在本快速入门中,你将使用 Bicep 在 Azure HDInsight 中创建 Apache Spark 群集。 然后,你将创建一个 Jupyter Notebook 文件,并使用它针对 Apache Hive 表运行 Spark SQL 查询。 Azure HDInsight 是适用于企业的分析服务,具有托管、全面且开源的特点。 用于 HDInsight 的 Apache Spark 框架使用内存中处理功能实现快速数据分析和群集计算。 使用 Jupyter Notebook,可以与数据进行交互、将代码和 Markdown 文本结合使用,以及进行简单的可视化。
如果将多个群集一起使用,则需创建一个虚拟网络;如果使用的是 Spark 群集,则还需使用 Hive Warehouse Connector。 有关详细信息,请参阅为 Azure HDInsight 规划虚拟网络和将 Apache Spark 和 Apache Hive 与 Hive Warehouse Connector 集成。
Bicep 是一种特定于域的语言 (DSL),使用声明性语法来部署 Azure 资源。 它提供简明的语法、可靠的类型安全性以及对代码重用的支持。 Bicep 会针对你的 Azure 基础结构即代码解决方案提供最佳创作体验。
先决条件
如果没有 Azure 订阅,请在开始前创建试用版订阅。
查阅 Bicep 文件
本快速入门中使用的 Bicep 文件来自 Azure 快速入门模板。
@description('The name of the HDInsight cluster to create.')
param clusterName string
@description('These credentials can be used to submit jobs to the cluster and to log into cluster dashboards. The username must consist of digits, upper or lowercase letters, and/or the following special characters: (!#$%&\'()-^_`{}~).')
@minLength(2)
@maxLength(20)
param clusterLoginUserName string
@description('The password must be at least 10 characters in length and must contain at least one digit, one upper case letter, one lower case letter, and one non-alphanumeric character except (single-quote, double-quote, backslash, right-bracket, full-stop). Also, the password must not contain 3 consecutive characters from the cluster username or SSH username.')
@minLength(10)
@secure()
param clusterLoginPassword string
@description('These credentials can be used to remotely access the cluster. The sshUserName can only consit of digits, upper or lowercase letters, and/or the following special characters (%&\'^_`{}~). Also, it cannot be the same as the cluster login username or a reserved word')
@minLength(2)
param sshUserName string
@description('SSH password must be 6-72 characters long and must contain at least one digit, one upper case letter, and one lower case letter. It must not contain any 3 consecutive characters from the cluster login name')
@minLength(6)
@maxLength(72)
@secure()
param sshPassword string
@description('Location for all resources.')
param location string = resourceGroup().location
@description('This is the headnode Azure Virtual Machine size, and will affect the cost. If you don\'t know, just leave the default value.')
@allowed([
'Standard_A4_v2'
'Standard_A8_v2'
'Standard_E2_v3'
'Standard_E4_v3'
'Standard_E8_v3'
'Standard_E16_v3'
'Standard_E20_v3'
'Standard_E32_v3'
'Standard_E48_v3'
])
param headNodeVirtualMachineSize string = 'Standard_E8_v3'
@description('This is the workernode Azure Virtual Machine size, and will affect the cost. If you don\'t know, just leave the default value.')
@allowed([
'Standard_A4_v2'
'Standard_A8_v2'
'Standard_E2_v3'
'Standard_E4_v3'
'Standard_E8_v3'
'Standard_E16_v3'
'Standard_E20_v3'
'Standard_E32_v3'
'Standard_E48_v3'
])
param workerNodeVirtualMachineSize string = 'Standard_E8_v3'
resource defaultStorageAccount 'Microsoft.Storage/storageAccounts@2021-04-01' = {
name: 'storage${uniqueString(resourceGroup().id)}'
location: location
sku: {
name: 'Standard_LRS'
}
kind: 'StorageV2'
}
resource cluster 'Microsoft.HDInsight/clusters@2018-06-01-preview' = {
name: clusterName
location: location
properties: {
clusterVersion: '4.0'
osType: 'Linux'
tier: 'Standard'
clusterDefinition: {
kind: 'spark'
configurations: {
gateway: {
'restAuthCredential.isEnabled': true
'restAuthCredential.username': clusterLoginUserName
'restAuthCredential.password': clusterLoginPassword
}
}
}
storageProfile: {
storageaccounts: [
{
name: replace(replace(defaultStorageAccount.properties.primaryEndpoints.blob, 'https://', ''), '/', '')
isDefault: true
container: clusterName
key: defaultStorageAccount.listKeys('2021-04-01').keys[0].value
}
]
}
computeProfile: {
roles: [
{
name: 'headnode'
targetInstanceCount: 2
hardwareProfile: {
vmSize: headNodeVirtualMachineSize
}
osProfile: {
linuxOperatingSystemProfile: {
username: sshUserName
password: sshPassword
}
}
}
{
name: 'workernode'
targetInstanceCount: 2
hardwareProfile: {
vmSize: workerNodeVirtualMachineSize
}
osProfile: {
linuxOperatingSystemProfile: {
username: sshUserName
password: sshPassword
}
}
}
]
}
}
}
output storage object = defaultStorageAccount.properties
output cluster object = cluster.properties
该 Bicep 文件中定义了两个 Azure 资源:
- Microsoft.Storage/storageAccounts:创建 Azure 存储帐户。
- Microsoft.HDInsight/cluster:创建 HDInsight 群集。
部署 Bicep 文件
将该 Bicep 文件另存为本地计算机上的 main.bicep。
使用 Azure CLI 或 Azure PowerShell 来部署该 Bicep 文件。
az group create --name exampleRG --location chinaeast az deployment group create --resource-group exampleRG --template-file main.bicep --parameters clusterName=<cluster-name> clusterLoginUserName=<cluster-username> sshUserName=<ssh-username>需要提供参数的值:
- 将 <cluster-name> 替换为要创建的 HDInsight 群集的名称。
- 将 <cluster-username> 替换为用于向群集提交作业以及登录到群集仪表板的凭据。 用户名的最小长度为 2 个字符,最大长度为 20 个字符。 它必须包含数字、大写字母或小写字母,和/或以下特殊字符:(!#$%&'()-^_`{}~).')。
- 将 <ssh-username> 替换为用于远程访问群集的凭据。 用户名的长度至少为两个字符。 它必须包含数字、大写字母或小写字母,和/或以下特殊字符:(%&'^_`{}~)。 不能与群集用户名相同。
系统将提示你输入以下信息:
- clusterLoginPassword,长度必须至少为 10 个字符,必须至少包含一个数字、一个大写字母、一个小写字母和一个非字母数字字符,但不能包含单引号、双引号、反斜杠、右括号和句号。 此外,不能包含群集用户名或 SSH 用户名中的三个连续字符。
- sshPassword,长度必须为 6-72 个字符,必须至少包含一个数字、一个大写字母和一个小写字母。 不能包含群集登录名中的任意三个连续字符。
注意
部署完成后,应会看到一条指出部署成功的消息。
如果在创建 HDInsight 群集时遇到问题,可能是因为你没有这样做的适当权限。 有关详细信息,请参阅访问控制要求。
查看已部署的资源
使用 Azure 门户、Azure CLI 或 Azure PowerShell 列出资源组中已部署的资源。
az resource list --resource-group exampleRG
创建 Jupyter Notebook 文件
Jupyter Notebook 是支持各种编程语言的交互式笔记本环境。 可以使用 Jupyter Notebook 文件与数据交互,将代码和 Markdown 文本相结合,并执行简单的可视化操作。
打开 Azure 门户。
选择“HDInsight 群集”,然后选择所创建的群集。
在门户的“群集仪表板”部分中,选择“Jupyter Notebook”。 出现提示时,请输入群集的群集登录凭据。
选择“新建”>“PySpark”,创建笔记本 。
新笔记本随即已创建,并以 Untitled(Untitled.pynb) 名称打开。
运行 Apache Spark SQL 语句
SQL(结构化查询语言)是用于查询和转换数据的最常见、最广泛使用的语言。 Spark SQL 作为 Apache Spark 的扩展使用,可使用熟悉的 SQL 语法处理结构化数据。
验证 kernel 已就绪。 如果在 Notebook 中的内核名称旁边看到空心圆,则内核已准备就绪。 实心圆表示内核正忙。

首次启动 Notebook 时,内核在后台执行一些任务。 等待内核准备就绪。
将以下代码粘贴到一个空单元格中,然后按 SHIFT + ENTER 来运行这些代码。 此命令列出群集上的 Hive 表:
%%sql SHOW TABLES将 Jupyter Notebook 文件与 HDInsight 群集配合使用时,会获得一个预设
spark会话,可以使用它通过 Spark SQL 来运行 Hive 查询。%%sql指示 Jupyter Notebook 使用预设spark会话运行 Hive 查询。 该查询从默认情况下所有 HDInsight 群集都带有的 Hive 表 (hivesampletable) 检索前 10 行。 第一次提交查询时,Jupyter 将为笔记本创建 Spark 应用程序。 该操作需要大约 30 秒才能完成。 Spark 应用程序准备就绪后,查询将在大约一秒钟内执行并生成结果。 输出如下所示: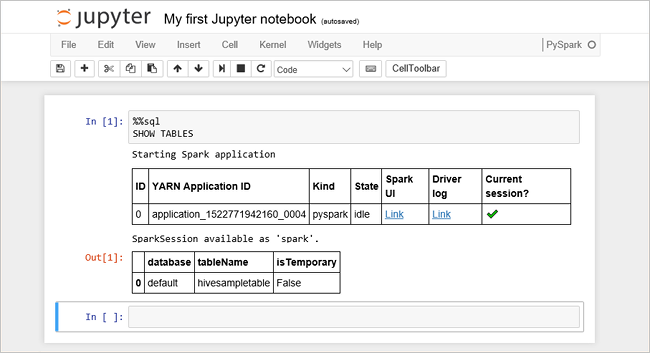
每次在 Jupyter 中运行查询时,Web 浏览器窗口标题中都会显示“(繁忙)”状态和 Notebook 标题。 右上角“PySpark” 文本的旁边还会出现一个实心圆。
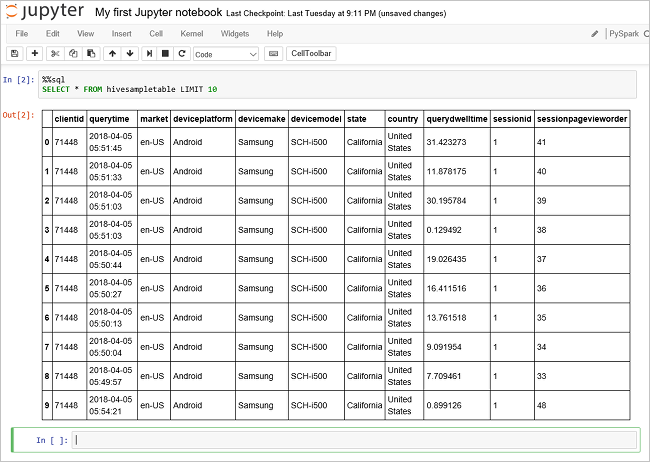
运行另一个查询,请查看
hivesampletable中的数据。%%sql SELECT * FROM hivesampletable LIMIT 10屏幕在刷新后会显示查询输出。
请在 Notebook 的“文件”菜单中选择“关闭并停止” 。 关闭笔记本会释放群集资源,包括 Spark 应用程序。
清理资源
如果不再需要资源组及其资源,请使用 Azure 门户、Azure CLI 或 Azure PowerShell 将其删除。
az group delete --name exampleRG
后续步骤
在本快速入门中,你已了解如何在 HDInsight 中创建 Apache Spark 群集并运行基本的 Spark SQL 查询。 转到下一教程,了解如何使用 HDInsight 群集针对示例数据运行交互式查询。