了解如何使用 Apache Ambari Hive 视图运行 Hive 查询。 Hive 视图允许从 Web 浏览器创作、优化和运行 Hive 查询。
先决条件
HDInsight 上的 Hadoop 群集。 请参阅 Linux 上的 HDInsight 入门。
运行 Hive 查询
从群集仪表板中,选择“Ambari 视图”。 当提示进行身份验证时,请使用在创建群集时所提供的群集登录名(默认为
admin)帐户名称和密码。 还可以在浏览器中导航到https://CLUSTERNAME.azurehdinsight.cn/#/main/views,其中CLUSTERNAME是群集的名称。在视图列表中,选择“Hive 视图”。
Hive 视图页面类似于下图:
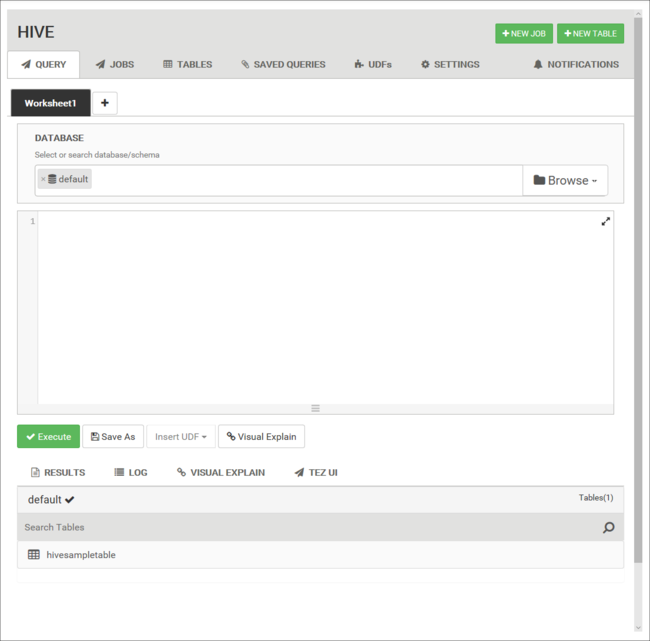
将以下 HiveQL 语句从“查询”选项卡粘贴到工作表中:
DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4jLogs( t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS loglevel, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' GROUP BY t4;这些语句执行以下操作:
语句 说明 DROP TABLE 删除表和数据文件(如果该表已存在)。 CREATE EXTERNAL TABLE 在 Hive 中创建一个新的“外部”表。 外部表仅在 Hive 中存储表定义。 数据保留在原始位置。 ROW FORMAT 演示如何设置数据格式。 在此情况下,每个日志中的字段以空格分隔。 STORED AS TEXTFILE LOCATION 显示数据的存储位置,并且数据已存储为文本。 SELECT 选择 t4 列包含值 [ERROR] 的所有行的计数。 重要
将“数据库”选择保留为“默认”。 本文档中的示例使用 HDInsight 附带的默认数据库。
若要启动查询,请选择工作表下方的“执行”。 按钮变为橙色,文本更改为“停止”。
完成查询后,“结果”选项卡显示操作结果。 以下文本是查询结果:
loglevel count [ERROR] 3可使用“日志”选项卡查看创建的作业的日志记录信息。
提示
从“结果”选项卡下的“操作”下拉对话框下载或保存结果。
视觉对象说明
若要显示查询计划的可视化效果,请选择工作表下方的“视觉对象说明”选项卡。
查询的“视觉对象说明”视图可帮助理解复杂查询的流程。
Tez UI
若要显示查询的 Tez UI,请选择工作表下方的“Tez UI”选项卡。
重要
Tez 不用于解析所有查询。 无需使用 Tez 即可解析许多查询。
查看作业历史记录
“作业”选项卡显示 Hive 查询的历史记录。
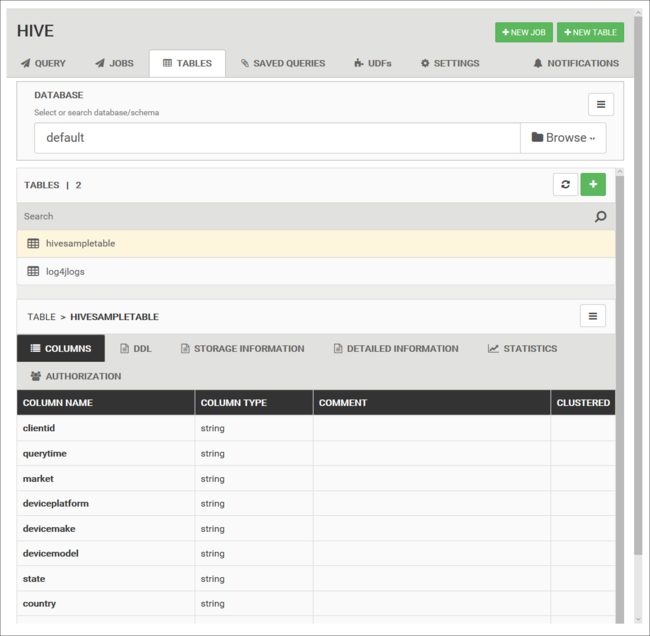
数据库表
可使用“表”选项卡处理 Hive 数据库内的表。
已保存的查询
在“查询”选项卡中,可以按需要保存查询。 保存查询后,可通过“已保存的查询”选项卡对其重复进行使用。
提示
保存的查询存储在默认群集存储中。 可在路径 /user/<username>/hive/scripts 下找到保存的查询。 它们存储为纯文本 .hql 文件。
用户定义的函数
可以通过用户定义函数 (UDF) 扩展 Hive。 使用 UDF 实现 HiveQL 中不容易建模的功能或逻辑。
使用 Hive 视图顶部的“UDF”选项卡,声明并保存一组 UDF。 可以在查询编辑器中使用这些 UDF。
“插入 UDF”按钮显示在“查询编辑器”的底部。 此项将显示 Hive 视图中定义的 UDF 的下拉列表。 选择一个 UDF 可向查询添加 HiveQL 语句以启用 UDF。
例如,如果定义了具有以下属性的 UDF:
资源名称:myudfs
资源路径:/myudfs.jar
UDF 名称:myawesomeudf
UDF 类名称:com.myudfs.Awesome
使用“插入 UDF”按钮将显示名为 myudfs 的条目,以及为该资源定义的每个 UDF 的另一下拉列表。 本例中为 myawesomeudf。 选择此条目会在查询的开头添加以下内容:
add jar /myudfs.jar;
create temporary function myawesomeudf as 'com.myudfs.Awesome';
然后便可在查询中使用 UDF。 例如,SELECT myawesomeudf(name) FROM people;。
有关如何在 HDInsight 中将 UDF 与 Hive 配合使用的详细信息,请参阅以下文章:
Hive 设置
可以更改各种 Hive 设置,例如将 Hive 的执行引擎从 Tez(默认)更改为 MapReduce。
后续步骤
有关 HDInsight 中 Hive 的常规信息: