什么是 HDInsight 的高级分析?
HDInsight 提供可从大量结构化、非结构化和快速移动的数据中获取宝贵见解的功能。 高级分析使用高度可缩放的体系结构、统计、机器学习模型和智能仪表板提供有意义的见解。 机器学习(或预测分析)使用可从数据中的关系进行识别和学习的算法进行预测,然后引导你做出决策。
高级分析过程
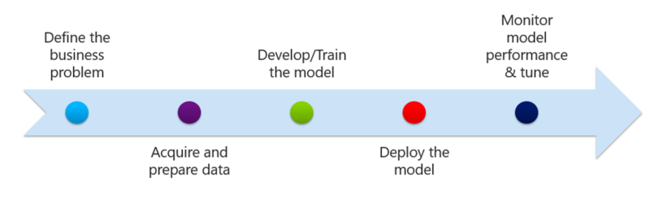
在确定业务问题并开始收集和处理数据之后,需要创建模型来表示你希望预测的问题。 你的模型将使用一种或多种机器学习算法来生成最符合业务需求的预测类型。 应将大部分数据用于训练模型,并将剩余的数据用于测试或评估该模型。
在创建、加载、测试和评估模型之后,下一步就是部署该模型,让它开始为问题提供解答。 最后一步是监视模型的性能,并根据需要进行优化。
常见算法类型
高级分析解决方案提供一套机器学习算法。 下面是算法类别和相关常见业务用例的摘要。
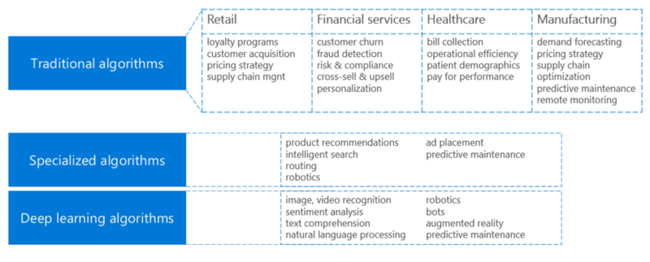
除了选择一种或多种最合适的算法以外,还需要考虑是否需要提供用于训练的数据。 机器学习算法划分为:
- 监督式 - 首先需要基于一组带有标签的数据训练算法,然后,该算法才能提供结果
- 半监督式 - 算法可以由训练者通过交互式查询以额外的目标进行补充,这些目标在初始训练阶段不可用
- 非监督式 - 算法无需训练数据
- 增强式 - 算法使用软件代理来确定特定上下文中的理想行为(通常在机器人中使用)
| 算法类别 | 用途 | 学习类型 | 算法 |
|---|---|---|---|
| 分类 | 将人员或事物分类成组 | 监督式 | 决策树、逻辑回归、神经网络 |
| 群集功能 | 将一组示例划分为同质组 | 非监督式 | K-Means 群集 |
| 模式检测 | 标识数据中的常见关联 | 非监督式 | 关联规则 |
| 回归 | 预测数字结果 | 监督式 | 线性回归、神经网络 |
| 增强式 | 确定机器人的最佳行为 | 增强式 | 蒙特卡洛仿真、DeepMind |
HDInsight 中的机器学习
HDInsight 提供多个适用于高级分析工作流的机器学习选项:
- 机器学习和 Apache Spark
- Azure 机器学习和 Apache Hive
- Apache Spark 和深度学习
机器学习和 Apache Spark
HDInsight Spark 是 Azure 托管的 Apache Spark 产品/服务,它是统一的开源并行数据处理框架,使用内存中处理来大幅提升大数据分析性能。 Spark 处理引擎是专为速度、易用性和复杂分析打造的产品。 Spark 的内存中分布式计算功能使其成为机器学习和图形计算中使用的迭代算法的最佳选择。
有三个可缩放的机器学习库向此分布式环境引入了算法建模功能。
- MLlib - MLlib 包含构建在 Spark RDD 基础之上的原始 API。
- SparkML - SparkML 是一个较新的包,提供构建在 Spark DataFrames 基础之上的高级 API 用于构造机器学习管道。
- MMLSpark - 适用于 Apache Spark 的 Azure 机器学习库 (MMLSpark) 旨在提升数据科学家在 Spark 上的生产力,它不仅可以提高试验成功率,而且还能在大型数据集中利用前沿的机器学习技术,包括深度学习。 MMLSpark 库简化了在 PySpark 中构建模型的常见建模任务。
Azure 机器学习和 Apache Hive
Azure 机器学习工作室(经典)不仅提供预测分析建模工具,还提供完全托管的服务,你可通过此服务将预测模型部署为随时可用的 Web 服务。 Azure 机器学习提供可在云中创建完整预测分析解决方案的工具,用于快速创建、测试、操作和管理预测模型。 可以从大型算法库中进行选择、使用基于 Web 的工作室来构建模型,然后将模型轻松部署为 Web 服务。
Apache Spark 和深度学习
深度学习是机器学习的一个分支,使用以人类大脑的生物学流程为灵感的深度神经网络 (DNN)。 许多研究人员将深度学习视为有前景的人工智能方法。 深度学习的例子包括口译工具、图像识别系统和计算机推理。 为帮助推进自身在深度学习方面的工作,Azure 开发了免费、易用的开源 Microsoft Cognitive Toolkit。 该工具包在各种 Azure 产品、世界各地需要大规模部署深度学习的公司,以及对最新算法和技术感兴趣的学生中得到了广泛使用。
方案 - 为图像评分以识别城市发展模式
接下来我们探讨一个使用 HDInsight 的高级分析机器学习管道示例。
此方案展示了如何使用 HDInsight Spark 群集上的 PySpark,使深度学习框架(Azure Cognitive Toolkit (CNTK))中生成的 DNN 变得可操作,从而为存储在 Azure Blob 存储帐户中的大型图像集合进行评分。 此方法适用于一般的 DNN 用例和航拍图像分类,并可用于识别最近的城市发展模式。 你将使用预先训练的图像分类模型。 该模型是在 CIFAR-10 数据集 上预先训练的,并已应用于 10,000 张保留的图像。
此高级分析方案包括三个关键任务:
- 使用 Apache Spark 2.1.0 分发版创建 Azure HDInsight Hadoop 群集。
- 运行自定义脚本,在 Azure HDInsight Spark 群集的所有节点上安装 Microsoft Cognitive Toolkit。
- 将预先构建的 Jupyter Notebook 上传到 HDInsight Spark 群集,以使用 Spark Python API (PySpark) 将训练的 Azure Cognitive Toolkit 深度学习模型应用到 Azure Blob 存储帐户中的文件。
此示例使用了 Alex Krizhevsky、Vinod Kumar 及 Geoffrey Hinton 编译和分发的 CIFAR-10 图像集。 CIFAR-10 数据集包含 60,000 个分属 10 个互斥类的 32×32 彩色图像:

有关该数据集的详细信息,请参阅 Alex Krizhevsky 撰写的 Learning Multiple Layers of Features from Tiny Images(从微小图像中学习多层特征)。
该数据集已分区成由 50,000 个图像组成的训练集,以及由 10,000 个图像组成的测试集。 第一个集用于按照认知工具包 GitHub 存储库中的此教程,使用 Azure 认知工具包来训练深度达 20 层的卷积残差网络 (ResNet) 模型。 剩余的 10,000 个图像用于测试模型的准确性。 这正是分布式计算发挥作用的地方:对图像进行预处理和评分的任务是高度并行化的。 借助手头保存的已训练模型:
- 我们使用了 PySpark 将图像和训练模型分发到群集的工作节点。
- 使用 Python 对 HDInsight Spark 群集每个节点的图像进行预处理。
- 使用 Cognitive Toolkit 在每个节点上加载模型,并对已进行预处理的图像进行评分。
- 使用了 Jupyter Notebook 运行 PySpark 脚本、聚合结果,并使用了 Matplotlib 将模型性能可视化。
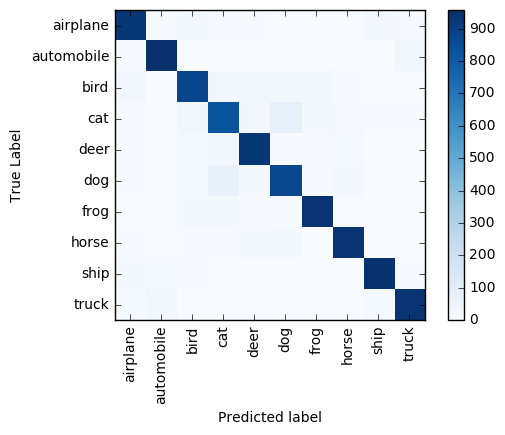
在包含 4 个工作器节点的群集上,对全部 10,000 张图像进行预处理和评分的用时不到一分钟。 该模型可准确预测大约 9,100 个 (91%) 图像的标签。 混淆矩阵可演示最常见的分类错误。 例如,以下矩阵显示,与其他标签对相比,发生将狗标记成猫(以及将猫标记成狗)的错误的频率较高。
试试吧!
请按照此教程以端到端的方式实施此解决方案:设置 HDInsight Spark 群集、安装认知工具包,然后运行可对 10,000 个 CIFAR 图像评分的 Jupyter Notebook。
后续步骤
Apache Hive 和 Azure 机器学习
Apache Spark 和 MLLib
- 在 Apache Spark on HDInsight 中使用机器学习
- Apache Spark 与机器学习:使用 HDInsight 中的 Apache Spark 来通过 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Apache Spark 预测食品检验结果
深度学习、认知工具包和其他技术