本文介绍Azure Stream Analytics中的兼容性级别选项。
流分析是一个托管服务,它会定期进行功能更新和持续进行性能改进。 该服务的大多数运行时更新会自动提供给最终用户,独立于兼容性级别。 但是,当新功能在现有作业的行为中引入更改,或在运行作业中使用数据的方式中引入更改时,我们将在新的兼容性级别下引入此更改。 可以通过降低兼容性级别设置,使现有流分析作业保持运行状态而不会发生重大更改。 如果已准备使用最新的运行时行为,可以选择提高兼容性级别。
选择兼容性级别
兼容性级别控制流分析作业的运行时行为。
Azure Stream Analytics目前支持三个兼容级别:
- 1.2 - 最新行为和最新改进
- 1.1 - 以前的行为
- 1.0 - 几年前正式发布Azure Stream Analytics期间引入的原始兼容级别。
创建新的流分析作业时,最佳做法是使用最新的兼容性级别来创建它。 依赖于最新的行为着手作业设计,以免将来添加更改和增大复杂性。
设置兼容性级别
可以在Azure门户中或使用 创建作业 REST API 调用来设置流分析作业的兼容性级别。
若要在Azure门户中更新作业的兼容性级别,请执行以下操作:
- 使用 Azure 门户定位到您的流分析作业。
- 停止该作业,然后更新兼容性级别。 如果作业处于运行状态,则无法更新兼容性级别。
- 在“配置”标题下,选择“兼容性级别”。
- 选择所需的兼容性级别值。
- 选择页面底部的“保存” 。
Azure 门户中的 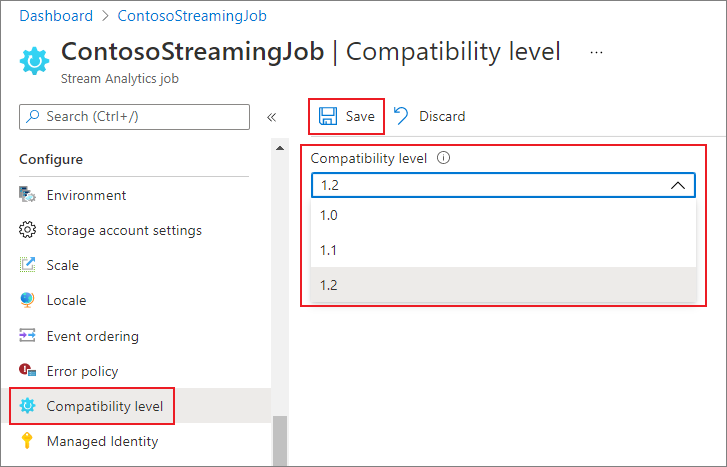
在更新兼容性级别时,T 编译器会使用与所选兼容性级别相对应的语法来验证作业。
兼容性级别 1.2
在兼容性级别 1.2 中引入了以下重大更改:
AMQP 消息传递协议
1.2 级别:Azure Stream Analytics 使用 高级消息队列协议(AMQP)消息传送协议写入服务总线队列和主题。 通过 AMQP 可使用开放标准协议构建跨平台的混合应用程序。
地理空间函数
以前的级别: Azure Stream Analytics 使用地理计算。
1.2 level: Azure Stream Analytics可用于计算几何投影地理坐标。 地理空间函数的签名没有变化。 但是,其语义略有不同,与以往相比可以提高计算精度。
Azure Stream Analytics支持地理空间引用数据索引。 可为包含地理空间元素的参考数据编制索引,以加快联接计算的速度。
更新的地理空间函数提供已知文本 (WKT) 地理空间格式的完整表达能力。 可以指定以前在 GeoJson 中所不支持的其他地理空间组件。
有关详细信息,请参阅 Azure Stream Analytics – 云和 IoT Edge 中地理空间功能的更新。
针对使用多个分区的输入源的并行执行查询
先前的级别:Azure Stream Analytics 查询需要使用 PARTITION BY 子句来跨输入源分区并行化查询处理。
1.2 level: 如果查询逻辑可以跨输入源分区并行化,Azure Stream Analytics创建单独的查询实例并并行运行计算。
原生批量 API 与 Azure Cosmos DB 输出集成
以前的级别: 插入或更新行为是“插入或合并”。
1.2级:本地批量API与Azure Cosmos DB的输出集成,最大化吞吐量并有效处理限制请求。 有关详细信息,请参阅 Azure Stream Analytics 输出到 Azure Cosmos DB 页面。
插入或替换行为是“插入或替换”。
写入到 SQL 输出时的 DateTimeOffset
以前的级别:DateTimeOffset 类型已调整为 UTC。
1.2 级别: 不再调整 DateTimeOffset。
写入到 SQL 输出时的 Long
以前的级别: 根据目标类型截断值。
1.2 级别: 不符合目标类型的值将根据输出错误策略进行处理。
写入到 SQL 输出时的记录和数组序列化
以前的级别: 记录以“记录”的形式编写,数组以“数组”的形式编写。
1.2 级别: 记录和数组以 JSON 格式进行序列化。
对函数前缀进行严格验证
以前的级别: 不对函数前缀执行严格验证。
1.2 level: Azure Stream Analytics对函数前缀进行了严格的验证。 将前缀添加到内置函数会导致出错。 例如,myprefix.ABS(…) 不受支持。
将前缀添加到内置聚合也会导致出错。 例如,myprefix.SUM(…) 不受支持。
对用户定义的任何函数使用前缀“system”会导致出错。
禁止数组和对象作为Azure Cosmos DB输出适配器中的键属性
以前的级别: 支持使用数组和对象类型作为键属性。
1.2 级别: 不再支持使用数组和对象类型作为键属性。
反序列化 JSON、AVRO 和 PARQUET 中的布尔类型
先前级别: Azure Stream Analytics 将布尔值反序列化为 BIGINT 类型 - false 映射到 0,true 映射到 1。 仅当将事件显式转换为 BIT 时,输出才会在 JSON、AVRO 和 PARQUET 中创建布尔值。
例如,传递查询(例如 SELECT value INTO output1 FROM input1 从 input1 读取 JSON { "value": true })会将 JSON 值 { "value": 1 } 写入 output1 中。
1.2 level: Azure Stream Analytics将布尔值反序列化为 BIT 类型。 False 映射到 0,True 映射到 1。 传递查询(例如 SELECT value INTO output1 FROM input1 从 input1 读取 JSON { "value": true } )会将 JSON 值 { "value": true } 写入到 output1 中。 可以在查询中将值强制转换为 BIT 类型,以确保它们在支持布尔类型的格式输出中显示为 true 和 false。
兼容性级别 1.1
在兼容性级别 1.1 中引入了以下重大更改:
Service Bus XML 格式
1.0 level: Azure Stream Analytics使用了 DataContractSerializer,因此消息内容包含 XML 标记。 例如:
@\u0006string\b3http://schemas.microsoft.com/2003/10/Serialization/\u0001{ "SensorId":"1", "Temperature":64\}\u0001
1.1 级别: 消息内容只包含流,没有其他的标记。 例如: { "SensorId":"1", "Temperature":64}
对字段名称保留区分大小写
1.0 level:字段名称在Azure Stream Analytics引擎处理时更改为小写。
1.1 level:字段名称在由Azure Stream Analytics引擎处理时保留区分大小写的特性。
注意
尚不能在使用边缘环境托管的流分析作业中保持区分大小写的功能。 因此,如果在 Edge 上托管作业,所有字段名称都将转换为小写。
浮点NaN反序列化被禁用
1.0 级别:CREATE TABLE 命令不使用 NaN(非数值。例如,Infinity、-Infinity)在 FLOAT 列类型中筛选事件,因为对于这些数字来说,事件不在已记录的范围之内。
1.1 级别: CREATE TABLE 允许指定强架构。 流分析引擎验证数据是否符合此架构。 使用这一模型,该命令可以通过 NaN 值筛选事件。
对于 JSON,在入口处禁用日期/时间字符串到 DateTime 类型的自动转换
1.0 级别: JSON 分析器会在入口处将包含日期/时间/区域信息的字符串值自动转换为 DATETIME 类型,使该值立即丢失其原始格式和时区信息。 因为这是在入口处完成的,所以即使查询中没有使用该字段,它也会转换为 UTC DateTime。
1.1 级别: 没有将包含日期/时间/区域信息的字符串值自动转换为 DATETIME 类型。 因此,时区信息和原始格式保持不变。 但是,如果在查询中使用 NVARCHAR(MAX) 字段作为 DATETIME 表达式的一部分(例如 DATEADD 函数),它将被转换为 DATETIME 类型来执行计算,并且会失去其原始形式。