在本文中,将执行以下步骤。
运行自定义脚本,以在 Azure HDInsight Spark 群集上安装 Microsoft Cognitive Toolkit。
将 Jupyter Notebook 上传到 Apache Spark 群集,以了解如何使用 Spark Python API (PySpark) 将定型的 Microsoft Cognitive Toolkit 深度学习模型应用于 Azure Blob 存储帐户中的文件
必备条件
HDInsight 上的 Apache Spark 群集。 请参阅创建 Apache Spark 群集。
熟悉 Jupyter Notebook 和 Spark on HDInsight 的结合使用。 有关详细信息,请参阅使用 Apache Spark on HDInsight 加载数据并运行查询。
此解决方案的流程如何?
此解决方案分为两部分,即本文和在本文中上传的 Jupyter Notebook。 在本文中,完成以下步骤:
- 在 HDInsight Spark 群集上运行脚本操作,以安装 Azure Cognitive Toolkit 和 Python 包。
- 将运行解决方案的 Jupyter Notebook 上传到 HDInsight Spark 群集中。
以下其余步骤涵盖在 Jupyter Notebook 中。
- 将示例图像加载到 Spark 弹性分布式数据集或 RDD 中。
- 加载模块并定义预设。
- 将数据集下载到本地 Spark 群集上。
- 将数据集格式转换为 RDD。
- 使用定型的 Cognitive Toolkit 模型对图像评分。
- 将定型的 Cognitive Toolkit 模型下载到 Spark 群集。
- 定义由辅助角色节点使用的函数。
- 对辅助角色节点上的图像评分。
- 评估模型准确性。
安装 Azure Cognitive Toolkit
可以使用脚本操作在 Spark 群集上安装 Azure Cognitive Toolkit。 脚本操作使用自定义脚本在群集上安装默认情况下未提供的组件。 可以从 Azure 门户、通过使用 HDInsight .NET SDK 或 Azure PowerShell,来使用自定义脚本。 还可以在创建群集过程中或者在群集已启动并运行之后使用脚本安装工具包。
在本文中,我们在群集创建完成后使用门户安装该工具包。 有关运行自定义脚本的其他方式,请参阅使用脚本操作自定义 HDInsight 群集。
使用 Azure 门户
有关如何使用 Azure 门户运行脚本操作的说明,请参阅使用脚本操作自定义 HDInsight 群集。 确保提供以下输入,以便安装 Azure Cognitive Toolkit。 对于脚本操作,请使用以下值:
| properties | Value |
|---|---|
| 脚本类型 | - Custom |
| 名称 | 安装 MCT |
| Bash 脚本 URI | https://raw.githubusercontent.com/Azure-Samples/hdinsight-pyspark-cntk-integration/master/cntk-install.sh |
| 节点类型: | 头节点、工作器节点 |
| parameters | 无 |
将 Jupyter Notebook 上传到 Azure HDInsight Spark 群集
要将 Azure Cognitive Toolkit 与 Azure HDInsight Spark 群集配合使用,必须将 Jupyter Notebook CNTK_model_scoring_on_Spark_walkthrough.ipynb 加载到 Azure HDInsight Spark 群集中。 GitHub 上的 https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration 位置提供了此 Notebook。
下载并解压缩 https://github.com/Azure-Samples/hdinsight-pyspark-cntk-integration。
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中CLUSTERNAME是群集的名称。在 Jupyter Notebook 中,选择右上角的“上传”,然后导航到“下载”并选择文件
CNTK_model_scoring_on_Spark_walkthrough.ipynb。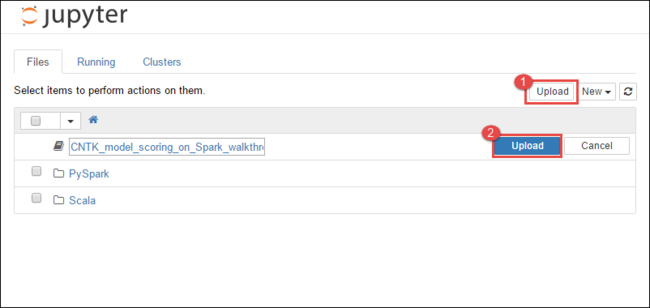
再次选择“上传” 。
笔记本上传后,单击笔记本的名称,并按照笔记本本身中有关如何加载数据集和执行本文的说明进行操作。
另请参阅
方案
- Apache Spark 和 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 和机器学习:使用 HDInsight 中的 Spark 结合 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
- 使用 HDInsight 中的 Apache Spark 执行 Application Insight 遥测数据分析
创建和运行应用程序
工具和扩展
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件创建和提交 Spark Scala 应用程序
- 使用适用于 IntelliJ IDEA 的 HDInsight 工具插件远程调试 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)