了解如何将 Azure HDInsight 中的 Apache Spark 群集连接到 Azure SQL 数据库。 然后,在 SQL 数据库中读取、写入和流式传输数据。 本文中的说明使用 Jupyter Notebook 运行 Scala 代码片段。 但是,可以在 Scala 或 Python 中创建独立的应用程序,然后执行相同的任务。
先决条件
Azure HDInsight Spark 群集。 遵照在 HDInsight 中创建 Apache Spark 群集中的说明。
Azure SQL 数据库。 按照在 Azure SQL 数据库中创建数据库中的说明进行操作。 确保使用示例 AdventureWorksLT 架构和数据创建数据库。 另外,请确保创建服务器级防火墙规则,以允许客户端的 IP 地址访问 SQL 数据库。 同一篇文章中提供了有关添加防火墙规则的说明。 创建 SQL 数据库后,请确保准备好以下值。 从 Spark 群集连接到数据库时需要这些值。
- 服务器名称。
- 数据库名称。
- Azure SQL 数据库管理员用户名/密码。
SQL Server Management Studio (SSMS)。 遵照使用 SSMS 连接和查询数据中的说明。
创建 Jupyter Notebook
首先,创建与 Spark 群集关联的 Jupyter Notebook。 到时要使用此 Notebook 来运行本文中所用的代码片段。
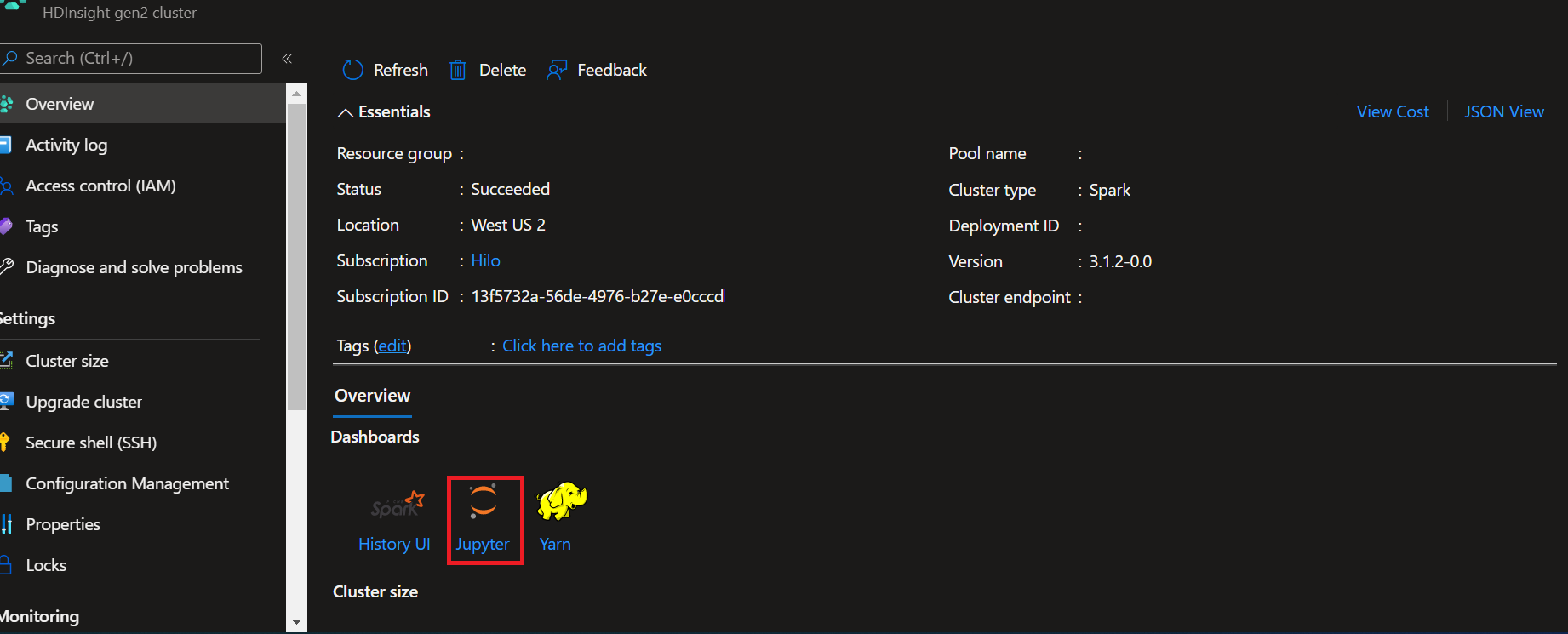
- 从 Azure 门户网站打开群集。
- 选择右侧“群集仪表板”下方的“Jupyter Notebook”。 如果没有看到“群集仪表板”,请从左侧菜单中选择“概述”。 出现提示时,请输入群集的管理员凭据。
注意
也可以在浏览器中打开以下 URL 来访问 Spark 群集中的 Jupyter Notebook。 将 CLUSTERNAME 替换为群集的名称:
https://CLUSTERNAME.azurehdinsight.cn/jupyter
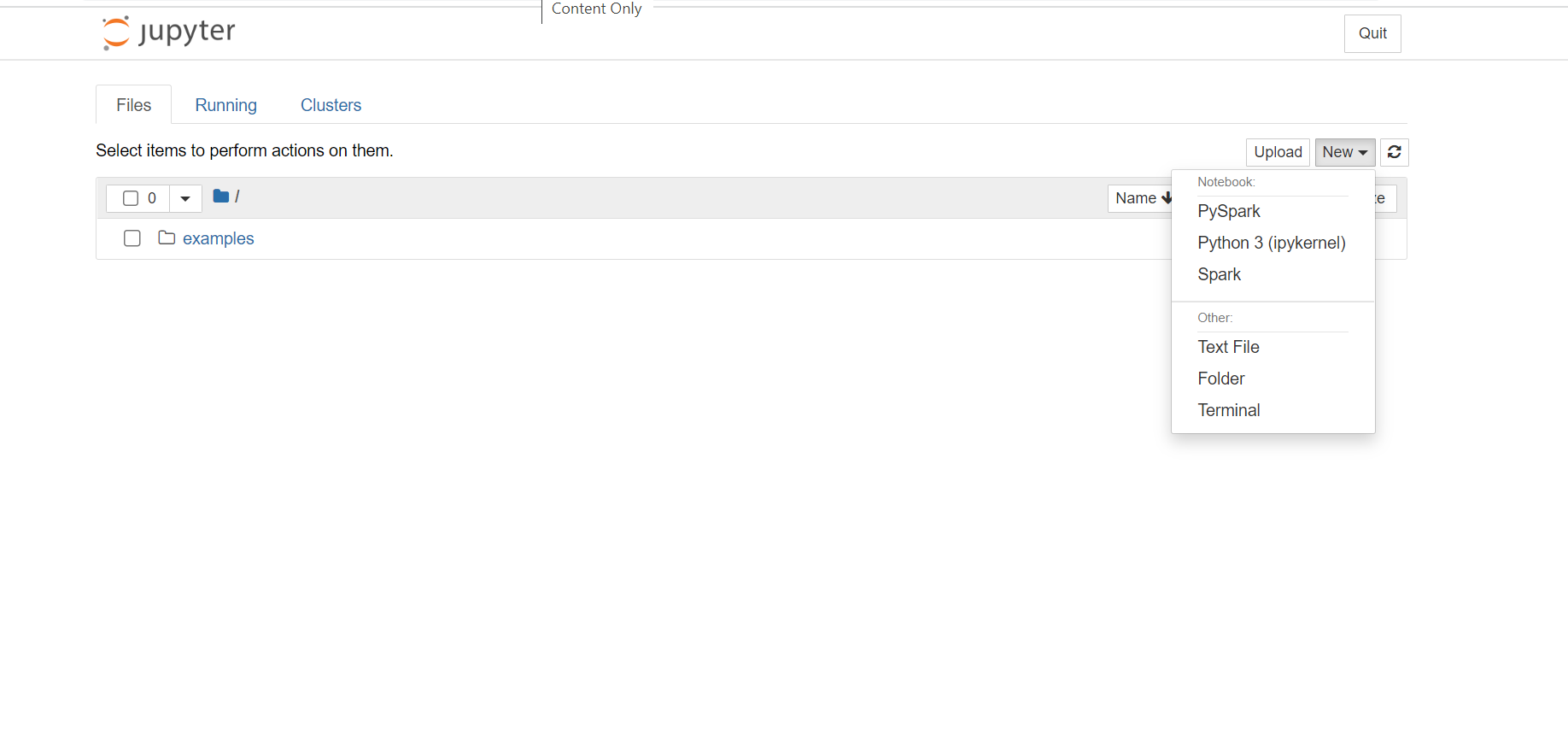
- 在 Jupyter Notebook 的右上角,依次单击“新建”、“Spark”,以便创建 Scala 笔记本。 HDInsight Spark 群集上的 Jupyter Notebook 还提供适用于 Python2 应用程序的 PySpark 内核,以及适用于 Python3 应用程序的 PySpark3 内核。 本文将会创建 Scala 笔记本。
有关内核的详细信息,请参阅将 Jupyter Notebook 内核与 HDInsight 中的 Apache Spark 群集配合使用。
注意
本文使用 Spark (Scala) 内核,因为目前只有 Scala 和 Java 才支持将数据从 Spark 流式传输到 SQL 数据库。 尽管可以使用 Python 在 SQL中 读取和写入数据,但为了保持一致,本文将使用 Scala 执行所有三个操作。
将打开默认名称为“无标题”的新笔记本。 单击笔记本名称,然后输入所选的名称。
现在可以开始创建应用程序。
从 Azure SQL 数据库读取数据
在本部分,我们要从 AdventureWorks 数据库中的某个表(例如 SalesLT.Address)读取数据。
在新的 Jupyter Notebook 的代码单元中,粘贴以下代码片段,并将占位符值替换为数据库的值。
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.chinacloudapi.cn val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"按 SHIFT + ENTER 运行代码单元。
使用以下代码片段生成可传递给 Spark 数据帧 API 的 JDBC URL。 此代码创建一个
Properties对象来保存参数。 粘贴代码单元中的代码片段,然后按 SHIFT + ENTER 运行。import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.chinacloudapi.cn;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")使用以下代码片段创建一个数据帧,其中包含数据库内某个表中的数据。 此代码片段使用 AdventureWorksLT 数据库中包含的
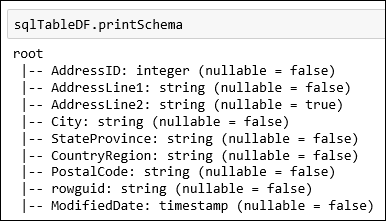
SalesLT.Address表。 粘贴代码单元中的代码片段,然后按 SHIFT + ENTER 运行。val sqlTableDF = spark.read.jdbc(jdbc_url, "SalesLT.Address", connectionProperties)现在,可以对数据帧执行操作,例如,获取数据架构:
sqlTableDF.printSchema会显示如下图所示的输出:
还可以执行其他操作,例如检索前 10 行。
sqlTableDF.show(10)或者,从数据集检索特定的列。
sqlTableDF.select("AddressLine1", "City").show(10)
将数据写入 Azure SQL 数据库
在本部分,我们使用群集上的示例 CSV 文件在数据库中创建一个表,并在其中填充数据。 该示例 CSV 文件 (HVAC.csv) 已在所有 HDInsight 群集上提供,路径为 HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv。
在新的 Jupyter Notebook 的代码单元中,粘贴以下代码片段,并将占位符值替换为数据库的值。
// Declare the values for your database val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.chinacloudapi.cn val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>"按 SHIFT + ENTER 运行代码单元。
以下代码片段生成可传递给 Spark 数据帧 API 的 JDBC URL。 此代码创建一个
Properties对象来保存参数。 粘贴代码单元中的代码片段,然后按 SHIFT + ENTER 运行。import java.util.Properties val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.chinacloudapi.cn;loginTimeout=60;" val connectionProperties = new Properties() connectionProperties.put("user", s"${jdbcUsername}") connectionProperties.put("password", s"${jdbcPassword}")使用以下代码片段提取 HVAC.csv 中的数据架构,并使用该架构将 CSV 中的数据载入数据帧
readDf。 粘贴代码单元中的代码片段,然后按 SHIFT + ENTER 运行。val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readDf = spark.read.format("csv").schema(userSchema).load("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv")使用
readDf数据帧创建临时表temphvactable。 然后使用该临时表创建 Hive 表hvactable_hive。readDf.createOrReplaceTempView("temphvactable") spark.sql("create table hvactable_hive as select * from temphvactable")最后,使用该 Hive 表在数据库中创建一个表。 以下代码片段在 Azure SQL 数据库中创建
hvactable。spark.table("hvactable_hive").write.jdbc(jdbc_url, "hvactable", connectionProperties)使用 SSMS 连接到 Azure SQL 数据库,并确认其中是否显示了
dbo.hvactable。a. 启动 SSMS,然后提供以下屏幕截图中所示的连接详细信息,以连接到 Azure SQL 数据库。
b. 在对象资源管理器中,展开数据库和表节点,查看创建的 dbo.hvactable 。
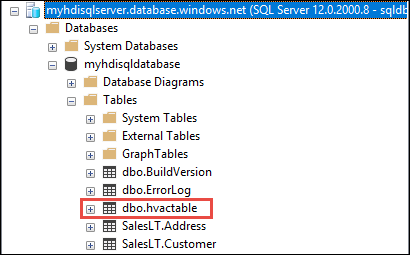
在 SSMS 中运行查询以查看表中的列。
SELECT * from hvactable
将数据流式传输到 Azure SQL 数据库
在本部分,我们要将数据流式传输到上一部分已创建的 hvactable。
首先,请确保
hvactable中没有记录。 使用 SSMS 针对该表运行以下查询。TRUNCATE TABLE [dbo].[hvactable]在 HDInsight Spark 群集上创建一个新的 Jupyter Notebook。 在代码单元中粘贴以下代码片段,然后按 SHIFT + ENTER:
import org.apache.spark.sql._ import org.apache.spark.sql.types._ import org.apache.spark.sql.functions._ import org.apache.spark.sql.streaming._ import java.sql.{Connection,DriverManager,ResultSet}我们要将数据从 HVAC.csv 流式传输到
hvactable。 HVAC.csv 文件已在群集上提供,其路径为/HdiSamples/HdiSamples/SensorSampleData/HVAC/。 在以下代码片段中,我们先获取要流式传输的数据的架构。 然后,使用该架构创建流数据帧。 粘贴代码单元中的代码片段,然后按 SHIFT + ENTER 运行。val userSchema = spark.read.option("header", "true").csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv").schema val readStreamDf = spark.readStream.schema(userSchema).csv("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/") readStreamDf.printSchema输出显示 HVAC.csv 的架构。
hvactable也有相同的架构。 输出列出表中的列。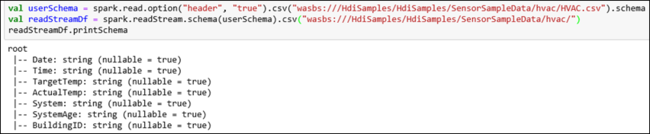
最后,使用以下代码片段从 HVAC.csv 读取数据,并将其流式传输到数据库中的
