本文介绍 Hive Warehouse Connector (HWC) 支持的基于 Spark 的操作。 下面显示的所有示例都将通过 Apache Spark shell 执行。
先决条件
完成 Hive Warehouse Connector 设置步骤。
入门
若要启动 spark-shell 会话,请执行以下步骤:
使用 ssh 命令连接到 Apache Spark 群集。 编辑以下命令,将 CLUSTERNAME 替换为群集的名称,然后输入该命令:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.cn在 ssh 会话中,执行以下命令以记下
hive-warehouse-connector-assembly版本:ls /usr/hdp/current/hive_warehouse_connector使用上面标识的
hive-warehouse-connector-assembly版本编辑下面的代码。 然后执行命令启动 spark shell:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<STACK_VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false启动 spark shell 后,可以使用以下命令启动 Hive Warehouse Connector 实例:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
使用 Hive 查询创建 Spark 数据帧
使用 HWC 库的所有查询的结果都将作为数据帧返回。 以下示例演示如何创建基本的 hive 查询。
hive.setDatabase("default")
val df = hive.executeQuery("select * from hivesampletable")
df.filter("state = 'Colorado'").show()
查询的结果是 Spark 数据帧,可以与 MLIB 和 SparkSQL 等 Spark 库一起使用。
将 Spark 数据帧写入 Hive 表
Spark 本身不支持写入 Hive 的托管 ACID 表。 但是,使用 HWC 可以将任何数据帧写入 Hive 表。 以下示例演示了此功能的用法:
创建名为
sampletable_colorado的表,并使用以下命令指定其列:hive.createTable("sampletable_colorado").column("clientid","string").column("querytime","string").column("market","string").column("deviceplatform","string").column("devicemake","string").column("devicemodel","string").column("state","string").column("country","string").column("querydwelltime","double").column("sessionid","bigint").column("sessionpagevieworder","bigint").create()筛选列
state等于Colorado的表hivesampletable。 此 hive 查询使用write函数返回存储在 Hive 表sampletable_colorado中的 Spark 数据帧和结果。hive.table("hivesampletable").filter("state = 'Colorado'").write.format("com.hortonworks.spark.sql.hive.llap.HiveWarehouseConnector").mode("append").option("table","sampletable_colorado").save()使用以下命令查看结果:
hive.table("sampletable_colorado").show()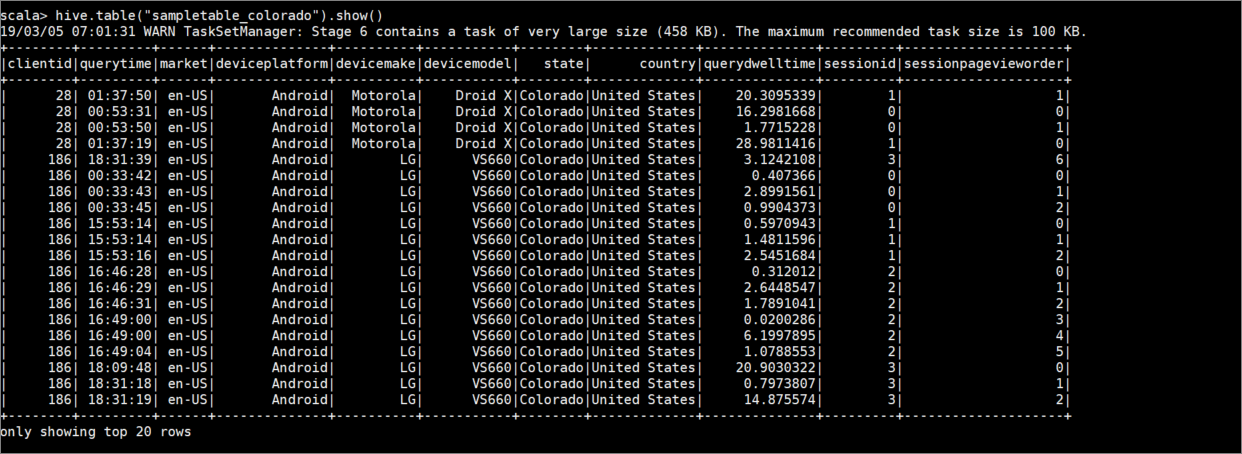
结构化流写入
使用 Hive Warehouse Connector,可以使用 Spark 流将数据写入 Hive 表。
重要
启用 ESP 的 Spark 4.0 群集不支持结构化流写入。
按照以下步骤将数据从 localhost 端口 9999 上的 Spark 流引入到 Hive 表中。 Hive Warehouse Connector。
从打开的 Spark shell 中,使用以下命令启动 spark 流:
val lines = spark.readStream.format("socket").option("host", "localhost").option("port",9999).load()通过执行以下步骤,为创建的 Spark 流生成数据:
- 在同一个 Spark 群集上打开另一个 SSH 会话。
- 在命令提示符下键入
nc -lk 9999。 此命令使用netcat实用工具将数据从命令行发送到指定端口。
返回到第一个 SSH 会话,并创建新的 Hive 表来保存流数据。 在 spark-shell 中输入以下命令:
hive.createTable("stream_table").column("value","string").create()然后,使用以下命令将流数据写入新建的表:
lines.filter("value = 'HiveSpark'").writeStream.format("com.hortonworks.spark.sql.hive.llap.streaming.HiveStreamingDataSource").option("database", "default").option("table","stream_table").option("metastoreUri",spark.conf.get("spark.datasource.hive.warehouse.metastoreUri")).option("checkpointLocation","/tmp/checkpoint1").start()重要
由于 Apache Spark 的已知问题,目前必须手动设置
metastoreUri和database选项。 有关此问题的详细信息,请参阅 SPARK-25460。返回到另一个 SSH 会话,然后输入以下值:
foo HiveSpark bar返回到第一个 SSH 会话,并记下简单的活动。 若要查看数据,请使用以下命令:
hive.table("stream_table").show()
使用 Ctrl + C 在第二个 SSH 会话上停止 netcat。 使用 :q 在第一个 SSH 会话中退出 spark shell。