了解如何使用 Azure HDInsight 中的 Apache Hive 处理和分析 JavaScript 对象表示法 (JSON) 文件。 本文使用以下 JSON 文档:
{
"StudentId": "trgfg-5454-fdfdg-4346",
"Grade": 7,
"StudentDetails": [
{
"FirstName": "Peggy",
"LastName": "Williams",
"YearJoined": 2012
}
],
"StudentClassCollection": [
{
"ClassId": "89084343",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "High",
"Score": 93,
"PerformedActivity": false
},
{
"ClassId": "78547522",
"ClassParticipation": "NotSatisfied",
"ClassParticipationRank": "None",
"Score": 74,
"PerformedActivity": false
},
{
"ClassId": "78675563",
"ClassParticipation": "Satisfied",
"ClassParticipationRank": "Low",
"Score": 83,
"PerformedActivity": true
}
]
}
可以在 wasb://processjson@hditutorialdata.blob.core.chinacloudapi.cn/上找到该文件。 有关如何将 Azure Blob 存储与 HDInsight 配合使用的详细信息,请参阅将 HDFS 兼容的 Azure Blob 存储与 HDInsight 中的 Apache Hadoop 配合使用。 可以将该文件复制到群集的默认容器。
在本文中,将使用 Apache Hive 控制台。 有关如何打开 Hive 控制台的说明,请参阅在 HDInsight 中将 Apache Ambari Hive 视图与 Apache Hadoop 配合使用。
注意
HDInsight 4.0 中不再提供 Hive 视图。
平展 JSON 文档
下一部分中所列的方法需要 JSON 文档在单个行中。 因此,必须将 JSON 文档平展成字符串。 如果 JSON 文档已平展,则可以跳过此步骤,直接转到有关分析 JSON 数据的下一部分。 若要平展 JSON 文档,请运行以下脚本:
DROP TABLE IF EXISTS StudentsRaw;
CREATE EXTERNAL TABLE StudentsRaw (textcol string) STORED AS TEXTFILE LOCATION "wasb://processjson@hditutorialdata.blob.core.chinacloudapi.cn/";
DROP TABLE IF EXISTS StudentsOneLine;
CREATE EXTERNAL TABLE StudentsOneLine
(
json_body string
)
STORED AS TEXTFILE LOCATION '/json/students';
INSERT OVERWRITE TABLE StudentsOneLine
SELECT CONCAT_WS(' ',COLLECT_LIST(textcol)) AS singlelineJSON
FROM (SELECT INPUT__FILE__NAME,BLOCK__OFFSET__INSIDE__FILE, textcol FROM StudentsRaw DISTRIBUTE BY INPUT__FILE__NAME SORT BY BLOCK__OFFSET__INSIDE__FILE) x
GROUP BY INPUT__FILE__NAME;
SELECT * FROM StudentsOneLine
原始 JSON 文件位于 wasb://processjson@hditutorialdata.blob.core.chinacloudapi.cn/。 StudentsRaw Hive 表指向未平展的原始 JSON 文档。
StudentsOneLine Hive 表将数据存储在 HDInsight 默认文件系统中的 /json/students/ 路径下。
INSERT 语句使用平展的 JSON 数据填充 StudentOneLine 表。
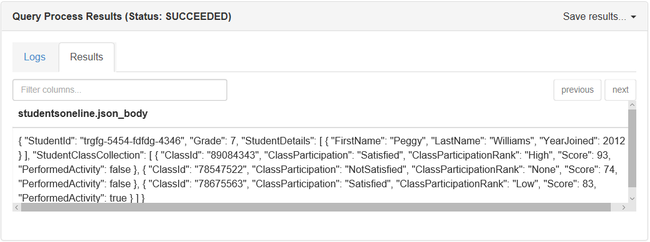
SELECT 语句只返回 1 行。
下面是 SELECT 语句的输出:
在 Hive 中分析 JSON 文档
Hive 提供了三种不同的机制用于对 JSON 文档运行查询,你也可以编写自己的代码:
- 使用 get_json_object 用户定义的函数 (UDF)。
- 使用 json_tuple UDF。
- 使用自定义序列化程序/反序列化程序 (SerDe)。
- 使用 Python 或其他语言编写自己的 UDF。 有关如何使用 Hive 运行自己的 Python 代码的详细信息,请参阅使用 Apache Hive 和 Apache Pig 运行 Python UDF。
使用 get_json_object UDF
Hive 提供名为 get_json_object 的内置 UDF,它在运行时查询 JSON。 此方法采用两个参数:表名和方法名。 方法名具有平展 JSON 文档和需要分析的 JSON 字段。 让我们探讨一个示例,了解此 UDF 的工作原理。
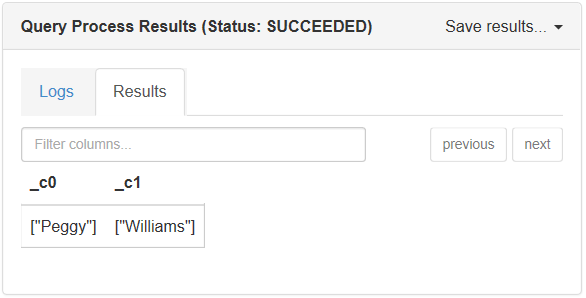
以下查询返回每个学生的名字和姓氏:
SELECT
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.FirstName'),
GET_JSON_OBJECT(StudentsOneLine.json_body,'$.StudentDetails.LastName')
FROM StudentsOneLine;
下面是在控制台窗口中运行此查询时的输出:
get_json_object UDF 有限制:
- 由于查询中的每个字段都需要重新分析查询,因此会影响性能。
- GET_JSON_OBJECT() 返回数组的字符串表示形式。 要将此数组转换为 Hive 数组,必须使用正则表达式来替换方括号“[”和“]”,然后调用拆分来获取数组。
此转换是 Hive Wiki 建议使用 json_tuple 的原因。
使用 json_tuple UDF
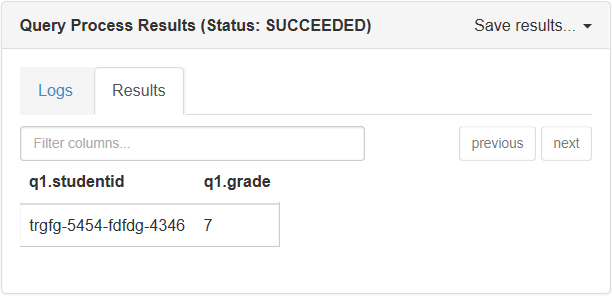
Hive 提供的另一个 UDF 名为 json_tuple,其性能比 get_json_object 要高。 此方法采用一组键和一个 JSON 字符串, 然后返回值的元组。 以下查询将从 JSON 文档返回学生 ID 和年级:
SELECT q1.StudentId, q1.Grade
FROM StudentsOneLine jt
LATERAL VIEW JSON_TUPLE(jt.json_body, 'StudentId', 'Grade') q1
AS StudentId, Grade;
此脚本在 Hive 控制台中的输出:
json_tuple UDF 在 Hive 中使用了横向视图语法,使 json_tuple 能够通过将 UDT 函数应用于原始表的每一行来创建虚拟表。 由于重复使用横向视图,复杂的 JSON 会变得过于庞大。 此外,JSON_TUPLE 无法处理嵌套的 JSON。
使用自定义 SerDe
SerDe 是用于分析嵌套 JSON 文档的最佳选择。 使用它可以定义 JSON 架构,然后使用该架构来分析文档。 有关说明,请参阅如何将自定义 JSON SerDe 与 Azure HDInsight 配合使用。
摘要
在 Hive 中选择的 JSON 运算符的类型取决于方案。 使用一个简单的 JSON 文档并拥有一个要查找的字段时,请选择 Hive UDF get_json_object。 如果有多个要查找的键,则可以使用 json_tuple。 对于嵌套文档,请使用 JSON SerDe。
后续步骤
相关文章请参阅: