监视 HDInsight 群集的运行状况和性能对于维持最佳性能和资源利用率来说至关重要。 监视还可以帮助你检测并解决群集配置错误和用户代码问题。
以下各部分介绍了如何监视和优化群集上的负载、Apache Hadoop YARN 队列,以及检测存储限制问题。
监视群集负载
当群集上的负载均匀分布在所有节点中时,Hadoop 群集可以提供最佳性能。 这使得处理任务在运行时可以不受个体节点上的 RAM、CPU 或磁盘资源约束。
若要概括地查看群集的节点及其负载,请登录到 Ambari Web UI,然后选择“主机”选项卡。将按主机完全限定域名列出主机。 每个主机的运行状态由一个彩色运行状况指示器进行显示:
| 颜色 | 说明 |
|---|---|
| 红色 | 主机上至少有一个主组件已关闭。 悬停鼠标以查看列出受影响组件的工具提示。 |
| 橙色 | 主机上至少有一个辅助组件已关闭。 悬停鼠标以查看列出受影响组件的工具提示。 |
| 黄色 | Ambari 服务器已超过 3 分钟没有接收到来自主机的检测信号。 |
| 绿色 | 正常运行状态。 |
此外还将看到列,显示每个主机的内核数及 RAM 量、磁盘使用情况和平均负载。
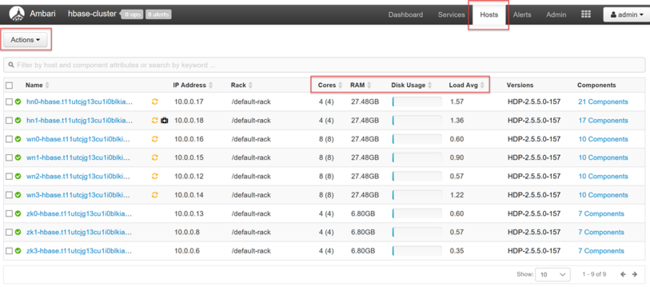
选择任意主机名,详细了解在该主机上运行的组件及其指标。 查看 CPU 使用情况、负载、磁盘使用情况、内存使用情况、网络使用情况和进程数的可选时间线,了解这些指标。
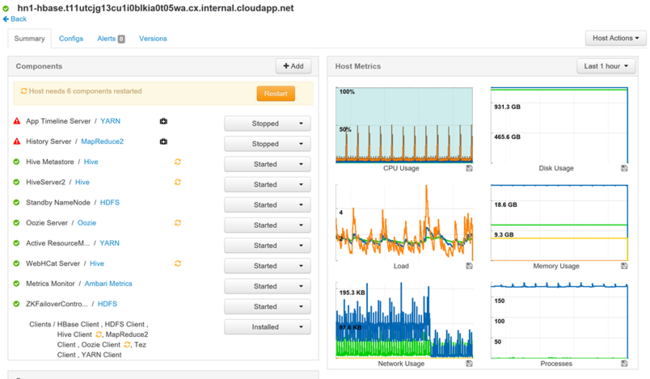
有关设置警报和查看指标的详细信息,请参阅使用 Apache Ambari Web UI 管理 HDInsight 群集。
YARN 队列配置
Hadoop 跨其分布式平台运行各种服务。 YARN (Yet Another Resource Negotiator) 协调这些服务并分配群集资源以确保任何负载都均匀地分布在群集中。
YARN 将 JobTracker、资源管理和作业计划/监视的两种责任划分为两个守护程序:一个全局资源管理器和一个每应用程序 ApplicationMaster (AM)。
资源管理器是一个纯计划程序,且仅仲裁所有竞争应用程序之间的可用资源。 资源管理器确保所有资源都处于使用状态,并针对各种常量(如 SLA、容量保障等)进行优化。 ApplicationMaster 处理来自于 ResourceManager 的资源,并与 NodeManager 一起执行和监视容器及其资源消耗。
如果多个租户共享一个大型群集,则产生针对群集资源的竞争。 CapacityScheduler 是一种可插入计划程序,通过对请求进行排队来协助资源共享。 CapacityScheduler 还支持分层队列,确保在允许其他应用程序的队列使用可用资源之前,在组织的子队列之间共享资源。
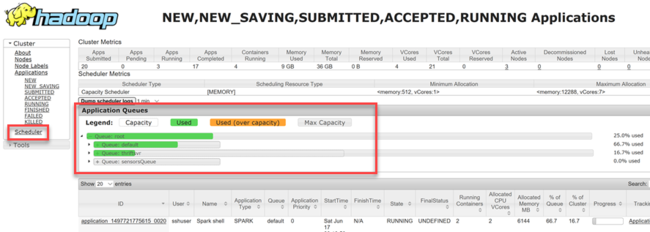
YARN 允许我们将资源分配给这些队列,并显示是否已分配所有可用资源。 若要查看有关队列的信息,请登录到 Ambari Web UI,然后从顶部菜单选择“YARN 队列管理器”。
YARN 队列管理器页的左侧显示队列的列表,以及分配给每个队列的容量百分比。
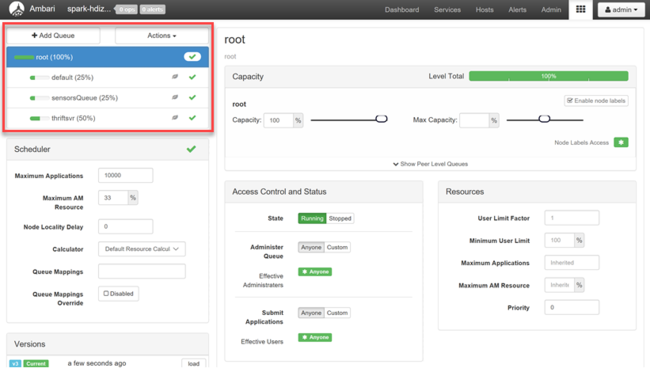
若要更加详细地查看队列,在 Ambari 仪表板中,从左侧列表选择“YARN”服务。 然后,在“快速链接”下拉菜单下,选择活动节点下的“资源管理器 UI”。

在资源管理器 UI 中,从左侧菜单中选择“计划程序”。 “应用程序队列”下将显示队列的列表。 此处可看到用于每个队列的容量、作业在队列之间的分布情况,以及作业是否受资源约束。
存储限制
群集的性能瓶颈可能发生于存储级别。 这种类型的瓶颈最常见的原因是阻止了输入/输出 (IO) 操作,当正在运行的任务发送的 IO 超过存储服务可以处理的数量时,就会发生这种情况。 这种阻止将创建等待处理完当前 IO 后再进行处理的 IO 请求队列。 这些阻止是因为存储限制,这不是物理限制,而是存储服务通过服务级别协议 (SLA) 施加的限制。 此限制确保单个客户端或租户无法独占服务。 SLA 会限制 Azure 存储的每秒 IO 数 (IOPS) - 有关详细信息,请参阅标准存储帐户的可伸缩性和性能目标。
如果使用 Azure 存储,有关监视与存储相关问题(包括限制)的信息,请参阅监视、诊断和排查 Azure 存储问题。
排查节点性能缓慢问题
在某些情况下,响应迟缓可能是因为群集上的磁盘空间不足。 按照以下步骤进行调查:
使用 ssh 命令连接到每个节点。
通过运行以下命令之一来检查磁盘使用情况:
df -h du -h --max-depth=1 / | sort -h查看输出,并检查
mnt文件夹或其他文件夹中是否存在任何大型文件。 通常,usercache和appcache(mnt/resource/hadoop/yarn/local/usercache/hive/appcache/) 文件夹包含大型文件。如果有大型文件,则可能是当前作业导致文件增长,也可能是上一个作业失败导致此问题。 若要检查此行为是否由当前作业引起,请运行以下命令:
sudo du -h --max-depth=1 /mnt/resource/hadoop/yarn/local/usercache/hive/appcache/如果此命令指示特定作业,则可选择使用类似于以下内容的命令来终止作业:
yarn application -kill -applicationId <application_id>将
application_id替换为应用程序 ID。 如果未指示特定作业,请转到下一步。上面的命令完成后,或如果未指示任何特定作业,请运行类似如下的命令,删除确定的大型文件:
rm -rf filecache usercache
有关磁盘空间问题的详细信息,请参阅磁盘空间不足。
注意
如果有想要保留的大型文件,但其导致磁盘空间不足的问题,则需要纵向扩展 HDInsight 群集并重启服务。 完成此过程并等待几分钟后,你会注意到存储空间得到释放,节点的常规性能恢复。
后续步骤
请访问以下链接,了解有关故障排除和监视群集的详细信息: