重要
此功能目前以公共预览版提供。 可以在预览页面上确认加入状态。 请参阅 管理 Azure Databricks 预览版。
重要
- 本文档已过时,将来可能不会更新。 本内容中提及的产品、服务或技术不再受支持。
- 本文中的指南适用于旧式 MLflow 模型服务。 Databricks 建议你将模型服务工作流迁移到模型服务,从而获取增强的模型终结点部署和可伸缩性。
旧式 MLflow 模型服务允许你将模型注册表中的机器学习模型作为 REST 终结点(它们基于模型版本的可用性和阶段自动更新)托管。 它使用单节点群集,当前该群集在称为经典计算平面的帐户下运行。 此计算平面包括虚拟网络及其关联的计算资源,例如笔记本和作业的群集、专业 SQL 仓库和经典 SQL 仓库以及旧版模型服务终结点。
为给定的已注册模型启用模型服务时,Azure Databricks 会自动为该模型创建唯一的群集,并在该群集上部署该模型的所有未存档版本。 如果出现错误,Azure Databricks 会重启群集,并在你为模型禁用模型服务的情况下终止群集。 模型服务自动与模型注册表同步,并部署任何新的已注册模型版本。 可以通过标准 REST API 请求查询已部署的模型版本。 Azure Databricks 使用其标准身份验证对针对模型的请求进行身份验证。
当此服务为预览版时,Databricks 建议将其用于低吞吐量和非关键应用程序。 目标吞吐量为 200 qps,目标可用性为 99.5%,但任何一个都不保证能达到。 此外,有效负载大小限制为每个请求 16 MB。
每个模型版本都使用 MLflow 模型部署进行部署,并在其依赖项指定的 Conda 环境中运行。
注意
- 只要启用了服务,就会维护群集,即使不存在任何活动的模型版本。 若要终止服务群集,请为已注册的模型禁用模型服务。
- 该群集被视为通用群集,按通用工作负载定价。
- 全局 init 脚本不是在为群集提供服务的模型上运行的。
重要
Anaconda Inc. 为 anaconda.org 通道更新了其服务条款。 根据新的服务条款,如果依赖 Anaconda 的打包和分发,则可能需要商业许可证。 有关详细信息,请参阅 Anaconda Commercial Edition 常见问题解答。 对任何 Anaconda 通道的使用都受其服务条款的约束。
在 v1.18(Databricks Runtime 8.3 ML 或更低版本)之前记录的 MLflow 模型默认以 conda defaults 通道 (https://repo.anaconda.com/pkgs/) 作为依赖项进行记录。 由于此许可证更改,Databricks 已停止对使用 MLflow v1.18 及更高版本记录的模型使用 defaults 通道。 记录的默认通道现在为 conda-forge,它指向社区管理的 https://conda-forge.org/。
如果在 MLflow v1.18 之前记录了一个模型,但没有从模型的 conda 环境中排除 defaults 通道,则该模型可能依赖于你可能没有预期到的 defaults 通道。
若要手动确认模型是否具有此依赖项,可以检查与记录的模型一起打包的 channel 文件中的 conda.yaml 值。 例如,具有 conda.yaml 通道依赖项的模型 defaults 可能如下所示:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
由于 Databricks 无法确定是否允许你根据你与 Anaconda 的关系使用 Anaconda 存储库来与模型交互,因此 Databricks 不会强制要求其客户进行任何更改。 如果允许你根据 Anaconda 的条款通过 Databricks 使用 Anaconda.com 存储库,则你不需要采取任何措施。
若要更改模型环境中使用的通道,可以使用新的 conda.yaml 将模型重新注册到模型注册表。 为此,可以在 conda_env 的 log_model() 参数中指定该通道。
有关 log_model() API 的详细信息,请参阅所用模型风格的 MLflow 文档,例如用于 scikit-learn 的 log_model。
有关 conda.yaml 文件的详细信息,请参阅 MLflow 文档。
要求
模型注册表中的模型服务
可以在 Azure Databricks 中通过模型注册表使用模型服务。
启用和禁用模型服务
可以从已注册模型页为模型启用服务。
单击“服务”选项卡。如果尚未为模型启用服务,则会显示“启用服务”按钮。
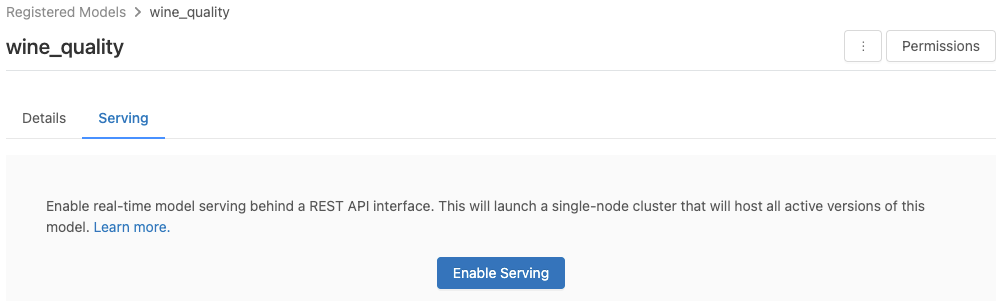
单击“启用服务”。 将显示“服务”选项卡,其中的“状态”为“挂起”。 几分钟后,“状态”更改为“就绪”。
若要为模型禁用服务,请单击“停止”。
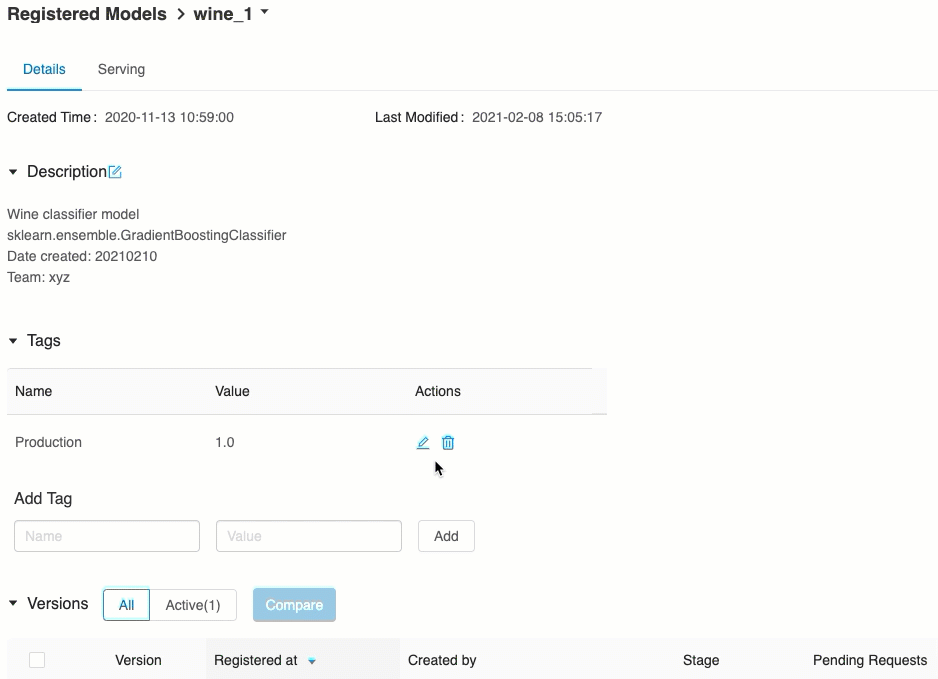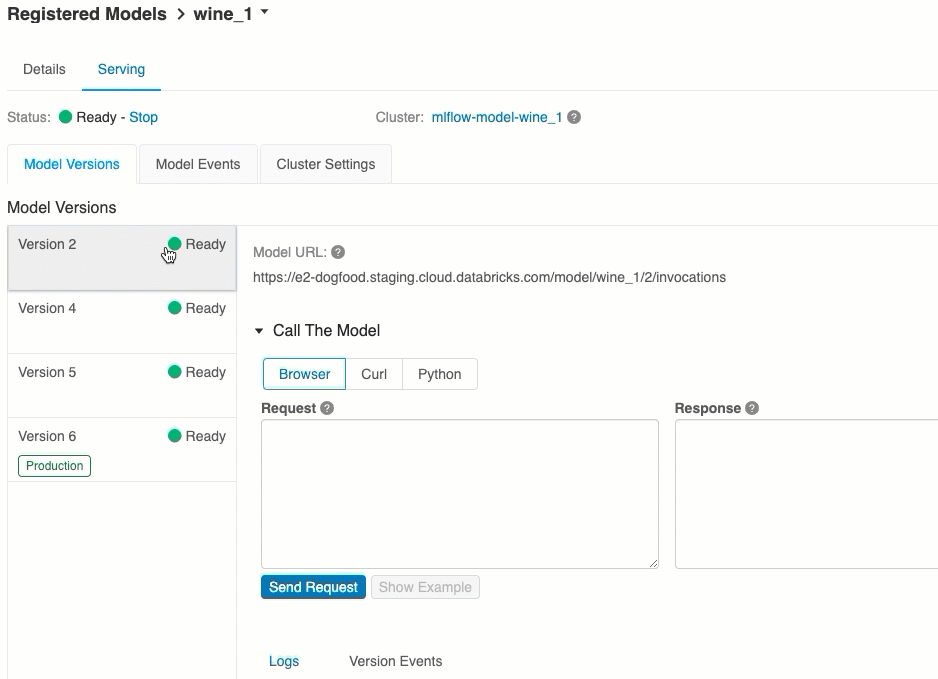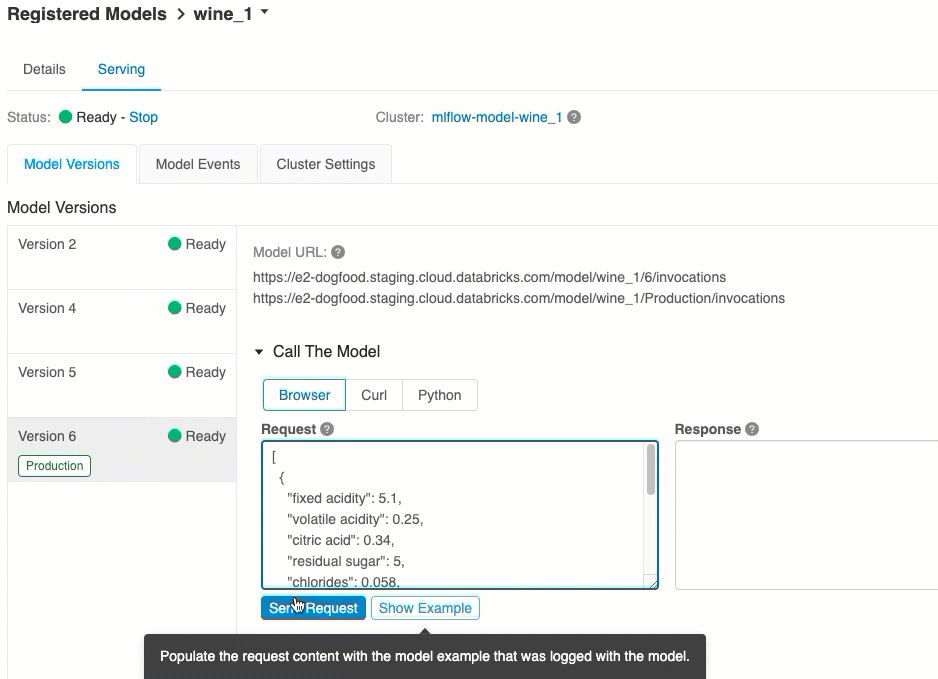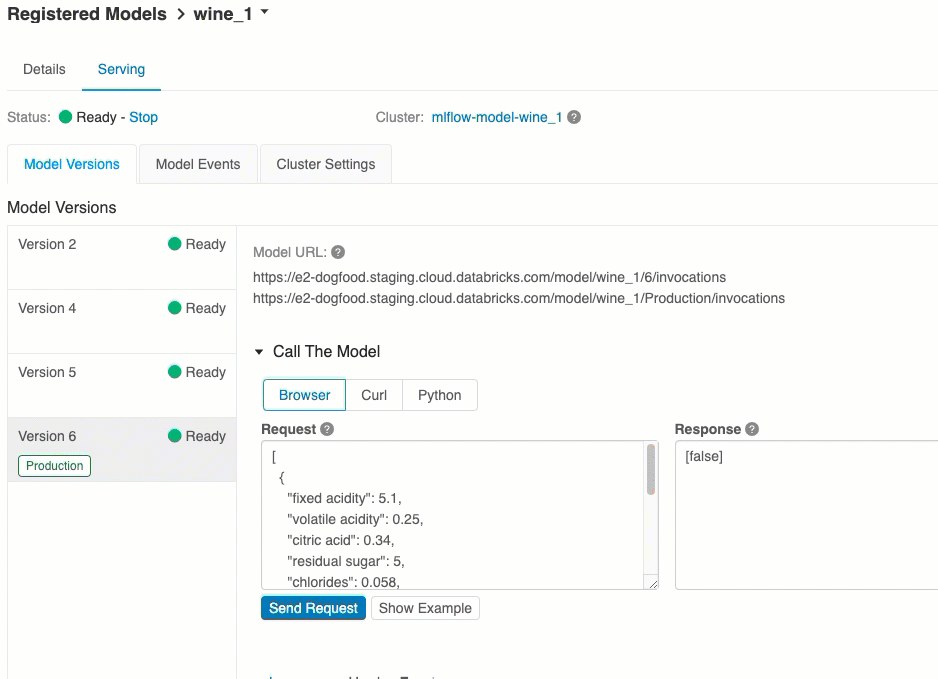
验证模型服务
在“服务”选项卡中,可将请求发送到所服务的模型并查看响应。
模型版本 URI
每个已部署的模型版本都分配有一个或多个唯一 URI。 每个模型版本至少分配有一个如下构造的 URI:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
例如,若要调用注册为 iris-classifier 的模型的版本 1,请使用以下 URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
还可以通过模型版本的阶段来调用模型版本。 例如,如果版本 1 处于“生产”阶段,则还可以使用以下 URI 对其进行评分:
https://<databricks-instance>/model/iris-classifier/Production/invocations
可用模型 URI 的列表显示在服务页上的“模型版本”选项卡的顶部。
管理所服务的版本
所有活动的(未存档的)模型版本都会部署,你可以使用 URI 查询它们。 Azure Databricks 在新的模型版本注册时自动部署新版本,并在旧版本存档时自动删除旧版本。
注意
已注册模型的所有已部署版本共享同一群集。
管理模型访问权限
模型访问权限从模型注册表继承而来。 启用或禁用服务功能需要对已注册的模型拥有“管理”权限。 具有读取权限的任何人都可以对任何已部署的版本进行评分。
对已部署的模型版本进行评分
若要对已部署的模型进行评分,可以使用 UI 或将 REST API 请求发送到模型 URI。
通过 UI 进行评分
这是用来测试模型的最简单且最快速的方法。 你可以插入 JSON 格式的模型输入数据,并单击“发送请求”。 如果已使用输入示例记录了模型(如上图所示),请单击“加载示例”来加载输入示例。
通过 REST API 请求进行评分
你可以使用标准 Databricks 身份验证通过 REST API 发送评分请求。 以下示例演示如何通过 MLflow 1.x 使用个人访问令牌进行身份验证。
注意
作为安全最佳做法,在使用自动化工具、系统、脚本和应用进行身份验证时,Databricks 建议使用属于服务主体(而不是工作区用户)的个人访问令牌。 若要为服务主体创建令牌,请参阅管理服务主体的令牌。
对于给定的 MODEL_VERSION_URI(例如 https://<databricks-instance>/model/iris-classifier/Production/invocations,其中的 <databricks-instance> 是你的 Databricks 实例的名称)和名为 DATABRICKS_API_TOKEN 的 Databricks REST API 令牌,以下示例说明了如何查询所服务的模型:
以下示例反映了使用 MLflow 1.x 创建的模型的评分格式。 如果你偏好使用 MLflow 2.0,则需要更新请求有效负载格式。
Bash
用于查询接受数据帧输入的模型的代码片段。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
用于查询接受张量输入的模型的代码片段。 应该根据 TensorFlow 服务的 API 文档中所述设置张量输入的格式。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
PowerBI
可以使用以下步骤在 Power BI Desktop 中为数据集评分:
打开要评分的数据集。
转到“转换数据”。
右键单击左侧面板,然后选择“创建新查询”。
转到“视图>高级编辑器”。
填写适当的
DATABRICKS_API_TOKEN和MODEL_VERSION_URI后,将查询主体替换为下面的代码片段。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction将查询命名为所需的模型名称。
打开你的数据集的高级查询编辑器,并应用模型函数。
监视所服务的模型
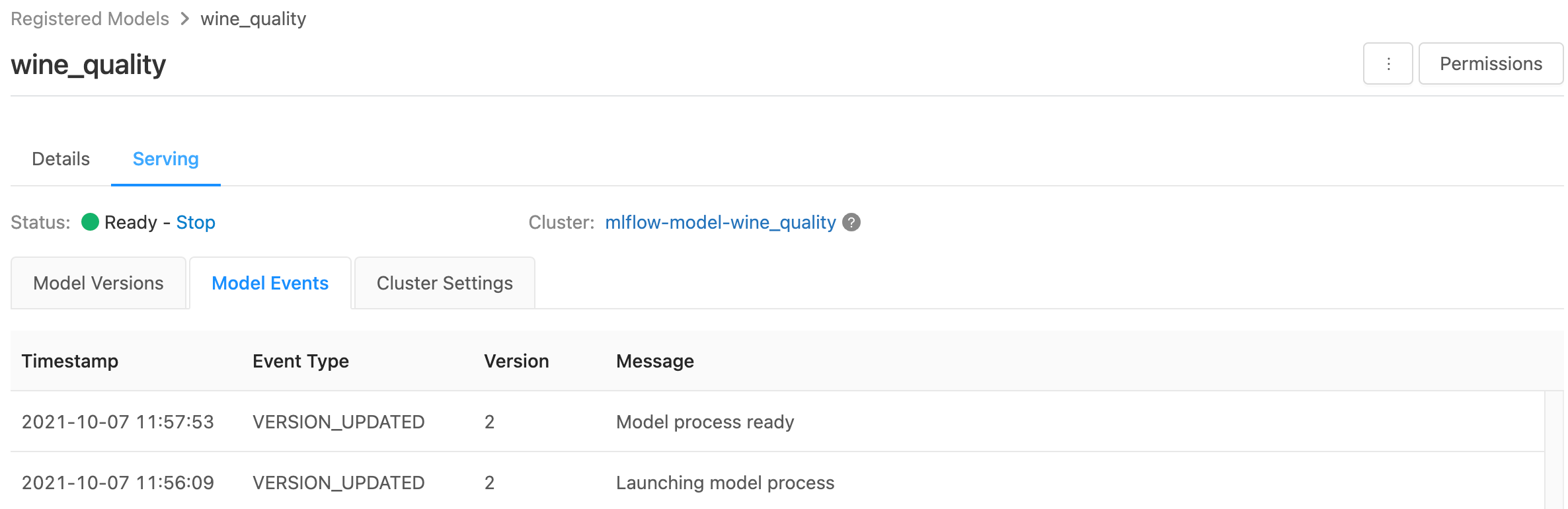
服务页显示服务群集的状态指示器以及各个模型版本。
- 若要检查服务群集的状态,请使用“模型事件”选项卡,其中显示了此模型的所有服务事件的列表。
- 若要检查单个模型版本的状态,请单击“模型版本”选项卡,然后滚动以查看“日志”或“版本事件”项卡 选。
自定义服务群集
若要自定义服务群集,请使用“服务”选项卡上的“群集设置”选项卡 。
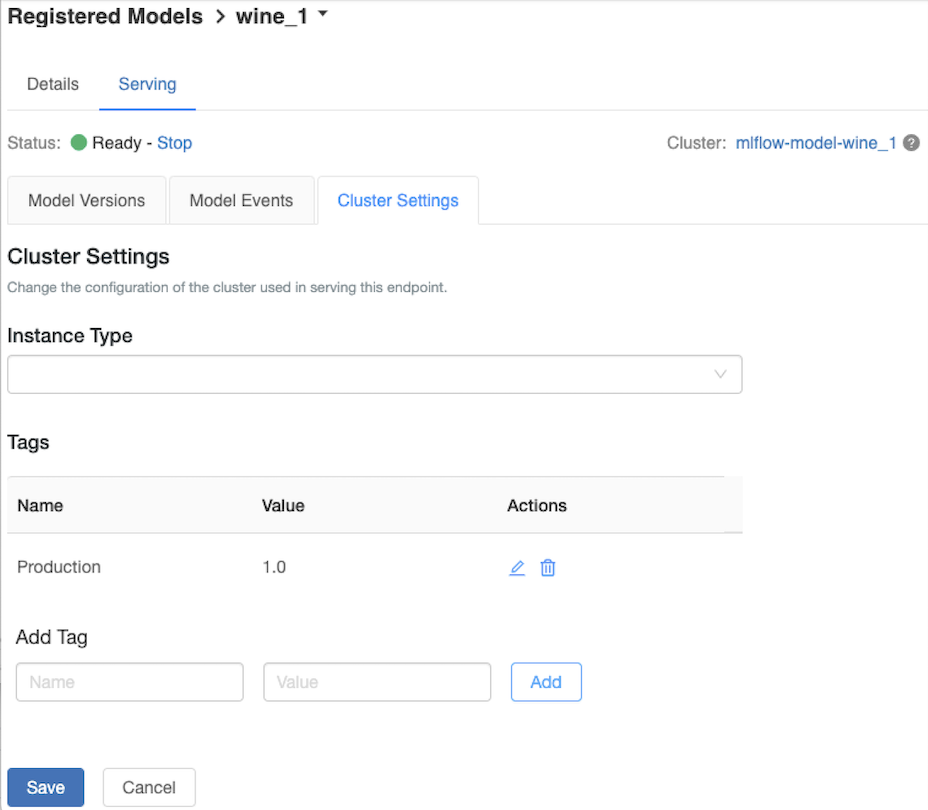
- 若要修改服务群集的内存大小和核心数,请使用“实例类型”下拉菜单选择所需的群集配置。 单击“保存”时,将终止现有群集并使用指定的设置创建新群集。
- 若要添加标记,请在“添加标记”字段中键入名称和值,然后单击“添加” 。
- 若要编辑或删除现有标记,请单击“标记”表的“操作”列中的相应图标 。
特征存储集成
旧式模型服务可以自动在已发布的联机存储中查找特征值。
Databricks 旧版 MLflow 模型服务支持从以下联机存储中查找特征:
- Azure Cosmos DB(v0.5.0 及更高版本)
- Azure Database for MySQL
已知错误
ResolvePackageNotFound: pyspark=3.1.0
如果模型依赖于 pyspark 并且是使用 Databricks Runtime 8.x 记录的,则可能会发生此错误。
如果看到此错误,请在记录模型时使用 pyspark显式指定 pyspark 版本。
Unrecognized content type parameters: format
新的 MLflow 2.0 评分协议格式可能会导致此错误。 如果看到此错误,你可能使用了过时的评分请求格式。 若要解决该错误,可以执行以下操作:
将评分请求格式更新为最新协议。
注意
以下示例反映了 MLflow 2.0 中引入的评分格式。 如果首选使用 MLflow 1.x,则可以修改
log_model()API 调用,以在extra_pip_requirements参数中包含所需的 MLflow 版本依赖项。 这样做可确保使用适当的评分格式。mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
查询接受 pandas 数据帧输入的模型。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'查询接受张量输入的模型。 应该根据 TensorFlow 服务的 API 文档中所述设置张量输入的格式。
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)PowerBI
可以使用以下步骤在 Power BI Desktop 中为数据集评分:
打开要评分的数据集。
转到“转换数据”。
右键单击左侧面板,然后选择“创建新查询”。
转到“视图>高级编辑器”。
填写适当的
DATABRICKS_API_TOKEN和MODEL_VERSION_URI后,将查询主体替换为下面的代码片段。(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPrediction将查询命名为所需的模型名称。
打开你的数据集的高级查询编辑器,并应用模型函数。
如果评分请求使用 MLflow 客户端(如
mlflow.pyfunc.spark_udf()),请将 MLflow 客户端升级到版本 2.0 或更高版本,以使用最新格式。 详细了解 MLflow 2.0 中更新的 MLflow 模型评分协议。
若要详细了解服务器接受的输入数据格式(例如,面向 pandas 拆分的格式),请参阅 MLflow 文档。