HDInsight 群集包括 Azure Monitor 日志集成,它提供可查询的指标和日志,以及可配置的警报。 本文介绍如何使用 Azure Monitor 来监视群集。
Azure Monitor 日志集成
使用 Azure Monitor 日志可在一个位置收集与聚合多个资源(例如 HDInsight 群集)生成的数据,以实现统一监视体验。
作为先决条件,需要创建一个 Log Analytics 工作区来存储收集的数据。 如果尚未创建,可以按照以下说明作: 创建 Log Analytics 工作区。
启用 HDInsight Azure Monitor 日志集成
在门户上的 HDInsight 群集资源页中,选择“Azure Monitor”。 然后选择“启用”并从下拉列表中选择你的 Log Analytics 工作区。
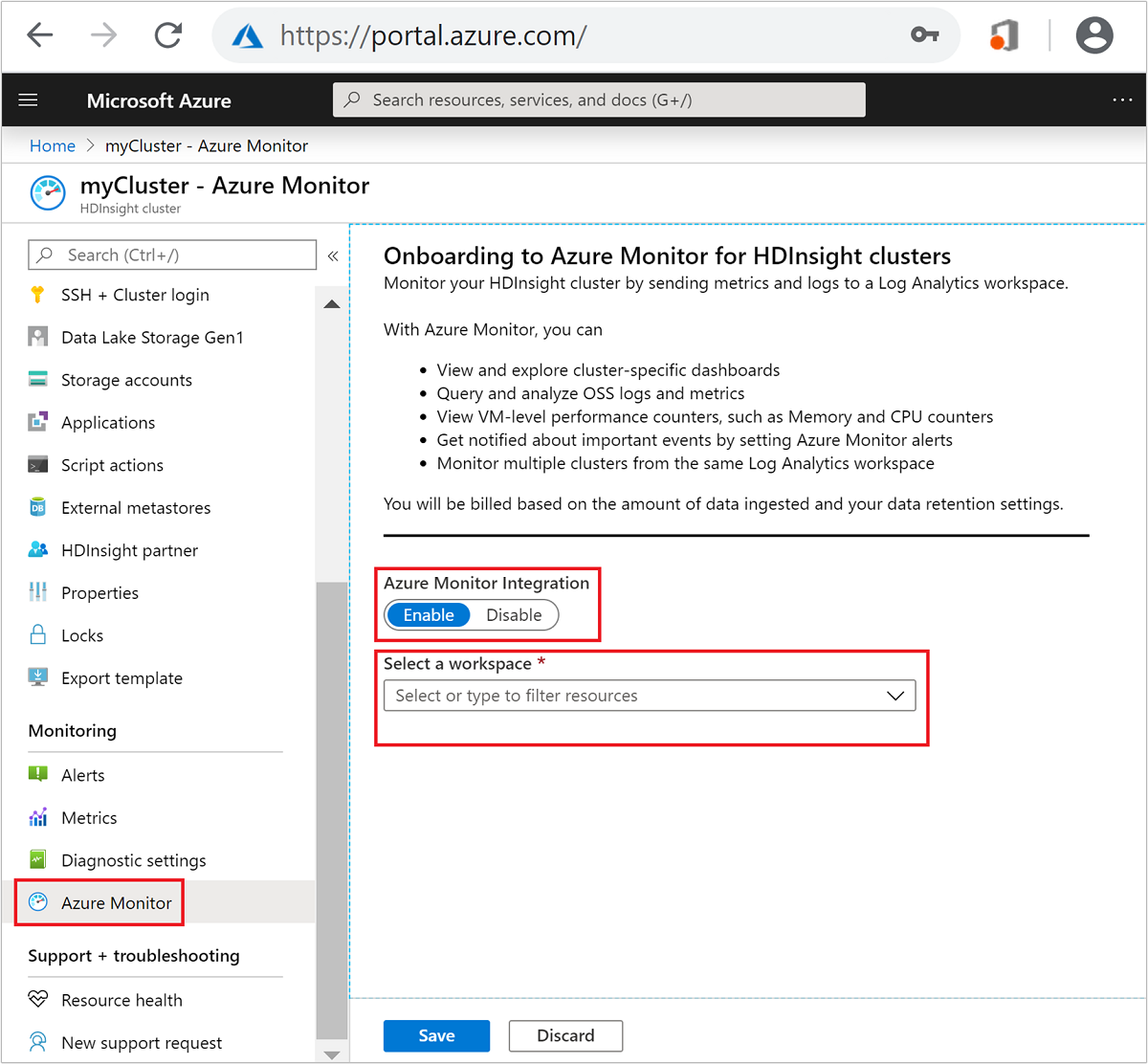
默认情况下,这会将 OMS 代理安装在除边缘节点外的所有群集节点上。 由于群集边缘节点上未安装 OMS 代理,因此默认情况下,Log Analytics 中没有关于边缘节点的遥测数据。
查询指标和日志表
启用 Azure Monitor 日志集成后(这可能需要几分钟时间),导航到“Log Analytics 工作区”资源并选择“日志”。
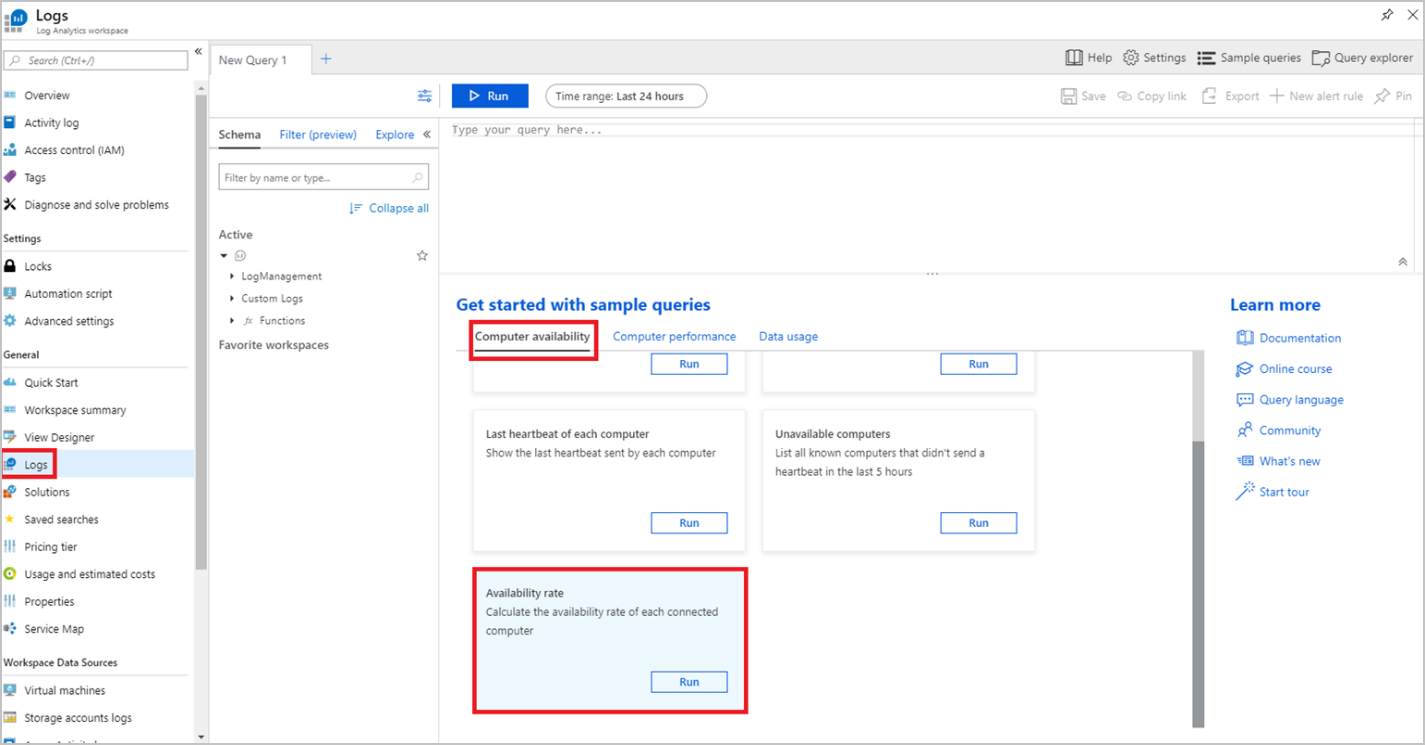
日志列出了多个示例查询,例如:
| 查询名称 | DESCRIPTION |
|---|---|
| 目前的计算机可用性 | 绘制图表展示每小时发送日志的计算机数量 |
| 列出检测信号 | 列出过去一小时的所有计算机检测信号 |
| 每台计算机的最后一次心跳 | 显示每台计算机发送的最新心跳信号 |
| 不可用的计算机 | 显示过去5小时未发送心跳信号的所有已知电脑 |
| 可用率 | 计算每台已连接计算机的可用率 |
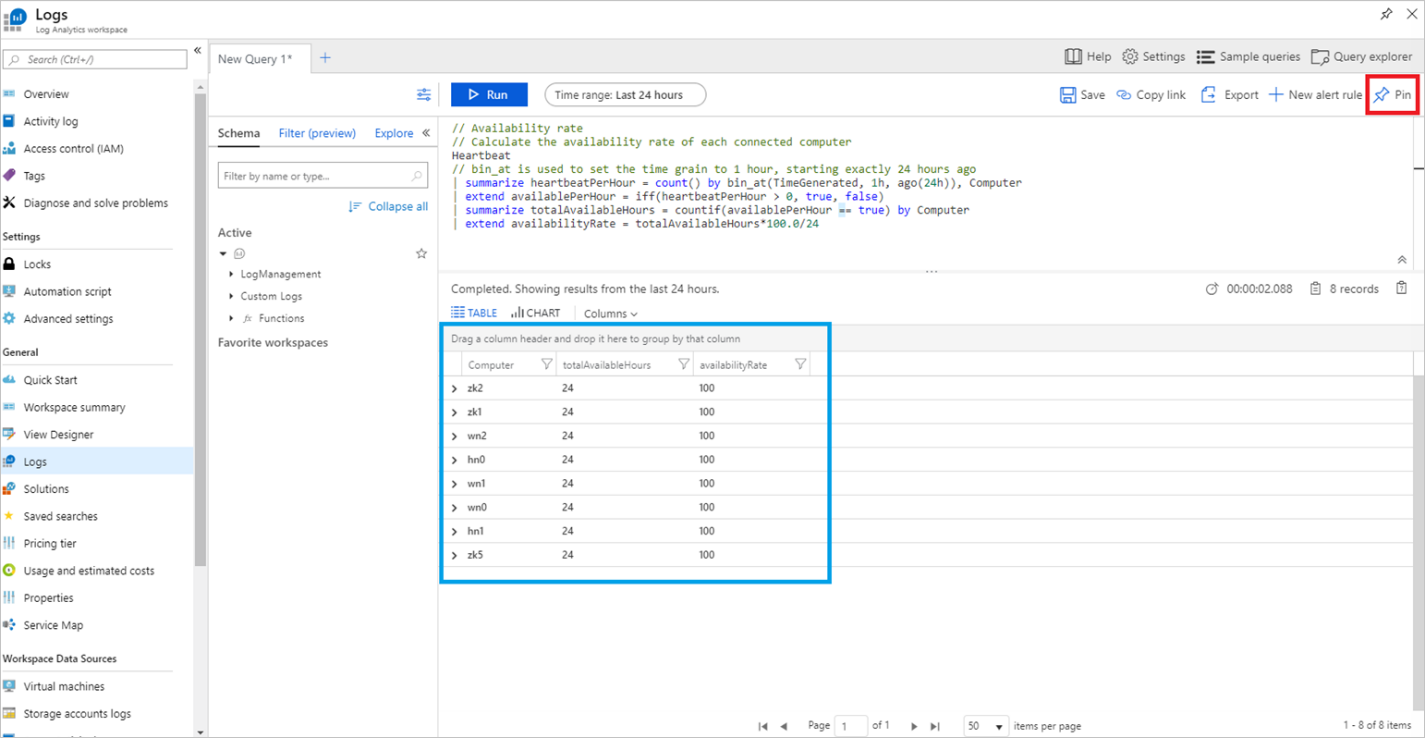
例如,选择该查询对应的“运行”以运行“可用率”示例查询,如以上屏幕截图中所示。 这会以百分比显示群集中每个节点的可用率。 如果启用了多个 HDInsight 群集以将指标发送到相同的 Log Analytics 工作区,则会显示这些群集中所有节点(不包括边缘节点)的可用率。
注释
可用率是按 24 小时期限测量的,因此,群集至少需要运行 24 小时才能显示准确的可用率。
您可以通过单击右上角的“固定”按钮,将此表固定在共享仪表板上。 如果没有可写的共享仪表板,可在此处了解如何创建 仪表板:在 Azure 门户中创建和共享仪表板。
Azure Monitor 警报
还可以设置当某个指标的值或某个查询的结果符合特定条件时要触发的 Azure Monitor 警报。 例如,让我们创建一个警报,以便在一个或多个节点在 5 小时内未发送检测信号时(即,假设这些节点不可用)发送电子邮件。
在“日志”中,选择该查询对应的“运行”以运行“不可用的计算机”示例查询,如下所示。
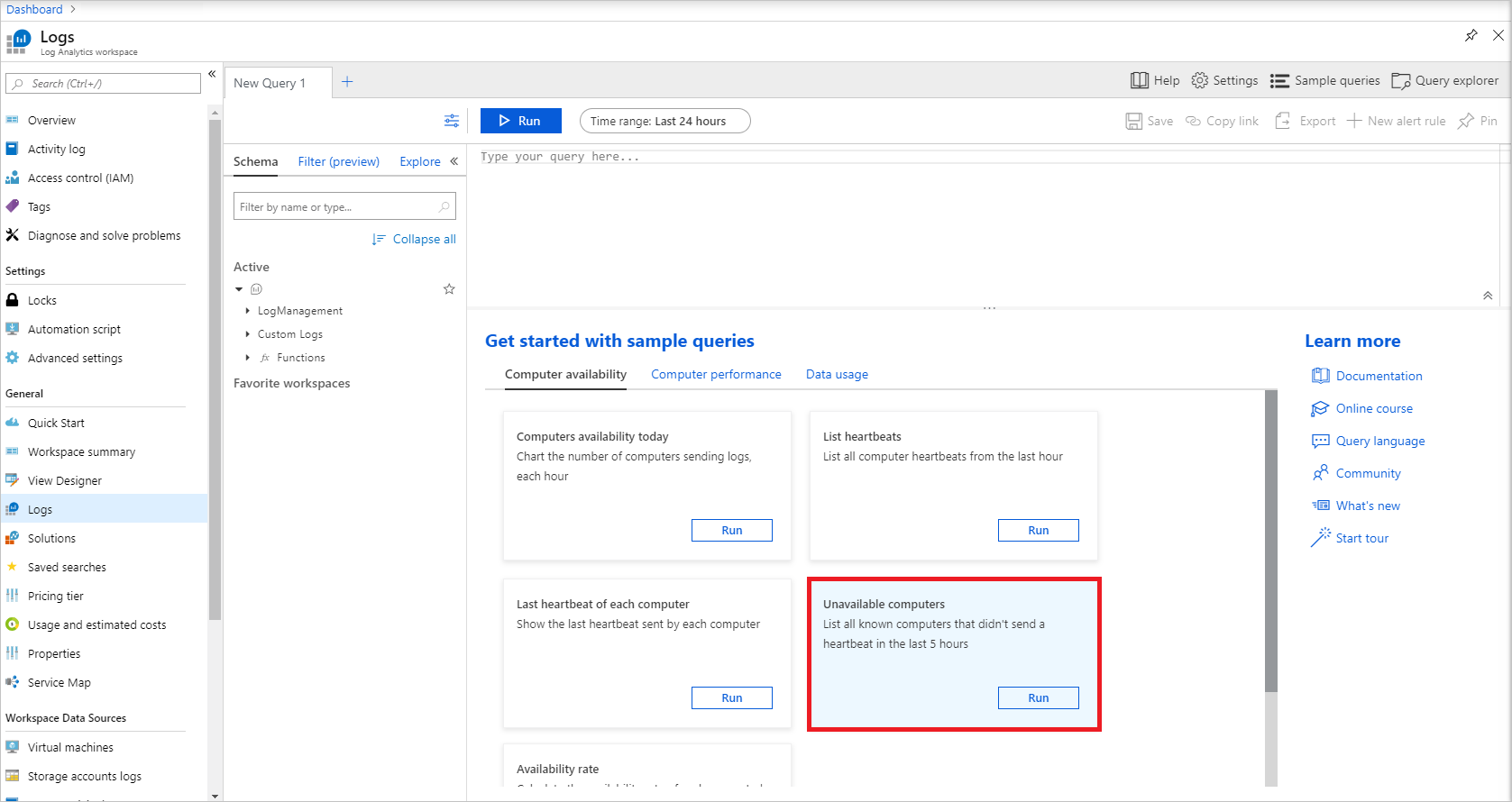
如果所有节点可用,此查询应返回零个结果。 单击“新建警报规则”以开始为此查询配置警报。
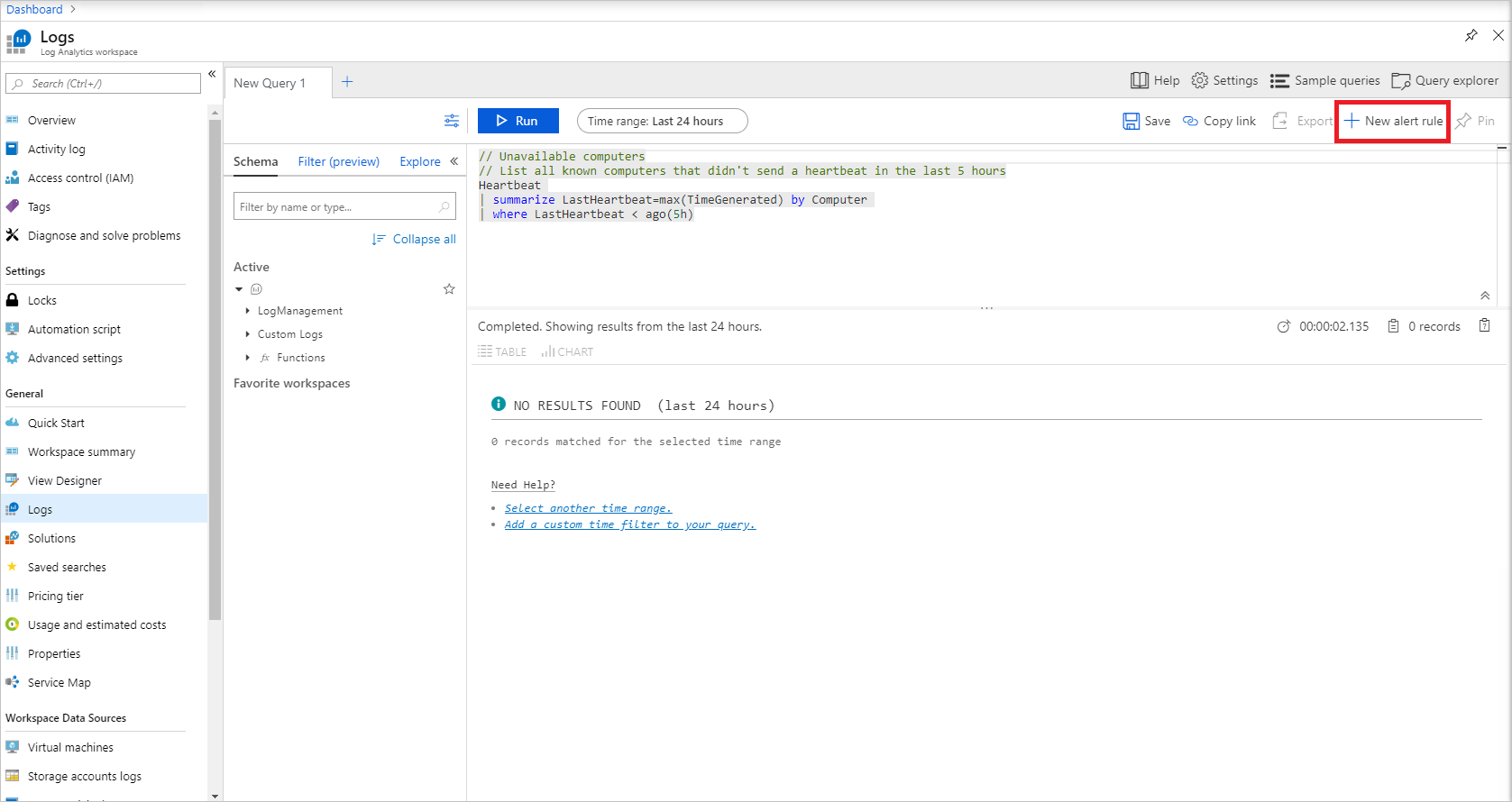
警报有三个组成部分:资源(在本例中为 Log Analytics 工作区),用于创建规则;触发警报的条件;以及确定警报触发后发生操作的操作组。 单击 条件标题,如下所示,完成信号逻辑配置。
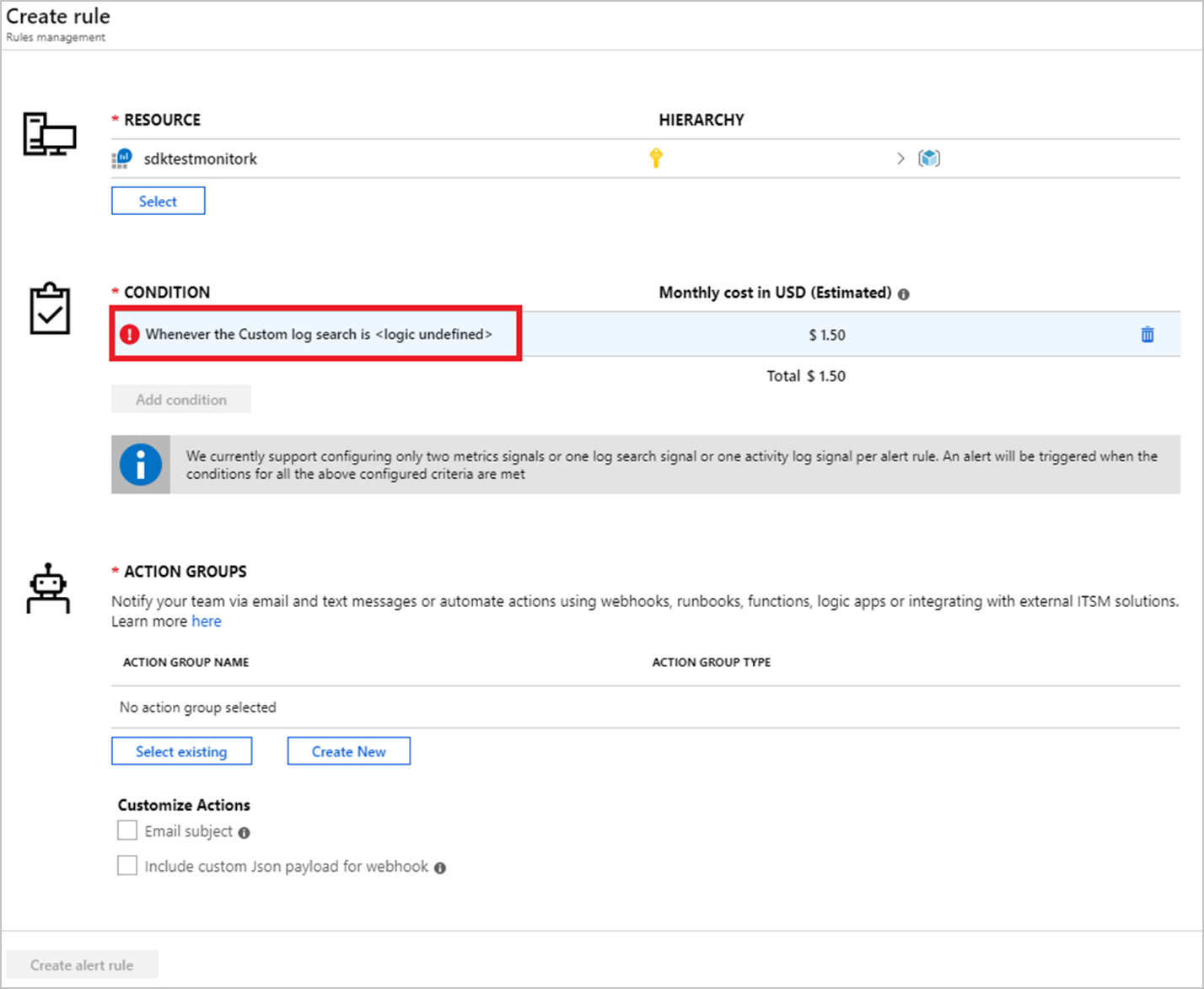
此时会打开“配置信号逻辑”。
将“警报逻辑”部分设置为如下内容:
依据:结果数量,条件:大于,阈值:0。
由于此查询只返回不可用的节点作为结果,如果结果数大于 0,应会激发警报。
在“计算依据”部分设置“时段”,并根据检查不可用节点的频率设置“频率”。
出于此警报的目的,需要确保 Period=Frequency。 有关时段、频率和其他警报参数的详细信息,可 在此处找到。
完成信号逻辑配置后,选择“完成”。
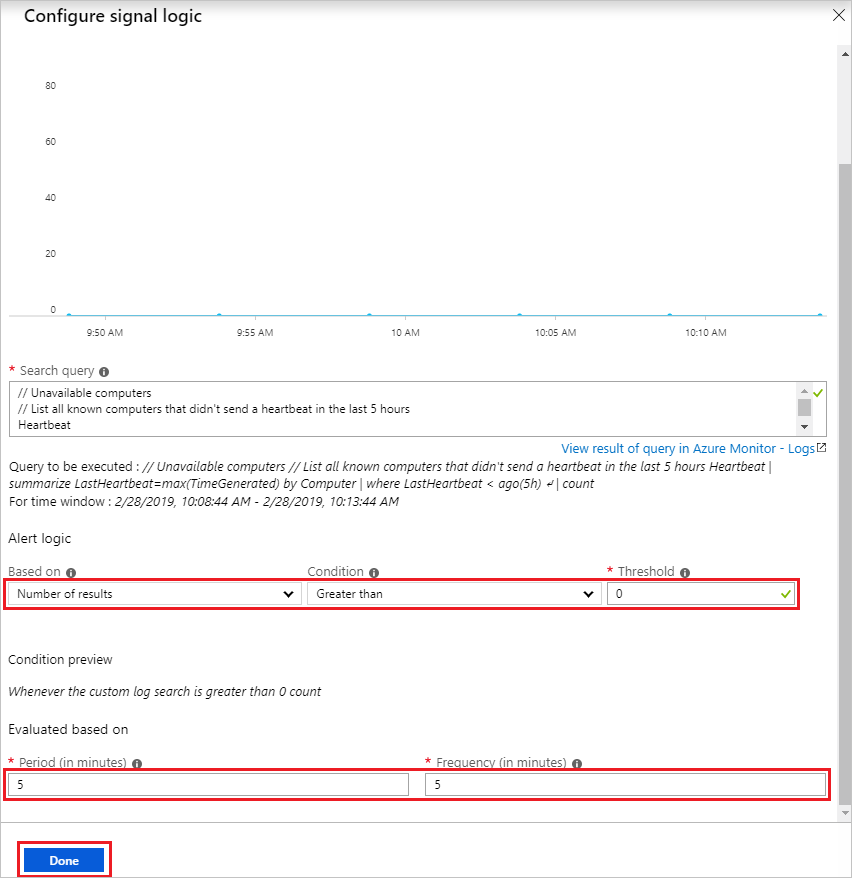
如果您还没有现有的操作组,请在“操作组”部分下单击“新建”。
此时会打开“添加操作组”。 选择“操作组名称”、“短名称”、“订阅”和“资源组”。在“操作”部分下,选择“操作名称”并选择“电子邮件/短信/推送/语音”作为“操作类型”。
注释
除了“电子邮件/短信/推送/语音”以外,警报还可以触发其他几个操作,例如 Azure 函数、逻辑应用、Webhook、ITSM 和自动化 Runbook。 了解更多信息。
此时会打开“电子邮件/短信/推送/语音”。 选择收件人的姓名,选中“电子邮件”框,然后键入要将警报发送到的电子邮件地址。 在“电子邮件/短信/推送/语音”中选择“确定”,然后在“添加操作组”中完成操作组的配置。
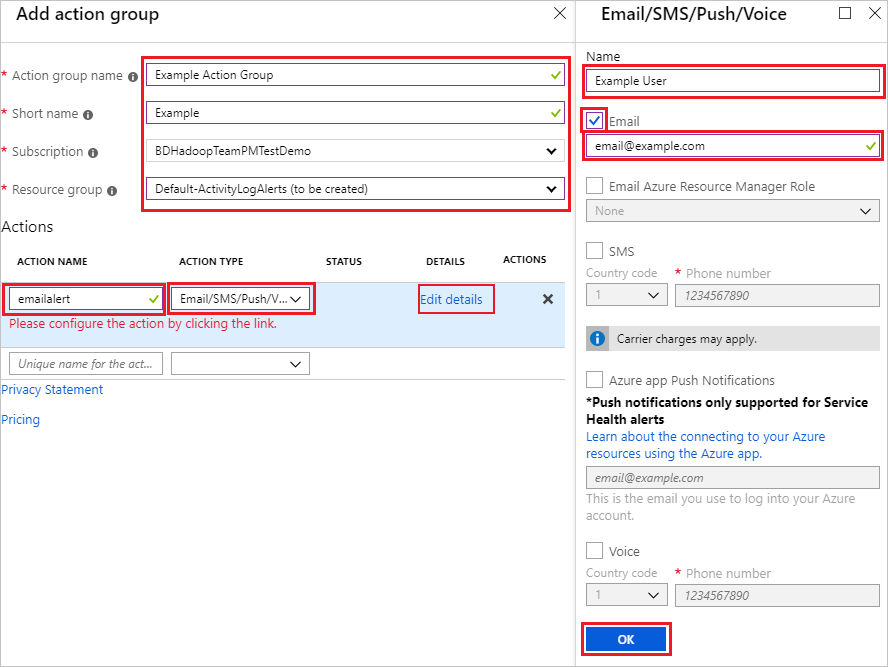
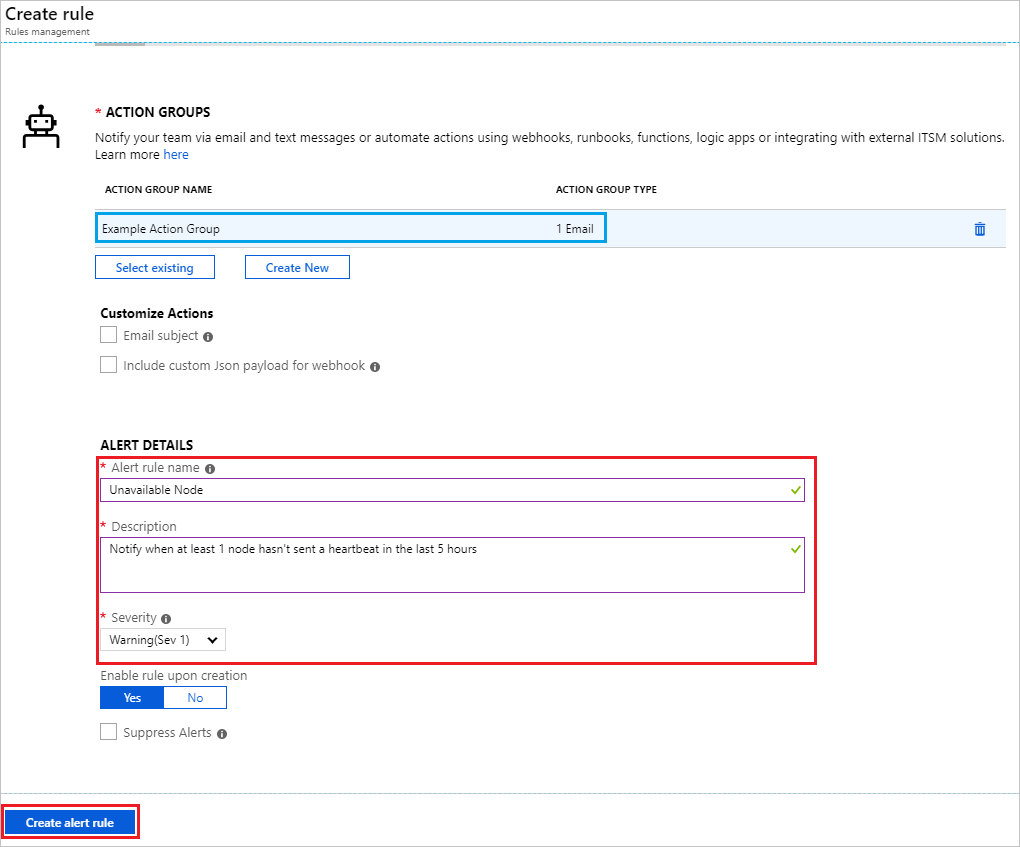
关闭这些边栏选项卡后,应会看到你的操作组已列在“操作组”部分下。 最后,键入警报规则名称和说明并选择严重性,完成“警报详细信息”部分。 单击“创建警报规则”以完成操作。
小窍门
指定“严重性”是一个强大的功能,可在创建多个警报时使用它。 例如,可以创建一个警报以便在一个头节点出现故障时引发“警告”警报(严重性 1),并创建另一个警报以便在两个头节点同时出现故障时(这种情况很少见)引发“严重”警报(严重性 1)。
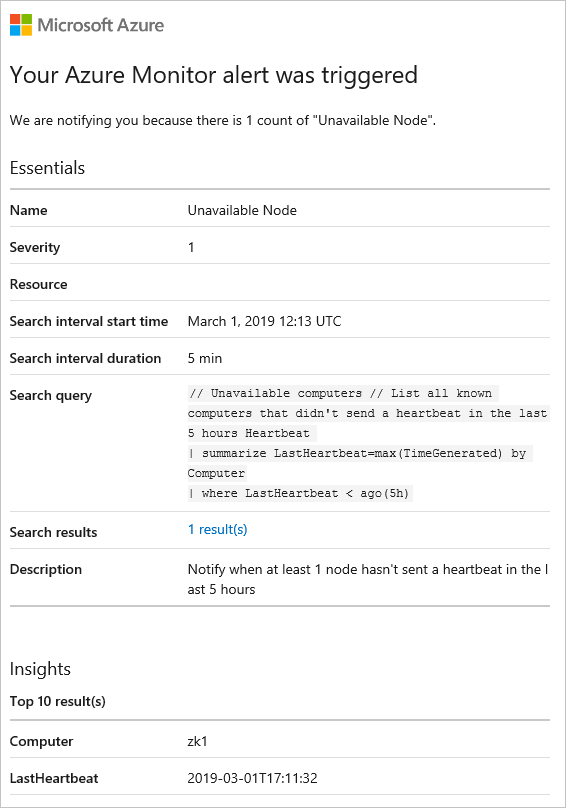
如果符合此警报的条件,则会激发该警报,你会收到一封电子邮件,其中包含如下所示的警报详细信息:
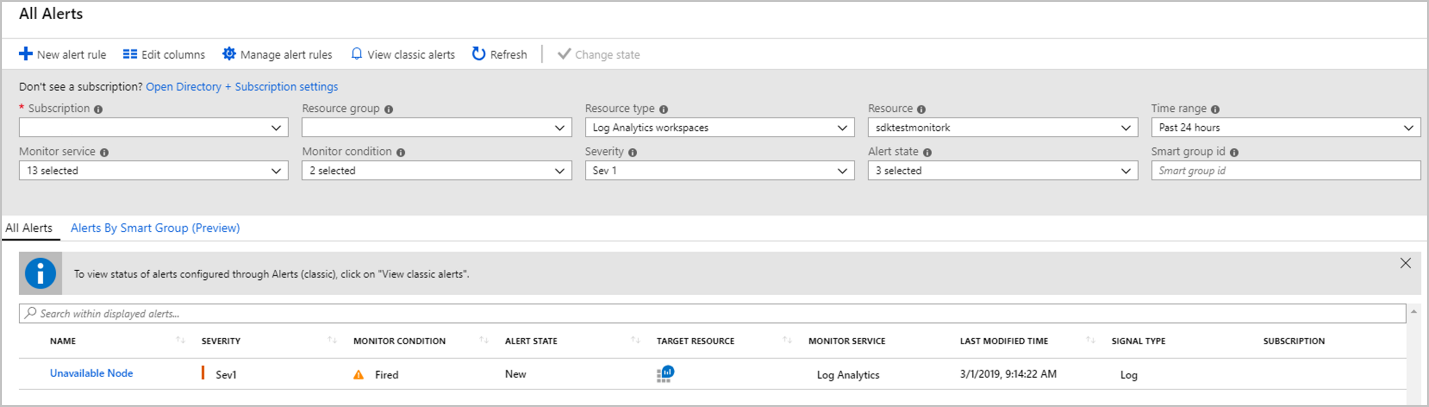
还可以转到“Log Analytics 工作区”中的“警报”,查看所有已激发的警报(按严重性分组)。
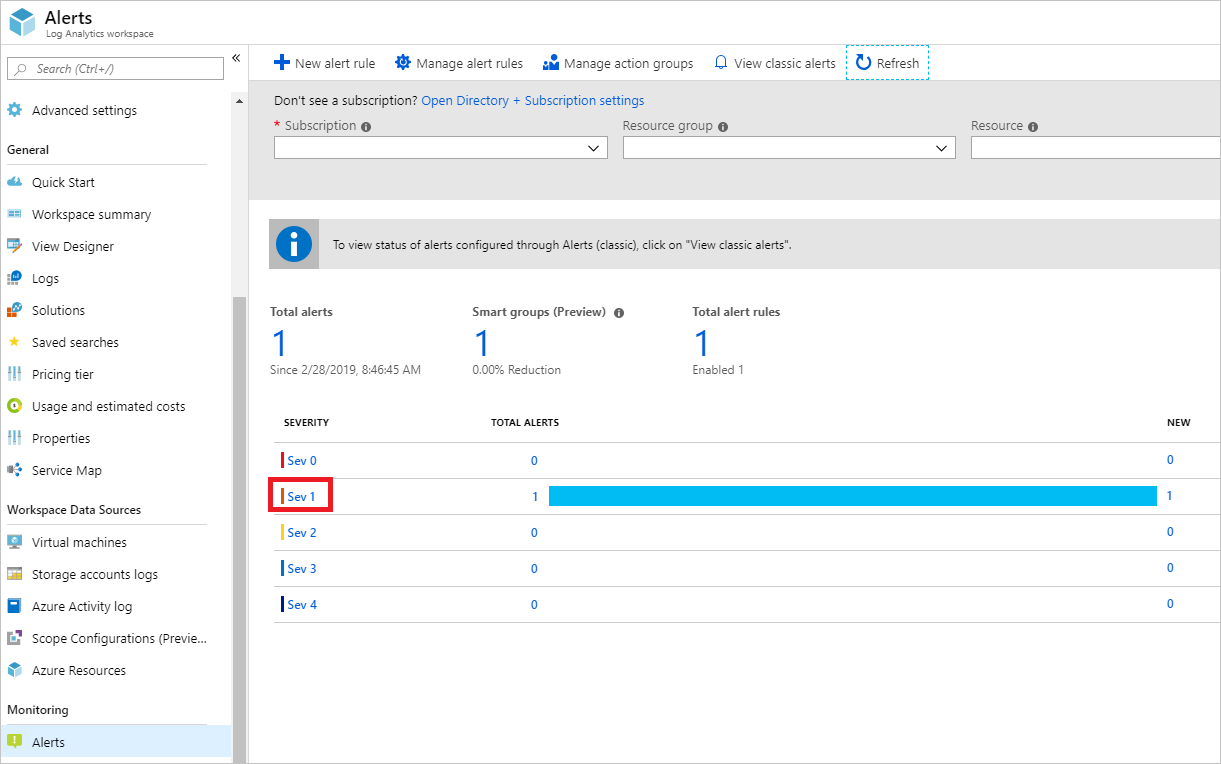
在选择某个严重性分组时(例如,上图中突出显示的“严重性 1”),会显示具有该严重性的所有已激发警报的记录,如下所示:
后续步骤
- 群集可用性 - Apache Ambari