适用于:✔️ Linux VM ✔️ Windows VM ✔️ 灵活规模集 ✔️ 统一规模集
消息传递接口 (MPI) 是实现分布式内存并行化的开放库和事实标准。 它通常跨许多 HPC 工作负荷使用。 支持 RDMA 的 HB 系列和 N 系列虚拟机 (VM) 上的 HPC 工作负载可使用 MPI 通过低延迟和高带宽 InfiniBand 网络进行通信。
- 通过 Azure 上已启用 SR-IOV 的 VM 大小,可将几乎任何形式的 MPI 与 Mellanox OFED 配合使用。
- 在未启用 SR-IOV 的 VM 上,支持的 MPI 实现使用 Microsoft Network Direct (ND) 接口在 VM 之间通信。 因此,仅支持 Microsoft MPI (MS-MPI) 2012 R2 或更高版本以及 Intel MPI 5.x 版本。 更高版本(2017、2018)的 Intel MPI 运行时库不一定与 Azure RDMA 驱动程序兼容。
对于启用了 SR-IOV 的支持 RDMA 的 VM,适合使用 Ubuntu-HPC VM 映像。 这些 VM 映像已经过优化,并预先加载了用于 RDMA 的 OFED 驱动程序以及各种常用的 MPI 库和科学计算包,是最简单的入门方法。
尽管此处的示例适用于 RHEL,但步骤是通用的,可用于任何兼容的 Linux 操作系统,例如 Ubuntu(18.04、20.04、22.04)和 SLES(12 SP4 和 15 SP4)。 如需在其他发行版上设置其他 MPI 实现的更多示例,请查看 azhpc 映像存储库。
注意
若要在具有特定 MPI 库(例如平台 MPI)且已启用 SR-IOV 的虚拟机上运行 MPI 作业,可能需要跨租户设置分区密钥(p 键)来实现隔离和安全性。 按照发现分区密钥部分中的步骤,详细了解如何确定 p 键值以及如何为具有该 MPI 库的 MPI 作业正确设置这些值。
注意
下面是示例代码片段。 建议使用包的最新稳定版本,或者查看 azhpc 映像存储库。
选择 MPI 库
如果 HPC 应用程序推荐特定的 MPI 库,请先试用该版本。 如果可以灵活选择 MPI,并想要获得最佳性能,请尝试 HPC-X。 总体而言,HPC-X MPI 为 InfiniBand 接口使用 UCX 框架时表现最佳,并具有所有 Mellanox InfiniBand 硬件和软件功能的优势。 此外,HPC-X 和 OpenMPI 兼容 ABI,因此你可以使用通过 OpenMPI 生成的 HPC-X 动态运行 HPC 应用程序。 同样,Intel MPI、MVAPICH 和 MPICH 也兼容 ABI。
下图说明了常用 MPI 库的体系结构。
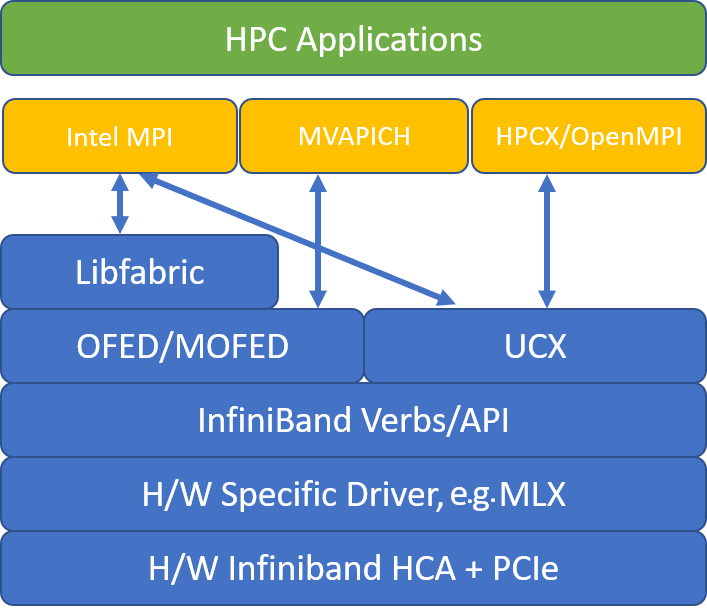
HPC-X
HPC-X 软件工具包包含 UCX 和 HCOLL,可针对 UCX 生成。
HPCX_VERSION="v2.6.0"
HPCX_DOWNLOAD_URL=https://azhpcstor.blob.core.chinacloudapi.cn/azhpc-images-store/hpcx-v2.6.0-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
wget --retry-connrefused --tries=3 --waitretry=5 $HPCX_DOWNLOAD_URL
tar -xvf hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64.tbz
mv hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64 ${INSTALL_PREFIX}
HPCX_PATH=${INSTALL_PREFIX}/hpcx-${HPCX_VERSION}-gcc-MLNX_OFED_LINUX-5.0-1.0.0.0-redhat7.7-x86_64
以下命令说明了适用于 HPC-X 和 OpenMPI 的一些建议的 mpirun 参数。
mpirun -n $NPROCS --hostfile $HOSTFILE --map-by ppr:$NUMBER_PROCESSES_PER_NUMA:numa:pe=$NUMBER_THREADS_PER_PROCESS -report-bindings $MPI_EXECUTABLE
其中:
| 参数 | 说明 |
|---|---|
NPROCS |
指定 MPI 进程的数量。 例如:-n 16。 |
$HOSTFILE |
指定包含主机名或 IP 地址的文件,以指示 MPI 进程运行的位置。 例如:--hostfile hosts。 |
$NUMBER_PROCESSES_PER_NUMA |
指定在每个 NUMA 域中运行的 MPI 进程数。 例如,若要为每个 NUMA 指定四个 MPI 进程,请使用 --map-by ppr:4:numa:pe=1。 |
$NUMBER_THREADS_PER_PROCESS |
指定每个 MPI 进程拥有的线程数量。 例如,若要为每个 NUMA 指定一个 MPI 进程和四个线程,请使用 --map-by ppr:1:numa:pe=4。 |
-report-bindings |
打印 MPI 进程映射到内核,这对验证 MPC 进程固定是否正确十分有用。 |
$MPI_EXECUTABLE |
在 MPI 库中指定 MPI 可执行文件生成的链接。 MPI 编译器包装器会自动执行此操作。 例如 mpicc 或 mpif90。 |
运行 OSU 延迟微基准测试程序的示例如下所示:
${HPCX_PATH}mpirun -np 2 --map-by ppr:2:node -x UCX_TLS=rc ${HPCX_PATH}/ompi/tests/osu-micro-benchmarks-5.3.2/osu_latency
优化 MPI 集体
MPI 集体通信基元提供一种灵活的可移植方式来实现组通信操作。 它们被广泛用于各种科学并行应用程序,并对总体应用程序性能产生显著影响。 有关使用 HPC-X 和 HCOLL 库进行集体通信以优化集体通信性能的配置参数的详细信息,请参阅 TechCommunity 文章。
例如,如果怀疑紧密耦合 MPI 应用程序正在进行大量的集体通信,则可以尝试启用分层集体 (HCOLL)。 若要启用这些功能,请使用以下参数。
-mca coll_hcoll_enable 1 -x HCOLL_MAIN_IB=<MLX device>:<Port>
注意
使用 HPC-X 2.7.4 及更高版本时,如果 MOFED 上的 UCX 版本与 HPC-X 中的 UCX 版本不同,则可能需要显式传递 LD_LIBRARY_PATH。
OpenMPI
如上所述安装 UCX。 HCOLL 是 HPC-X 软件工具包的一部分,无需特殊安装。
可从存储库提供的包中安装 OpenMPI。
sudo yum install -y openmpi
建议使用 UCX 生成最新且稳定的 OpenMPI 版本。
OMPI_VERSION="4.0.3"
OMPI_DOWNLOAD_URL=https://download.open-mpi.org/release/open-mpi/v4.0/openmpi-${OMPI_VERSION}.tar.gz
wget --retry-connrefused --tries=3 --waitretry=5 $OMPI_DOWNLOAD_URL
tar -xvf openmpi-${OMPI_VERSION}.tar.gz
cd openmpi-${OMPI_VERSION}
./configure --prefix=${INSTALL_PREFIX}/openmpi-${OMPI_VERSION} --with-ucx=${UCX_PATH} --with-hcoll=${HCOLL_PATH} --enable-mpirun-prefix-by-default --with-platform=contrib/platform/mellanox/optimized && make -j$(nproc) && make install
为获得最佳性能,请使用 ucx 和 hcoll 运行 OpenMPI。 另请参阅 HPC-X 的示例。
${INSTALL_PREFIX}/bin/mpirun -np 2 --map-by node --hostfile ~/hostfile -mca pml ucx --mca btl ^vader,tcp,openib -x UCX_NET_DEVICES=mlx5_0:1 -x UCX_IB_PKEY=0x0003 ./osu_latency
如上所述检查分区键。
Intel MPI
下载所选的 Intel MPI 版本。 Intel MPI 2019 版本从 Open Fabrics Alliance (OFA) 框架切换为 Open Fabrics Interfaces (OFI) 框架,当前支持 libfabric。 有两个访问接口可用于 InfiniBand 支持:mlx 和 verbs。 根据版本更改环境变量 I_MPI_FABRICS。
- Intel MPI 2019 和 2021:使用
I_MPI_FABRICS=shm:ofi和I_MPI_OFI_PROVIDER=mlx。mlx提供程序使用 UCX。 谓词的使用不稳定,并且性能较差。 有关更多详细信息,请查看技术社区文章。 - Intel MPI 2018:使用
I_MPI_FABRICS=shm:ofa - Intel MPI 2016:使用
I_MPI_DAPL_PROVIDER=ofa-v2-ib0
下面是适用于 Intel MPI 2019 update 5+ 的一些建议的 mpirun 参数。
export FI_PROVIDER=mlx
export I_MPI_DEBUG=5
export I_MPI_PIN_DOMAIN=numa
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
其中:
| 参数 | 说明 |
|---|---|
FI_PROVIDER |
指定要使用的 libfabric 访问接口,它将影响所用的 API、协议和网络。 verbs 是另一种选择,但通常 mlx 的性能更佳。 |
I_MPI_DEBUG |
指定额外的调试输出级别,这可以提供有关进程的固定位置、使用的协议和网络的详细信息。 |
I_MPI_PIN_DOMAIN |
指定希望采用的固定进程的方式。 例如,可以固定到内核、套接字或 NUMA 域。 在本示例中,我们将此环境变量设为 numa,这意味着将进程固定到 NUMA 节点域。 |
优化 MPI 集体
你可以尝试其他一些选项,尤其是在集体操作占用大量时间的情况下。 Intel MPI 2019 update 5+ 支持访问接口 mlx,并使用 UCX 框架与 InfiniBand 通信。 它还支持 HCOLL。
export FI_PROVIDER=mlx
export I_MPI_COLL_EXTERNAL=1
非 SR-IOV VM
对于非 SR-IOV VM,下载 5.x 运行时免费评估版的示例如下:
wget http://registrationcenter-download.intel.com/akdlm/irc_nas/tec/9278/l_mpi_p_5.1.3.223.tgz
有关安装步骤,请参阅 Intel MPI 库安装指南。 可选择为非根非调试器进程启用 ptrace(对于最新版的 Intel MPI,则必须启用)。
echo 0 | sudo tee /proc/sys/kernel/yama/ptrace_scope
SUSE Linux
对于 SUSE Linux Enterprise Server VM 映像版本 - SLES 12 SP3 for HPC、SLES 12 SP3 for HPC(高级版)、SLES 12 SP1 for HPC、SLES 12 SP1 for HPC(高级版)、SLES 12 SP4 和 SLES 15,已安装 RDMA 驱动程序,并且已在 VM 上分发 Intel MPI 包。 运行以下命令安装 Intel MPI:
sudo rpm -v -i --nodeps /opt/intelMPI/intel_mpi_packages/*.rpm
MVAPICH
下面是构建 MVAPICH2 的示例。 请注意,可能有比下面使用的版本更新的版本。
wget http://mvapich.cse.ohio-state.edu/download/mvapich/mv2/mvapich2-2.3.tar.gz
tar -xv mvapich2-2.3.tar.gz
cd mvapich2-2.3
./configure --prefix=${INSTALL_PREFIX}
make -j 8 && make install
运行 OSU 延迟微基准测试程序的示例如下所示:
${INSTALL_PREFIX}/bin/mpirun_rsh -np 2 -hostfile ~/hostfile MV2_CPU_MAPPING=48 ./osu_latency
下面的列表包含若干建议的 mpirun 参数。
export MV2_CPU_BINDING_POLICY=scatter
export MV2_CPU_BINDING_LEVEL=numanode
export MV2_SHOW_CPU_BINDING=1
export MV2_SHOW_HCA_BINDING=1
mpirun -n $NPROCS -f $HOSTFILE $MPI_EXECUTABLE
其中:
| 参数 | 说明 |
|---|---|
MV2_CPU_BINDING_POLICY |
指定要使用的绑定策略,这将影响如何将进程固定到内核 ID。 在本例中,你指定 scatter,因此进程将在各个 NUMA 域中均匀分布。 |
MV2_CPU_BINDING_LEVEL |
指定固定进程的位置。 在本例中,将其设置为 numanode,这意味着将进程固定到 NUMA 域的各个单元。 |
MV2_SHOW_CPU_BINDING |