hvactable。 在代码单元中粘贴该代码片段,并将占位符值替换为数据库的值,然后按 Shift+Enter 运行。val WriteToSQLQuery = readStreamDf.writeStream.foreach(new ForeachWriter[Row] { var connection:java.sql.Connection = _ var statement:java.sql.Statement = _ val jdbcUsername = "<SQL DB ADMIN USER>" val jdbcPassword = "<SQL DB ADMIN PWD>" val jdbcHostname = "<SQL SERVER NAME HOSTING SDL DB>" //typically, this is in the form or servername.database.chinacloudapi.cn val jdbcPort = 1433 val jdbcDatabase ="<AZURE SQL DB NAME>" val driver = "com.microsoft.sqlserver.jdbc.SQLServerDriver" val jdbc_url = s"jdbc:sqlserver://${jdbcHostname}:${jdbcPort};database=${jdbcDatabase};encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.chinacloudapi.cn;loginTimeout=30;" def open(partitionId: Long, version: Long):Boolean = { Class.forName(driver) connection = DriverManager.getConnection(jdbc_url, jdbcUsername, jdbcPassword) statement = connection.createStatement true } def process(value: Row): Unit = { val Date = value(0) val Time = value(1) val TargetTemp = value(2) val ActualTemp = value(3) val System = value(4) val SystemAge = value(5) val BuildingID = value(6) val valueStr = "'" + Date + "'," + "'" + Time + "'," + "'" + TargetTemp + "'," + "'" + ActualTemp + "'," + "'" + System + "'," + "'" + SystemAge + "'," + "'" + BuildingID + "'" statement.execute("INSERT INTO " + "dbo.hvactable" + " VALUES (" + valueStr + ")") } def close(errorOrNull: Throwable): Unit = { connection.close } }) var streamingQuery = WriteToSQLQuery.start()通过在 SQL Server Management Studio (SSMS) 中运行以下查询,验证数据是否正在流式传输到
hvactable。 每次运行该查询时,它都会显示表中的行数已递增。SELECT COUNT(*) FROM hvactable