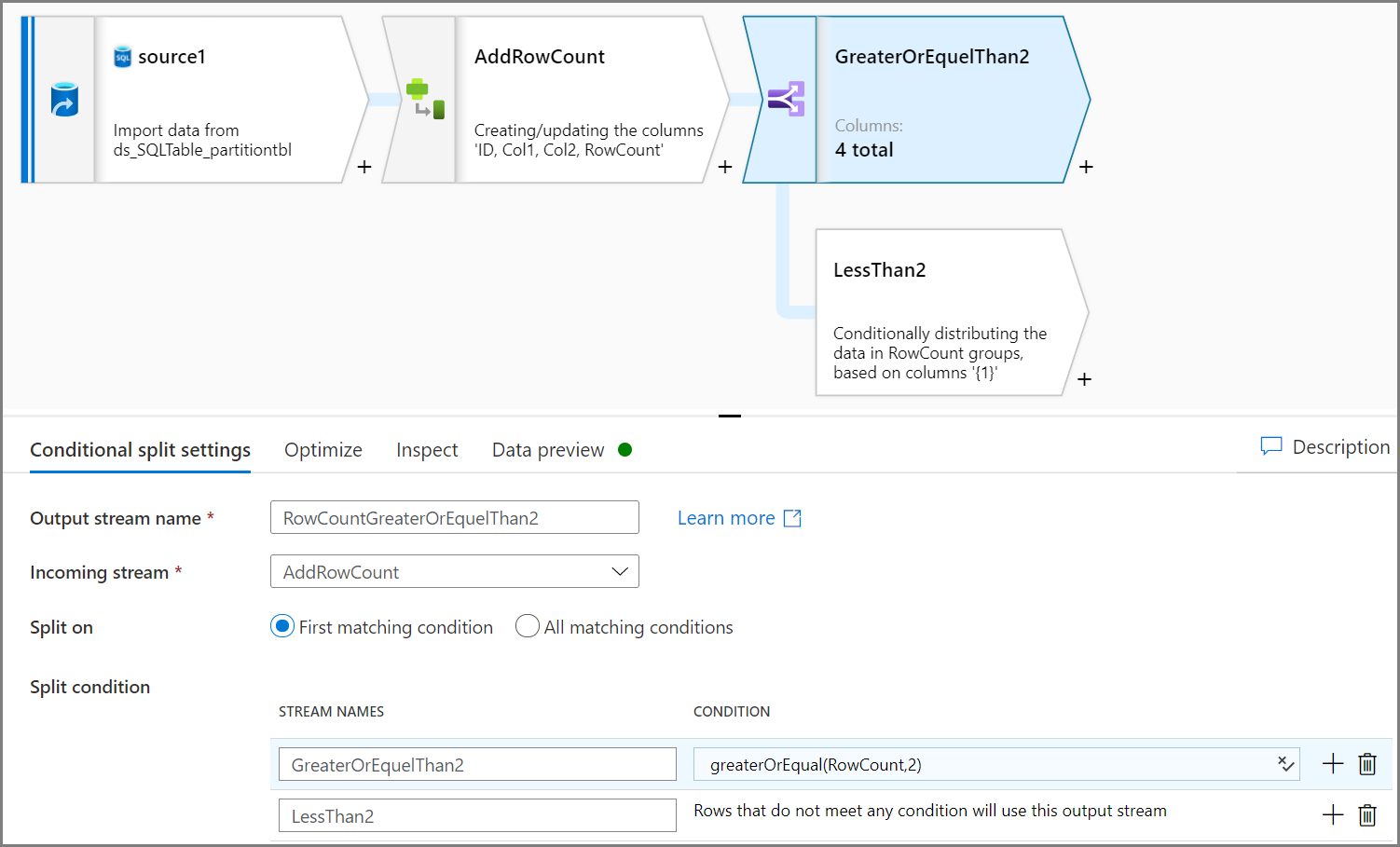
注意
- 创建一个用于获取行计数的新源,在后续步骤中将在初始源中使用行计数。
- 出于性能考虑,请使用 CacheSink。
拆分训练数据和测试数据
我们想要拆分每个分区的训练数据和测试数据。 在此示例中,对于相同的 Col2 值,请获取前 2 行作为测试数据,并获取其余行作为训练数据。
使用窗口活动为每个分区添加一个列行号。 在“超过”选项卡上,为分区选择一个列。 在本教程中,我们将对 Col2 进行分区。 在“排序”选项卡上给出一个顺序,本教程中将基于 ID 排序。 在“窗口列”选项卡上给出一个顺序,为每个分区添加一列作为行号。
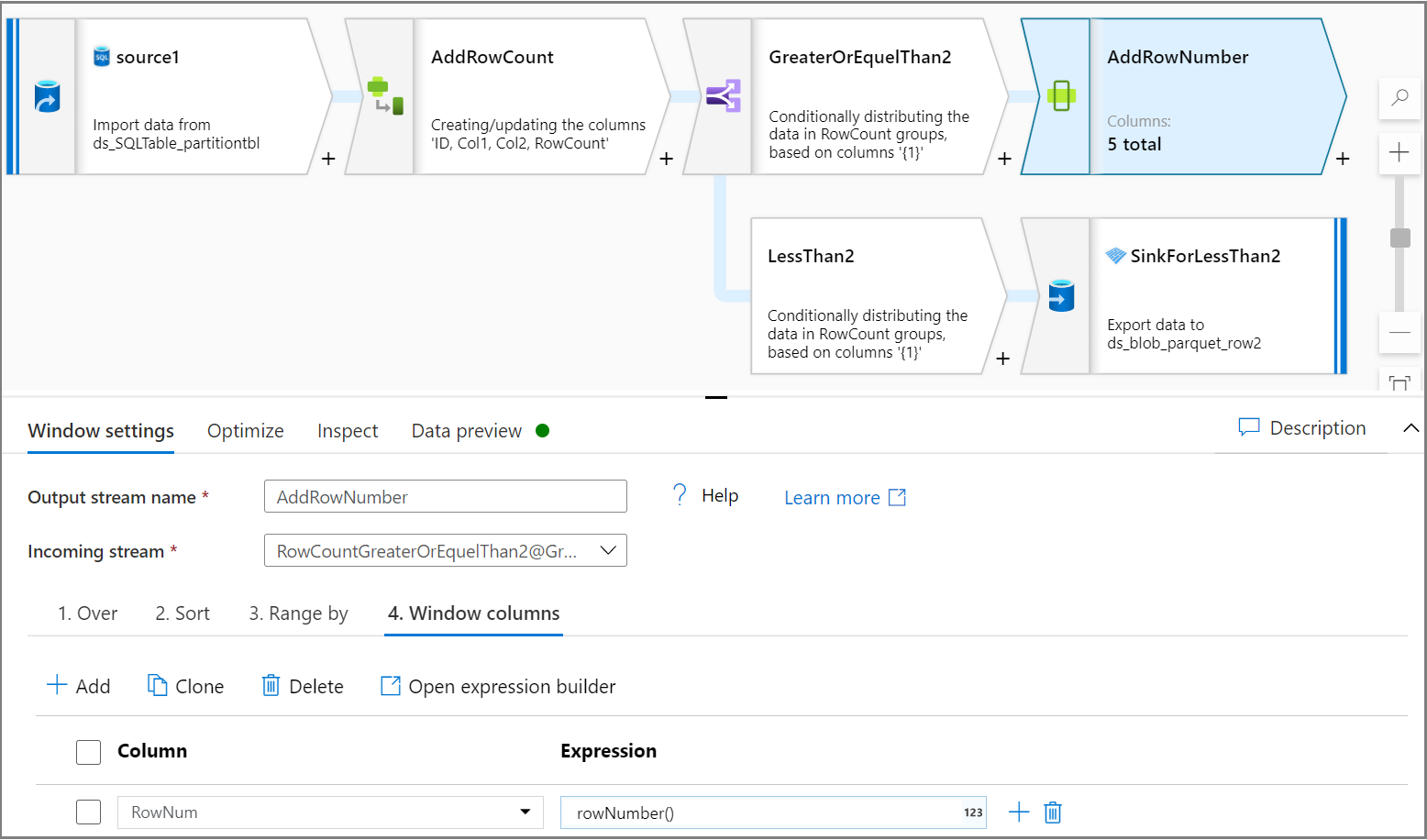
使用“有条件拆分”活动可将每个分区的前 2 行拆分为测试数据集,并将其余行拆分为训练数据集。 在“有条件拆分设置”选项卡上,将表达式
lesserOrEqual(RowNum,2)用作条件。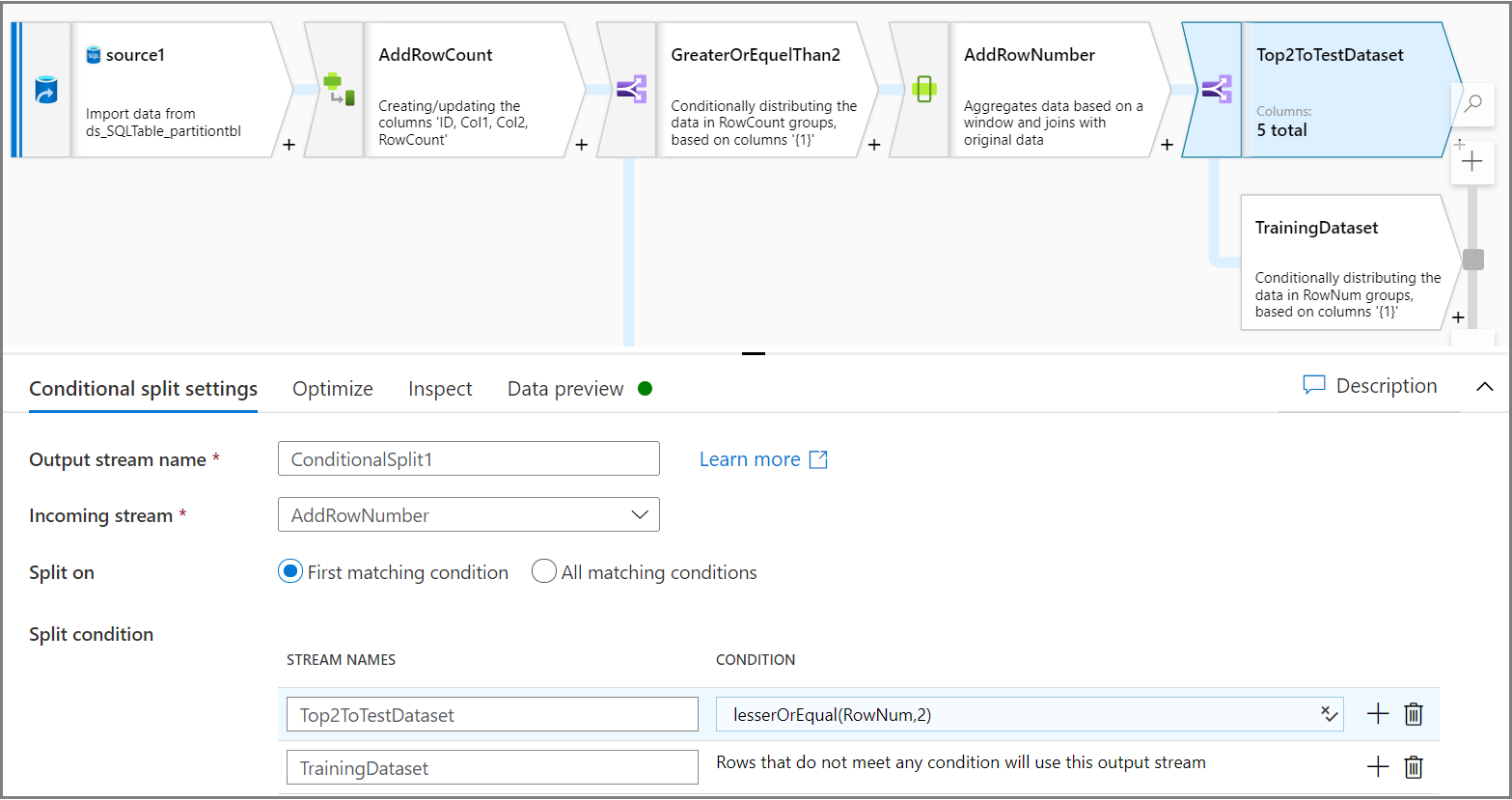
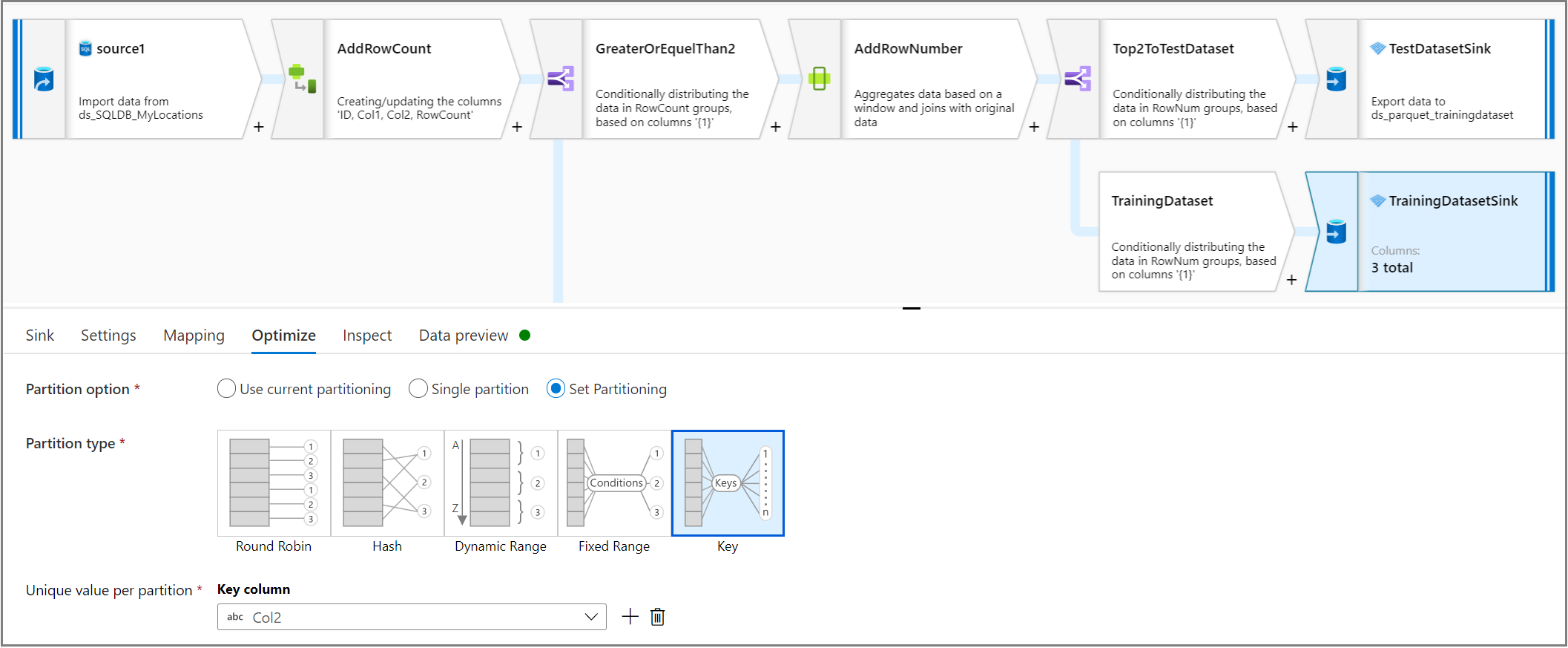
采用 Parquet 格式对训练和测试数据集进行分区
使用接收器活动,在“优化”选项卡中,使用“每个分区的唯一值”将列设置为分区的列键。
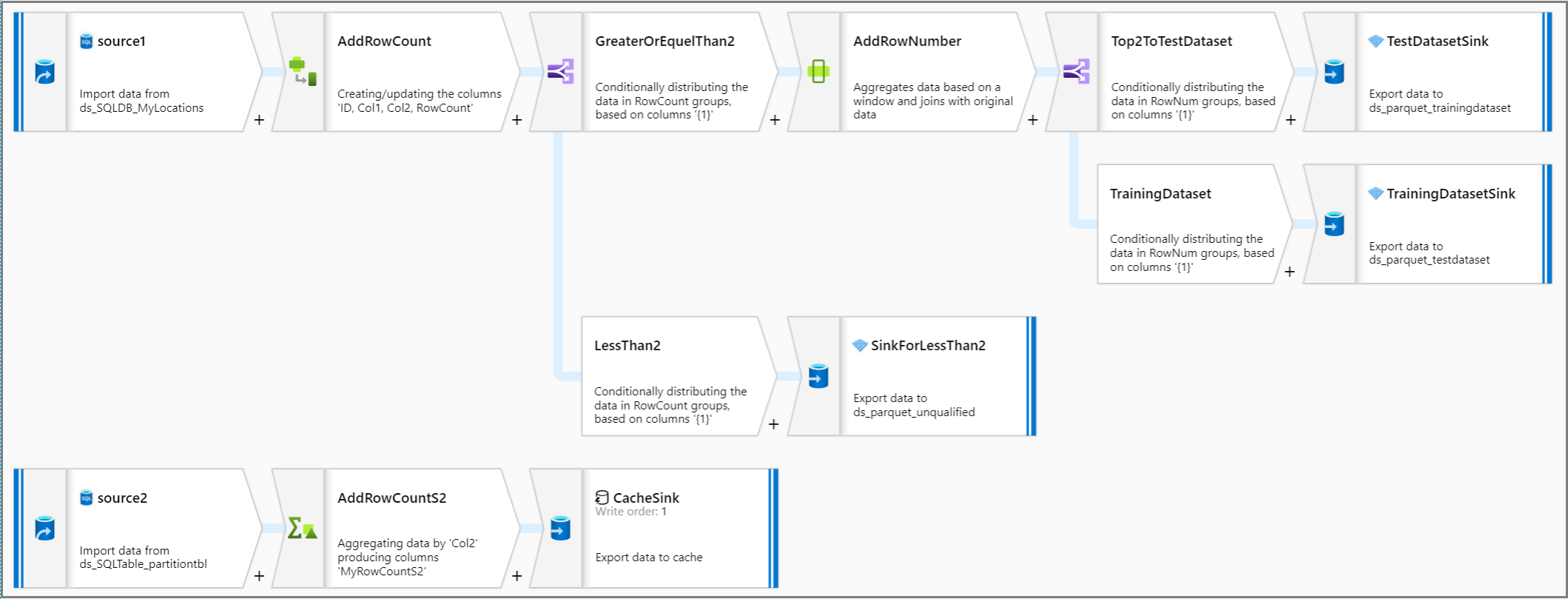
让我们回顾一下整个管道逻辑。
相关内容
使用映射数据流转换来生成数据流逻辑的其余部分。