指定是否想要获取有关进程固定位置的调试信息。 |
MV2_SHOW_HCA_BINDING |
指定是否想要获取有关每个进程正在使用的主机通道适配器的调试信息。 |
平台 MPI
安装平台 MPI 社区版所需的包。
sudo yum install libstdc++.i686
sudo yum install glibc.i686
Download platform MPI at https://www.ibm.com/developerworks/downloads/im/mpi/index.html
sudo ./platform_mpi-09.01.04.03r-ce.bin
请按照安装流程操作。
MPICH
如上所述安装 UCX。 生成 MPICH。
wget https://www.mpich.org/static/downloads/3.3/mpich-3.3.tar.gz
tar -xvf mpich-3.3.tar.gz
cd mpich-3.3
./configure --with-ucx=${UCX_PATH} --prefix=${INSTALL_PREFIX} --with-device=ch4:ucx
make -j 8 && make install
运行 MPICH。
${INSTALL_PREFIX}/bin/mpiexec -n 2 -hostfile ~/hostfile -env UCX_IB_PKEY=0x0003 -bind-to hwthread ./osu_latency
如上所述检查分区键。
OSU MPI 基准
下载 OSU MPI 基准并进行解压。
wget http://mvapich.cse.ohio-state.edu/download/mvapich/osu-micro-benchmarks-5.5.tar.gz
tar -xvf osu-micro-benchmarks-5.5.tar.gz
cd osu-micro-benchmarks-5.5
使用特定 MPI 库生成基准:
CC=<mpi-install-path/bin/mpicc>CXX=<mpi-install-path/bin/mpicxx> ./configure
make
可在 mpi/ 文件夹下找到 MPI 基准。
发现分区键
发现分区键(p 键),用来与同一租户(可用性集或虚拟机规模集)中的其他 VM 进行通信。
/sys/class/infiniband/mlx5_0/ports/1/pkeys/0
/sys/class/infiniband/mlx5_0/ports/1/pkeys/1
这两者中较大的键是应与 MPI 一起使用的租户键。 示例:如果下面是 p 键,则应对 MPI 使用 0x800b。
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/0
0x800b
cat /sys/class/infiniband/mlx5_0/ports/1/pkeys/1
0x7fff
请注意,接口在 HPC VM 映像中命名为 mlx5_ib*。
另请注意,只要存在租户(可用性集或虚拟机集规模集),PKEY 就保持不变。 即使添加/删除节点,也是如此。 新租户获取不同的 PKEY。
设置 MPI 的用户限制
设置 MPI 的用户限制。
cat << EOF | sudo tee -a /etc/security/limits.conf
* hard memlock unlimited
* soft memlock unlimited
* hard nofile 65535
* soft nofile 65535
EOF
设置 MPI 的 SSH 键
为需要 SSH 键的 MPI 类型设置这些键。
ssh-keygen -f /home/$USER/.ssh/id_rsa -t rsa -N ''
cat << EOF > /home/$USER/.ssh/config
Host *
StrictHostKeyChecking no
EOF
cat /home/$USER/.ssh/id_rsa.pub >> /home/$USER/.ssh/authorized_keys
chmod 600 /home/$USER/.ssh/authorized_keys
chmod 644 /home/$USER/.ssh/config
上述语法假定有一个共享主目录,否则必须将 .ssh 目录复制到每个节点。
后续步骤
- 了解已启用 InfiniBand 的 HB 系列和 N 系列 VM。
- 查看 HBv3 系列概述。
- 读取 HB 系列 VM 的最佳 MPI 进程位置。
- 在 Azure 计算技术社区博客上阅读最新公告、HPC 工作负载示例和性能结果。