在搜索解决方案中,具有复杂模式或特殊字符的字符串可能很难使用,因为 默认分析器 去除或误解了模式有意义的部分。 这会导致用户找不到所需的信息,这会导致搜索体验不佳。 电话号码是难以分析的字符串的经典示例。 它们采用各种格式,并包含默认分析器忽略的特殊字符。
本教程使用 搜索服务 REST API 通过电话号码作为主题来解决 使用自定义分析器的模式数据问题。 此方法可直接用于电话号码,并适用于具有相同特征的字段,例如采用特殊字符格式的 URL、电子邮件、邮政编码和日期。
在本教程中,你将:
- 了解问题
- 开发用于处理电话号码的初始自定义分析器
- 测试自定义分析器
- 反复修改自定义分析器设计来进一步改进结果
先决条件
具有活动订阅的Azure帐户。 创建试用版订阅。
下载文件
本教程的源代码位于 custom-analyzer.rest 文件中,位于 Azure-Samples/azure-search-rest-samples 的 GitHub 存储库中。
复制管理员密钥和 URL
本教程中的 REST 调用需要搜索服务终结点和管理员 API 密钥。 可以从Azure门户获取这些值。
在 Azure 门户中,转到你的搜索服务。
在左窗格中,选择“ 概述 ”并复制终结点。 它应采用以下格式:
https://my-service.search.azure.cn在左窗格中,选择“设置>”,并复制管理密钥以获取服务的完整权限。 有两个可交换的管理员密钥,为保证业务连续性而提供,以防需要滚动一个密钥。 可以对请求使用任一键来添加、修改或删除对象。
Azure 门户中 URL 和 API 密钥的截屏.
创建初始索引
在Visual Studio Code中打开新的文本文件。
将变量设置为在上一部分中收集的搜索终结点和 API 密钥。
@baseUrl = PUT-YOUR-SEARCH-SERVICE-URL-HERE @apiKey = PUT-YOUR-ADMIN-API-KEY-HERE使用
.rest文件扩展名保存文件。粘贴以下示例以创建一个包含两个字段的
phone-numbers-index小型索引:id和phone_number。### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false } ] }尚未定义分析器,因此默认使用
standard.lucene分析器。选择“发送请求”。 应具有
HTTP/1.1 201 Created响应,响应正文应包含索引架构的 JSON 表示形式。使用包含各种电话号码格式的文档将数据加载到索引中。 这是测试数据。
### Load documents POST {{baseUrl}}/indexes/phone-numbers-index/docs/index?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "value": [ { "@search.action": "upload", "id": "1", "phone_number": "425-555-0100" }, { "@search.action": "upload", "id": "2", "phone_number": "(321) 555-0199" }, { "@search.action": "upload", "id": "3", "phone_number": "+1 425-555-0100" }, { "@search.action": "upload", "id": "4", "phone_number": "+1 (321) 555-0199" }, { "@search.action": "upload", "id": "5", "phone_number": "4255550100" }, { "@search.action": "upload", "id": "6", "phone_number": "13215550199" }, { "@search.action": "upload", "id": "7", "phone_number": "425 555 0100" }, { "@search.action": "upload", "id": "8", "phone_number": "321.555.0199" } ] }尝试查询类似于用户可能输入的内容。 例如,用户可能搜索
(425) 555-0100任意数量的格式,但仍希望返回结果。 首先搜索(425) 555-0100。### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "(425) 555-0100" }查询返回四个预期结果中的三个,但也返回两个意外结果。
{ "value": [ { "@search.score": 0.05634898, "phone_number": "+1 425-555-0100" }, { "@search.score": 0.05634898, "phone_number": "425 555 0100" }, { "@search.score": 0.05634898, "phone_number": "425-555-0100" }, { "@search.score": 0.020766128, "phone_number": "(321) 555-0199" }, { "@search.score": 0.020766128, "phone_number": "+1 (321) 555-0199" } ] }在没有任何格式的情况下重试:
4255550100### Search for a phone number POST {{baseUrl}}/indexes/phone-numbers-index/docs/search?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "search": "4255550100" }此查询更糟,只返回四个正确匹配项中的一个。
{ "value": [ { "@search.score": 0.6015292, "phone_number": "4255550100" } ] }
看到这些结果让人困惑,这种感觉不止你一个人有。 下一部分说明为何获得这些结果。
查看分析器的工作方式
若要理解这些搜索结果,必须了解分析器正在执行的操作。 在此处,可以使用 分析 API 测试默认分析器,从而为设计更符合需求的分析器提供了基础。
分析器是全文搜索引擎的一个组件,负责处理查询字符串和索引文档中的文本。 不同的分析器根据具体的方案以不同的方式处理文本。 对于此场景,我们需要构建一个专为电话号码定制的分析器。
分析器包含三个组件:
- 字符筛选器,用于从输入文本中删除或替换单个字符。
- 一个将输入文本分解为令牌的 分词器,这些令牌将成为搜索索引中的键。
- 标记筛选器,用于处理 tokenizer 生成的标记。
下图显示了这三个组件如何协同工作来标记句子。
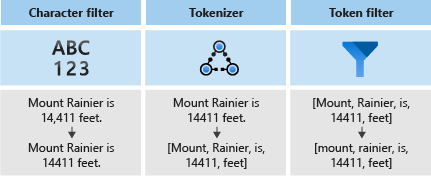
这些标记随后被存储在倒排索引中,以便进行快速的全文搜索。 倒排索引通过将在词法分析过程中提取的所有唯一词映射到它们所在的文档来实现全文搜索。 可以在下图中看到一个示例:

所有搜索均可归结为搜索存储在倒排索引中的字词。 用户发出查询时:
- 将查询解析后再分析查询词。
- 倒排索引被扫描,以搜索包含匹配字词的文档。
- 评分算法对检索的文档进行排名。
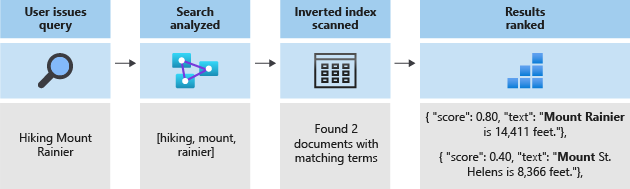
如果查询词与倒排索引中的词不匹配,则不会返回结果。 若要详细了解查询的工作原理,请参阅 Azure AI Search 中的全文搜索。
注意
对于此规则,部分字词查询是一个重要的例外情况。 与常规术语查询不同,这些查询(前缀查询、通配符查询和正则表达式查询)绕过词法分析过程。 部分字词在与索引中的字词匹配之前只使用小写。 如果未将分析器配置为支持这些类型的查询,则通常会收到意外的结果,因为索引中不存在匹配的字词。
使用分析 API 来测试分析器
Azure AI Search提供了一个 Analyze API,可用于测试分析器以了解如何处理文本。
使用以下请求调用分析 API:
### Test analyzer
POST {{baseUrl}}/indexes/phone-numbers-index/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "(425) 555-0100",
"analyzer": "standard.lucene"
}
API 使用指定的分析器返回从文本中提取的标记。 标准 Lucene 分析器将电话号码拆分为三个单独的令牌。
{
"tokens": [
{
"token": "425",
"startOffset": 1,
"endOffset": 4,
"position": 0
},
{
"token": "555",
"startOffset": 6,
"endOffset": 9,
"position": 1
},
{
"token": "0100",
"startOffset": 10,
"endOffset": 14,
"position": 2
}
]
}
相反,格式化为没有任何标点符号的电话号码 4255550100 被切分为单个标记。
{
"text": "4255550100",
"analyzer": "standard.lucene"
}
响应:
{
"tokens": [
{
"token": "4255550100",
"startOffset": 0,
"endOffset": 10,
"position": 0
}
]
}
请记住,查询词和索引文档都要进行分析。 回想上一步的搜索结果,可以开始了解返回这些结果的原因。
在第一个查询中,返回了意外的电话号码,因为其中一个标记 555 与你搜索的一个词匹配。 在第二个查询中,只返回一个数字,因为它是唯一具有标记匹配 4255550100的记录。
生成自定义分析器
了解所看到的结果后,请生成一个自定义分析器来改进令牌化逻辑。
目的是提供对电话号码的直观搜索,无论查询或索引字符串采用哪种格式。 若要实现此结果,请指定 字符筛选器、 tokenizer 和 标记筛选器。
字符筛选器
字符筛选器在将文本馈送到 tokenizer 之前对其进行处理。 字符筛选器的常见用途是筛选掉 HTML 元素并替换特殊字符。
对于电话号码,需要删除空格和特殊字符,因为并非所有电话号码格式都包含相同的特殊字符和空格。
"charFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.MappingCharFilter",
"name": "phone_char_mapping",
"mappings": [
"-=>",
"(=>",
")=>",
"+=>",
".=>",
"\\u0020=>"
]
}
]
筛选器从输入中删除 -()+. 和空格。
| 输入 | 输出 |
|---|---|
(321) 555-0199 |
3215550199 |
321.555.0199 |
3215550199 |
Tokenizers
Tokenizer 将文本拆分为标记,并在此过程中丢弃某些字符,如标点符号。 在许多情况下,分词的目标是将句子拆分为单个单词。
对于此场景,我们使用关键字 tokenizer keyword_v2 将电话号码捕获为单个词。 这不是解决此问题的唯一方法,如 “备用方法 ”部分中所述。
关键字标记器始终将输入的文本作为单个术语输出。
| 输入 | 输出 |
|---|---|
The dog swims. |
[The dog swims.] |
3215550199 |
[3215550199] |
标记筛选器
令牌筛选器修改或筛选掉 tokenizer 生成的令牌。 标记筛选器的一种常见用法是使用小写标记筛选器将所有字符小写。 另一种常见用途是筛选出 停用词,例如 the,and或 is。
虽然不需要为此方案使用任一筛选器,但请使用 nGram 令牌筛选器来允许对电话号码进行部分搜索。
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2",
"name": "custom_ngram_filter",
"minGram": 3,
"maxGram": 20
}
]
NGramTokenFilterV2
nGram_v2 标记筛选器根据 minGram 和 maxGram 参数将标记拆分为给定大小的 n 元语法。
对于手机分析器,由于用户预计会搜索的子字符串最短,因此将 minGram 设置为 3。
maxGram 被设置为 20 以确保所有电话号码,即便带有分机号,也能被包含在单个 n 元语法中。
令人遗憾的是,n 元语法的副作用是会返回一些误报。 你将在稍后的步骤中解决此问题,方法是为不包含 n 元语法标记筛选器的搜索构建一个单独的分析器。
| 输入 | 输出 |
|---|---|
[12345] |
[123, 1234, 12345, 234, 2345, 345] |
[3215550199] |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
分析器
有了字符筛选器、tokenizer 和标记筛选器,就可以定义分析器了。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer",
"tokenizer": "keyword_v2",
"tokenFilters": [
"custom_ngram_filter"
],
"charFilters": [
"phone_char_mapping"
]
}
]
根据分析 API,根据以下输入,自定义分析器的输出如下所示:
| 输入 | 输出 |
|---|---|
12345 |
[123, 1234, 12345, 234, 2345, 345] |
(321) 555-0199 |
[321, 3215, 32155, 321555, 3215550, 32155501, 321555019, 3215550199, 215, 2155, 21555, 215550, ... ] |
输出列中的所有标记都存在于索引中。 如果查询包含上述任何术语,则返回电话号码。
使用新分析器重新生成
删除当前索引。
### Delete the index DELETE {{baseUrl}}/indexes/phone-numbers-index?api-version=2026-04-01 HTTP/1.1 api-key: {{apiKey}}使用新的分析器重新创建索引。 此索引架构在电话号码字段中添加自定义分析器定义和自定义分析器分配。
### Create a new index POST {{baseUrl}}/indexes?api-version=2026-04-01 HTTP/1.1 Content-Type: application/json api-key: {{apiKey}} { "name": "phone-numbers-index-2", "fields": [ { "name": "id", "type": "Edm.String", "key": true, "searchable": true, "filterable": false, "facetable": false, "sortable": true }, { "name": "phone_number", "type": "Edm.String", "sortable": false, "searchable": true, "filterable": false, "facetable": false, "analyzer": "phone_analyzer" } ], "analyzers": [ { "@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer", "name": "phone_analyzer", "tokenizer": "keyword_v2", "tokenFilters": [ "custom_ngram_filter" ], "charFilters": [ "phone_char_mapping" ] } ], "charFilters": [ { "@odata.type": "#Microsoft.Azure.Search.MappingCharFilter", "name": "phone_char_mapping", "mappings": [ "-=>", "(=>", ")=>", "+=>", ".=>", "\\u0020=>" ] } ], "tokenFilters": [ { "@odata.type": "#Microsoft.Azure.Search.NGramTokenFilterV2", "name": "custom_ngram_filter", "minGram": 3, "maxGram": 20 } ] }
测试自定义分析器
重新创建索引后,使用以下请求测试分析器:
### Test custom analyzer
POST {{baseUrl}}/indexes/phone-numbers-index-2/analyze?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"text": "+1 (321) 555-0199",
"analyzer": "phone_analyzer"
}
现在,应该会看到由电话号码生成的标记集合。
{
"tokens": [
{
"token": "132",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "1321",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
{
"token": "13215",
"startOffset": 1,
"endOffset": 17,
"position": 0
},
...
...
...
]
}
修改自定义分析器以处理误报问题
使用自定义分析器针对索引进行示例查询后,应会看到召回已改进,现在返回所有匹配的电话号码。 但是,n 元语法标记筛选器也会返回一些误报。 这是 n 元语法标记筛选器的常见副作用。
若要防止误报,请创建单独的分析器进行查询。 此分析器与上一个分析器相同,只不过它省略了 custom_ngram_filter。
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_search",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [],
"charFilters": [
"phone_char_mapping"
]
}
在索引定义中,同时指定 indexAnalyzer 和 searchAnalyzer。
{
"name": "phone_number",
"type": "Edm.String",
"sortable": false,
"searchable": true,
"filterable": false,
"facetable": false,
"indexAnalyzer": "phone_analyzer",
"searchAnalyzer": "phone_analyzer_search"
}
进行该更改后,一切准备就绪。 后续步骤如下:
删除索引。
添加新的自定义分析器(
phone_analyzer-search)并将该分析phone-number器分配给字段searchAnalyzer的属性后,重新创建索引。重新加载数据。
重新测试查询以验证搜索是否按预期工作。 如果使用示例文件,此步骤将创建名为
phone-number-index-3的第三个索引。
备用方法
上一部分所述的分析器旨在最大程度地提高搜索的灵活性。 但这样做的代价是,在索引中存储许多可能无关紧要的字词。
以下示例演示了一个替代分析器,该分析器在令牌化方面效率更高,但它有缺点。
给定 14255550100 的输入,分析器无法以逻辑方式对电话号码进行分块。 例如,它无法将国家/地区代码 1 与区号 425 分开。 如果用户在其搜索中不包含国家/地区代码,则这一差异会导致不返回电话号码。
"analyzers": [
{
"@odata.type": "#Microsoft.Azure.Search.CustomAnalyzer",
"name": "phone_analyzer_shingles",
"tokenizer": "custom_tokenizer_phone",
"tokenFilters": [
"custom_shingle_filter"
]
}
],
"tokenizers": [
{
"@odata.type": "#Microsoft.Azure.Search.StandardTokenizerV2",
"name": "custom_tokenizer_phone",
"maxTokenLength": 4
}
],
"tokenFilters": [
{
"@odata.type": "#Microsoft.Azure.Search.ShingleTokenFilter",
"name": "custom_shingle_filter",
"minShingleSize": 2,
"maxShingleSize": 6,
"tokenSeparator": ""
}
]
在以下示例中,电话号码被拆分为通常希望用户搜索的区块。
| 输入 | 输出 |
|---|---|
(321) 555-0199 |
[321, 555, 0199, 321555, 5550199, 3215550199] |
根据你的需求,这可能是解决问题的更有效的方法。
要点
本教程演示了生成和测试自定义分析器的过程。 你已创建了索引、为数据编制了索引,然后针对索引进行了查询以查看返回的搜索结果。 然后,你使用了分析 API 来查看实际的词法分析过程。
本教程中定义的分析器为搜索电话号码提供了一种简单的解决方案,但可以使用这个相同的过程来为共享类似特征的任何场景构建自定义分析器。
清理资源
在操作您自己的订阅服务时,最好在项目结束时删除其中不再需要的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
可以使用左侧导航窗格中的“所有资源”或“资源组”链接在Azure门户中查找和管理资源。
后续步骤
了解如何创建自定义分析器后,请查看可用于生成丰富搜索体验的各种筛选器、标记化器和分析器: