了解如何使用针对 Visual Studio 的 Data Lake 工具查询 Apache Hive。 使用 Data Lake 工具,可以轻松创建 Hive 查询,将其提交到 Azure HDInsight 上的 Apache Hadoop 并进行监视。
先决条件
HDInsight 中的 Apache Hadoop 群集。 有关创建此项的信息,请参阅使用资源管理器模板在 Azure HDInsight 中创建 Apache Hadoop 群集。
Visual Studio。 本文中的步骤使用 Visual Studio 2019。
Visual Studio 的 HDInsight 工具或 Visual Studio 的 Azure Data Lake 工具。 有关安装和配置工具的信息,请参阅安装适用于 Visual Studio 的 Data Lake 工具。
使用 Visual Studio 运行 Apache Hive 查询
可以使用两个选项来创建并运行 Hive 查询:
- 创建临时查询。
- 创建 Hive 应用程序。
创建临时 Hive 查询。
即席查询可以批处理或交互式模式执行。
启动 Visual Studio 并选择“继续但无需代码”。
在服务器资源管理器中右键单击“Azure”并选择“连接到 Azure 订阅...”,然后完成登录过程。
展开“HDInsight”,右键单击要运行查询的群集,然后选择“编写 Hive 查询”。
输入以下 Hive 查询:
SELECT * FROM hivesampletable;选择“执行” 。 执行模式默认为“交互式”。
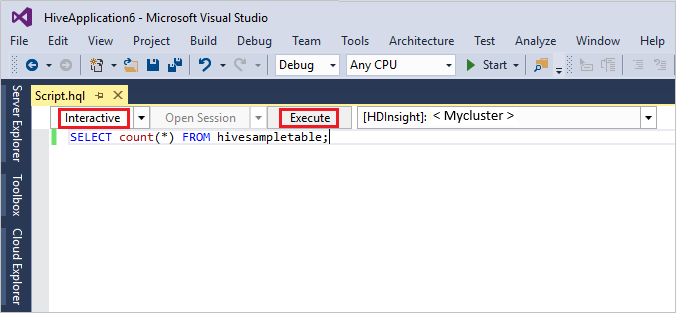
若要以批处理模式下运行同一查询,请将下拉列表从“交互式”切换到“批处理”。 执行按钮将从“执行”更改为“提交”。
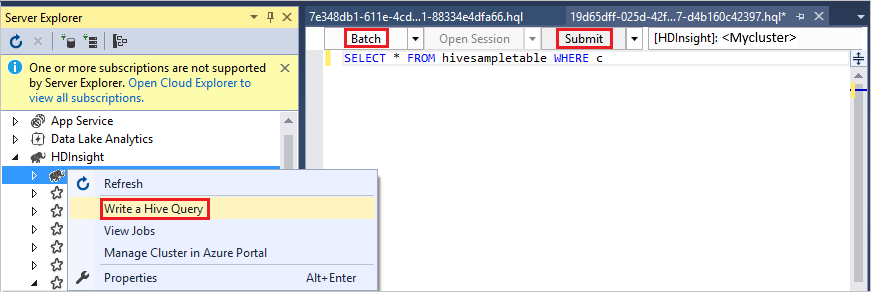
Hive 编辑器支持 IntelliSense。 用于 Visual Studio 的 Data Lake 工具支持在编辑 Hive 脚本时加载远程元数据。 例如,如果键入
SELECT * FROM,则 IntelliSense 会列出所有建议的表名称。 在指定表名称后,IntelliSense 会列出列名称。 这些工具支持大多数 Hive DML 语句、子查询和内置 UDF。 IntelliSense 只建议 HDInsight 工具栏中所选群集的元数据。在查询工具栏(查询选项卡下面以及查询文本上面的区域)中,选择“提交”,或者选择“提交”旁边的下拉箭头并从下拉列表中选择“高级”。 如果选择后一个选项,
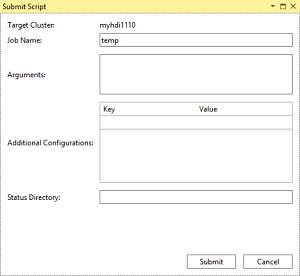
即选择高级提交选项,请在“提交脚本”对话框中配置“作业名称”、“参数”、“其他配置”和“状态目录”。 然后选择“提交”。
创建 Hive 应用程序
若要通过创建 Hive 应用程序来运行 Hive 查询,请执行以下步骤:
打开“Visual Studio”。
在“开始”窗口中,选择“创建新项目”。
在“创建新项目”窗口中的“搜索模板”框内,输入 Hive。 然后依次选择“Hive 应用程序”、“下一步”。
在“配置新项目”窗口中输入一个项目名称,选择或创建新项目的位置,然后选择“创建”。
打开使用此项目创建的 Script.hql 文件,并在其中粘贴以下 HiveQL 语句:
set hive.execution.engine=tez; DROP TABLE log4jLogs; CREATE EXTERNAL TABLE log4j Logs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) ROW FORMAT DELIMITED FIELDS TERMINATED BY ' ' STORED AS TEXTFILE LOCATION '/example/data/'; SELECT t4 AS sev, COUNT(*) AS count FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log' GROUP BY t4;这些语句执行以下操作:
DROP TABLE:如果表存在,则删除它。CREATE EXTERNAL TABLE:在 Hive 中创建一个新的“外部”表。 外部表只会在 Hive 中存储表定义。 (数据保留在原始位置。)注意
如果你预期基础数据会由外部源(例如 MapReduce 作业或 Azure 服务)更新,则应使用外部表。
删除外部表不会删除数据,只会删除表定义。
ROW FORMAT:告知 Hive 如何设置数据的格式。 在此情况下,每个日志中的字段以空格分隔。STORED AS TEXTFILE LOCATION:告知 Hive 数据已以文本形式存储在 example/data 目录中。SELECT:选择t4列包含值[ERROR]的所有行计数。 此语句会返回值3,因为有三个行包含此值。INPUT__FILE__NAME LIKE '%.log':告知 Hive 仅返回以 .log 结尾的文件中的数据。 此子句将搜索限定为包含数据的 sample.log 文件。
在查询文件工具栏(其外观与临时查询工具栏类似)中,选择要用于此查询的 HDInsight 群集。 然后,将“交互式”更改为“批处理”(如果需要),并选择“提交”以 Hive 作业形式运行语句。
“Hive 作业摘要”会出现并显示有关正在运行的作业的信息。 在“作业状态”更改为“已完成”之前,使用“刷新”链接刷新作业信息。
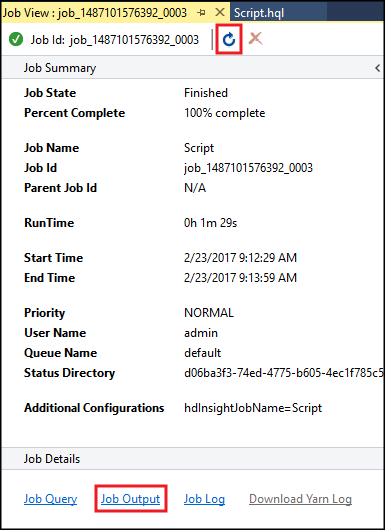
选择“作业输出”查看此作业的输出。 它显示
[ERROR] 3,这是此查询返回的值。
其他示例
以下示例依赖于在前一过程创建 Hive 应用程序中创建的 log4jLogs 表。
在“服务器资源管理器”中,右键单击群集,然后选择“编写 Hive 查询”。
输入以下 Hive 查询:
set hive.execution.engine=tez; CREATE TABLE IF NOT EXISTS errorLogs (t1 string, t2 string, t3 string, t4 string, t5 string, t6 string, t7 string) STORED AS ORC; INSERT OVERWRITE TABLE errorLogs SELECT t1, t2, t3, t4, t5, t6, t7 FROM log4jLogs WHERE t4 = '[ERROR]' AND INPUT__FILE__NAME LIKE '%.log';这些语句执行以下操作:
CREATE TABLE IF NOT EXISTS:如果表尚不存在,则创建表。 由于未使用EXTERNAL关键字,因此此语句会创建内部表。 内部表存储在 Hive 数据仓库中,由 Hive 管理。注意
与
EXTERNAL表不同,删除内部表会同时删除基础数据。STORED AS ORC:以优化的行纵栏式 (ORC) 格式存储数据。 ORC 是高度优化且有效的 Hive 数据存储格式。INSERT OVERWRITE ... SELECT:从包含[ERROR]的log4jLogs表中选择行,然后将数据插入errorLogs表中。
根据需要将“交互式”更改为“批处理”,然后选择“提交”。
若要验证该作业是否已创建表,请转到“服务器资源管理器”并展开“Azure”>“HDInsight”。 展开 HDInsight 群集,然后展开“Hive 数据库”>“默认”。 此时会列出 errorLogs 表和 Log4jLogs 表。
后续步骤
可以看到,适用于 Visual Studio 的 HDInsight 工具可以轻松地在 HDInsight 上处理 Hive 查询。
有关 HDInsight 中 Hive 的一般信息,请参阅 Azure HDInsight 中的 Apache Hive 和 HiveQL 是什么?
有关在 HDInsight 上处理 Hadoop 的其他方式的信息,请参阅在 HDInsight 上的 Apache Hadoop 中使用 MapReduce
有关适用于 Visual Studio 的 HDInsight 工具的详细信息,请参阅使用适用于 Visual Studio 的 Data Lake 工具连接到由世纪互联运营的 Microsoft Azure HDInsight 并运行 Apache Hive 查询