在数据库和仓库的上下文中,复制是将实体从一个仓库复制到另一个仓库的过程。 复制可应用于整个数据库,也可应用于更小的级别(例如表或分区)。 目标是让一个副本在基本实体发生更改时进行更改。 Apache Hive 上的复制侧重于灾难恢复,提供单向的主副本复制。 在 HDInsight 群集中,可使用 Hive 复制功能单向复制 Hive 元存储以及其关联的底层数据湖到 Azure Data Lake Storage Gen2 上。
Hive 复制已经过多年的发展,更新的版本提供了更好的功能,速度更快,资源消耗更少。 在本文中,我们讨论了在 HDInsight 3.6 和 HDInsight 4.0 群集类型中都支持的 Hive 复制 (Replv2)。
replv2 的优势
与使用了 Hive IMPORT-EXPORT 的第一版 Hive 复制相比,Replv2(也称为 )具有以下优点:
- 基于事件的增量复制
- 时间点复制
- 降低了带宽要求
- 中间副本数量减少
- 复制状态已被维护
- 受限制的复制
- 支持中心辐射型模型
- 支持 ACID 表(在 HDInsight 4.0 中)
复制阶段
Hive 基于事件的复制是在主群集与辅助群集之间配置的。 此复制包括两个不同的阶段:启动和增量运行。
自举
初始化旨在运行一次,以将数据库的基础状态从主数据库复制到辅助数据库。 如果需要,你可以对启动进行配置,以便在需要启用复制的目标数据库中包括表的子集。
增量运行
启动初始化后,增量运行自动化在主群集上执行,并且在这些增量运行期间生成的事件会在辅助群集上被回放。 当辅助群集赶上主群集的进度后,辅助群集的事件会与主群集的事件保持一致。
复制命令
Hive 提供了一组 REPL 命令(DUMP、LOAD 和 STATUS)来协调事件流。
DUMP 命令生成主群集上所有 DDL/DML 事件的本地日志。
LOAD 命令是一种将记录的元数据和数据惰性地复制到提取的复制转储输出中,并在目标集群上执行的方法。
STATUS 命令从目标群集运行,用于提供表明已成功复制最新复制负载的最新事件 ID。
设置复制源
在开始复制之前,请确保要复制的数据库已设置为复制源。 你可以使用 DESC DATABASE EXTENDED <db_name> 命令来确定是否为参数 repl.source.for 设置了策略名称。
如果已计划策略,但未设置 repl.source.for 参数,则需先使用 ALTER DATABASE <db_name> SET DBPROPERTIES ('repl.source.for'='<policy_name>') 设置此参数。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source.for'='replpolicy1')
将元数据转储到数据湖
启动阶段使用 REPL DUMP [database name]. => location / event_id 命令将相关元数据转储到Azure Data Lake Storage Gen2。
event_id指定相关元数据已放入Azure Data Lake Storage Gen2的最小事件。
repl dump tpcds_orc;
示例输出:
| dump_dir | last_repl_id (最后替换标识) |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0 | 2925 |
将数据加载到目标群集
对于复制的启动和增量阶段,都使用 REPL LOAD [database name] FROM [ location ] { WITH ( 'key1'='value1'{, 'key2'='value2'} ) } 命令将数据加载到目标群集中。
[database name] 可以与源同名,也可以是目标群集上的另一名称。
[location] 表示之前的 REPL DUMP 命令的输出中的位置。 这意味着目标群集应该能够与源群集通信。 添加 WITH 子句主要是为了防止目标群集重启,以便进行复制。
repl load tpcds_orc from '/tmp/hive/repl/38896729-67d5-41b2-90dc-46eeed4c5dd0';
输出最后一个复制的事件 ID
REPL STATUS [database name] 命令在目标群集上执行,并输出最后一个复制的 event_id。 用户还可以使用此命令了解已将其目标群集复制成什么状态。 可以使用此命令的输出来构造用于增量复制的下一个 REPL DUMP 命令。
repl status tpcds_orc;
示例输出:
| last_repl_id (最后替换标识) |
|---|
| 2925 |
将相关数据和元数据转储到数据湖
REPL DUMP [database name] FROM [event-id] { TO [event-id] } { LIMIT [number of events] } 命令用于将相关的元数据和数据转储到Azure Data Lake Storage。 此命令在增量阶段使用,在源仓库上运行。 对于增量阶段,FROM [event-id] 是必需的,event-id 的值可以通过在目标仓库上运行 REPL STATUS [database name] 命令来派生。
repl dump tpcds_orc from 2925;
示例输出:
| dump_dir | last_repl_id (最后替换标识) |
|---|---|
| /tmp/hive/repl/38896729-67d5-41b2-90dc-466466agadd0 | 2960 |
Hive 复制过程
在 Hive 复制过程中发生的事件是按照以下步骤的顺序进行的。
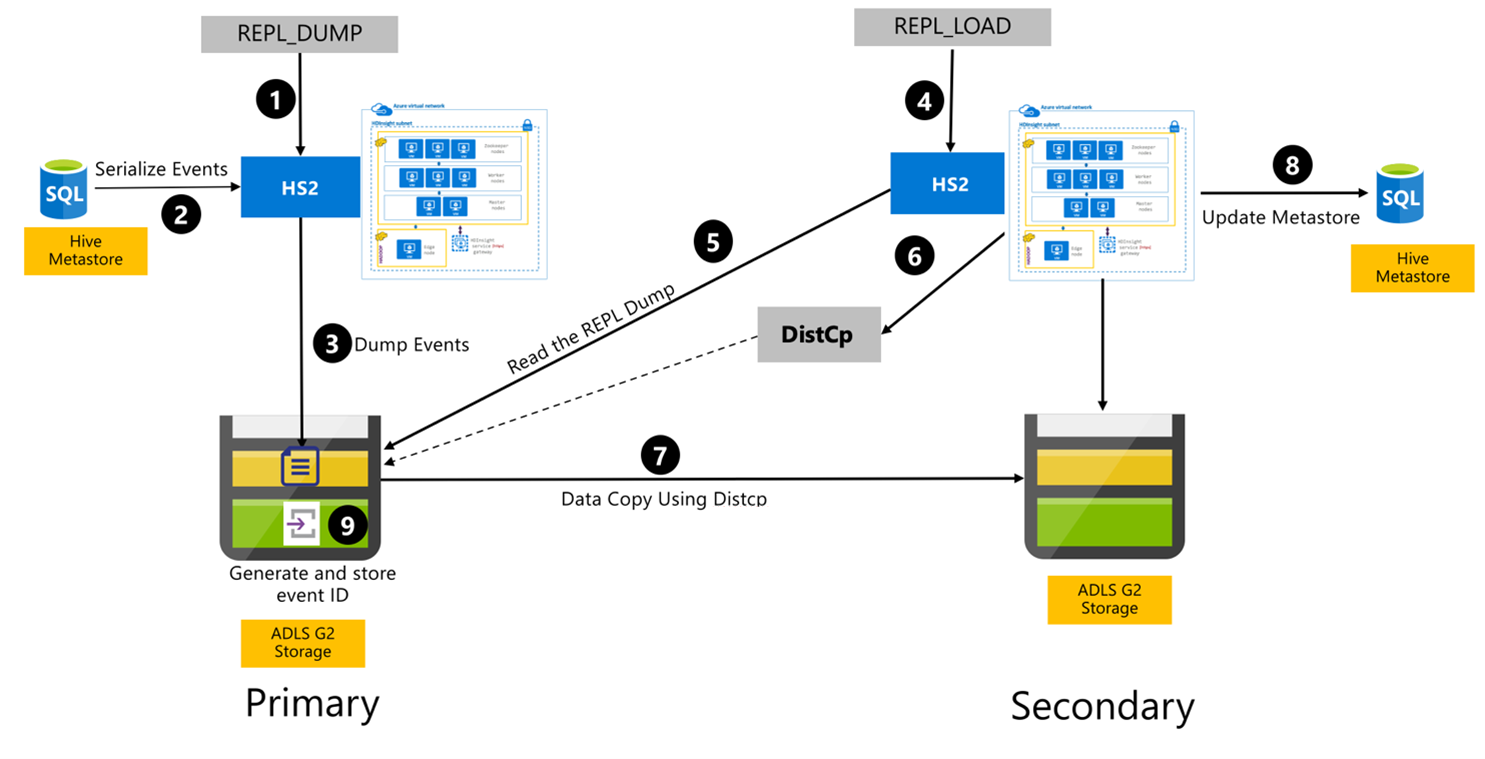
确保要复制的表已设置为特定策略的复制源。
REPL_DUMP命令颁发给主群集,其关联的约束包括数据库名称、事件 ID 范围和Azure Data Lake Storage Gen2存储 URL。系统将元存储中所有已跟踪事件的转储序列化为最新版本。 此转储存储在主群集上的 Azure Data Lake Storage Gen2 存储帐户中,该 URL 由
REPL_DUMP指定。主群集将复制元数据保存到主群集的Azure Data Lake Storage Gen2存储。 该路径可在 Ambari 的 Hive 配置 UI 中进行配置。 此过程提供元数据的存储路径,以及最新的已跟踪 DML/DDL 事件的 ID。
REPL_LOAD命令是从辅助群集发出的。 此命令指向步骤 3 中配置的路径。次要群集读取包含在步骤 3 中创建的已跟踪事件的元数据文件。 确保辅助群集与主群集的Azure Data Lake Storage Gen2存储建立了网络连接,其中存储了来自
REPL_DUMP的跟踪事件。辅助群集创建了分布式复制 (
DistCP) 计算。辅助群集从主群集的存储复制数据。
次级集群上的元存储已更新。
将最后一个已跟踪事件 ID 存储在主元存储中。
增量复制遵循相同的过程,它需要最后一个复制的事件 ID 作为输入。 这会导致自上次复制事件以来的增量复制。 增量复制通常以预定的频率自动执行,以实现所需的恢复点目标 (RPO)。
复制模式
复制通常配置为在主群集与辅助群集之间单向进行,在这种情况下,主群集用于满足读取和写入请求。 辅助群集仅用于满足读取请求。 如果发生灾难,则允许在辅助群集上执行写入,但需要配置到主群集的反向复制。
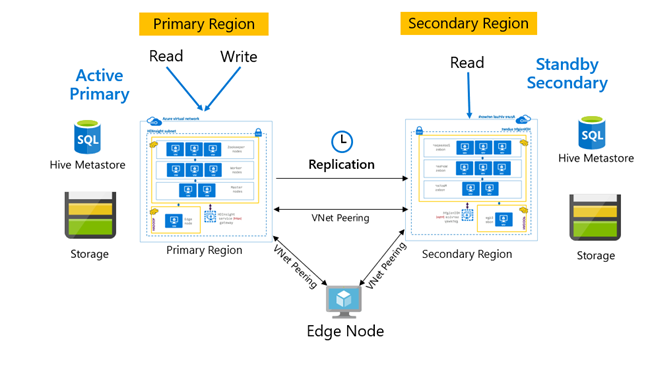
有许多适用于 Hive 复制的模式,包括“主-辅”模式、“中心辐射”模式和“中继”模式。
在 HDInsight 中,“主动-备用辅助”是一种常见的业务连续性和灾难恢复 (BCDR) 模式,HiveReplicationV2 可通过 VNet 对等互连将此模式与区域分隔的 HDInsight Hadoop 群集配合使用。 可以使用对等互连到这两个群集的公用虚拟机来承载复制自动化脚本。
企业安全套件的 Hive 复制
如果在包含企业安全套件的 HDInsight Hadoop 群集上计划进行 Hive 复制,则必须考虑 Ranger 元存储和 Microsoft Entra 域服务的复制功能。
使用Microsoft Entra Domain Services副本集功能跨多个区域为每个Microsoft Entra租户创建多个Microsoft Entra Domain Services副本集。 每个单独的副本集需要在其所在区域通过 HDInsight 虚拟网络 (VNet) 进行对等互连。 在此配置中,Microsoft Entra Domain Services的更改(包括配置、用户标识和凭据、组、组策略对象、计算机对象和其他更改)将应用于托管域中使用Microsoft Entra Domain Services复制的所有副本集。
可使用 Ranger 导入-导出功能定期备份 Ranger 策略并将其从主群集复制到辅助群集。 你可以选择复制所有或部分 Ranger 策略,具体取决于要在辅助群集上实现的授权级别。
代码示例
下面的代码序列提供了一个示例,展示了如何在名为 tpcds_orc 的示例表上实现启动和增量复制。
将该表设置为复制策略的源。
ALTER DATABASE tpcds_orc SET DBPROPERTIES ('repl.source. for'='replpolicy1');主群集上的Bootstrap转储。
repl dump tpcds_orc with ('hive.repl.rootdir'='/tmpag/hiveag/replag');示例输出:
dump_dir last_repl_id (最后替换标识) /tmpag/hiveag/replag/675d1bea-2361-4cad-bcbf-8680d305a27a 2925 辅助群集上的引导负载。
repl load tpcds_orc from '/tmpag/hiveag/replag 675d1bea-2361-4cad-bcbf-8680d305a27a';检查辅助群集上的
REPL状态。repl status tpcds_orc;last_repl_id (最后替换标识) 2925 初级簇群中的增量转储。
repl dump tpcds_orc from 2925 with ('hive.repl.rootdir'='/tmpag/hiveag/ replag');示例输出:
dump_dir last_repl_id (最后替换标识) /tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31 2960 备用集群上的增量负载。
repl load tpcds_orc from '/tmpag/hiveag/replag/31177ff7-a40f-4f67-a613-3b64ebe3bb31';检查次要群集上的
REPL状态。repl status tpcds_orc;last_repl_id (最后替换标识) 2960
后续步骤
若要详细了解本文中所述的项,请参阅: