摘要
Azure HDInsight 是 Azure 中最受企业客户青睐的开源分析服务之一。 订阅 HDInsight 发行说明,获取有关 HDInsight 和所有 HDInsight 版本的最新信息。
若要订阅,请单击横幅中的“关注”按钮,关注 HDInsight 发布。
版本信息
发布日期:2025 年 10 月 6 日
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2508190809。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
新功能
已启用 Azure HDInsight 群集的 Entra 身份验证。 用户现在可以选择让 Entra ID 完成用户身份验证。
Entra 群集现在支持 Grafana 登录。
C++启用了 CodeQL 扫描,以实现更好的静态分析覆盖范围。
非公有云现在支持对 SQL 数据库的基于托管标识(MI)的身份验证。 有关详细信息,请参阅 Azure HDInsight 中使用托管标识进行 SQL 数据库身份验证
修复的问题
修补了多个依赖项(qs、大括号、连接、调试等)的多个 OS 级漏洞。
默认情况下禁用本地用户创建以增强访问控制。
更新
- HDInsight 不再支持以下独立驱动程序。
Reminder
Azure 基本负载均衡器的弃用公告发布后,HDInsight 服务已将其所有群集配置切换为使用标准负载均衡器。
重要
默认情况下,使用标准负载均衡器创建任何新的 HDInsight 群集。 建议参考 迁移指南重新创建群集。 如需任何帮助,请联系 支持人员。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2025 年 5 月 28 日
注意
这是资源提供程序的修补程序/维护版本。 有关详细信息,请参阅 资源提供程序。
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2501080039。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
修复的问题
- 使用托管标识时 SQL 数据库的身份验证问题。
更新
- 自 2025 年 5 月 26 日起,创建具有预先确定映像版本的 HDInsight 群集的活动 PIN 请求将被撤销/取消。 客户只能使用每个 HDInsight 版本的已更新的(合规)映像创建群集。 此措施旨在提高群集安全性,并防止群集和网关节点出现潜在问题。
Reminder
Azure 基本负载均衡器的弃用公告发布后,HDInsight 服务已将其所有群集配置切换为使用标准负载均衡器。
重要
默认情况下,使用标准负载均衡器创建任何新的 HDInsight 群集。 建议参考 迁移指南重新创建群集。 如需任何帮助,请联系 支持人员。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2025 年 4 月 28 日
注意
这是资源提供程序的修补程序/维护版本。 有关详细信息,请参阅 资源提供程序。
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2501080039。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
修复的问题
- 在存储上启用网络 ACL 时,WASB 的基于标识的托管身份验证遇到问题。
- 使用可用性区域时,SQL 数据库的托管服务身份验证遇到问题。
- 多个安全修补程序。
更新
- 2025 年 5 月 26 日,将吊销/取消用于创建具有预先确定映像版本的 HDInsight 群集的活动 PIN 请求。 在此日期之外,客户只能使用每个 HDInsight 版本更新的(合规)映像创建群集。 此措施旨在提高群集安全性,并防止群集和网关节点出现潜在问题。
Reminder
由于 Azure 基本负载均衡器的弃用公告,HDInsight 服务已过渡到为其所有群集配置使用标准负载均衡器。
重要
默认情况下,使用标准负载均衡器创建任何新的 HDInsight 群集。 建议参考 迁移指南重新创建群集。 如需任何帮助,请联系 支持人员。
-
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2025 年 1 月 23 日
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2501080039。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
新功能
基于 MSI 的 SQL 数据库身份验证。
HDInsight 现在在其群集产品/服务中提供托管标识,以便使用 SQL 数据库进行安全身份验证。 此增强功能提供更安全的身份验证机制。 有关详细信息,请参阅在 Azure HDInsight 中使用托管标识进行 SQL 数据库身份验证。
若要将托管标识与 SQL 数据库一起使用,请按照以下步骤操作:
此功能在默认情况下未启用。 若要启用它,请使用订阅和区域详细信息提交支持工单。
启用该功能后,继续重新创建群集。
注意
托管标识目前仅在公共区域可用。 它将在未来的版本中推广到其他地区(联邦地区和中国地区)。
新区域
- 新西兰北部。
Reminder
由于 Azure 基本负载均衡器的弃用公告,HDInsight 服务已过渡到为其所有群集配置使用标准负载均衡器。
注意
此项更改已在所有区域中推出。 请重新创建群集以使用此项更改。 如需任何帮助,请联系 支持人员。
重要
在创建群集期间使用自己的虚拟网络(自定义 VNet)时,请注意,启用此更改后,群集创建不会成功。 建议参考 迁移指南重新创建群集。 如需任何帮助,请联系 支持人员。
-
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
 即将推出的功能
即将推出的功能
- HDInsight 4.0 和 HDInsight 5.0 停用通知。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2024 年 10 月 22 日
注意
这是资源提供程序的修补程序/维护版本。 有关详细信息,请参阅 资源提供程序。
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2409240625。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
Updated
Azure Blob 存储具有基于 MSI 的身份验证支持。
- Azure HDInsight 现在支持基于 OAuth 的身份验证,以利用 Azure Active Directory (AAD) 和托管标识 (MSI) 访问 Azure Blob 存储。 通过此增强功能,HDInsight 使用用户分配的托管标识来访问 Azure Blob 存储。 有关详细信息,请参阅 Azure 资源的托管标识。
由于 Azure 基本负载均衡器的弃用公告,HDInsight 服务已过渡到为其所有群集配置使用标准负载均衡器。
注意
此项更改已在所有区域中推出。 请重新创建群集以使用此项更改。 如需任何帮助,请联系 支持人员。
重要
在创建群集期间使用自己的虚拟网络(自定义 VNet)时,请注意,启用此更改后,群集创建不会成功。 建议参考 迁移指南重新创建群集。 如需任何帮助,请联系 支持人员。
即将推出的功能
-
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
HDInsight 4.0 和 HDInsight 5.0 停用通知。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2024 年 8 月 30 日
注意
这是资源提供程序的修补程序/维护版本。 有关详细信息,请参阅 资源提供程序。
Azure HDInsight 会定期发布维护更新,以提供 bug 修复、性能增强和安全补丁,确保你及时安装这些更新,以保证最佳性能和可靠性。
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2407260448。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
问题已修复
- 默认 DB bug 修复。
即将发布
-
基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- HDInsight 4.0 和 HDInsight 5.0 停用通知。
发布日期:2024 年 8 月 9 日
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2407260448。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
更新
在 HDInsight 中添加用于 Log Analytics 的 Azure Monitor 代理
注意
有效映像编号2407260448,使用门户进行日志分析的客户将具有默认的 Azure Monitor 代理体验。 若要切换到 Azure Monitor 体验(预览),可以通过创建支持请求将群集固定到旧映像。
发布日期:2024 年 7 月 5 日
注意
这是资源提供程序的修补程序/维护版本。 有关详细信息,请参阅资源提供程序
修复的问题
HOBO 标记覆盖用户标记。
- HDInsight 群集创建中子资源上的 HOBO 标记覆盖用户标记。
发布日期:2024 年 6 月 19 日
此发行说明适用于
![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2406180258。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
修复的问题
安全性改进
HDInsight Log Analytics 中对 HDInsight 资源提供程序的系统托管标识支持的改进。
添加了新活动以升级旧映像的
mdsd代理版本(在 2024 年之前创建)。在网关中启用 MISE 作为 MSAL 迁移的持续改进的一部分。
将 Spark Thrift 服务器
Httpheader hiveConf合并到 Jetty HTTP ConnectionFactory。还原 RANGER-3753 和 RANGER-3593。
Ranger 2.3.0 版本中提供的
setOwnerUser会实现在 Hive 使用时存在严重的回归问题。 在 Ranger 2.3.0 中,当 HiveServer2 尝试评估策略时,Ranger Client 会尝试通过在 setOwnerUser 函数中调用元存储来获取 hive 表的所有者,该函数实质上会调用存储以检查该表的访问。 此问题会导致 Hive 在 2.3.0 Ranger 上运行时运行缓慢。
即将发布
-
基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- HDInsight 4.0 和 HDInsight 5.0 停用通知。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2024 年 5 月 16 日
此发行说明适用于
![]() HDInsight 5.0 版本。
HDInsight 5.0 版本。
![]() HDInsight 4.0 版本。
HDInsight 4.0 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2405081840。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
已修复的问题
- 在网关中添加了 API,用于获取 Keyvault 的令牌,作为 SFI 计划的一部分。
- 在新日志监视器
HDInsightSparkLogs表中,对于日志类型SparkDriverLog,缺少某些字段。 例如LogLevel & Message。 此版本将缺少的字段添加到SparkDriverLog的架构和固定格式。 - Log Analytics 监视
SparkDriverLog表中不可用的 Livy 日志,这是因为 livy 日志源路径和SparkLivyLog配置中的日志分析正则表达式出现问题。 - 任何使用 ADLS Gen2 作为主存储帐户的 HDInsight 群集都可以利用 MSI 访问应用程序代码中使用的任何 Azure 资源(例如 SQL、Keyvaults)。
即将推出的功能
-
基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- HDInsight 4.0 和 HDInsight 5.0 停用通知。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2024 年 4 月 15 日
此发行说明适用于 ![]() HDInsight 5.1 版本。
HDInsight 5.1 版本。
HDInsight 版本在几天内对所有区域可用。 此发行说明适用于映像编号 2403290825。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关特定于工作负载的版本,请参阅 HDInsight 5.x 组件版本。
已修复的问题
- Ambari DB、Hive Warehouse Controller (HWC)、Spark、HDFS 的 Bug 修复
- HDInsightSparkLogs 日志分析模块的 Bug 修复
- HDInsight 资源提供程序的 CVE 修复。
即将发布
-
基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- HDInsight 4.0 和 HDInsight 5.0 停用通知。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题。
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,并关注我们以了解有关 AzureHDInsight 社区的更多动态。
发布日期:2024 年 2 月 15 日
此发布适用于 HDInsight 4.x 和 5.x 版本。 HDInsight 版本在几天内对所有区域可用。 此发布适用于映像编号 2401250802。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关工作负载专属版本,请参阅
新功能
- 使用企业安全性套餐为 Spark 3.3.0(HDInsight 版本 5.1)中的 Spark SQL 提供 Apache Ranger 支持。 你可在此处了解相关详细信息。
已修复的问题
- Ambari 和 Oozie 组件的安全性修补程序
即将推出的功能
- 基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,以及关注我们了解有关 AzureHDInsight 社区的更多动态
后续步骤
Azure HDInsight 是 Azure 中最受企业客户青睐的开源分析服务之一。 如果要订阅发行说明,请查看此 GitHub 存储库上的版本。
发布日期:2024 年 1 月 10 日
此修补程序版本适用于 HDInsight 4.x 和 5.x 版本。 HDInsight 版本在几天内对所有区域可用。 此版本适用于编号为 2401030422 的图像。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
注意
Ubuntu 18.04 由 Azure Linux 团队在扩展安全维护 (ESM) 下支持,适用于 2023 年 7 月后发布的 Azure HDInsight。
有关工作负载专属版本,请参阅
修复的问题
- Ambari 和 Oozie 组件的安全性修补程序
即将推出的功能
- 基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,以及关注我们了解有关 AzureHDInsight 社区的更多动态
发布日期:2023 年 10 月 26 日
此版本适用于 HDInsight 4.x,5.x HDInsight 版本将在几天内在所有区域可用。 此版本适用于映像编号 2310140056。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
有关工作负载专属版本,请参阅
新增功能
HDInsight 宣布从 2023 年 11 月 1 日起正式发布 HDInsight 5.1。 此版本对开源组件和 Azure 中的集成进行了全栈刷新。
- 最新开源版本 - HDInsight 5.1 随附最新的稳定开源版本。 客户可以从所有最新的开源功能、Azure 性能改进和 Bug 修复中受益。
- 安全 - 最新版本附带最新的安全修补程序,包括 Microsoft 提供的开源安全修补程序和安全改进。
- 降低了 TCO - 通过性能增强,客户可以降低运营成本,同时实现增强的自动缩放。
用于安全存储的群集权限
- 客户可以(在群集创建期间)指定是否应将安全通道用于 HDInsight 群集节点以连接存储帐户。
使用自定义 VNet 创建 HDInsight 群集。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
Microsoft Network/virtualNetworks/subnets/join/action来执行创建操作。 如果未启用此检查,客户可能会遇到创建失败。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
非 ESP ABFS 群集 [可读 Word 的群集权限]
- 非 ESP ABFS 群集会限制非 Hadoop 组用户使用 Hadoop 命令执行存储操作。 此更改可改善群集安全状况。
内联配额更新。
- 现在,可以直接从“我的配额”页面请求增加配额,因为使用了直接 API 调用,其速度会更快。 如果 API 调用失败,可以创建新的支持请求来要求增加配额。
群集名称的最大长度将从 59 个字符更改为 45 个字符,以改善群集的安全状况。 在即将发布的版本中,此更改将发布到所有区域。
基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。
- 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题
我们乐于倾听用户的反馈:欢迎在此处(HDInsight 创意)添加更多想法和其他主题并对其投票,以及关注我们了解有关 AzureHDInsight 社区的更多动态
注意
此版本解决了 MSRC 于 2023 年 9 月 12 日发布的以下 CVE 的问题。 此操作将更新到最新映像 2308221128 或 2310140056。 建议客户进行相应的规划。
| CVE | 严重性 | CVE 标题 | 备注 |
|---|---|---|---|
| CVE-2023-38156 | 重要 | Azure HDInsight Apache Ambari 特权提升漏洞 | 包含在映像 2308221128 或 2310140056 中 |
| CVE-2023-36419 | 重要 | Azure HDInsight Apache Oozie 工作流计划程序特权提升漏洞 | 在群集上应用脚本操作,或更新到 2310140056 映像 |
发布日期:2023 年 9 月 7 日
此版本适用于 HDInsight 4.x,5.x HDInsight 版本将在几天内在所有区域可用。 此版本适用于映像编号 2308221128。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
有关工作负载专属版本,请参阅
重要
此版本解决了 MSRC 于 2023 年 9 月 12 日发布的以下 CVE 的问题。 操作是更新到最新映像 2308221128。 建议客户进行相应的规划。
| CVE | 严重性 | CVE 标题 | 备注 |
|---|---|---|---|
| CVE-2023-38156 | 重要 | Azure HDInsight Apache Ambari 特权提升漏洞 | 包含在 2308221128 映像中 |
| CVE-2023-36419 | 重要 | Azure HDInsight Apache Oozie 工作流计划程序特权提升漏洞 | 在群集上应用脚本操作 |
即将推出
- 群集名称的最大长度将从 59 个字符更改为 45 个字符,以改善群集的安全状况。 此更改将于 2023 年 9 月 30 日实施。
- 安全存储的群集权限
- 客户可以(在群集创建期间)指定是否应将安全通道用于 HDInsight 群集节点以联系存储帐户。
- 内联配额更新。
- 可以直接从“我的配额”页请求提高配额,这是直接 API 调用,速度更快。 如果 API 调用失败,客户需要创建新的支持请求来提高配额。
- 使用自定义 VNet 创建 HDInsight 群集。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
Microsoft Network/virtualNetworks/subnets/join/action来执行创建操作。 客户需要相应地进行规划,因为此更改将是一项为了避免 2023 年 9 月 30 日之前群集创建失败的强制性检查。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
- 基本和标准 A 系列 VM 停用。
- 2024 年 8 月 31 日,我们将停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- 非 ESP ABFS 群集 [可读 Word 的群集权限]
- 计划在非 ESP ABFS 群集中引入更改,以限制非 Hadoop 组用户执行 Hadoop 命令以执行存储操作。 此更改可改善群集安全状况。 客户需要在 2023 年 9 月 30 日之前规划更新。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题
欢迎在 HDInsight 社区 (azure.com) 添加更多建议和想法以及其他主题,并为它们投票。
发布日期:2023 年 7 月 25 日
此版本适用于 HDInsight 4.x,5.x HDInsight 版本将在几天内在所有区域可用。 此版本适用于映像编号 2307201242。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.1:Ubuntu 18.04.5 LTS Linux 内核 5.4
有关工作负载专属版本,请参阅
 新增功能
新增功能
- ESP 群集现在支持 HDInsight 5.1。
- Ranger 2.3.0 和 Oozie 5.2.1 的升级版本现在是 HDInsight 5.1 的一部分
- Spark 3.3.1 (HDInsight 5.1) 群集附带了与 Interactive Query (HDInsight 5.1) 群集配合使用的 Hive Warehouse Connector (HWC) 2.1。
- Azure Linux 团队在 ESM(扩展安全维护)下支持 Ubuntu 18.04,用于 Azure HDInsight 2023 年 7 月及以后的版本。
重要
此版本解决了 MSRC 于 2023 年 8 月 8 日发布的以下 CVE 的问题。 操作是更新到最新映像 2307201242。 建议客户进行相应的规划。
| CVE | 严重性 | CVE 标题 |
|---|---|---|
| CVE-2023-35393 | 重要 | Azure Apache Hive 欺骗漏洞 |
| CVE-2023-35394 | 重要 | Azure HDInsight Jupyter Notebook 欺骗漏洞 |
| CVE-2023-36877 | 重要 | Azure Apache Oozie 欺骗漏洞 |
| CVE-2023-36881 | 重要 | Azure Apache Ambari 欺骗漏洞 |
| CVE-2023-38188 | 重要 | Azure Apache Hadoop 欺骗漏洞 |
即将推出的功能
- 群集名称的最大长度将从 59 个字符更改为 45 个字符,以改善群集的安全状况。 客户需要在 2023 年 9 月 30 日之前规划更新。
- 安全存储的群集权限
- 客户可以(在群集创建期间)指定是否应将安全通道用于 HDInsight 群集节点以联系存储帐户。
- 内联配额更新。
- 可以直接从“我的配额”页请求提高配额,这是直接 API 调用,速度更快。 如果 API 调用失败,则客户需要创建新的支持请求来提高配额。
- 使用自定义 VNet 创建 HDInsight 群集。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
Microsoft Network/virtualNetworks/subnets/join/action来执行创建操作。 客户需要相应地进行规划,因为此更改将是一项为了避免 2023 年 9 月 30 日之前群集创建失败的强制性检查。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
- 基本和标准 A 系列 VM 停用。
- 我们将在 2024 年 8 月 31 日停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负荷从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- 非 ESP ABFS 群集 [可读 Word 的群集权限]
- 计划在非 ESP ABFS 群集中引入更改,以限制非 Hadoop 组用户执行 Hadoop 命令以执行存储操作。 此更改可改善群集安全状况。 客户需要在 2023 年 9 月 30 日之前规划更新。
如果有任何其他问题,请联系 Azure 支持。
可以随时在 Azure HDInsight - Azure Q&A 中向我们提出有关 HDInsight 的问题
欢迎在 HDInsight 社区 (azure.com) 添加更多建议和想法以及其他主题,并为它们投票。
发布日期:2023 年 5 月 8 日
此版本适用于 HDInsight 4.x,几天内将在所有区域提供 5.x HDInsight 版本。 此版本适用于映像编号 2304280205。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
有关工作负载专属版本,请参阅
![]()
Azure HDInsight 5.1 更新为
- Apache HBase 2.4.11
- Apache Phoenix 5.1.2
- Apache Hive 3.1.2
- Apache Spark 3.3.1
- Apache Tez 0.9.1
- Apache Zeppelin 0.10.1
- Apache Livy 0.5
- Apache Kafka 3.2.0
注意
- 所有组件都与 Hadoop 3.3.4 和 ZK 3.6.3 集成
- 上述所有升级的组件现可在非 ESP 群集中作为公共预览版使用。
![]()
HDInsight 的增强型自动缩放
Azure HDInsight 对自动缩放的稳定性和延迟进行了显著改进,基本更改包括改进了缩放决策的反馈循环、显著改进了缩放延迟以及支持重新授权已解除授权的节点。详细了解增强功能,如何自定义配置群集并将其迁移到增强型自动缩放。 增强型自动缩放功能于 2023 年 5 月 17 日在所有受支持区域推出。
适用于 Apache Kafka 2.4.1 的 Azure HDInsight ESP 现已正式发布。
适用于 Apache Kafka 2.4.1 的 Azure HDInsight ESP 自 2022 年 4 月以来一直作为公共预览版提供。 在 CVE 修复和稳定性方面进行了显著改进后,Azure HDInsight ESP Kafka 2.4.1 现已正式发布并可用于生产工作负载,详细了解如何配置和迁移。
HDInsight 的配额管理
HDInsight 当前在区域级别向客户订阅分配配额。 分配给客户的核心是通用型核心,不会按 VM 系列级别(例如
Dv2、Ev3、Eav4等)分类。HDInsight 引入了改进的视图,以提供各系列级别 VM 的详细信息和配额分类,并允许客户按 VM 系列级别查看某个区域的当前配额和剩余配额。 借助增强型视图,客户可以了解更丰富的信息以规划配额,并提供更好的用户体验。 此功能目前适用于中国东部 2 EUAP 区域的 HDInsight 4.x 和 5.x。 稍后将在其他区域推出。
有关详细信息,请参阅 Azure HDInsight 中的群集容量计划 | Azure Learn
![]()
- 波兰中部
- 群集名的最大长度从 59 个字符更改为 45 个字符,以改善群集的安全状况。
- 安全存储的群集权限
- 客户可以(在群集创建期间)指定是否应将安全通道用于 HDInsight 群集节点以联系存储帐户。
- 内联配额更新。
- 可直接从“我的配额”页请求提高配额,这是直接 API 调用,速度更快。 如果 API 调用失败,则客户需要创建新的支持请求来提高配额。
- 使用自定义 VNet 创建 HDInsight 群集。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
Microsoft Network/virtualNetworks/subnets/join/action来执行创建操作。 客户需要相应地进行规划,因为这是一项用于避免群集创建失败的强制性检查。
- 若要改善 HDInsight 群集的整体安全状况,使用自定义 VNET 的 HDInsight 群集需要确保用户有权访问
- 基本和标准 A 系列 VM 停用。
- 我们将在 2024 年 8 月 31 日停用基本和标准 A 系列 VM。 在此之前,需要将工作负载迁移到 Av2 系列 VM,这将为每个 vCPU 提供更多内存,并在固态硬盘 (SSD) 上提供更快的存储速度。 若要避免服务中断,请在 2024 年 8 月 31 日之前,将工作负载从基本和标准 A 系列 VM 迁移到 Av2 系列 VM。
- 非 ESP ABFS 群集[全局可读的群集权限]
- 计划在非 ESP ABFS 群集中引入更改,以限制非 Hadoop 组用户执行 Hadoop 命令以执行存储操作。 此更改可改善群集安全状况。 客户需要规划更新。
发布日期:2023 年 2 月 28 日
此版本适用于 HDInsight 4.0。 和 5.0, 5.1。 HDInsight 发行版在几天后即会在所有区域中推出。 此版本适用于映像编号 2302250400。 如何检查映像编号?
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
有关工作负载专属版本,请参阅
重要
Azure 已发布 CVE-2023-23408,它已在当前版本上修复,并建议客户将其群集升级到最新映像。
![]()
HDInsight 5.1
我们已开始推出 HDInsight 5.1 的新版本。 所有新的开源版本都作为增量版本添加到 HDInsight 5.1 上。
![]()
Kafka 3.2.0 升级 (预览版)
- Kafka 3.2.0 包含几个重要的新功能/改进。
- 已将 Zookeeper 升级到 3.6.3
- Kafka Streams 支持
- 默认情况下为 Kafka 生成者启用更强大的交付保证。
-
log4j1.x 替换为reload4j。 - 向分区前导发送提示以恢复分区。
-
JoinGroupRequest和LeaveGroupRequest附加了原因。 - 添加了 Broker 计数指标 8。
- 镜像
Maker2改进。
HBase 2.4.11 升级 (预览版)
- 此版本具有新功能,例如为块缓存添加新的缓存机制类型、从 HBase WEB UI 更改
hbase:meta table和查看hbase:meta表的功能。
Phoenix 5.1.2 升级 (预览版)
- 在此版本中,Phoenix 版本已升级到 5.1.2。 此升级包括 Phoenix Query Server。 Phoenix Query Server 代理标准 Phoenix JDBC 驱动程序,并提供向后兼容的线路协议来调用该 JDBC 驱动程序。
Ambari CVE
- 多个 Ambari CVE 是固定的。
注意
此版本中的 Kafka 和 HBase 不支持 ESP。
![]()
后续步骤
- 自动缩放
- 具有延迟改善和多项改进的自动缩放
- 群集名称更改限制
- 在 Public 和由世纪互联运营的 Azure 中,群集名的最大长度从 59 更改为 45。
- 安全存储的群集权限
- 客户可以(在群集创建期间)指定是否应将安全通道用于 HDInsight 群集节点以联系存储帐户。
- 非 ESP ABFS 群集[全局可读的群集权限]
- 计划在非 ESP ABFS 群集中引入更改,以限制非 Hadoop 组用户执行 Hadoop 命令以执行存储操作。 此更改可改善群集安全状况。 客户需要规划更新。
- 开放源代码升级
- Apache Spark 3.3.0 和 Hadoop 3.3.4 正在 HDInsight 5.1 上开发,它包含几项重要的新功能、性能和其他改进。
发布日期:2022 年 12 月 12 日
此版本适用于 HDInsight 4.0。 和 5.0 HDInsight 版本在几天内对所有区域可用。
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
OS 版本
- HDInsight 4.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
- HDInsight 5.0:Ubuntu 18.04.5 LTS Linux 内核 5.4
![]()
- Log Analytics - 客户可以启用经典监视以获取最新的 OMS 版本 14.19。 要删除旧版本,请禁用并启用经典监视。
- Ambari 用户会因不活动而自动从 UI 退出登录。 有关详细信息,请参阅此文
- Spark - 此版本包含经过优化的新版本 Spark 3.1.3。 我们使用 TPC-DS 基准测试了 Apache Spark 3.1.2(以前的版本)和 Apache Spark 3.1.3(当前版本)。 该测试使用 E8 V3 SKU 执行,适用于 1 TB 工作负载上的 Apache Spark。 对于使用相同硬件规格的 TPC-DS 查询,按照总运行时间考虑,Apache Spark 3.1.3(当前版本)的性能比 Apache Spark 3.1.2(以前的版本)高出 40% 以上。 Azure Spark 团队通过 Azure HDInsight 在 Azure Synapse 中添加了可用的优化。 有关更多信息,请参阅通过 Azure Synapse 中 Apache Spark 3.1.2 的性能更新加快数据工作负载
![]()
HDInsight 已从 Azul Zulu Java JDK 8 迁移到
Adoptium Temurin JDK 8,后者支持高质量的 TCK 认证运行时以及用于整个 Java 生态系统的关联技术。HDInsight 已迁移到
reload4j。log4j更改适用于- Apache Hadoop
- Apache Zookeeper
- Apache Oozie
- Apache Ranger
- Apache Sqoop
- Apache Pig
- Apache Ambari
- Apache Kafka
- Apache Spark
- Apache Zeppelin
- Apache Livy
- Apache Rubix
- Apache Hive
- Apache Tez
- Apache HBase
- OMI
- Apache Phoenix
![]()
HDInsight 将继续实施 TLS1.2,并在该平台上更新之前的版本。 如果你在 HDInsight 上运行任何应用程序,并且应用程序使用 TLS 1.0 和 1.1,请升级到 TLS 1.2 以避免服务中断。
有关详细信息,请参阅如何启用传输层安全性 (TLS)
![]()
对 Ubuntu 16.04 LTS 上的 Azure HDInsight 群集的支持已于 2022 年 11 月 30 日终止。 HDInsight 于 2021 年 6 月 27 日开始使用 Ubuntu 18.04 发布群集映像。 对于使用 Ubuntu 16.04 运行群集的客户,我们建议在 2022 年 11 月 30 日前使用最新的 HDInsight 映像重新生成其群集。
有关如何检查群集的 Ubuntu 版本的详细信息,请参阅此处
在终端执行命令“lsb_release -a”。
如果输出中“Description”属性的值为“Ubuntu 16.04 LTS”,则此更新适用于群集。
![]()
- 针对 Kafka 和 HBase(写访问)群集支持可用性区域选择。
开源 bug 修复
Hive 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| HIVE-26127 | INSERT OVERWRITE 错误 - 找不到文件 |
| HIVE-24957 | 当子查询在相关谓词中具有 COALESCE 时出现错误结果 |
| HIVE-24999 | HiveSubQueryRemoveRule 为具有多个关联的 IN 子查询生成了无效计划 |
| HIVE-24322 | 如果存在直接插入,则必须在读取清单文件时检查尝试 ID |
| HIVE-23363 | 将 DataNucleus 依赖项升级到 5.2 |
| HIVE-26412 | 创建接口以提取可用槽并添加默认值 |
| HIVE-26173 | 将 derby 升级到 10.14.2.0 |
| HIVE-25920 | 将 Xerce2 升级到 2.12.2。 |
| HIVE-26300 | 将 Jackson 数据绑定版本升级到 2.12.6.1+ 以避免 CVE-2020-36518 |
发布日期:2022/08/10
此版本适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
![]()
新功能
1. 在 HDI Hadoop/Spark 群集中附加外部磁盘
HDInsight 群集附带基于 SKU 的预定义磁盘空间。 在大型作业场景中,这个空间可能是不够的。
此新功能允许在群集中添加更多磁盘,用作节点管理器本地目录。 在 HIVE 和 Spark 群集创建期间,将磁盘数添加到工作器节点,而所选磁盘将成为节点管理器本地目录的一部分。
注意
添加的磁盘仅针对节点管理器本地目录进行配置。
有关详细信息,请参阅此文
2. 选择性日志记录分析
选择性日志记录分析现已在所有区域提供公共预览版。 可以将群集连接到 Log Analytics 工作区。 启用后,可以查看 HDInsight 安全日志、Yarn 资源管理器、系统指标等日志和指标。可以监视工作负载,并了解它们如何影响群集的稳定性。 通过选择性日志记录,可启用/禁用所有表,或者在 Log Analytics 工作区中启用选择性表。 可以调整每个表的源类型,因为在新版本的 Geneva 监视中,一个表有多个源。
- Geneva 监视系统使用 mdsd(MDS 守护程序),这是一种监视代理和 fluentd,用于使用统一的日志记录层收集日志。
- 选择性日志记录使用脚本操作来禁用/启用表及其日志类型。 由于未打开任何新端口或更改任何现有安全设置,因此没有安全更改。
- 脚本操作在所有指定节点上并行运行,并更改用于禁用/启用表及其日志类型的配置文件。
![]()
固定
Log Analytics
与运行 OMS 版本 13 的 Azure HDInsight 集成的 Log Analytics 需要升级到 OMS 版本 14 才能应用最新的安全更新。 使用 OMS 版本 13 的旧版群集的客户需要安装 OMS 版本 14 以满足安全要求。 (如何检查当前版本和安装版本 14)
如何检查当前的 OMS 版本
- 使用 SSH 登录到群集。
- 在 SSH 客户端中运行以下命令。
sudo /opt/omi/bin/ominiserver/ --version

如何将 OMS 版本从 13 升级到 14
- 登录到 Azure 门户
- 从资源组中选择 HDInsight 群集资源
- 选择“脚本操作”
- 在“提交脚本操作”面板中,为“脚本类型”选择“自定义”
- 在 Bash 脚本 URL 框中粘贴以下链接:https://hdiconfigactions.blob.core.chinacloudapi.cn/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- 选择“节点类型”
- 选择“创建”
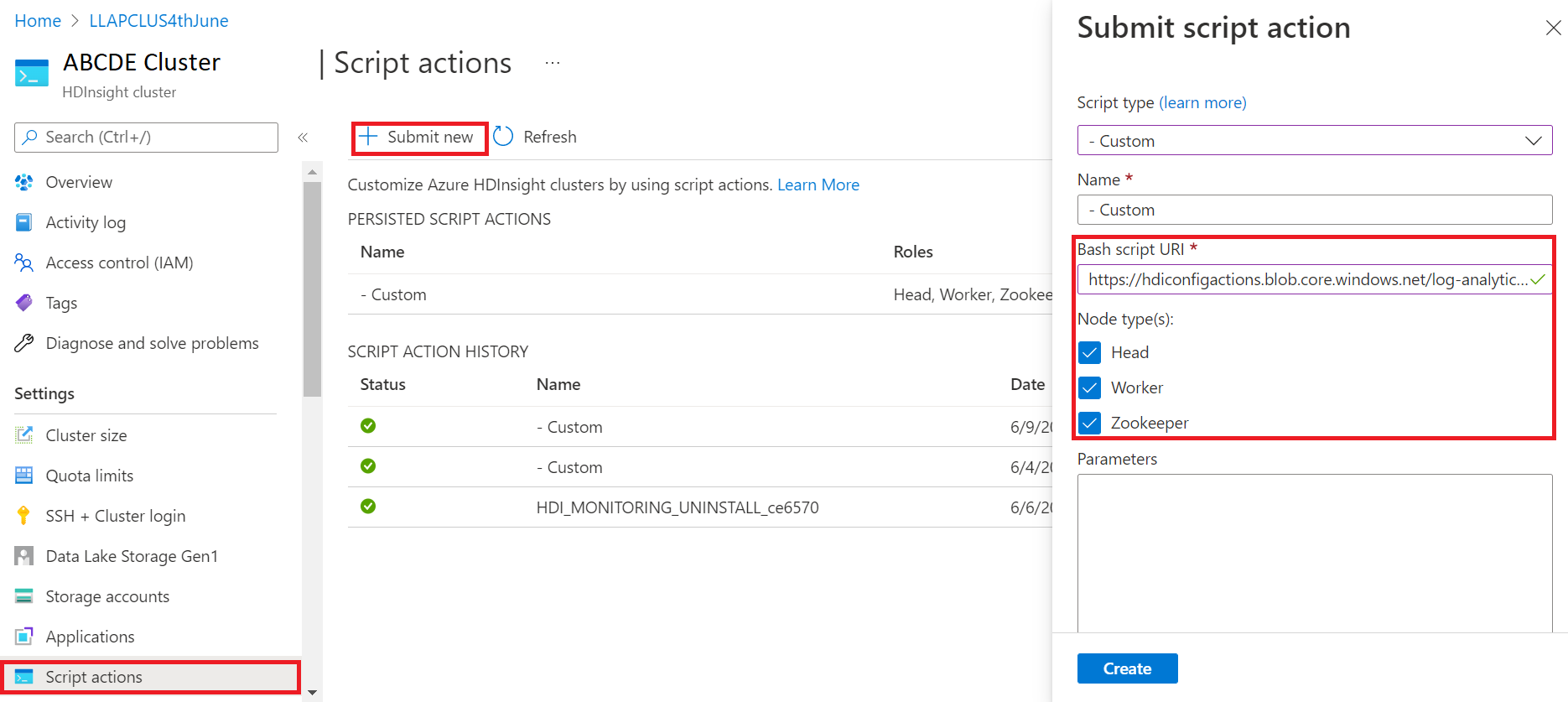
使用以下步骤验证是否成功安装补丁:
使用 SSH 登录到群集。
在 SSH 客户端中运行以下命令。
sudo /opt/omi/bin/ominiserver/ --version
其他 bug 修复
- 如果任何
TFile损坏或为空,Yarn 日志的 CLI 检索不到日志。 - 解决了从 Microsoft Entra ID 获取 OAuth 标记时出现的“服务主体详细信息无效”错误。
- 改进了在配置 100 多个工作节点时群集创建操作的可靠性。
开源 bug 修复
TEZ 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| Tez 生成失败:未找到 FileSaver.js | TEZ-4411 |
当仓库和 scratchdir 位于不同的 FS 上时出现“错误 FS”异常 |
TEZ-4406 |
| TezUtils::createByteStringFromConf 应使用 snappy,而不是 DeflaterOutputStream | TEZ-4113 |
| 将 protobuf 依赖项更新为 3.x | TEZ-4363 |
Hive 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| ORC 拆分生成中的 Perf 优化 | HIVE-21457 |
| 在表名称以“delta”开头,但表非事务性且使用 BI 拆分策略时,避免将表读取为 ACID | HIVE-22582 |
| 从 AcidUtils#getLogicalLength 中移除 FS#exists 调用 | HIVE-23533 |
| 矢量化 OrcAcidRowBatchReader.computeOffset 并优化 Bucket | HIVE-17917 |
已知问题
HDInsight 与 Apache HIVE 3.1.2 兼容。 由于此版本中存在 bug,Hive 版本在 Hive 接口中显示为 3.1.0。 不过,这对功能没有影响。
发布日期:2022/08/10
此版本适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。
HDInsight 使用涉及逐步区域部署的安全部署做法。 新发布或新版本最多可能需要 10 个工作日就能在所有区域中可用。
![]()
新功能
1. 在 HDI Hadoop/Spark 群集中附加外部磁盘
HDInsight 群集附带基于 SKU 的预定义磁盘空间。 在大型作业场景中,这个空间可能是不够的。
通过这项新功能,可在群集中添加更多磁盘,这些磁盘将用作节点管理器本地目录。 在 HIVE 和 Spark 群集创建期间,将磁盘数添加到工作器节点,而所选磁盘将成为节点管理器本地目录的一部分。
注意
添加的磁盘仅针对节点管理器本地目录进行配置。
有关详细信息,请参阅此文
2. 选择性日志记录分析
选择性日志记录分析现已在所有区域提供公共预览版。 可以将群集连接到 Log Analytics 工作区。 启用后,可以查看 HDInsight 安全日志、Yarn 资源管理器、系统指标等日志和指标。可以监视工作负载,并了解它们如何影响群集的稳定性。 通过选择性日志记录,可启用/禁用所有表,或者在 Log Analytics 工作区中启用选择性表。 可以调整每个表的源类型,因为在新版本的 Geneva 监视中,一个表有多个源。
- Geneva 监视系统使用 mdsd(MDS 守护程序),这是一种监视代理和 fluentd,用于使用统一的日志记录层收集日志。
- 选择性日志记录使用脚本操作来禁用/启用表及其日志类型。 由于未打开任何新端口或更改任何现有安全设置,因此没有安全更改。
- 脚本操作在所有指定节点上并行运行,并更改用于禁用/启用表及其日志类型的配置文件。
![]()
固定
Log Analytics
与运行 OMS 版本 13 的 Azure HDInsight 集成的 Log Analytics 需要升级到 OMS 版本 14 才能应用最新的安全更新。 使用 OMS 版本 13 的旧版群集的客户需要安装 OMS 版本 14 以满足安全要求。 (如何检查当前版本和安装版本 14)
如何检查当前的 OMS 版本
- 使用 SSH 登录到群集。
- 在 SSH 客户端中运行以下命令。
sudo /opt/omi/bin/ominiserver/ --version
如何将 OMS 版本从 13 升级到 14
- 登录到 Azure 门户
- 从资源组中选择 HDInsight 群集资源
- 选择“脚本操作”
- 在“提交脚本操作”面板中,为“脚本类型”选择“自定义”
- 在 Bash 脚本 URL 框中粘贴以下链接:https://hdiconfigactions.blob.core.chinacloudapi.cn/log-analytics-patch/OMSUPGRADE14.1/omsagent-vulnerability-fix-1.14.12-0.sh
- 选择“节点类型”
- 选择“创建”
使用以下步骤验证是否成功安装补丁:
使用 SSH 登录到群集。
在 SSH 客户端中运行以下命令。
sudo /opt/omi/bin/ominiserver/ --version
其他 bug 修复
- 如果任何
TFile损坏或为空,Yarn 日志的 CLI 检索不到日志。 - 解决了从 Microsoft Entra ID 获取 OAuth 标记时出现的“服务主体详细信息无效”错误。
- 改进了在配置 100 多个工作节点时群集创建操作的可靠性。
开源 bug 修复
TEZ 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| Tez 生成失败:未找到 FileSaver.js | TEZ-4411 |
当仓库和 scratchdir 位于不同的 FS 上时出现“错误 FS”异常 |
TEZ-4406 |
| TezUtils::createByteStringFromConf 应使用 snappy,而不是 DeflaterOutputStream | TEZ-4113 |
| 将 protobuf 依赖项更新为 3.x | TEZ-4363 |
Hive 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| ORC 拆分生成中的 Perf 优化 | HIVE-21457 |
| 在表名称以“delta”开头,但表非事务性且使用 BI 拆分策略时,避免将表读取为 ACID | HIVE-22582 |
| 从 AcidUtils#getLogicalLength 中移除 FS#exists 调用 | HIVE-23533 |
| 矢量化 OrcAcidRowBatchReader.computeOffset 并优化 Bucket | HIVE-17917 |
已知问题
HDInsight 与 Apache HIVE 3.1.2 兼容。 由于此版本中存在 bug,Hive 版本在 Hive 接口中显示为 3.1.0。 不过,这对功能没有影响。
发行日期:2022 年 6 月 3 日
此版本适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
版本特点
Spark v3.1.2 上的 Hive Warehouse Connector (HWC)
通过 Hive Warehouse Connector (HWC),可利用 Hive 和 Spark 的独特功能构建功能强大的大数据应用程序。 目前仅 Spark v2.4 支持 HWC。 通过允许使用 Spark 在 Hive 表上进行 ACID 事务,此功能增加了业务价值。 对于在数据资产中同时使用 Hive 和 Spark 的客户,此功能非常有用。 有关详细信息,请参阅 Apache Spark & Hive - Hive Warehouse Connector - Azure HDInsight | Azure
Ambari
- 缩放和预配改进更改
- HDI Hive 现在与 OSS 版本 3.1.2 兼容
HDI Hive 3.1 版本已升级到 OSS Hive 3.1.2。 此版本包含开源的 Hive 3.1.2 版本中提供的所有修补程序和功能。
注意
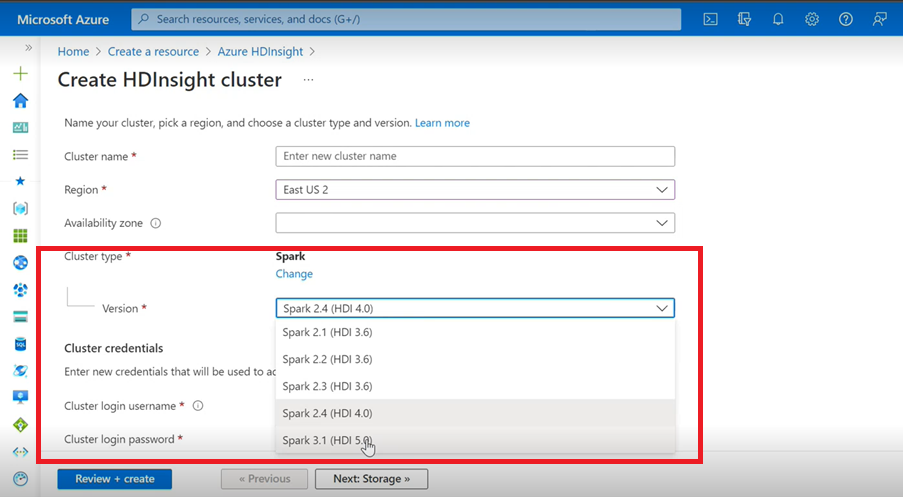
Spark
- 如果使用 Azure 用户界面为 HDInsight 创建 Spark 群集,会从下拉列表中看到另一个版本 Spark 3.1.(HDI 5.0) 以及旧版本。 此版本是 Spark 3.1.(HDI 4.0) 的重命名版本。 这只是 UI 级别的更改,不会影响现有用户和已使用 ARM 模板的用户的任何内容。
注意
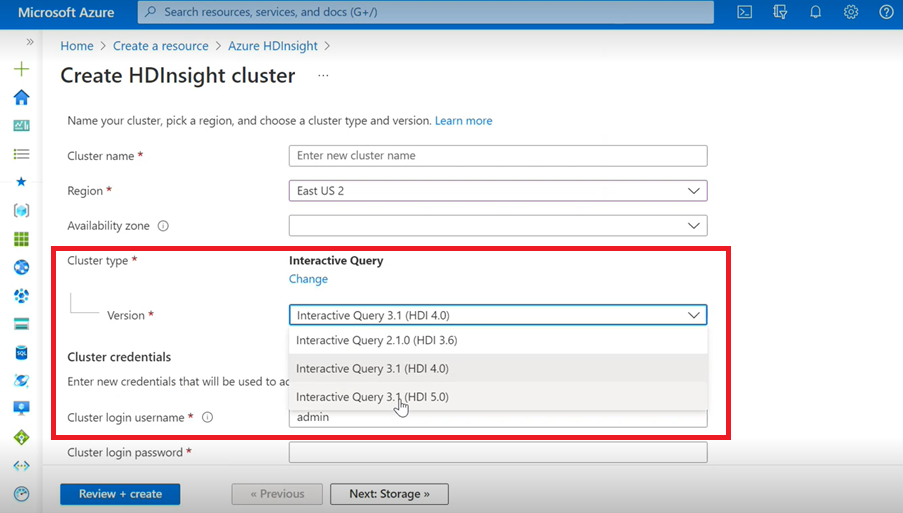
交互式查询
- 如果要创建 Interactive Query 群集,将在下拉列表中看到另一个版本,即 Interactive Query 3.1 (HDI 5.0)。
- 如果要将 Spark 3.1 版本与需要 ACID 支持的 Hive 一起使用,则需要选择此版本 Interactive Query 3.1 (HDI 5.0)。
TEZ 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| TezUtils createByteStringFromConf 应使用 snappy 而不是 DeflaterOutputStream | TEZ-4113 |
HBase 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
TableSnapshotInputFormat 应使用 ReadType.STREAM 扫描 HFiles |
HBASE-26273 |
| 添加了用于在 TableSnapshotInputFormat 中禁用 scanMetrics 的选项 | HBASE-26330 |
| 修复了执行负载均衡器时的 ArrayIndexOutOfBoundsException | HBASE-22739 |
Hive 的 bug 修复
| Bug 修复 | Apache JIRA |
|---|---|
| 使用 dynpart 排序优化插入具有“distribute by”子句的数据时的 NPE | HIVE-18284 |
| 删除分区时分区筛选失败的 MSCK REPAIR 命令 | HIVE-23851 |
| 如果 capacity<=0,则引发错误异常 | HIVE-25446 |
| 支持 HastTable 的并行加载 - 接口 | HIVE-25583 |
| 默认情况下,在 HiveServer2 中包含 MultiDelimitSerDe | HIVE-20619 |
| 从 jdbc-standalone jar 中删除 glassfish.jersey 和 mssql-jdbc 类 | HIVE-22134 |
| 针对 MM 表运行压缩时出现空指针异常。 | HIVE-21280 |
通过 knox 进行大型 Hive 查询失败,并且中断管道写入失败 |
HIVE-22231 |
| 添加了用户设置绑定用户的功能 | HIVE-21009 |
| 实现了 UDF 以使用其内部表示形式和公历-儒略历混合日历来解释日期/时间戳 | HIVE-22241 |
| 用于显示/不显示执行报告的 Beeline 选项 | HIVE-22204 |
| Tez:SplitGenerator 尝试查找对于 Tez 不存在的计划文件 | HIVE-22169 |
从 LLAP 缓存 hotpath 中移除了开销很高的日志记录 |
HIVE-22168 |
| UDF:FunctionRegistry 在 org.apache.hadoop.hive.ql.udf.UDFType 类上进行了同步 | HIVE-22161 |
| 如果属性设置为 false,则阻止创建查询路由追加器 | HIVE-22115 |
| 删除 partition-eval 的跨查询同步 | HIVE-22106 |
| 在规划过程中跳过设置 Hive 暂存目录 | HIVE-21182 |
| 如果 RPC 已启用,则跳过为 tez 创建暂存目录 | HIVE-21171 |
切换 Hive UDF 以使用 Re2J 正则表达式引擎 |
HIVE-19661 |
| hive 3 上使用 bucketing_version 1 迁移的聚集表使用 bucketing_version 2 进行插入 | HIVE-22429 |
| Bucket 存储:Bucket 存储版本 1 错误地对数据进行分区 | HIVE-21167 |
| 将 ASF 许可证标头添加到新添加的文件 | HIVE-22498 |
| 用于支持 mergeCatalog 的架构工具增强功能 | HIVE-22498 |
| 具有 TEZ UNION ALL 和 UDTF 的 Hive 会导致数据丢失 | HIVE-21915 |
| 即使存在页眉/页脚,也会拆分文本文件 | HIVE-21924 |
| 如果加载的文件的列数多于表架构中存在的列数,则 MultiDelimitSerDe 会在最后一列中返回错误结果 | HIVE-22360 |
| LLAP 外部客户端 - 需要减少 LlapBaseInputFormat#getSplits() 占用 | HIVE-22221 |
| 在重写包括对有掩码列的表进行联接的查询时,没有转义具有保留关键字的列名称(Zoltan Matyus 通过 Zoltan Haindrich) | HIVE-22208 |
防止 AMReporter 相关 RuntimeException 上的 LLAP 关闭 |
HIVE-22113 |
| LLAP 状态服务驱动程序可能因 Yarn 应用 ID 错误而停滞 | HIVE-21866 |
| OperationManager.queryIdOperation 没有正确清理多个 queryId | HIVE-22275 |
| 关闭节点管理器阻止重启 LLAP 服务 | HIVE-22219 |
| 删除大量分区时的 Stack OverflowError | HIVE-15956 |
| 删除临时目录时访问检查失败 | HIVE-22273 |
| 修复了特定边界条件下左外部映射联接中的错误结果/ArrayOutOfBound 异常 | HIVE-22120 |
| 从 pom.xml 中删除了分发管理标记 | HIVE-19667 |
| 如果存在深层嵌套子查询,分析时间可能会很长 | HIVE-21980 |
对于 ALTER TABLE t SET TBLPROPERTIES ('EXTERNAL'='TRUE');,TBL_TYPE 属性更改未反映非大写字母 |
HIVE-20057 |
JDBC:HiveConnection 对 log4j 界面进行着色 |
HIVE-18874 |
更新 poms 中的存储库 URL - 分支 3.1 版本 |
HIVE-21786 |
主数据库和分支 3.1 上的 DBInstall 测试中断 |
HIVE-21758 |
| 将数据加载到已进行 Bucket 存储的表中会忽略分区规格,并将数据加载到默认分区中 | HIVE-21564 |
| 带时间戳或带有本地时区文字的时间戳的联接条件的查询引发 SemanticException | HIVE-21613 |
| 分析遗留在 HDFS 上的暂存目录中的列的计算统计信息 | HIVE-21342 |
| Hive Bucket 计算中的不兼容更改 | HIVE-21376 |
| 当未使用其他授权者时,提供了回退授权者 | HIVE-20420 |
| 某些 alterPartitions 调用引发了“NumberFormatException: null” | HIVE-18767 |
| HiveServer2:在某些情况下,HTTP 传输的预身份验证主题不会在整个 HTTP 通信期间保留 | HIVE-20555 |
发布日期:03/10/2022
此版本适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
此发行版的 OS 版本为:
- HDInsight 4.0:Ubuntu 18.04.5
Spark 3.1 现已推出正式版
Spark 3.1 现已在 HDInsight 版本 4.0 中推出正式版。 此版本包括
- 自适应查询执行;
- 将排序合并联接转换为广播哈希联接;
- Spark Catalyst Optimizer;
- 动态分区修剪;
- 客户将能够创建新的 Spark 3.1 群集,而不是 Spark 3.0(预览版)群集。
有关详细信息,请参阅 Apache Spark 3.1 现已在 HDInsight 上推出正式版 - Azure 技术社区。
有关改进的完整列表,请参阅 Apache Spark 3.1 发行说明。
有关迁移的详细信息,请参阅迁移指南。
Kafka 2.4 现已推出正式版
Kafka 2.4.1 现已推出正式版。 有关详细信息,请参阅 Kafka 2.4.1 发行说明。其他功能包括 MirrorMaker 2 可用性、新的指标类别 AtMinIsr 主题分区、通过索引文件的按需延迟 mmap 改进代理启动时间,以及其他用于观察用户轮询行为的使用者指标。
HDInsight 4.0 现在支持 HWC 中的映射数据类型
此版本包括通过 spark-shell 应用程序和 HWC 支持的所有其他 spark 客户端,提供对 HWC 1.0 (Spark 2.4) 的映射数据类型的支持。 与任何其他数据类型一样包括以下改进:
用户可以
- 使用包含映射数据类型的任何列创建 Hive 表,将数据插入该表并从中读取结果。
- 创建具有映射类型的 Apache Spark 数据帧,并执行批/流读取和写入。
新区域
HDInsight 现已将其地理区域扩展到两个新区域:中国东部 2 3 和中国北部 3。
OSS 后向移植更改
Hive 中包含 OSS 后向移植,这包括支持映射数据类型的 HWC 1.0 (Spark 2.4)。
下面是此版本的 OSS 后向移植 Apache JIRA:
| 受影响的功能 | Apache JIRA |
|---|---|
| 应根据 SQL DB 允许的最大参数拆分包含 IN/(NOT IN) 的元存储直接 SQL 查询 | HIVE-25659 |
将 log4j 从 2.16.0 升级到 2.17.0 |
HIVE-25825 |
更新 Flatbuffer 版本 |
HIVE-22827 |
| 原生支持 Arrow 格式的映射数据类型 | HIVE-25553 |
| LLAP 外部客户端 - 当父结构为 null 时处理嵌套值 | HIVE-25243 |
| 将 arrow 版本升级到 0.11.0 | HIVE-23987 |
弃用通告
HDInsight 上的 Azure 虚拟机规模集
HDInsight 将不再使用 Azure 虚拟机规模集来预配群集,但预期不会发生中断性变更。 虚拟机规模集上的现有 HDInsight 群集没有任何影响,最新映像上的任何新群集将不再使用虚拟机规模集。
现在仅支持使用手动缩放来缩放 Azure HDInsight HBase 工作负载
从 2022 年 3 月 1 日开始,HDInsight 仅支持手动缩放 HBase,但对正在运行的群集没有影响。 新的 HBase 群集将无法启用基于计划的自动缩放。 若要详细了解如何手动缩放 HBase 群集,请参阅有关手动缩放 Azure HDInsight 群集的文档
发布日期:2021/12/27
此版本适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
此发行版的 OS 版本为:
- HDInsight 4.0:Ubuntu 18.04.5 LTS
HDInsight 4.0 映像已更新,以缓解 Log4j 漏洞,如 Azure 对 CVE-2021-44228 Apache Log4j 2 的响应中所述。
注意
- 在 UTC 2021 年 12 月 27 日 00:00 之后创建的任何 HDI 4.0 群集都使用更新版映像创建,该映像可缓解
log4j漏洞。 因此,客户无需修补/重新启动这些群集。 - 对于在 UTC 2021 年 12 月 16 日 01:15 到 UTC 2021 年 12 月 27 日 00:00 之间创建的新 HDInsight 4.0 群集、HDInsight 3.6 或 2021 年 12 月 16 日之后在固定订阅中的群集,将在创建群集的时间内自动应用补丁,但客户必须随后重新启动其节点才能完成修补(Kafka 管理节点除外,这些节点自动重新启动)。
发布日期:2021/07/27
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
此发行版的 OS 版本为:
- HDInsight 3.6:Ubuntu 16.04.7 LTS
- HDInsight 4.0:Ubuntu 18.04.5 LTS
新功能
Azure HDInsight 对受限公共连接的支持已于 2021 年 10 月 15 日正式发布
Azure HDInsight 现在支持所有区域中的受限公共连接。 下面是此功能的一些亮点:
- 可以反向资源提供程序到群集的通信,使群集可以出站连接到资源提供程序
- 支持自带已启用专用链接的资源(例如存储、SQL、密钥保管库),使 HDInsight 群集能够仅通过专用网络访问资源
- 不为任何资源预配公共 IP 地址
使用此新功能,还可跳过 HDInsight 管理 IP 的入站网络安全组 (NSG) 服务标记规则。 详细了解如何限制公共连接
Azure HDInsight 对 Azure 专用链接的支持已于 2021 年 10 月 15 日正式发布
现在可以使用专用终结点通过专用链接连接到 HDInsight 群集。 在 VNET 对等互连不可用或未启用的跨 VNET 方案中,可以使用专用链接。
使用 Azure 专用链接,可以通过虚拟网络中的专用终结点访问 Azure PaaS 服务(例如,Azure 存储和 SQL 数据库)和 Azure 托管的客户拥有的服务/合作伙伴服务。
虚拟网络与服务之间的流量将遍历 Microsoft Azure 主干网络。 不再需要向公共 Internet 公开服务。
在启用专用链接中了解详细信息。
新的 Azure Monitor 集成体验(预览版)
新的Azure监视器集成体验将在中国东部 2 和中国北部 3 版推出。 请在此处详细了解新的 Azure Monitor 体验。
弃用
HDInsight 3.6 版本从 2022 年 10 月 1 日起已弃用。
行为更改
HDInsight Interactive Query 仅支持基于计划的自动缩放
随着客户方案日益成熟和多样化,我们发现 Interactive Query (LLAP) 基于负载的自动缩放存在一些限制。 存在这些限制的原因可能是 LLAP 查询动态的性质、未来的负载预测准确性问题以及 LLAP 计划程序任务重新分发中的问题。 由于这些限制,用户可能会发现,当启用自动缩放时,LLAP 群集上的查询运行速度变慢了。 对性能的影响可能会超过自动缩放的成本优势。
从 2021 年 7 月开始,HDInsight 中的 Interactive Query 工作负载仅支持基于计划的自动缩放。 无法再对新的 Interactive Query 群集启用基于负载的自动缩放。 现有正在运行的群集可以继续运行,但存在上述已知限制。
Azure 建议你改用基于计划的自动缩放以使用 LLAP。 可以通过 Grafana Hive 仪表板分析群集的当前使用模式。 有关详细信息,请参阅自动缩放 Azure HDInsight 群集。
即将推出的更改
即将推出的版本中将发生以下更改。
ESP Spark 群集中的内置 LLAP 组件将被删除
HDInsight 4.0 ESP Spark 群集的内置 LLAP 组件在两个头节点上运行。 ESP Spark 群集中的 LLAP 组件最初是为 HDInsight 3.6 ESP Spark 添加的,但在 HDInsight 4.0 ESP Spark 中没有实际用例。 在计划于 2021 年 9 月发布的下一版本中,HDInsight 将删除 HDInsight 4.0 ESP Spark 群集中的内置 LLAP 组件。 此更改有助于消除头节点工作负载,并避免混淆 ESP Spark 和 ESP Interactive Hive 群集类型。
新区域
- 中国北部 3
-
Jio印度西部 - 澳大利亚中部
组件版本更改
此版本更改了以下组件版本:
- 从 1.5.1 到 1.5.9 的 ORC 版本
可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
向后移植 JIRA
下面是此版本向后移植的 Apache JIRA:
| 受影响的功能 | Apache JIRA |
|---|---|
| 日期/时间戳 | HIVE-25104 |
| HIVE-24074 | |
| HIVE-22840 | |
| HIVE-22589 | |
| HIVE-22405 | |
| HIVE-21729 | |
| HIVE-21291 | |
| HIVE-21290 | |
| UDF | HIVE-25268 |
| HIVE-25093 | |
| HIVE-22099 | |
| HIVE-24113 | |
| HIVE-22170 | |
| HIVE-22331 | |
| ORC | HIVE-21991 |
| HIVE-21815 | |
| HIVE-21862 | |
| 表架构 | HIVE-20437 |
| HIVE-22941 | |
| HIVE-21784 | |
| HIVE-21714 | |
| HIVE-18702 | |
| HIVE-21799 | |
| HIVE-21296 | |
| 工作负载管理 | HIVE-24201 |
| 压缩 | HIVE-24882 |
| HIVE-23058 | |
| HIVE-23046 | |
| 具体化视图 | HIVE-22566 |
HDInsight Dv2 虚拟机的价格更正
HDInsight 上 Dv2 VM 系列的定价错误已于 2021 年 4 月 25 日更正。 此定价错误导致某些客户在 4 月 25 日之前的帐单收费降低,经过更正后,现在的价格已与 HDInsight 定价页和 HDInsight 定价计算器上公布的价格相匹配。 此定价错误影响了在以下区域中使用 Dv2 VM 的客户:
- 加拿大中部
- 加拿大东部
- 中国东部 2
- 南非北部
- 中国东部 2
- 阿拉伯联合酋长国中部
从 2021 年 4 月 25 日开始,更正后的 Dv2 VM 收费金额将应用于你的帐户。 客户通知已在更改之前发送给订阅所有者。 你可以使用定价计算器、HDInsight 定价页或 Azure 门户中的“创建 HDInsight 群集”边栏选项卡,查看你所在区域中 Dv2 VM 更正后的成本。
你无需执行任何其他操作。 价格更正仅适用于指定地区在 2021 年 4 月 25 日或之后的使用情况,而不是此日期之前的任何使用情况。 为确保你拥有最高性能和经济高效的解决方案,我们建议你查看 Dv2 群集的定价、vCPU 和 RAM,并比较 Dv2 与 Ev3 VM 的规格,以了解你的解决方案是否能从使用某一较新的 VM 系列中受益。
发行日期:06/02/2021
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
此发行版的 OS 版本为:
- HDInsight 3.6:Ubuntu 16.04.7 LTS
- HDInsight 4.0:Ubuntu 18.04.5 LTS
新功能
OS 版本升级
如 Ubuntu 发布周期中所述,Ubuntu 16.04 内核于 2021 年 4 月终止生命周期 (EOL)。 我们已开始通过此发行版推出在 Ubuntu 18.04 上运行的新 HDInsight 4.0 群集映像。 新版本可用后,默认情况下,新创建的 HDInsight 4.0 群集将在 Ubuntu 18.04 上运行。 Ubuntu 16.04 上的现有群集按原样运行,并可获得完全支持。
HDInsight 3.6 将继续在 Ubuntu 16.04 上运行。 从 2021 年 7 月 1 日开始,这种支持将从标准支持更改为基本支持。 有关日期和支持选项的详细信息,请参阅 Azure HDInsight 版本。 HDInsight 3.6 不支持 Ubuntu 18.04。 若要使用 Ubuntu 18.04,需要将群集迁移到 HDInsight 4.0。
若要将现有 HDInsight 4.0 群集迁移到 Ubuntu 18.04,需要删除再重新创建群集。 请计划好在 Ubuntu 18.04 支持发布后创建或重新创建群集。
创建新群集后,可以通过 SSH 连接到群集,并运行 sudo lsb_release -a 来验证它是否在 Ubuntu 18.04 上运行。 建议先在测试订阅中测试你的应用程序,然后再将其转移到生产环境。
HBase 加速写入群集上的缩放优化
HDInsight 对已启用 HBase 加速写入的群集的缩放做出了一些改进和优化。 详细了解 HBase 加速写入。
弃用
此版本没有任何弃用功能。
行为更改
禁用将 Standard_A5 VM 大小作为 HDInsight 4.0 的头节点
HDInsight 群集头节点负责初始化和管理群集。 对于 HDInsight 4.0,Standard_A5 VM 大小作为头节点存在可靠性问题。 从此版本开始,客户将无法创建以 Standard_A5 VM 大小作为头节点的新群集。 可以使用其他双核 VM,例如 E2_v3 或 E2s_v3。 现有群集将照常运行。 强烈建议使用四核 VM 作为头节点,以确保生产 HDInsight 群集的高可用性和可靠性。
对于在 Azure 虚拟机规模集上运行的群集,网络接口资源不可见
HDInsight 正在逐步迁移到 Azure 虚拟机规模集。 对于使用 Azure 虚拟机规模集的群集的客户,虚拟机的网络接口不再可见。
即将推出的更改
即将发布的版本中将推出以下变更。
HDInsight Interactive Query 仅支持基于计划的自动缩放
随着客户方案日益成熟和多样化,我们发现 Interactive Query (LLAP) 基于负载的自动缩放存在一些限制。 存在这些限制的原因可能是 LLAP 查询动态的性质、未来的负载预测准确性问题以及 LLAP 计划程序任务重新分发中的问题。 由于这些限制,用户可能会发现,当启用自动缩放时,LLAP 群集上的查询运行速度变慢了。 对性能的影响可能会超过自动缩放的成本优势。
从 2021 年 7 月开始,HDInsight 中的 Interactive Query 工作负载仅支持基于计划的自动缩放。 无法再在新的 Interactive Query 群集上启用自动缩放。 现有正在运行的群集可以继续运行,但存在上述已知限制。
Azure 建议你改用基于计划的自动缩放以使用 LLAP。 可以通过 Grafana Hive 仪表板分析群集的当前使用模式。 有关详细信息,请参阅自动缩放 Azure HDInsight 群集。
VM 主机命名将在 2021 年 7 月 1 日更改
HDInsight 目前使用 Azure 虚拟机来预配群集。 此服务正在逐步迁移到 Azure 虚拟机规模集。 此迁移将改变群集主机名 FQDN 名称格式,并且也不能保证按顺序显示主机名中的编号。 若要获取每个节点的 FQDN 名称,请参阅查找群集节点的主机名。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 该服务将逐步迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
发布日期:2021/03/24
新功能
Spark 3.0 预览版
HDInsight 在 HDInsight 4.0 中添加了 Spark 3.0.0 支持作为预览功能。
Kafka 2.4 预览版
HDInsight 在 HDInsight 4.0 中添加了 Kafka 2.4.1 支持作为预览功能。
Eav4 系列支持
HDInsight 在此版本中添加了 Eav4 系列支持。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 此服务正在逐步迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
此版本没有任何弃用功能。
行为更改
默认群集版本更改为 4.0
HDInsight 群集的默认版本从 3.6 更改为 4.0。 有关可用版本的详细信息,请参阅可用版本。 详细了解 HDInsight 4.0 中的新增功能。
默认的群集 VM 大小更改为 Ev3 系列
默认的群集 VM 大小从 D 系列更改为 Ev3 系列。 此更改适用于头节点和工作器节点。 为避免此更改影响你已测试的工作流,请在 ARM 模板中指定要使用的 VM 大小。
对于在 Azure 虚拟机规模集上运行的群集,网络接口资源不可见
HDInsight 正在逐步迁移到 Azure 虚拟机规模集。 对于使用 Azure 虚拟机规模集的群集的客户,虚拟机的网络接口不再可见。
即将推出的更改
即将发布的版本中将推出以下变更。
HDInsight Interactive Query 仅支持基于计划的自动缩放
随着客户方案日益成熟和多样化,我们发现 Interactive Query (LLAP) 基于负载的自动缩放存在一些限制。 存在这些限制的原因可能是 LLAP 查询动态的性质、未来的负载预测准确性问题以及 LLAP 计划程序任务重新分发中的问题。 由于这些限制,用户可能会发现,当启用自动缩放时,LLAP 群集上的查询运行速度变慢了。 对性能的影响可能会超过自动缩放的成本优势。
从 2021 年 7 月开始,HDInsight 中的 Interactive Query 工作负载仅支持基于计划的自动缩放。 无法再在新的 Interactive Query 群集上启用自动缩放。 现有正在运行的群集可以继续运行,但存在上述已知限制。
Azure 建议你改用基于计划的自动缩放以使用 LLAP。 可以通过 Grafana Hive 仪表板分析群集的当前使用模式。 有关详细信息,请参阅自动缩放 Azure HDInsight 群集。
OS 版本升级
HDInsight 群集当前正在 Ubuntu 16.04 LTS 上运行。 像 Ubuntu 发行周期中提及的那样,Ubuntu 16.04 内核将在 2021 年 4 月生命周期结束 (EOL)。 我们将于 2021 年 5 月开始推出在 Ubuntu 18.04 上运行的新的 HDInsight 4.0 群集映像。 新创建的 HDInsight 4.0 群集将在可用时在 Ubuntu 18.04 上运行。 Ubuntu 16.04 上的现有群集将按原样运行,并受到完全支持。
HDInsight 3.6 将继续在 Ubuntu 16.04 上运行。 它将在 2021 年 6 月 30 日结束标准支持,并从 2021 年 7 月 1 日起改为标准支持。 有关日期和支持选项的详细信息,请参阅 Azure HDInsight 版本。 HDInsight 3.6 不支持 Ubuntu 18.04。 若要使用 Ubuntu 18.04,需要将群集迁移到 HDInsight 4.0。
若要将现有群集迁移到 Ubuntu 18.04,需要删除并重新创建群集。 Ubuntu 18.04 支持推出后,请计划创建或重新创建群集。 新映像在所有区域中可用后,我们会再发送一个通知。
强烈建议你对 Ubuntu 18.04 虚拟机 (VM) 的边缘节点上部署的脚本操作和自定义应用程序进行提前测试。 可以在 18.04-LTS 上创建 Ubuntu Linux VM,然后在 VM 上创建并使用安全外壳 (SSH) 密钥对,以运行和测试在边缘节点上部署的脚本操作和自定义应用程序。
禁用将 Standard_A5 VM 大小作为 HDInsight 4.0 的头节点
HDInsight 群集头节点负责初始化和管理群集。 对于 HDInsight 4.0,Standard_A5 VM 大小作为头节点存在可靠性问题。 从 2021 年 5 月的下一版本开始,客户将无法创建以 Standard_A5 VM 大小作为头节点的新群集。 你可以使用其他 2 核 VM,例如 E2_v3 或 E2s_v3。 现有群集将照常运行。 我们强烈推荐使用 4 核 VM 作为头节点,以确保生产 HDInsight 群集的高可用性和高可靠性。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
添加了 Spark 3.0.0 和 Kafka 2.4.1 支持作为预览功能。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发布日期:2021 年 2 月 5 日
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
Dav4 系列支持
HDInsight 在此版本中添加了 Dav4 系列支持。 可以在此处详细了解 Dav4 系列。
Kafka REST Proxy 正式发布
使用 Kafka REST 代理可以通过基于 HTTPS 的 REST API 与 Kafka 群集交互。 从此版本开始,Kafka REST 代理正式发布。 可以在此处详细了解 Kafka REST 代理。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 此服务正在逐步迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
禁用的 VM 大小
自 2021 年 1 月 9 日起,HDInsight 将阻止所有客户使用 standard_A8、standard_A9、standard_A10 和 standard_A11 VM 大小创建群集。 现有群集将照常运行。 请考虑迁移到 HDInsight 4.0,避免出现潜在的系统/支持中断。
行为更改
默认的群集 VM 大小更改为 Ev3 系列
默认的群集 VM 大小将从 D 系列更改为 Ev3 系列。 此更改适用于头节点和工作器节点。 为避免此更改影响你已测试的工作流,请在 ARM 模板中指定要使用的 VM 大小。
对于在 Azure 虚拟机规模集上运行的群集,网络接口资源不可见
HDInsight 正在逐步迁移到 Azure 虚拟机规模集。 对于使用 Azure 虚拟机规模集的群集的客户,虚拟机的网络接口不再可见。
即将推出的更改
即将发布的版本中将推出以下变更。
默认群集版本将更改为 4.0
自 2021 年 2 月起,HDInsight 群集的默认版本将从 3.6 更改为 4.0。 有关可用版本的详细信息,请参阅可用版本。 详细了解 HDInsight 4.0 中的新增功能。
OS 版本升级
HDInsight 正在将 OS 版本从 Ubuntu 16.04 升级到 18.04。 此升级将在 2021 年 4 月之前完成。
将于 2021 年 6 月 30 日终止支持 HDInsight 3.6
将终止支持 HDInsight 3.6。 自 2021 年 6 月 30 日起,客户无法创建新的 HDInsight 3.6 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑迁移到 HDInsight 4.0,避免出现潜在的系统/支持中断。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/11/18
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
为客户管理的密钥静态加密自动轮替密钥
从此版本开始,客户可使用不限 Azure KeyValut 版本的加密密钥 URL 来实现客户管理的密钥静态加密。 密钥过期时,HDInsight 会自动轮替密钥,或将其替换为新的版本。 请访问此处了解更多详细信息。
能够为 Spark、Hadoop 和 ML 服务选择不同的 Zookeeper 虚拟机大小
HDInsight 之前不支持为 Spark、Hadoop 和 ML 服务群集类型自定义 Zookeeper 节点大小。 默认情况下为 A2_v2/A2 虚拟机大小(免费提供)。 从此版本开始,你可以选择最适合自己方案的 Zookeeper 虚拟机大小。 虚拟机大小不是 A2_v2/A2 的 Zookeeper 节点需要付费。 A2_v2 和 A2 虚拟机仍免费提供。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从此版本开始,该服务将逐渐迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
弃用 HDInsight 3.6 ML 服务群集
HDInsight 3.6 ML 服务群集类型将于 2020 年 12 月 31 日终止支持。 2020 年 12 月 31 日之后,客户将不能创建新的 3.6 ML 服务群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请在此处检查 HDInsight 版本的有效期限和群集类型。
禁用的 VM 大小
自 2020 年 11 月 16 日起,HDInsight 将阻止新客户使用 standard_A8、standard_A9、standard_A10 和 standard_A11 VM 大小创建群集。 过去三个月内使用过这些 VM 大小的现有客户将不会受到影响。 自 2021 年 1 月 9 日起,HDInsight 将阻止所有客户使用 standard_A8、standard_A9、standard_A10 和 standard_A11 VM 大小创建群集。 现有群集将照常运行。 请考虑迁移到 HDInsight 4.0,避免出现潜在的系统/支持中断。
行为更改
添加在缩放操作前进行的 NSG 规则检查
HDInsight 为缩放操作添加了网络安全组 (NSG) 和用户定义的路由 (UDR) 检查。 除了群集创建外,还会对群集缩放执行相同的验证。 此验证有助于防止不可预知的错误。 如果验证未通过,则缩放会失败。 若要详细了解如何正确配置 NSG 和 UDR,请参阅 HDInsight 管理 IP 地址。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/11/09
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
HDInsight 标识中介 (HIB) 现已正式发布
为 ESP 群集启用 OAuth 身份验证的 HDInsight 标识中介 (HIB) 现已在此版本中正式发布。 在发布此版本后创建的 HIB 群集将提供最新的 HIB 功能:
- 高可用性 (HA)
- 支持多重身份验证 (MFA)
- 不使用密码哈希同步到 AAD-DS 的联合用户登录。有关详细信息,请参阅 HIB 文档。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从此版本开始,该服务将逐渐迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
弃用 HDInsight 3.6 ML 服务群集
HDInsight 3.6 ML 服务群集类型将于 2020 年 12 月 31 日终止支持。 2020 年 12 月 31 日之后,客户将不会创建新的 3.6 ML 服务群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请在此处检查 HDInsight 版本的有效期限和群集类型。
禁用的 VM 大小
自 2020 年 11 月 16 日起,HDInsight 将阻止新客户使用 standard_A8、standard_A9、standard_A10 和 standard_A11 VM 大小创建群集。 过去三个月内使用过这些 VM 大小的现有客户将不会受到影响。 自 2021 年 1 月 9 日起,HDInsight 将阻止所有客户使用 standard_A8、standard_A9、standard_A10 和 standard_A11 VM 大小创建群集。 现有群集将照常运行。 请考虑迁移到 HDInsight 4.0,避免出现潜在的系统/支持中断。
行为更改
此版本没有行为变更。
即将推出的更改
即将发布的版本中将推出以下变更。
能够为 Spark、Hadoop 和 ML 服务选择不同的 Zookeeper 虚拟机大小
目前,HDInsight 不支持为 Spark、Hadoop 和 ML 服务群集类型自定义 Zookeeper 节点大小。 默认情况下为 A2_v2/A2 虚拟机大小(免费提供)。 在即将发布的版本中,可以选择最适合自己方案的 Zookeeper 虚拟机大小。 虚拟机大小不是 A2_v2/A2 的 Zookeeper 节点需要付费。 A2_v2 和 A2 虚拟机仍免费提供。
默认群集版本将更改为 4.0
自 2021 年 2 月起,HDInsight 群集的默认版本将从 3.6 更改为 4.0。 有关可用版本的详细信息,请参阅受支持的版本。 详细了解 HDInsight 4.0 中的新增功能
将于 2021 年 6 月 30 日终止支持 HDInsight 3.6
将终止支持 HDInsight 3.6。 自 2021 年 6 月 30 日起,客户无法创建新的 HDInsight 3.6 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑迁移到 HDInsight 4.0,避免出现潜在的系统/支持中断。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
解决重启群集中的 VM 时出现的问题
解决了重启群集中的 VM 时出现的问题,又可以使用 PowerShell 或 REST API 重启群集中的节点了。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/10/08
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
没有公共 IP 和专用链接的 HDInsight 专用群集(预览版)
HDInsight 现支持创建没有公共 IP 和专用链接(用于访问相应群集)的群集(处于预览状态)。 客户可以使用新的高级网络设置来创建没有公共 IP 的完全独立的群集,并可以使用自己的专用终结点来访问该群集。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从此版本开始,该服务将逐渐迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
弃用 HDInsight 3.6 ML 服务群集
HDInsight 3.6 ML 服务群集类型将于 2020 年 12 月 31 日终止支持。 之后,客户将不会创建新的 3.6 ML 服务群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请在此处检查 HDInsight 版本的有效期限和群集类型。
行为更改
此版本没有行为变更。
即将推出的更改
即将发布的版本中将推出以下变更。
能够为 Spark、Hadoop 和 ML 服务选择不同的 Zookeeper 虚拟机大小
目前,HDInsight 不支持为 Spark、Hadoop 和 ML 服务群集类型自定义 Zookeeper 节点大小。 默认情况下为 A2_v2/A2 虚拟机大小(免费提供)。 在即将发布的版本中,可以选择最适合自己方案的 Zookeeper 虚拟机大小。 虚拟机大小不是 A2_v2/A2 的 Zookeeper 节点需要付费。 A2_v2 和 A2 虚拟机仍免费提供。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/09/28
此版本适用于 HDInsight 3.6 和 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
对于 HDInsight 4.0,Interactive Query 的自动缩放现已正式发布
对于 HDInsight 4.0,Interactive Query 群集类型的自动缩放现已正式发布 (GA)。 2020 年 8 月 27 日之后创建的所有 Interactive Query 4.0 群集都将对自动缩放功能提供 GA 支持。
HBase 群集支持高级 ADLS Gen2
HDInsight 现在支持将高级 ADLS Gen2 作为 HDInsight HBase 3.6 和 4.0 群集的主要存储帐户。 不仅可以加速写入,还可以获得更佳的 HBase 群集性能。
Azure 容错域上的 Kafka 分区分发
容错域是 Azure 数据中心基础硬件的逻辑分组。 每个容错域共享公用电源和网络交换机。 在 HDInsight 之前,Kafka 可能会将所有分区副本存储在同一容错域中。 从此版本开始,HDInsight 现支持根据 Azure 容错域自动分发 Kafka 分区。
传输中加密
客户可以使用 IPsec 加密和平台管理的密钥在群集节点之间启用传输中加密。 可以在创建群集时启用此选项。 查看有关如何启用传输中加密的更多详细信息。
主机加密
启用主机加密时,存储在 VM 主机上的数据将静态加密,且已加密的数据将流向存储服务。 在此版本中,可以在创建群集时在临时数据磁盘上启用主机加密。 只有有限区域中的某些 VM SKU 上支持主机加密。 HDInsight 支持以下节点配置和 SKU。 查看有关如何启用主机加密的更多详细信息。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从此版本开始,该服务将逐渐迁移到 Azure 虚拟机规模集。 整个过程可能需要数月时间。 迁移区域和订阅后,新创建的 HDInsight 群集将在虚拟机规模集上运行,而无需客户执行任何操作。 预计不会有中断性变更。
弃用
此版本没有任何弃用功能。
行为更改
此版本没有行为变更。
即将推出的更改
即将发布的版本中将推出以下变更。
能够为 Spark、Hadoop 和 ML 服务选择不同的 Zookeeper SKU
HDInsight 目前不支持更改 Spark、Hadoop 和 ML 服务群集类型的 Zookeeper SKU。 它为 Zookeeper 节点使用 A2_v2/A2 SKU,客户无需对此付费。 在即将发布的版本中,客户可以按需更改 Spark、Hadoop 和 ML 服务的 Zookeeper SKU。 会对不使用 A2_v2/A2 SKU 的 Zookeeper 节点收取费用。 默认 SKU 仍为 A2_V2/A2 并免费。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/08/09
此版本仅适用于 HDInsight 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
对 SparkCruise 的支持
SparkCruise 是 Spark 的自动计算重用系统。 它基于过去的查询工作负载选择要具体化的常见子表达式。 SparkCruise 将这些子表达式具体化为查询处理的一部分,系统会在后台自动应用计算重用。 无需对 Spark 代码进行任何修改,就可以通过 SparkCruise 受益。
提供对 HDInsight 4.0 的 Hive 视图支持
Apache Ambari Hive 视图的作用是帮助你通过 Web 浏览器创作、优化和执行 Hive 查询。 从此版本开始,提供对 HDInsight 4.0 群集的本机 Hive 视图支持。 它不适用于现有群集。 需要删除并重新创建群集才能获取内置的 Hive 视图。
支持 HDInsight 4.0 的 Tez 视图
Apache Tez 视图用于跟踪和调试 Hive Tez 作业的执行情况。 从此版本开始,HDInsight 4.0 支持本机 Tez 视图。 它不适用于现有群集。 需要删除并重新创建群集,才能获得内置的 Tez 视图。
弃用
弃用 HDInsight 3.6 Spark 群集中的 Spark 2.1 和 2.2
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 3.6 上的 Spark 2.1 和 2.2 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 3.6 上的 Spark 2.3,以避免潜在的系统/支持中断。
弃用 HDInsight 4.0 Spark 群集中的 Spark 2.3
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 4.0 上的 Spark 2.3 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.4,避免出现潜在的系统/支持中断。
弃用 HDInsight 4.0 Kafka 群集中的 Kafka 1.1
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 4.0 上的 Kafka 1.1 创建新的 Kafka 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.1,避免出现潜在的系统/支持中断。
行为更改
Ambari 堆栈版本更改
在此版本中,Ambari 版本从 2.x.x.x 更改为 4.1。 可以在 Ambari 中验证堆栈版本 (HDInsight 4.1):Ambari > User > Versions。
即将推出的更改
没有需要注意的即将发生的中断性变更。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
已为 Hive 向后移植以下 JIRA:
已为 Hive 向后移植以下 HBase:
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
已知问题
Azure 门户中已修复了一个问题,即用户在使用 SSH 身份验证类型的公钥创建 Azure HDInsight 群集时会遇到错误。 当用户单击“查看 + 创建”时,他们将收到错误“不得包含 SSH 用户名中的任意三个连续字符。”此问题已解决,但可能要求你按 Ctrl + F5 加载已更正的视图来刷新浏览器缓存。 解决此问题的方法是使用 ARM 模板创建群集。
发行日期:2020/07/13
此版本适用于 HDInsight 3.6 和 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
支持 Azure 客户密码箱
Azure HDInsight 现在支持 Azure 客户密码箱。 客户可通过其提供的界面查看和批准/拒绝客户数据访问请求。 当 Azure 工程师需要在支持请求期间访问客户数据时,可以使用它。
存储的服务终结点策略
现在,客户可以在 HDInsight 群集子网上使用服务终结点策略 (SEP)。 详细了解 Azure 服务终结点策略。
弃用
弃用 HDInsight 3.6 Spark 群集中的 Spark 2.1 和 2.2
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 3.6 上的 Spark 2.1 和 2.2 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 3.6 上的 Spark 2.3,以避免潜在的系统/支持中断。
弃用 HDInsight 4.0 Spark 群集中的 Spark 2.3
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 4.0 上的 Spark 2.3 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.4,避免出现潜在的系统/支持中断。
弃用 HDInsight 4.0 Kafka 群集中的 Kafka 1.1
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 4.0 上的 Kafka 1.1 创建新的 Kafka 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.1,避免出现潜在的系统/支持中断。
行为更改
无需注意任何行为更改。
即将推出的更改
即将发布的版本中将推出以下变更。
能够为 Spark、Hadoop 和 ML 服务选择不同的 Zookeeper SKU
HDInsight 目前不支持更改 Spark、Hadoop 和 ML 服务群集类型的 Zookeeper SKU。 它为 Zookeeper 节点使用 A2_v2/A2 SKU,客户无需对此付费。 在即将推出的版本中,客户可以根据需要更改 Spark、Hadoop 和 ML 服务的 Zookeeper SKU。 会对不使用 A2_v2/A2 SKU 的 Zookeeper 节点收取费用。 默认 SKU 仍为 A2_V2/A2 并免费。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
已修复 Hive 仓库连接器问题
以前的版本中,Hive 仓库连接器的可用性存在问题。 现在已修复该问题。
已修复 Zeppelin 笔记本截断起始零的问题
Zeppelin 过去会在字符串格式的表输出中错误地截断起始零。 此版本已修复此问题。
组件版本更改
此发行版未发生组件版本更改。 可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2020/06/11
此版本适用于 HDInsight 3.6 和 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从此版本起,新创建的 HDInsight 群集开始使用 Azure 虚拟机规模集。 此更改将逐步推出。 预计不会有中断性变更。 详细了解 Azure 虚拟机规模集。
重启 HDInsight 群集中的 VM
在此版本中,我们支持重启 HDInsight 群集中的 VM 以重启无响应的节点。 目前只能通过 API 完成此操作,即将支持使用 PowerShell 和 CLI。 有关此 API 的详细信息,请参阅此文档。
弃用
弃用 HDInsight 3.6 Spark 群集中的 Spark 2.1 和 2.2
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 3.6 上的 Spark 2.1 和 2.2 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 3.6 上的 Spark 2.3,以避免潜在的系统/支持中断。
弃用 HDInsight 4.0 Spark 群集中的 Spark 2.3
从 2020 年 7 月 1 日起,客户无法使用 HDInsight 4.0 上的 Spark 2.3 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.4,避免出现潜在的系统/支持中断。
弃用 HDInsight 4.0 Kafka 群集中的 Kafka 1.1
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 4.0 上的 Kafka 1.1 创建新的 Kafka 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.1,避免出现潜在的系统/支持中断。
行为更改
ESP Spark 群集头节点大小更改
允许的最小 ESP Spark 群集头节点大小已更改为 Standard_D13_V2。 如果作为头节点的 VM 具有较低的核心和内存,则可能会由于 CPU 和内存容量相对较低而导致 ESP 群集问题。 从此版本起,将使用高于 Standard_D13_V2 和 Standard_E16_V3 的 SKU 作为 ESP Spark 群集的头节点。
提供至少有 4 个核心的 VM 作为头节点
头节点至少需要 4 核 VM,以确保 HDInsight 群集的高可用性和可靠性。 从 2020 年 4 月 6 日开始,客户只能选择至少有 4 个核心的 VM 作为新 HDInsight 群集的头节点。 现有群集将继续按预期方式运行。
群集工作器节点预配更改
当 80% 的工作器节点准备就绪时,群集将进入可运行阶段。 在此阶段中,客户可以执行所有数据平面操作,例如运行脚本和作业。 但客户不能执行任何控制平面操作,例如纵向扩展/缩减。 仅支持删除。
在进入可运行阶段后,群集会再等待 60 分钟,等待的对象是其余的 20% 的工作器节点。 在 60 分钟结束时,即使仍有部分工作器节点不可用,群集也会进入正在运行阶段。 在群集进入正在运行阶段后,你可以正常使用它。 控制平面操作(例如纵向扩展/缩减)和数据平面操作(例如运行脚本和作业)都会被接受。 如果所请求的某些工作器节点不可用,则群集会被标记为部分成功。 你需要为已成功部署的节点付费。
通过 HDInsight 创建新的服务主体
以前,在创建群集的过程中,客户可以创建新的服务主体来访问 Azure 门户中已连接的 ADLS 第 1 代帐户。 从 2020 年 6 月 15 日起,无法在 HDInsight 创建工作流中创建新的服务主体,只支持现有的服务主体。 请参阅使用 Microsoft Entra ID 创建服务主体和证书。
创建群集时脚本操作的超时
HDInsight 支持在创建群集的过程中运行脚本操作。 从此版本起,群集创建过程中的所有脚本操作都必须在 60 分钟内完成,否则会超时。提交到正在运行的群集的脚本操作不受影响。 请访问此处了解更多详细信息。
即将推出的更改
没有需要注意的即将发生的中断性变更。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
HBase 2.0 到 2.1.6
HBase 版本已从 2.0 升级到 2.1.6。
Spark 2.4.0 到 2.4.4
Spark 版本已从 2.4.0 升级到 2.4.4。
Kafka 2.1.0 到 2.1.1
Kafka 版本已从 2.1.0 升级到 2.1.1。
可以在此文档中查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本
已知问题
Hive 仓库连接器问题
此版本中的 Hive Warehouse Connector 存在问题。 下一版本将修复该问题。 在此版本之前创建的现有群集不受影响。 如果可能,请避免删除并重新创建群集。 如果需要进一步的帮助,请打开支持票证。
发行日期:01/09/2020
此版本适用于 HDInsight 3.6 和 4.0。 HDInsight 发行版在几天后即会在所有区域中推出。 此处的发行日期是指在第一个区域中的发行日期。 如果看不到以下更改,请耐心等待,几天后版本会在你所在的区域推出。
新功能
强制执行 TLS 1.2
传输层安全性 (TLS) 和安全套接字层 (SSL) 是提供计算机网络通信安全的加密协议。 详细了解 TLS。 HDInsight 在公共 HTTPs 终结点上使用 TLS 1.2,但为了向后兼容性仍支持 TLS 1.1。
在此发行版中,客户只能为通过公共群集终结点建立的所有连接启用 TLS 1.2。 为了支持此方案,我们引入了新属性 minSupportedTlsVersion,在创建群集期间可以指定此属性。 如果未设置该属性,则群集仍支持 TLS 1.0、1.1 和 1.2,这与当前的行为相同。 客户可以将此属性的值设置为“1.2”,这意味着群集仅支持 TLS 1.2 和更高版本。 有关详细信息,请参阅传输层安全性。
为磁盘加密创建自己的密钥
通过 Azure 存储服务加密 (SSE) 保护 HDInsight 中的所有托管磁盘。 这些磁盘上的数据默认已使用 Azure 托管的密钥进行加密。 从此发行版开始,可以创建自己的密钥 (BYOK) 进行磁盘加密,并使用 Azure 密钥保管库 管理该密钥。 BYOK 加密是群集创建期间的一步配置,无需其他费用。 只需将 HDInsight 作为托管标识注册到 Azure 密钥保管库,并在创建群集时添加加密密钥。 有关详细信息,请参阅客户管理的密钥磁盘加密。
弃用
此版本无弃用。 若要为即将到来的弃用做好准备,请参阅即将推出的变更。
行为更改
此版本无行为变更。 若要为即将推出的更改做好准备,请参阅即将推出的更改。
即将推出的更改
即将发布的版本中将推出以下变更。
弃用 HDInsight 3.6 Spark 群集中的 Spark 2.1 和 2.2
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 3.6 上的 Spark 2.1 和 2.2 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 3.6 上的 Spark 2.3,以避免潜在的系统/支持中断。
弃用 HDInsight 4.0 Spark 群集中的 Spark 2.3
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 4.0 上的 Spark 2.3 创建新的 Spark 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.4,避免出现潜在的系统/支持中断。
弃用 HDInsight 4.0 Kafka 群集中的 Kafka 1.1
从 2020 年 7 月 1 日开始,客户将无法使用 HDInsight 4.0 上的 Kafka 1.1 创建新的 Kafka 群集。 现有群集将在没有 Azure 支持的情况下按原样运行。 请考虑在 2020 年 6 月 30 日之前转移到 HDInsight 4.0 上的 Spark 2.1,避免出现潜在的系统/支持中断。 有关详细信息,请参阅将 Apache Kafka 工作负荷迁移到 Azure HDInsight 4.0。
HBase 2.0 到 2.1.6
在即将推出的 HDInsight 4.0 版本中,HBase 版本将从 2.0 升级到 2.1.6
Spark 2.4.0 到 2.4.4
在即将推出的 HDInsight 4.0 版本中,Spark 版本将从版本 2.4.0 升级到 2.4.4
Kafka 2.1.0 到 2.1.1
在即将推出的 HDInsight 4.0 版本中,Kafka 版本将从版本 2.1.0 升级到 2.1.1
提供至少有 4 个核心的 VM 作为头节点
头节点至少需要 4 核 VM,以确保 HDInsight 群集的高可用性和可靠性。 从 2020 年 4 月 6 日开始,客户只能选择至少有 4 个核心的 VM 作为新 HDInsight 群集的头节点。 现有群集将继续按预期方式运行。
ESP Spark 群集节点大小更改
在即将推出的版本中,ESP Spark 群集允许的最小节点大小将更改为 Standard_D13_V2。 由于 CPU 和内存容量相对较低,因此 A 系列 VM 可能会导致 ESP 群集问题。 创建新 ESP 群集时将弃用 A 系列 VM。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 在即将推出的发行版中,HDInsight 将改用 Azure 虚拟机规模集。 请参阅有关 Azure 虚拟机规模集的详细信息。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
此发行版未发生组件版本更改。 可在此处查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发行日期:2019/12/17
此版本适用于 HDInsight 3.6 和 4.0。
新功能
服务标记
服务标记通过使你轻松限制 Azure 服务的网络访问,以此简化 Azure 虚拟机和 Azure 虚拟网络的安全性。 你可在网络安全组 (NSG) 规则中使用服务标记,允许或拒绝全局或每个 Azure 区域的特定 Azure 服务流量。 Azure 会对每个标记下面的 IP 地址进行维护。 网络安全组 (NSG) 的 HDInsight 服务标记是运行状况和管理服务的 IP 地址组。 这些组有助于尽量降低创建安全规则时的复杂性。 HDInsight 客户可通过 Azure 门户、PowerShell 和 REST API 启用服务标记。 有关详细信息,请参阅 Azure HDInsight 的网络安全组 (NSG) 服务标记。
自定义 Ambari DB
通过 HDInsight,你现在可将自己的 SQL DB 用于 Apache Ambari。 可以从 Azure 门户或通过资源管理器模板来配置此自定义 Ambari DB。 此功能可让你为处理和容量需求选择合适的 SQL DB。 你还可轻松升级以匹配业务增长需求。 有关详细信息,请参阅使用自定义 Ambari 数据库设置 HDInsight 群集。

弃用
此版本无弃用。 若要为即将到来的弃用做好准备,请参阅即将推出的变更。
行为更改
此版本无行为变更。 若要为即将到来的行为变更做好准备,请参阅即将推出的变更。
即将推出的更改
即将发布的版本中将推出以下变更。
传输层安全性 (TLS) 1.2 强制措施
传输层安全性 (TLS) 和安全套接字层 (SSL) 是提供计算机网络通信安全的加密协议。 有关详细信息,请参阅传输层安全性。 虽然 Azure HDInsight 群集接受公共 HTTPS 终结点上的 TLS 1.2 连接,但仍支持 TLS 1.1,以便实现与旧客户端的后向兼容性。
从下一个版本开始,你将可以选择加入和配置新的 HDInsight 群集,以仅接受 TLS 1.2 连接。
今年晚些时候,预计从 2020/6/30 开始,Azure HDInsight 将为所有 HTTPS 连接强制实行 TLS 2.1 或更高版本。 我们建议你确保所有客户端都已准备好处理 TLS 1.2 或更高版本。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从 2020 年 2 月开始(将在稍后传达确切日期),HDInsight 将改为使用 Azure 虚拟机规模集。 详细了解 Azure 虚拟机规模集。
ESP Spark 群集节点大小更改
在即将推出的版本中:
- 允许的最小 ESP Spark 群集节点大小将变更为 Standard_D13_V2。
- 将不再推荐使用 A 系列 VM 创建新 ESP 群集,因为 A 系列 VM 的 CPU 和内存容量相对较低,可能导致 ESP 群集问题。
HBase 2.0 到 2.1
在即将推出的 HDInsight 4.0 版本中,HBase 版本将从 2.0 升级到 2.1。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
我们已将 HDInsight 3.6 支持延长到 2020 年 12 月 31 日。 如需了解更多详情,请参阅支持的 HDInsight 版本。
HDInsight 4.0 无组件版本变更。
HDInsight 3.6 上的 Apache Zeppelin:0.7.0-->0.7.3。
可以在此文档中获取最新的组件版本。
新区域
阿拉伯联合酋长国北部
阿拉伯联合酋长国北部的管理 IP 为 65.52.252.96 和 65.52.252.97。
发行日期:11/07/2019
此版本适用于 HDInsight 3.6 和 4.0。
新功能
HDInsight 标识中介 (HIB)(预览版)
HDInsight 标识中介 (HIB) 可让用户使用多重身份验证 (MFA) 登录到 Apache Ambari,并获取所需的 Kerberos 票证,而无需在 Microsoft Entra ID 域服务 (AAD-DS) 中提供密码哈希。 目前,HIB 仅适用于通过 Azure 资源管理 (ARM) 模板部署的群集。
Kafka REST API 代理(预览版)
Kafka Rest API 代理通过受保护的 Microsoft Entra ID 授权和 OAuth 协议,为 Kafka 群集提供一键式的高可用性 REST 代理部署。
自动缩放
适用于 Azure HDInsight 的自动缩放功能现已在所有区域中针对 Apache Spark 和 Hadoop 群集类型推出正式版。 使用此功能能够以更具成本效益且高效的方式管理大数据分析工作负荷。 现在,你可以优化 HDInsight 群集的使用,并且只需为所用的资源付费。
可以根据要求,在基于负载和基于计划的自动缩放之间进行选择。 基于负载的自动缩放可根据当前资源需求增大和缩小群集大小,而基于计划的自动缩放可根据预定义的计划更改群集大小。
适用于 HBase 和 LLAP 工作负荷的自动缩放支持也推出了公共预览版。 有关详细信息,请参阅自动缩放 Azure HDInsight 群集。
适用于 Apache HBase 的 HDInsight 加速写入
加速写入使用 Azure 高级 SSD 托管磁盘,可以改善 Apache HBase 预写日志 (WAL) 的性能。 有关详细信息,请参阅面向 Apache HBase 的 Azure HDInsight 加速写入。
自定义 Ambari DB
HDInsight 现在提供新的容量,使客户能够使用自己的适用于 Ambari 的 SQL 数据库。 现在,客户可以选择适当的用于 Ambari 的 SQL 数据库,并根据自己的业务增长需求轻松对其进行升级。 部署是使用 Azure 资源管理器模板完成的。 有关详细信息,请参阅使用自定义 Ambari 数据库设置 HDInsight 群集。
现已推出适用于 HDInsight 的 F 系列虚拟机
F 系列虚拟机 (VM) 非常适合用于体验处理要求很低的 HDInsight。 根据每个 vCPU 的 Azure 计算单位 (ACU),在较低的小时价列表中,F 系列在 Azure 产品组合中具有最高性价比。 有关详细信息,请参阅为 Azure HDInsight 群集选择适当的 VM 大小。
弃用
G 系列虚拟机已弃用
从此发行版开始,HDInsight 中不再提供 G 系列 VM。
Dv1 虚拟机已弃用
从此发行版开始,已弃用包含 HDInsight 的 Dv1 VM。 客户提出的 Dv1 请求将自动以 Dv2 来满足。
Dv1 与 Dv2 VM 的价格没有差别。
行为更改
群集托管磁盘大小更改
HDInsight 在群集中提供托管磁盘空间。 从此发行版开始,新建的群集中每个节点的托管磁盘大小将更改为 128 GB。
即将推出的更改
即将发布的版本中将发生以下更改。
迁移到 Azure 虚拟机规模集
HDInsight 目前使用 Azure 虚拟机来预配群集。 从 12 月开始,HDInsight 将改用 Azure 虚拟机规模集。 详细了解 Azure 虚拟机规模集。
HBase 2.0 到 2.1
在即将推出的 HDInsight 4.0 版本中,HBase 版本将从 2.0 升级到 2.1。
ESP 群集的 A 系列虚拟机已弃用
由于 CPU 和内存容量相对较低,A 系列 VM 可能会导致 ESP 群集出现问题。 在即将发布的版本中,A 系列 VM 将会弃用,不再可用于创建新的 ESP 群集。
Bug 修复
HDInsight 会持续改善群集的可靠性和性能。
组件版本更改
此版本未发生组件版本更改。 可在此处查找 HDInsight 4.0 和 HDInsight 3.6 的当前组件版本。
发布日期:2019/08/07
组件版本
下面提供了所有 HDInsight 4.0 组件的正式 Apache 版本。 列出的组件是可用的最新稳定版本。
- Apache Ambari 2.7.1
- Apache Hadoop 3.1.1
- Apache HBase 2.0.0
- Apache Hive 3.1.0
- Apache Kafka 1.1.1、2.1.0
- Apache Mahout 0.9.0+
- Apache Oozie 4.2.0
- Apache Phoenix 4.7.0
- Apache Pig 0.16.0
- Apache Ranger 0.7.0
- Apache Slider 0.92.0
- Apache Spark 2.3.1、2.4.0
- Apache Sqoop 1.4.7
- Apache TEZ 0.9.1
- Apache Zeppelin 0.8.0
- Apache ZooKeeper 3.4.6
除了上面所列的版本以外,Apache 组件的较高版本有时也会捆绑在 HDP 分发版中。 在这种情况下,这些较高版本会列在“技术预览”表中,并且在生产环境中不应替换为上述列表中的 Apache 组件版本。
Apache 修补程序信息
有关 HDInsight 4.0 中可用的修补程序的详细信息,请参阅下表中适用于每个产品的修补程序列表。
| 产品名称 | 修补程序信息 |
|---|---|
| Ambari | Ambari 修补程序信息 |
| Hadoop | Hadoop 修补程序信息 |
| HBase | HBase 修补程序信息 |
| Hive | 此版本提供 Hive 3.1.0,但不提供其他 Apache 修补程序。 |
| Kafka | 此版本提供 Kafka 1.1.1,但不提供其他 Apache 修补程序。 |
| Oozie | Oozie 修补程序信息 |
| Phoenix | Phoenix 修补程序信息 |
| Pig | Pig 修补程序信息 |
| Ranger | Ranger 修补程序信息 |
| Spark | Spark 修补程序信息 |
| Sqoop | 此版本提供 Sqoop 1.4.7,但不提供其他 Apache 修补程序。 |
| Tez | 此版本提供 Tez 0.9.1,但不提供其他 Apache 修补程序。 |
| Zeppelin | 此版本提供 Zeppelin 0.8.0,但不提供其他 Apache 修补程序。 |
| Zookeeper | Zookeeper 修补程序信息 |
修复了常见漏洞和透露
有关此版本中已解决的安全问题的详细信息,请参阅 Hortonworks 编写的修复了 HDP 3.0.1 的常见漏洞和透露。
已知问题
使用默认安装选项时 Secure HBase 的复制中断
对于 HDInsight 4.0,请执行以下步骤:
启用群集间通信。
登录到活动的头节点。
使用以下命令下载一个脚本以启用复制:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.sh键入命令
sudo kinit <domainuser>。键入以下命令以运行该脚本:
sudo bash hdi_enable_replication.sh -m <hn*> -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
对于 HDInsight 3.6
登录到活动的 HMaster ZK。
使用以下命令下载一个脚本以启用复制:
sudo wget https://raw.githubusercontent.com/Azure/hbase-utils/master/replication/hdi_enable_replication.sh键入命令
sudo kinit -k -t /etc/security/keytabs/hbase.service.keytab hbase/<FQDN>@<DOMAIN>。输入以下命令:
sudo bash hdi_enable_replication.sh -s <srclusterdns> -d <dstclusterdns> -sp <srcclusterpasswd> -dp <dstclusterpasswd> -copydata
将 HBase 群集迁移到 HDInsight 4.0 后,Phoenix Sqlline 停止工作
执行以下步骤:
- 删除以下 Phoenix 表:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.MUTEXSYSTEM.CATALOG
- 如果无法删除其中的任何表,请重启 HBase 以清除与表建立的任何连接。
- 再次运行
sqlline.py。 Phoenix 将重新创建在步骤 1 中删除的所有表。 - 重新生成 HBase 数据的 Phoenix 表和视图。
将 HBase Phoenix 元数据从 HDInsight 3.6 复制到 4.0 之后,Phoenix Sqlline 停止工作
执行以下步骤:
- 在执行复制之前,请转到目标 4.0 群集并执行
sqlline.py。 此命令将生成类似于SYSTEM.MUTEX和SYSTEM.LOG且只存在于 4.0 中的 Phoenix 表。 - 删除以下表:
SYSTEM.FUNCTIONSYSTEM.SEQUENCESYSTEM.STATSSYSTEM.CATALOG
- 启动 HBase 复制
弃用
Apache Storm 和机器学习服务在 HDInsight 4.0 中不可用。
发布日期:2019/04/14
新功能
新的更新和功能划分为以下类别:
更新 Hadoop 和其他开源项目 - 除了超过 20 个开源项目的 1000 多个 bug 修复,此更新还包含 Spark (2.3) 和 Kafka (1.0) 的新版本。
将 R Server 9.1 更新到机器学习服务 9.3 - 通过此发布,我们为数据科学家和工程师提供通过算法革新和便捷的操作化增强的最佳开放源代码,均在其首选语言中提供(达到 Apache Spark 速度)。 此版本扩展了 R Server 的功能,添加了对 Python 的支持,群集名称因而从 R Server 更改为 ML Services。
支持 Azure Data Lake Storage Gen2 - HDInsight 将支持 Azure Data Lake Storage Gen2 的预览版本。 在可用区域中,客户可以选择将 ADLS Gen2 帐户作为 HDInsight 群集的主要存储或辅助存储。
HDInsight 企业安全性套餐更新(预览版)-(预览版)虚拟网络服务终结点支持 Azure Blob 存储、ADLS Gen1、Cosmos DB 和 Azure DB。
组件版本
下面列出了所有 HDInsight 3.6 组件的正式 Apache 版本。 此处列出的所有组件是最新稳定版本的正式 Apache 发行版。
Apache Hadoop 2.7.3
Apache HBase 1.1.2
Apache Hive 1.2.1
Apache Hive 2.1.0
Apache Kafka 1.0.0
Apache Mahout 0.9.0+
Apache Oozie 4.2.0
Apache Phoenix 4.7.0
Apache Pig 0.16.0
Apache Ranger 0.7.0
Apache Slider 0.92.0
Apache Spark 2.2.0/2.3.0
Apache Sqoop 1.4.6
Apache Storm 1.1.0
Apache TEZ 0.7.0
Apache Zeppelin 0.7.3
Apache ZooKeeper 3.4.6
除了上面所列的版本以外,某些 Apache 组件的较高版本有时也捆绑在 HDP 分发版中。 在这种情况下,这些较高版本会列在“技术预览”表中,并且在生产环境中不应替换为上述列表中的 Apache 组件版本。
Apache 修补程序信息
Hadoop
此版本提供 Hadoop Common 2.7.3 和以下 Apache 修补程序:
HADOOP-13190:在 KMS HA 文档中提到 LoadBalancingKMSClientProvider。
HADOOP-13227:AsyncCallHandler 应使用事件驱动的体系结构来处理异步调用。
HADOOP-14104:客户端应始终请求 kms 提供程序路径的名称节点。
HADOOP-14799:将 nimbus-jose-jwt 更新为 4.41.1。
HADOOP-14814:将 FsServerDefaults 上不兼容的 API 更改修复为 HADOOP-14104。
HADOOP-14903:将 json-smart 显式添加到 pom.xml。
HADOOP-15042:当 numberOfPagesRemaining 为 0 时,Azure PageBlobInputStream.skip() 可以返回负值。
HADOOP-15255:LdapGroupsMapping 中的组名称支持大小写转换。
HADOOP-15265:从 hadoop-auth pom.xml 中显式排除 json-smart。
HDFS-7922:ShortCircuitCache#close 未发布 ScheduledThreadPoolExecutors。
HDFS-8496:在持有 FSDatasetImpl 锁的情况下调用 stopWriter() 可能会阻止其他线程 (cmccabe)。
HDFS-10267:FsDatasetImpl#recoverAppend 和 FsDatasetImpl#recoverClose 上的附加“synchronized”。
HDFS-10489:弃用 HDFS 加密区域的 dfs.encryption.key.provider.uri。
HDFS-11384:添加让均衡器分散 getBlocks 调用的选项,以避免 NameNode 的 rpc.CallQueueLength 峰值。
HDFS-11689:
DFSClient%isHDFSEncryptionEnabled引发的新异常破坏hackyhive 代码。HDFS-11711:发生“打开的文件过多”异常时 DN 不应删除块。
HDFS-12347:TestBalancerRPCDelay#testBalancerRPCDelay 频繁失败。
HDFS-12781:
Datanode关闭后,在NamenodeUI 中,Datanode选项卡引发警告消息。HDFS-13054:处理
DFSClient中的 PathIsNotEmptyDirectoryException 删除调用。HDFS-13120:concat 后,快照差异可能会损坏。
YARN-3742:如果
ZKClient创建超时,YARN RM 会关闭。YARN-6061:为 RM 中的关键线程添加 UncaughtExceptionHandler。
YARN-7558:如果启用 UI 身份验证,获取运行中容器的日志的 yarn logs 命令会失败。
YARN-7697:即使日志聚合已完成,提取已完成应用程序的日志也会失败。
HDP 2.6.4 提供 Hadoop Common 2.7.3 和以下 Apache 修补程序:
HADOOP-13700:从 TrashPolicy#initialize 和 #getInstance 签名中移除未引发的
IOException。HADOOP-13709:能够清理进程退出时由 Shell 生成的子进程。
HADOOP-14059:
s3arename(self, subdir) 错误消息中存在拼写错误。HADOOP-14542:添加接受 slf4j 记录器 API 的 IOUtils.cleanupWithLogger。
HDFS-9887:WebHdfs 套接字超时应可配置。
HDFS-9914:修复可配置的 WebhDFS 连接/读取超时。
MAPREDUCE-6698:增大 TestUnnecessaryBlockingOnHist oryFileInfo.testTwoThreadsQueryingDifferentJobOfSameUser 中的超时。
YARN-4550:TestContainerLanch 中的某些测试在非英语区域设置环境中失败。
YARN-4717:由于清理后发生 IllegalArgumentException,TestResourceLocalizationService.testPublicResourceInitializesLocalDir 间歇性失败。
YARN-5042:将 /sys/fs/cgroup 作为只读装载项装入 Docker 容器。
YARN-5318:修复 TestRMAdminService#te stRefreshNodesResourceWithFileSystemBasedConfigurationProvider 的间歇性测试失败。
YARN-5641:容器完成后,本地化程序留下 tarball。
YARN-6004:重构 TestResourceLocalizationService#testDownloadingResourcesOnContainer,使其小于 150 行。
YARN-6078:容器停滞在“正在本地化”状态。
YARN-6805:由于 null PrivilegedOperationException 退出代码,LinuxContainerExecutor 中出现 NPE。
HBase
此版本提供 HBase 1.1.2 和以下 Apache 修补程序。
HBASE-13376:Stochastic 负载均衡器改进。
HBASE-13716:停止使用 Hadoop 的 FSConstants。
HBASE-13848:通过凭据提供程序 API 访问 InfoServer SSL 密码。
HBASE-13947:在 AssignmentManager 中使用 MasterServices 而不是 Server。
HBASE-14135:HBase 备份/还原阶段 3:合并备份映像。
HBASE-14473:并行计算区域位置。
HBASE-14517:在主状态页中显示
regionserver's的版本。HBASE-14606:apache 上的主干版本中的 TestSecureLoadIncrementalHFiles 测试超时。
HBASE-15210:撤消每毫秒记录数十个行的激进负载均衡器日志记录。
HBASE-15515:改进均衡器中的 LocalityBasedCandidateGenerator。
HBASE-15615:
RegionServerCallable需要重试时休眠时间错误。HBASE-16135:可能永远无法删除已删除的对等方的 rs 下的 PeerClusterZnode。
HBASE-16570:启动时并行计算区域位置。
HBASE-16810:当
regionservers在 /hbase/draining znode 中且已卸载时,HBase 均衡器引发 ArrayIndexOutOfBoundsException。HBASE-16852:TestDefaultCompactSelection 在 branch-1.3 上失败。
HBASE-17387:在 multi() 的 RegionActionResult 中减少异常报告的开销。
HBASE-17850:备份系统修复实用工具。
HBASE-17931:将系统表分配到具有最高版本的服务器。
HBASE-18083:使大/小文件清理线程数在 HFileCleaner 中可配置。
HBASE-18084:改进 CleanerChore,以便从消耗更多磁盘空间的目录中清理数据。
HBASE-18164:位置成本函数和候选生成器的速度快得多。
HBASE-18212:在独立模式下出现本地文件系统 HBase 日志警告消息:无法在类 org.apache.hadoop.fs.FSDataInputStream 中调用“unbuffer”方法。
HBASE-18808:配置签入 BackupLogCleaner#getDeletableFiles() 的效率低下。
HBASE-19052:FixedFileTrailer 应识别 branch-1.x 中的 CellComparatorImpl 类。
HBASE-19065:HRegion#bulkLoadHFiles() 应等待并发 Region#flush() 完成。
HBASE-19285:添加每个表的延迟直方图。
HBASE-19393:使用 SSL 访问 HBase UI 时的 HTTP 413 FULL 标头。
HBASE-19395:[branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting 失败并出现 NPE。
HBASE-19421:branch-1 不会针对 Hadoop 3.0.0 进行编译。
HBASE-19934:启用读取副本并在区域拆分后创建联机快照时,发生 HBaseSnapshotException。
HBASE-20008:拆分区域后还原快照时发生 [backport] NullPointerException。
Hive
除以下修补程序以外,此版本还提供 Hive 1.2.1 和 Hive 2.1.0:
Hive 1.2.1 Apache 修补程序:
HIVE-10697:ObjectInspectorConvertors#UnionConvertor 执行错误的转换。
HIVE-11266:基于外部表的表统计信息 count(*) 错误结果。
HIVE-12245:支持基于 HBase 的表的列注释。
HIVE-12315:修复矢量化双精度除零。
HIVE-12360:使用谓词下推在未压缩的 ORC 中进行错误查找。
HIVE-12378:HBaseSerDe.serialize 二进制字段中出现异常。
HIVE-12785:包含联合类型和结构 UDF 的视图破坏。
HIVE-14013:描述表未正确显示 unicode。
HIVE-14205:Hive 不支持 AVRO 文件格式的联合类型。
HIVE-14421:FS.deleteOnExit 包含对 _tmp_space.db 文件的引用。
HIVE-15563:忽略 SQLOperation.runQuery 中的非法操作状态转换异常,以公开实际异常。
HIVE-15680:在 MR 模式下,当 hive.optimize.index.filter=true 且在查询中两次引用同一个 ORC 表时,出现错误的结果。
HIVE-15883:在 Hive 中的 HBase 映射表内插入十进制数失败。
HIVE-16232:QuotedIdentifier 中的列支持统计信息计算。
HIVE-16828:启用 CBO 后,基于分区视图进行查询会引发 IndexOutOfBoundException。
HIVE-17013:使用基于视图选择的子查询删除请求。
HIVE-17063:在首先删除分区的情况下,将覆盖分区插入外部表失败。
HIVE-17259:Hive JDBC 无法识别 UNIONTYPE 列。
HIVE-17419:ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS 命令显示掩码表的计算统计信息。
HIVE-17621:执行 HCatInputFormat 拆分计算期间忽略 Hive-site 设置。
HIVE-17729:添加 Database 和 Explain 相关的 Blob 存储测试。
HIVE-17803:使用 Pig 多重查询时,将 2 个 HCatStorer 写入同一个表会破坏彼此的输出。
HIVE-17829:ArrayIndexOutOfBoundsException - 中采用 Avro 架构的基于 HBASE 的表。
HIVE-17845:如果目标表列不是小写,插入将会失败。
HIVE-17900:分析压缩器触发的列中的统计信息生成包含多个分区列的、格式不当的 SQL。
HIVE-18026:Hive webhcat 主体配置优化。
HIVE-18031:支持“更改数据库”操作的复制。
HIVE-18090:通过 hadoop 凭据连接元存储时,acid 检测信号失败。
HIVE-18189:将 hive.groupby.orderby.position.alias 设置为 true 时,Hive 查询返回错误结果。
HIVE-18258:矢量化:包含重复列的化简端 GROUP BY MERGEPARTIAL 已破坏。
HIVE-18293:Hive 无法压缩运行 HiveMetaStore 的标识不拥有的某个文件夹中的表。
HIVE-18327:删除 MiniHiveKdc 的不必要的 HiveConf 依赖项。
HIVE-18341:添加复制负载支持,以便能够使用相同的加密密钥添加 TDE 的“原始”命名空间。
HIVE-18352:引入执行 REPL DUMP 时的 METADATAONLY 选项,以便与其他工具集成。
HIVE-18353:CompactorMR 应调用 jobclient.close() 来触发清理。
HIVE-18390:查询 ColumnPruner 中的分区视图时发生 IndexOutOfBoundsException。
HIVE-18429:压缩应处理不生成任何输出的情况。
HIVE-18447:JDBC:提供某种方式让 JDBC 用户通过连接字符串传递 Cookie 信息。
HIVE-18460:压缩器不会将表属性传递给 Orc 写入器。
HIVE-18467:支持整个仓库转储/加载 + 创建/删除数据库事件(Anishek Agarwal,由 Sankar Hariappan 审阅)。
HIVE-18551:矢量化:VectorMapOperator 尝试为 Hybrid Grace 写入过许多的矢量列。
HIVE-18587:插入 DML 事件可能尝试针对目录计算校验和。
HIVE-18613:扩展 JsonSerDe 以支持 BINARY 类型。
HIVE-18626:复制负载“with”子句不会将配置传递给任务。
HIVE-18660:PCR 无法区分分区和虚拟列。
HIVE-18754:REPL STATUS 应支持“with”子句。
HIVE-18754:REPL STATUS 应支持“with”子句。
HIVE-18788:清理 JDBC PreparedStatement 中的输入。
HIVE-18794:复制负载“with”子句不会将配置传递给非分区表的任务。
HIVE-18808:统计信息更新失败时使压缩更加可靠。
HIVE-18817:读取 ACID 表期间发生 ArrayIndexOutOfBounds 异常。
HIVE-18833:“作为 orcfile 插入目录时”自动合并失败。
HIVE-18879:如果 xercesImpl.jar 在类路径中,需要能够禁止在 UDFXPathUtil 中使用嵌入式元素。
HIVE-18907:创建实用工具来解决 HIVE-18817 中的 acid 键索引问题。
Hive 1.2.0 Apache 修补程序
HIVE-14013:描述表未正确显示 unicode。
HIVE-14205:Hive 不支持 AVRO 文件格式的联合类型。
HIVE-15563:忽略 SQLOperation.runQuery 中的非法操作状态转换异常,以公开实际异常。
HIVE-15680:在 MR 模式下,当 hive.optimize.index.filter=true 且在查询中两次引用同一个 ORC 表时,出现错误的结果。
HIVE-15883:在 Hive 中的 HBase 映射表内插入十进制数失败。
HIVE-16757:删除对已弃用 AbstractRelNode.getRows 的调用。
HIVE-16828:启用 CBO 后,基于分区视图进行查询会引发 IndexOutOfBoundException。
HIVE-17063:在首先删除分区的情况下,将覆盖分区插入外部表失败。
HIVE-17259:Hive JDBC 无法识别 UNIONTYPE 列。
HIVE-17600:使用户可设置 OrcFile 的 enforceBufferSize。
HIVE-17601:改进 LlapServiceDriver 中的错误处理。
HIVE-17613:删除较短的相同线程分配的对象池。
HIVE-17617:空结果集汇总应包含空组集的分组。
HIVE-17621:执行 HCatInputFormat 拆分计算期间忽略 Hive-site 设置。
HIVE-17629:CachedStore:提供已批准/未批准的配置以允许对表/分区进行选择性缓存,并允许在预热时读取。
HIVE-17702:在 ORC 中的十进制读取器内进行错误的 isRepeating 处理。
HIVE-17729:添加 Database 和 Explain 相关的 Blob 存储测试。
HIVE-17803:使用 Pig 多重查询时,将 2 个 HCatStorer 写入同一个表会破坏彼此的输出。
HIVE-17845:如果目标表列不是小写,插入将会失败。
HIVE-17900:分析压缩器触发的列中的统计信息生成包含多个分区列的、格式不当的 SQL。
HIVE-18006:优化 HLLDenseRegister 的内存占用量。
HIVE-18026:Hive webhcat 主体配置优化。
HIVE-18031:支持“更改数据库”操作的复制。
HIVE-18090:通过 hadoop 凭据连接元存储时,acid 检测信号失败。
HIVE-18258:矢量化:包含重复列的化简端 GROUP BY MERGEPARTIAL 已破坏。
HIVE-18293:Hive 无法压缩运行 HiveMetaStore 的标识不拥有的某个文件夹中的表。
HIVE-18318:即使在未阻塞时,LLAP 记录读取器也应检查中断。
HIVE-18326:LLAP Tez 计划程序 - 仅当任务之间存在依赖关系时,才预先清空任务。
HIVE-18327:删除 MiniHiveKdc 的不必要的 HiveConf 依赖项。
HIVE-18331:添加 TGT 过期时重新登录和一些日志记录/lambda。
HIVE-18341:添加复制负载支持,以便能够使用相同的加密密钥添加 TDE 的“原始”命名空间。
HIVE-18352:引入执行 REPL DUMP 时的 METADATAONLY 选项,以便与其他工具集成。
HIVE-18353:CompactorMR 应调用 jobclient.close() 来触发清理。
HIVE-18390:查询 ColumnPruner 中的分区视图时发生 IndexOutOfBoundsException。
HIVE-18447:JDBC:提供某种方式让 JDBC 用户通过连接字符串传递 Cookie 信息。
HIVE-18460:压缩器不会将表属性传递给 Orc 写入器。
HIVE-18462:(使用映射联接的查询的格式化解释包含 columnExprMap,其中包含格式不当的列名称)。
HIVE-18467:支持整个仓库转储/加载 + 创建/删除数据库事件。
HIVE-18488:LLAP ORC 读取器缺少一些 null 检查。
HIVE-18490:使用 EXISTS 和 NOT EXISTS 且包含 non-equi 谓词的查询可能生成错误结果。
HIVE-18506:LlapBaseInputFormat - 负数组索引。
HIVE-18517:矢量化:修复 VectorMapOperator,以接受 VRB 并正确检查矢量化标志来支持 LLAP 缓存。
HIVE-18523:在没有输入的情况下修复摘要行。
HIVE-18528:聚合 ObjectStore 中的统计信息时收到错误的结果。
HIVE-18530:复制应暂时跳过 MM 表。
HIVE-18551:矢量化:VectorMapOperator 尝试为 Hybrid Grace 写入过许多的矢量列。
HIVE-18577:SemanticAnalyzer.validate 包含一些毫无意义的元存储调用。
HIVE-18587:插入 DML 事件可能尝试针对目录计算校验和。
HIVE-18613:扩展 JsonSerDe 以支持 BINARY 类型。
HIVE-18626:复制负载“with”子句不会将配置传递给任务。
HIVE-18643:不检查 ACID 操作的已存档分区。
HIVE-18660:PCR 无法区分分区和虚拟列。
HIVE-18754:REPL STATUS 应支持“with”子句。
HIVE-18788:清理 JDBC PreparedStatement 中的输入。
HIVE-18794:复制负载“with”子句不会将配置传递给非分区表的任务。
HIVE-18808:统计信息更新失败时使压缩更加可靠。
HIVE-18815:删除 HPL/SQL 中的未使用功能。
HIVE-18817:读取 ACID 表期间发生 ArrayIndexOutOfBounds 异常。
HIVE-18833:“作为 orcfile 插入目录时”自动合并失败。
HIVE-18879:如果 xercesImpl.jar 在类路径中,需要能够禁止在 UDFXPathUtil 中使用嵌入式元素。
HIVE-18944:DPP 期间错误地设置了分组集位置。
Kafka
此版本提供 Kafka 1.0.0 和以下 Apache 修补程序。
KAFKA-4827:Kafka 连接:连接器名称中的特殊字符导致错误。
KAFKA-6118:kafka.api.SaslScramSslEndToEndAuthorizationTest.testTwoConsumersWithDifferentSaslCredentials 中发生暂时性失败。
KAFKA-6156:JmxReporter 无法处理 Windows 样式的目录路径。
KAFKA-6164:如果在加载日志时遇到错误,ClientQuotaManager 线程会阻止关闭。
KAFKA-6167:streams 目录中的时间戳包含冒号,这是非法字符。
KAFKA-6179:RecordQueue.clear() 不会清除 MinTimestampTracker 的维护列表。
KAFKA-6185:如果执行向下转换,则选择器内存泄漏并很有可能出现 OOM。
KAFKA-6190:使用事务消息时,GlobalKTable 永远不会完成还原。
KAFKA-6210:如果将 1.0.0 用于 inter.broker.protocol.version 或 log.message.format.version,则会发生 IllegalArgumentException。
KAFKA-6214:结合内存中状态存储使用备用副本会导致流崩溃。
KAFKA-6215:KafkaStreamsTest 在主干中失败。
KAFKA-6238:应用滚动升级到 1.0.0 时,协议版本出现问题。
KAFKA-6260:AbstractCoordinator 不会明显处理 NULL 异常。
KAFKA-6261:如果 ack=0,则请求日志记录会引发异常。
KAFKA-6274:改善自动生成的
KTable源状态存储名称。
Mahout
HDP 2.3.x 和 2.4.x 未随附 Mahout 的特定 Apache 版本,而是同步到 Apache Mahout 主干中的特定修订版本点。 此修订版本点在 0.9.0 版本之后、0.10.0 版本之前。 与 0.9.0 版本相比,此版本提供大量的 bug 修复和功能增强,并且在完成转换到 0.10.0 中基于 Spark 的 Mahout 之前,提供 Mahout 功能的稳定版本。
为 HDP 2.3.x 和 2.4.x 中的 Mahout 选择的修订版本点在截至 2014 年 12 月 19 日,来自 GitHub 中 Apache Mahout 的“mahout-0.10.x”分支的 0f037cb03e77c096。
在 HDP 2.5.x 和 2.6.x 中,我们从 Mahout 中删除了“commons-httpclient”库(因为我们认为它是具有潜在安全问题的已过时库),并已将 Mahout 中的 Hadoop 客户端升级到了版本 2.7.3(HDP-2.5 中使用的相同版本)。 因此:
以前编译的 Mahout 作业需要在 HDP-2.5 或 2.6 环境中重新编译。
有很小的可能性发生这种情况:某些 Mahout 作业可能遇到与“org.apache.commons.httpclient”、“net.java.dev.jets3t”或类名前缀相关的“ClassNotFoundException”或“无法加载类”错误。 如果你的环境中可以接受过时库中的安全问题带来的风险,那么在发生这些错误时,可以考虑是否在作业的类路径中手动安装所需的 jar。
还有更小的可能性出现这种情况:由于二进制兼容问题,在 Mahout 对 hadoop-common 库的 hbase-client 代码调用中,某些 Mahout 作业可能会崩溃。 遗憾的是,没有任何方法可以解决此问题,只能还原到 Mahout 的 HDP-2.4.2 版本,而这可能会造成安全问题。 同样,这种情况很少见,在任何给定的 Mahout 作业套件中都不太可能会发生。
Oozie
此版本提供 Oozie 4.2.0 和以下 Apache 修补程序。
OOZIE-2571:添加 spark.scala.binary.version Maven 属性,以便可以使用 Scala 2.11。
OOZIE-2606:设置 spark.yarn.jars 以修复包含 Oozie 的 Spark 2.0。
OOZIE-2658:--driver-class-path 可以覆盖 SparkMain 中的类路径。
OOZIE-2787:Oozie 分配应用程序 jar 两次,导致 spark 作业失败。
OOZIE-2792:当 Hive 位于 Spark 上时,
Hive2操作不会正确分析日志文件中的 Spark 应用程序 ID。OOZIE-2799:为 hive 上的 spark sql 设置日志位置。
OOZIE-2802:由于重复的
sharelibs,Spark 操作在 Spark 2.1.0 上失败。OOZIE-2923:改善 Spark 选项分析。
OOZIE-3109:SCA:跨站点脚本:已反映。
OOZIE-3139:Oozie 不正确地验证工作流。
OOZIE-3167:升级 Oozie 4.3 分支上的 tomcat 版本。
Phoenix
此版本提供 Phoenix 4.7.0 和以下 Apache 修补程序:
PHOENIX-1751:在 preScannerNext 而不是 postScannerOpen 中执行聚合、排序,等等。
PHOENIX-2714:在 BaseResultIterators 中正确估计字节并公开为接口。
PHOENIX-2724:无统计信息相比,具有大量 guideposts 的查询速度更慢。
PHOENIX-2855:不会对 HBase 1.2 序列化的递增 TimeRange 的解决方法。
PHOENIX-3023:按默认方式并行执行限制查询时性能降低。
PHOENIX-3040:不要使用 guideposts 串行执行查询。
PHOENIX-3112:无法正确处理部分行扫描。
PHOENIX-3240:Pig 加载程序中出现 ClassCastException。
PHOENIX-3452:NULLS FIRST/NULL LAST 不应影响 GROUP BY 是否为保序。
PHOENIX-3469:NULLS LAST/NULLS FIRST 的 DESC 主键的排序顺序错误。
PHOENIX-3789:在 postBatchMutateIndispensably 中执行跨区域索引维护调用。
PHOENIX-3865:未针对第一个列系列筛选时,IS NULL 不会返回正确的结果。
PHOENIX-4290:使用包含不可变索引的表对 DELETE 执行全表扫描。
PHOENIX-4373:执行更新插入时,本地索引变量长度键可能包含尾随的 null 值。
PHOENIX-4466:java.lang.RuntimeException:响应代码 500 - 执行 spark 作业以连接到 phoenix 查询服务器并加载数据。
PHOENIX-4489:Phoenix MR 作业中的 HBase 连接泄漏。
PHOENIX-4525:GroupBy 执行中的整数溢出。
PHOENIX-4560:如果
pk列中包含 WHERE,则 ORDER BY 和 GROUP BY 不起作用。PHOENIX-4586:UPSERT SELECT 不会考虑子查询的比较运算符。
PHOENIX-4588:如果表达式的子级包含 Determinism.PER_INVOCATION,则也会克隆表达式。
Pig
此版本提供 Pig 0.16.0 和以下 Apache 修补程序。
Ranger
此版本提供 Ranger 0.7.0 和以下 Apache 修补程序:
RANGER-1805:遵循 js 中的最佳做法改善代码。
RANGER-1960:考虑删除快照的表名称。
RANGER-1982:改善 Ranger Admin 和 Ranger KMS 分析指标的错误。
RANGER-1984:HBase 审核日志记录无法显示与访问过的列相关联的所有标记。
RANGER-1988:修复不安全的随机性。
RANGER-1990:在 Ranger Admin 中添加单向 SSL MySQL 支持。
RANGER-2006:修复静态代码分析在
usersync同步源的 rangerldap中检测到的问题。RANGER-2008:策略评估对于多行策略条件失败。
滑块
此版本提供 Slider 0.92.0,但不提供其他 Apache 修补程序。
Spark
此版本提供 Spark 2.3.0 和以下 Apache 修补程序:
SPARK-13587:支持 pyspark 中的 virtualenv。
SPARK-19964:避免从 SparkSubmitSuite 中的远程存储库读取。
SPARK-22882:结构化流的机器学习测试:ml.classification。
SPARK-22915:spark.ml.feature 的从 N 到 Z 的流测试。
SPARK-23020:在进程内启动程序测试中修复另一种争用情况。
SPARK-23040:返回随机读取器的可中断迭代器。
SPARK-23173:从 JSON 加载数据时避免创建损坏的 parquet 文件。
SPARK-23264:修复 literals.sql.out 中的 scala.MatchError。
SPARK-23288:修正 parquet 接收器的输出指标。
SPARK-23329:修正三角函数的文档。
SPARK-23406:为 branch-2.3 启用流到流的自联接。
SPARK-23434:Spark 不应针对 HDFS 文件路径的 `metadata directory` 发出警告。
SPARK-23436:仅当分区可以强制转换为日期时才将其推断为日期。
SPARK-23457:首先在 ParquetFileFormat 中注册任务完成侦听器。
SPARK-23462:改善 `StructType` 中的缺少字段错误消息。
SPARK-23490:在 CreateTable 中检查包含现有表的 storage.locationUri。
SPARK-23524:不应检查大型本地随机块是否已损坏。
SPARK-23525:支持外部 hive 表的 ALTER TABLE CHANGE COLUMN COMMENT。
SPARK-23553:测试不应假设默认值为 `spark.sql.sources.default`。
SPARK-23569:允许 pandas_udf 使用 python3 样式的类型批注函数。
SPARK-23570:在 HiveExternalCatalogVersionsSuite 中添加 Spark 2.3.0。
SPARK-23598:使 BufferedRowIterator 中的方法成为公共方法,以避免大型查询出现运行时错误。
SPARK-23599:从伪随机数添加 UUID 生成器。
SPARK-23599:在 Uuid 表达式中使用 RandomUUIDGenerator。
SPARK-23601:从版本中移除
.md5文件。SPARK-23608:在 attachSparkUI 和 detachSparkUI 函数之间添加 SHS 同步,以避免 Jetty 处理程序的并发修改问题。
SPARK-23614:修复使用缓存时错误地重复使用交换的问题。
SPARK-23623:避免在 CachedKafkaConsumer (branch-2.3) 中并发使用缓存的使用者。
SPARK-23624:在 Datasource V2 中修订方法 pushFilters 的文档。
SPARK-23628:calculateParamLength 不应返回 1 + 表达式数目。
SPARK-23630:允许用户的 hadoop 配置自定义项生效。
SPARK-23635:Spark 执行器环境变量由同名的 AM 环境变量覆盖。
SPARK-23637:如果多次终止同一个执行器,Yarn 可能会分配更多的资源。
SPARK-23639:在初始化 SparkSQL CLI 中的元存储客户端之前获取令牌。
SPARK-23642:修复 AccumulatorV2 子类 isZero
scaladoc。SPARK-23644:对 SHS 中的 REST 调用使用绝对路径。
SPARK-23645:添加文档 RE `pandas_udf` 和关键字参数。
SPARK-23649:跳过 UTF-8 中禁止的字符。
SPARK-23658:InProcessAppHandle 在 getLogger 中使用错误的类。
SPARK-23660:修复应用程序快速结束时 yarn 群集模式的异常。
SPARK-23670:修复 SparkPlanGraphWrapper 上的内存泄漏。
SPARK-23671:修复状态以启用 SHS 线程池。
SPARK-23691:尽量在 PySpark 测试中使用 sql_conf 实用工具。
SPARK-23695:修正 Kinesis 流测试的错误消息。
SPARK-23706:spark.conf.get(value, default=None) 应在 PySpark 中生成 None。
SPARK-23728:修复运行流测试时机器学习测试出现预期异常的问题。
SPARK-23729:解析 glob 时遵循 URI 分段。
SPARK-23759:无法将 Spark UI 绑定到特定的主机名/IP。
SPARK-23760:CodegenContext.withSubExprEliminationExprs 应正确保存/还原 CSE 状态。
SPARK-23769:移除不必要地禁用
Scalastyle检查的注释。SPARK-23788:修复 StreamingQuerySuite 中的争用问题。
SPARK-23802:PropagateEmptyRelation 可能在未解决的状态下退出查询计划。
SPARK-23806:与动态分配配合使用时,Broadcast.unpersist 可能导致严重异常。
SPARK-23808:在仅限测试的 spark 会话中设置默认的 Spark 会话。
SPARK-23809:Active SparkSession 应由 getOrCreate 设置。
SPARK-23816:已终止的任务应忽略 FetchFailures。
SPARK-23822:改善有关 Parquet 架构不匹配的错误消息。
SPARK-23823:在 transformExpression 中保留来源。
SPARK-23827:StreamingJoinExec 应确保将输入数据分区成特定数目的分区。
SPARK-23838:正在运行的 SQL 查询在 SQL 选项卡中显示为“已完成”。
SPARK-23881:修复测试 JobCancellationSuite 中出现的怪异消息“随机读取器的不间断迭代器”。
Sqoop
此版本提供 Sqoop 1.4.6,但不提供其他 Apache 修补程序。
Storm
此版本提供 Storm 1.1.1 和以下 Apache 修补程序:
STORM-2652:JmsSpout 打开方法中引发异常。
STORM-2841:testNoAcksIfFlushFails UT 失败并出现 NullPointerException。
STORM-2854:公开 IEventLogger,使事件日志可插入。
STORM-2870:FileBasedEventLogger 泄漏非守护程序 ExecutorService,从而阻止进程完成。
STORM-2960:更好地强调为 Storm 进程设置正确 OS 帐户的重要性。
Tez
此版本提供 Tez 0.7.0 和以下 Apache 修补程序:
- TEZ-1526:运行大型作业时,TezTaskID 的 LoadingCache 速度较慢。
Zeppelin
此版本提供 Zeppelin 0.7.3,但不提供其他 Apache 修补程序。
ZEPPELIN-3072:如果存在过多的 Notebook,Zeppelin UI 将会变慢/无响应。
ZEPPELIN-3129:Zeppelin UI 不会在 Internet Explorer 中退出登录。
ZEPPELIN-903:将 CXF 替换为
Jersey2。
ZooKeeper
此版本提供 ZooKeeper 3.4.6 和以下 Apache 修补程序:
ZOOKEEPER-1256:ClientPortBindTest 在 macOS X 上失败。
ZOOKEEPER-1901:[JDK8] 将子级排序,以便在 AsyncOps 测试中进行比较。
ZOOKEEPER-2423:由于安全漏洞而升级 Netty 版本 (CVE-2014-3488)。
ZOOKEEPER-2693:针对 wchp/wchc 四字母单词展开 DOS 攻击 (4lw)。
ZOOKEEPER-2726:修补程序造成潜在争用条件。
修复了常见漏洞和透露
本部分介绍此版本中已解决的所有常见漏洞和透露 (CVE) 问题。
CVE-2017-7676
| 摘要:Apache Ranger 策略评估忽略“*”通配符后面的字符 |
|---|
| 严重性:关键 |
| 供应商: Hortonworks |
| 受影响的版本:HDInsight 3.6 版本,包括 Apache Ranger 版本 0.5.x/0.6.x/0.7.0 |
| 受影响的用户:使用在“*”通配符后面包含字符的 Ranger 策略的环境,如 my*test、test*.txt |
| 影响:策略资源匹配程序将忽略“*”通配符后面的字符,从而可能导致意外的行为。 |
| 修复详细信息:Ranger 策略资源匹配程序已更新,可以正确处理通配符匹配。 |
| 建议的操作:升级到 HDI 3.6(使用 Apache Ranger 0.7.1+)。 |
CVE-2017-7677
| 摘要:指定了外部位置时,Apache Ranger Hive 授权者应检查 RWX 权限 |
|---|
| 严重性:关键 |
| 供应商: Hortonworks |
| 受影响的版本:HDInsight 3.6 版本,包括 Apache Ranger 版本 0.5.x/0.6.x/0.7.0 |
| 受影响的用户:对 hive 表使用外部位置的环境 |
| 影响:在对 hive 表使用外部位置的环境中,Apache Ranger Hive 授权者应检查指定用于创建表的外部位置的 RWX 权限。 |
| 修复详细信息:Ranger Hive 授权者已更新,可以使用外部位置正确处理权限检查。 |
| 建议的操作:用户应升级到 HDI 3.6(使用 Apache Ranger 0.7.1+)。 |
CVE-2017-9799
| 摘要:可能以 Apache Storm 中错误用户的身份执行代码 |
|---|
| 严重性:重要 |
| 供应商: Hortonworks |
| 受影响的版本:HDP-2.4.0、HDP-2.5.0、HDP-2.6.0 |
| 受影响的用户:在安全模式下使用 Storm,并使用 Blob 存储来分发基于拓扑的项目或使用 Blob 存储来分发任何拓扑资源的用户。 |
| 影响:在某些情况下使用 storm 的配置时,在理论上,拓扑的所有者能够以不同的非 root 用户身份欺骗监督程序来启动辅助角色。 在最坏的情况下,这可能导致其他用户的安全凭据泄密。 此漏洞仅适用于已启用安全性的 Apache Storm 安装。 |
| 缓解措施:目前没有解决方法,只能升级到 HDP 2.6.2.1。 |
CVE-2016-4970
| 摘要:4.0.37.Final 之前的 Netty 4.0.x 以及 4.1.1.Final 之前的 4.1.x 中的 handler/ssl/OpenSslEngine.java 允许远程攻击者造成拒绝服务(无限循环) |
|---|
| 严重性: 中等 |
| 供应商: Hortonworks |
| 受影响的版本:从 2.3.x 开始的 HDP 2.x.x |
| 受影响的用户:使用 HDFS 的所有用户。 |
| 影响:影响较低,因为 Hortonworks 不直接在 Hadoop 代码库中使用 OpenSslEngine.java。 |
| 建议的操作:升级到 HDP 2.6.3。 |
CVE-2016-8746
| 摘要:策略评估中存在 Apache Ranger 路径匹配问题 |
|---|
| 严重性:一般 |
| 供应商: Hortonworks |
| 受影响的版本:所有 HDP 2.5 版本,包括 Apache Ranger 版本 0.6.0/0.6.1/0.6.2 |
| 受影响的用户:Ranger 策略管理工具的所有用户。 |
| 影响:在某些情况下,当策略包含通配符和递归标志时,Ranger 策略引擎不会正确匹配路径。 |
| 修复详细信息: 已修复策略评估逻辑 |
| 建议的操作:用户应升级到 HDP 2.5.4+(使用 Apache Ranger 0.6.3+)或 HDP 2.6+(使用 Apache Ranger 0.7.0+) |
CVE-2016-8751
| 摘要:Apache Ranger 存储跨站点脚本问题 |
|---|
| 严重性:一般 |
| 供应商: Hortonworks |
| 受影响的版本:所有 HDP 2.3/2.4/2.5 版本,包括 Apache Ranger 版本 0.5.x/0.6.0/0.6.1/0.6.2 |
| 受影响的用户:Ranger 策略管理工具的所有用户。 |
| 影响:进入自定义的策略条件时,Apache Ranger 容易受到存储跨站点脚本攻击。 在普通用户登录并访问策略时,管理员用户可能会存储一些任意 JavaScript 代码执行。 |
| 修复详细信息:添加了逻辑来清理用户输入。 |
| 建议的操作:用户应升级到 HDP 2.5.4+(使用 Apache Ranger 0.6.3+)或 HDP 2.6+(使用 Apache Ranger 0.7.0+) |
修复了支持问题
修复的问题代表以前通过 Hortonworks 支持记录的、但现已在当前版本中解决的选定问题。 这些问题可能已在先前版本的“已知问题”部分中报告;这意味着,这些问题已由客户报告,或者由 Hortonworks 质量工程团队识别。
不正确的结果
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100019 | YARN-8145 | yarn rmadmin -getGroups 不返回已更新的用户组 |
| BUG-100058 | PHOENIX-2645 | 通配符与换行符不匹配 |
| BUG-100266 | PHOENIX-3521、PHOENIX-4190 | 包含本地索引的结果错误 |
| BUG-88774 | HIVE-17617、HIVE-18413、HIVE-18523 | query36 失败,行计数不匹配 |
| BUG-89765 | HIVE-17702 | 在 ORC 中的十进制读取器内进行错误的 isRepeating 处理。 |
| BUG-92293 | HADOOP-15042 | 当 numberOfPagesRemaining 为 0 时,Azure PageBlobInputStream.skip() 可以返回负值。 |
| BUG-92345 | ATLAS-2285 | UI:已使用日期属性重命名保存的搜索。 |
| BUG-92563 | HIVE-17495、HIVE-18528 | 聚合 ObjectStore 中的统计信息时收到错误的结果 |
| BUG-92957 | HIVE-11266 | 基于外部表的表统计信息 count(*) 错误结果 |
| BUG-93097 | RANGER-1944 | 用于管理审核的操作筛选器不起作用 |
| BUG-93335 | HIVE-12315 | vectorization_short_regress.q 在执行双精度计算时出现错误结果问题 |
| BUG-93415 | HIVE-18258、HIVE-18310 | 矢量化:包含重复列的化简端 GROUP BY MERGEPARTIAL 已破坏 |
| BUG-93939 | ATLAS-2294 | 创建类型时添加了额外的参数“description” |
| BUG-94007 | PHOENIX-1751、PHOENIX-3112 | 由于存在 HBase 部分行,Phoenix 查询返回 Null 值 |
| BUG-94266 | HIVE-12505 | 同一加密区域中的插入覆盖操作以无提示方式失败,以删除某些现有文件 |
| BUG-94414 | HIVE-15680 | 当 hive.optimize.index.filter=true 且在查询中两次引用同一个 ORC 表时,出现错误的结果 |
| BUG-95048 | HIVE-18490 | 使用 EXISTS 和 NOT EXISTS 且包含 non-equi 谓词的查询可能生成错误结果 |
| BUG-95053 | PHOENIX-3865 | 未针对第一个列系列筛选时,IS NULL 不会返回正确的结果 |
| BUG-95476 | RANGER-1966 | 在某些情况下,策略引擎初始化不会创建上下文扩充器 |
| BUG-95566 | SPARK-23281 | 当复合 order by 子句引用原始列和别名时,查询以错误的顺序生成结果 |
| BUG-95907 | PHOENIX-3451、PHOENIX-3452、PHOENIX-3469、PHOENIX-4560 | 修复当查询包含聚合时 ORDER BY ASC 出现的问题 |
| BUG-96389 | PHOENIX-4586 | UPSERT SELECT 不会考虑子查询的比较运算符。 |
| BUG-96602 | HIVE-18660 | PCR 无法区分分区和虚拟列 |
| BUG-97686 | ATLAS-2468 | [基本搜索]:当 NEQ 用于数字类型时,OR 大小写出现问题 |
| BUG-97708 | HIVE-18817 | 读取 ACID 表期间发生 ArrayIndexOutOfBounds 异常。 |
| BUG-97864 | HIVE-18833 | “作为 orcfile 插入目录时”自动合并失败 |
| BUG-97889 | RANGER-2008 | 策略评估对于多行策略条件失败。 |
| BUG-98655 | RANGER-2066 | HBase 列系列由该列系列中的某个标记列授权 |
| BUG-99883 | HIVE-19073、HIVE-19145 | StatsOptimizer 可能损坏常量列 |
其他
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100267 | HBASE-17170 | 由于类加载程序的差异,HBase 也正在重试 DoNotRetryIOException。 |
| BUG-92367 | YARN-7558 | 如果启用 UI 身份验证,获取运行中容器的日志的“yarn logs”命令会失败。 |
| BUG-93159 | OOZIE-3139 | Oozie 不正确地验证工作流 |
| BUG-93936 | ATLAS-2289 | 将从 KafkaNotification 实现中移出嵌入的 kafka/zookeeper 服务器启动/停止代码 |
| BUG-93942 | ATLAS-2312 | 使用 ThreadLocal DateFormat 对象避免从多个线程同时使用 |
| BUG-93946 | ATLAS-2319 | UI:在平面结构和树结构中的标记列表内删除第 25 个位置以后的某个标记需要刷新,这样才能从该列表中删除该标记。 |
| BUG-94618 | YARN-5037、YARN-7274 | 能够在叶队列级别禁用弹性 |
| BUG-94901 | HBASE-19285 | 添加每个表的延迟直方图 |
| BUG-95259 | HADOOP-15185、HADOOP-15186 | 将 adls 连接器更新为使用 ADLS SDK 的当前版本 |
| BUG-95619 | HIVE-18551 | 矢量化:VectorMapOperator 尝试为 Hybrid Grace 写入过许多的矢量列 |
| BUG-97223 | SPARK-23434 | Spark 不应针对 HDFS 文件路径的 `metadata directory` 发出警告 |
性能
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-83282 | HBASE-13376、HBASE-14473、HBASE-15210、HBASE-15515、HBASE-16570、HBASE-16810、HBASE-18164 | 均衡器中的快速位置计算 |
| BUG-91300 | HBASE-17387 | 在 multi() 的 RegionActionResult 中减少异常报告的开销 |
| BUG-91804 | TEZ-1526 | 运行大型作业时,TezTaskID 的 LoadingCache 速度较慢 |
| BUG-92760 | ACCUMULO-4578 | 取消压缩 FATE 操作不会释放命名空间锁 |
| BUG-93577 | RANGER-1938 | 用于审核设置的 Solr 不会有效使用 DocValues |
| BUG-93910 | HIVE-18293 | Hive 无法压缩运行 HiveMetaStore 的标识不拥有的某个文件夹中的表 |
| BUG-94345 | HIVE-18429 | 压缩应处理不生成任何输出的情况 |
| BUG-94381 | HADOOP-13227、HDFS-13054 | 处理 RequestHedgingProxyProvider RetryAction 顺序:FAIL < RETRY < FAILOVER_AND_RETRY。 |
| BUG-94432 | HIVE-18353 | CompactorMR 应调用 jobclient.close() 来触发清理 |
| BUG-94869 | PHOENIX-4290、PHOENIX-4373 | 为本地索引加盐 phoenix 表请求 Get on HRegion 的超出范围的行。 |
| BUG-94928 | HDFS-11078 | 修复 LazyPersistFileScrubber 中的 NPE |
| BUG-94964 | HIVE-18269、HIVE-18318、HIVE-18326 | 多项 LLAP 修复 |
| BUG-95669 | HIVE-18577、HIVE-18643 | 针对 ACID 分区表运行更新/删除查询时,HS2 读取所有分区。 |
| BUG-96390 | HDFS-10453 | 对大型群集中同一文件执行复制和删除造成的资源争用可能会导致 ReplicationMonitor 线程长时间停滞。 |
| BUG-96625 | HIVE-16110 | 还原“矢量化:支持 2 值 CASE WHEN,而不是回退到 VectorUDFAdaptor” |
| BUG-97109 | HIVE-16757 | 使用已弃用的 getRows() 而不是新的 estimateRowCount(RelMetadataQuery...) 会造成严重的性能影响 |
| BUG-97110 | PHOENIX-3789 | 在 postBatchMutateIndispensably 中执行跨区域索引维护调用 |
| BUG-98833 | YARN-6797 | TimelineWriter 不完全使用 POST 响应 |
| BUG-98931 | ATLAS-2491 | 更新 Hive 挂钩,以使用 Atlas v2 通知 |
可能的数据丢失
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-95613 | HBASE-18808 | 配置签入 BackupLogCleaner#getDeletableFiles() 的效率低下 |
| BUG-97051 | HIVE-17403 | 非托管表和事务表的串联失败 |
| BUG-97787 | HIVE-18460 | 压缩器不会将表属性传递给 Orc 写入器 |
| BUG-97788 | HIVE-18613 | 扩展 JsonSerDe 以支持 BINARY 类型 |
查询失败
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100180 | CALCITE-2232 | 调整聚合索引时 AggregatePullUpConstantsRule 出现断言错误 |
| BUG-100422 | HIVE-19085 | FastHiveDecimal abs(0) 将符号设置为 +ve |
| BUG-100834 | PHOENIX-4658 | IllegalStateException:无法对 ReversedKeyValueHeap 调用 requestSeek |
| BUG-102078 | HIVE-17978 | TPCDS 查询 58 和 83 在矢量化中生成异常。 |
| BUG-92483 | HIVE-17900 | 分析压缩器触发的列中的统计信息生成包含多个分区列的、格式不当的 SQL |
| BUG-93135 | HIVE-15874、HIVE-18189 | 将 hive.groupby.orderby.position.alias 设置为 true 时,Hive 查询返回错误结果 |
| BUG-93136 | HIVE-18189 | 禁用 cbo 时无法按位置排序 |
| BUG-93595 | HIVE-12378、HIVE-15883 | 在 Hive 中的 HBase 映射表内插入十进制和二进制列失败 |
| BUG-94007 | PHOENIX-1751、PHOENIX-3112 | 由于存在 HBase 部分行,Phoenix 查询返回 Null 值 |
| BUG-94144 | HIVE-17063 | 在首先删除分区的情况下,将覆盖分区插入外部表失败 |
| BUG-94280 | HIVE-12785 | 包含联合类型的视图和用于 `cast` 结构的 UDF 破坏 |
| BUG-94505 | PHOENIX-4525 | GroupBy 执行中的整数溢出 |
| BUG-95618 | HIVE-18506 | LlapBaseInputFormat - 负数组索引 |
| BUG-95644 | HIVE-9152 | CombineHiveInputFormat:Tez 中的 Hive 查询失败并出现 java.lang.IllegalArgumentException 异常 |
| BUG-96762 | PHOENIX-4588 | 如果表达式的子级包含 Determinism.PER_INVOCATION,则也会克隆表达式 |
| BUG-97145 | HIVE-12245、HIVE-17829 | 支持基于 HBase 的表的列注释 |
| BUG-97741 | HIVE-18944 | DPP 期间错误地设置了分组集位置 |
| BUG-98082 | HIVE-18597 | LLAP:始终打包 log4j2 的 org.apache.log4j API jar |
| BUG-99849 | 空值 | 通过文件向导创建一个新表,以尝试使用默认数据库 |
安全性
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100436 | RANGER-2060 | 使用 Knox 的 knox-sso 代理不适用于 ranger |
| BUG-101038 | SPARK-24062 | Zeppelin %Spark 解释器发生“连接被拒绝”错误,HiveThriftServer 中出现“必须指定机密密钥...”错误 |
| BUG-101359 | ACCUMULO-4056 | 在发布时将 commons-collection 的版本更新为 3.2.2 |
| BUG-54240 | HIVE-18879 | 如果 xercesImpl.jar 在类路径中,需要能够禁止在 UDFXPathUtil 中使用嵌入式元素 |
| BUG-79059 | OOZIE-3109 | 转义日志流的特定于 HTML 的字符 |
| BUG-90041 | OOZIE-2723 | JSON.org 许可证现在为 CatX |
| BUG-93754 | RANGER-1943 | 集合为空或 null 时,将跳过 Ranger Solr 授权 |
| BUG-93804 | HIVE-17419 | ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS 命令显示掩码表的计算统计信息 |
| BUG-94276 | ZEPPELIN-3129 | Zeppelin UI 不会在 Internet Explorer 中退出登录 |
| BUG-95349 | ZOOKEEPER-1256、ZOOKEEPER-1901 | 升级 netty |
| BUG-95483 | 空值 | CVE 2017-15713 的修复 |
| BUG-95646 | OOZIE-3167 | 升级 Oozie 4.3 分支上的 tomcat 版本 |
| BUG-95823 | 空值 |
Knox:升级 Beanutils |
| BUG-95908 | RANGER-1960 | 在删除快照时,HBase 身份验证不考虑表命名空间 |
| BUG-96191 | FALCON-2322、FALCON-2323 | 升级 Jackson 和 Spring 版本以避免安全漏洞 |
| BUG-96502 | RANGER-1990 | 在 Ranger Admin 中添加单向 SSL MySQL 支持 |
| BUG-96712 | FLUME-3194 | 将 derby 升级到最新版本 (1.14.1.0) |
| BUG-96713 | FLUME-2678 | 将 xalan 升级到 2.7.2 以处理 CVE-2014-0107 漏洞 |
| BUG-96714 | FLUME-2050 | 升级到 log4j2(正式发布时) |
| BUG-96737 | 空值 | 使用 Java io 文件系统方法来问本地文件 |
| BUG-96925 | 空值 | 将 Hadoop 中的 Tomcat 从 6.0.48 升级到 6.0.53 |
| BUG-96977 | FLUME-3132 | 升级 tomcat jasper 库依赖项 |
| BUG-97022 | HADOOP-14799、HADOOP-14903、HADOOP-15265 | 升级具有 4.39 以上版本的 Nimbus JOSE JWT 库 |
| BUG-97101 | RANGER-1988 | 修复不安全的随机性 |
| BUG-97178 | ATLAS-2467 | Spring 和 nimbus-jose-jwt 的依赖项升级 |
| BUG-97180 | 空值 | 升级 Nimbus-jose-jwt |
| BUG-98038 | HIVE-18788 | 清理 JDBC PreparedStatement 中的输入 |
| BUG-98353 | HADOOP-13707 | 还原“如果在未配置 HTTP SPNEGO 的情况下启用 kerberos,则无法访问某些链接” |
| BUG-98372 | HBASE-13848 | 通过凭据提供程序 API 访问 InfoServer SSL 密码 |
| BUG-98385 | ATLAS-2500 | 将更多标头添加到 Atlas 响应。 |
| BUG-98564 | HADOOP-14651 | 将 Okhttp 版本更新为 2.7.5 |
| BUG-99440 | RANGER-2045 | 使用“desc table”命令列出没有显式允许策略的 Hive 表列 |
| BUG-99803 | 空值 | Oozie 应禁用 HBase 动态类加载 |
稳定性
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100040 | ATLAS-2536 | Atlas Hive 挂钩中 NPE |
| BUG-100057 | HIVE-19251 | 具有 LIMIT 的 ObjectStore.getNextNotification 应使用较少的内存 |
| BUG-100072 | HIVE-19130 | REPL LOAD 应用删除分区事件后引发 NPE。 |
| BUG-100073 | 空值 | 从 hiveserver 到数据节点的 close_wait 连接过多 |
| BUG-100319 | HIVE-19248 | 如果文件复制失败,REPL LOAD 不会引发错误。 |
| BUG-100352 | 空值 | CLONE - RM 过于频繁地清除逻辑扫描/注册表 znode |
| BUG-100427 | HIVE-19249 | 复制:WITH 子句无法在所有情况下正确地向任务传递配置 |
| BUG-100430 | HIVE-14483 | java.lang.ArrayIndexOutOfBoundsException org.apache.orc.impl.TreeReaderFactory$BytesColumnVectorUtil.commonReadByteArrays |
| BUG-100432 | HIVE-19219 | 如果请求的事件已清理,增量 REPL DUMP 应引发错误。 |
| BUG-100448 | SPARK-23637、SPARK-23802、SPARK-23809、SPARK-23816、SPARK-23822、SPARK-23823、SPARK-23838、SPARK-23881 | 将 Spark2 更新到 2.3.0+(4 月 11 日版) |
| BUG-100740 | HIVE-16107 | JDBC:发生 NoHttpResponseException 时 HttpClient 应重试一次或多次 |
| BUG-100810 | HIVE-19054 | Hive 函数复制失败 |
| BUG-100937 | MAPREDUCE-6889 | 添加 Job#close API 以关闭 MR 客户端服务。 |
| BUG-101065 | ATLAS-2587 | 为 HA 中的 /apache_atlas/active_server_info znode 设置读取 ACL,以便 Knox 代理进行读取。 |
| BUG-101093 | STORM-2993 | 使用时间轮换策略时,Storm HDFS Bolt 引发 ClosedChannelException |
| BUG-101181 | 空值 | PhoenixStorageHandler 不会正确处理谓词中的 AND |
| BUG-101266 | PHOENIX-4635 | org.apache.phoenix.hive.mapreduce.PhoenixInputFormat 中的 HBase 连接泄漏 |
| BUG-101458 | HIVE-11464 | 存在多个输出时缺少沿袭信息 |
| BUG-101485 | 空值 | hive metastore thrift api 速度缓慢,导致客户端超时 |
| BUG-101628 | HIVE-19331 | Hive 增量复制到云失败。 |
| BUG-102048 | HIVE-19381 | FunctionTask 的 Hive 函数复制到云失败 |
| BUG-102064 | 空值 | ReplCopyTask 中的 Hive 复制 \[ onprem to onprem \] 测试失败 |
| BUG-102137 | HIVE-19423 | ReplCopyTask 中的 Hive 复制 \[ Onprem to Cloud \] 测试失败 |
| BUG-102305 | HIVE-19430 | HS2 和 hive 元存储 OOM 转储 |
| BUG-102361 | 空值 | 复制到目标 hive 群集 (onprem - s3) 的单个插入内容中存在多个插入结果 |
| BUG-87624 | 空值 | 启用 storm 事件日志记录导致工作线程持续关闭 |
| BUG-88929 | HBASE-15615 | RegionServerCallable 需要重试时休眠时间错误 |
| BUG-89628 | HIVE-17613 | 删除较短的相同线程分配的对象池 |
| BUG-89813 | 空值 | SCA:代码正确性:非同步方法重写同步方法 |
| BUG-90437 | ZEPPELIN-3072 | 如果存在过多的笔记本,Zeppelin UI 将会变慢/无响应 |
| BUG-90640 | HBASE-19065 | HRegion#bulkLoadHFiles() 应等待并发 Region#flush() 完成 |
| BUG-91202 | HIVE-17013 | 使用基于视图选择的子查询删除请求 |
| BUG-91350 | KNOX-1108 | NiFiHaDispatch 不会故障转移 |
| BUG-92054 | HIVE-13120 | 生成 ORC 拆分时传播 doAs |
| BUG-92373 | FALCON-2314 | 将 TestNG 版本升级到 6.13.1 以避免 BeanShell 依赖关系 |
| BUG-92381 | 空值 | testContainerLogsWithNewAPI 和 testContainerLogsWithOldAPI UT 失败 |
| BUG-92389 | STORM-2841 | testNoAcksIfFlushFails UT 失败并出现 NullPointerException |
| BUG-92586 | SPARK-17920、SPARK-20694、SPARK-21642、SPARK-22162、SPARK-22289、SPARK-22373、SPARK-22495、SPARK-22574、SPARK-22591、SPARK-22595、SPARK-22601、SPARK-22603、SPARK-22607、SPARK-22635、SPARK-22637、SPARK-22653、SPARK-22654、SPARK-22686、SPARK-22688、SPARK-22817、SPARK-22862、SPARK-22889、SPARK-22972、SPARK-22975、SPARK-22982、SPARK-22983、SPARK-22984、SPARK-23001、SPARK-23038、SPARK-23095 | 将最新的 Spark2 更新到 2.2.1(1 月 16 日版) |
| BUG-92680 | ATLAS-2288 | 通过 Hive 创建 hbase 表后运行 import-hive 脚本时出现 NoClassDefFoundError 异常 |
| BUG-92760 | ACCUMULO-4578 | 取消压缩 FATE 操作不会释放命名空间锁 |
| BUG-92797 | HDFS-10267、HDFS-8496 | 在某些用例中减少数据节点锁争用 |
| BUG-92813 | FLUME-2973 | hdfs 接收器中出现死锁 |
| BUG-92957 | HIVE-11266 | 基于外部表的表统计信息 count(*) 错误结果 |
| BUG-93018 | ATLAS-2310 | 在 HA 中,被动节点使用错误的 URL 编码重定向请求 |
| BUG-93116 | RANGER-1957 | 启用增量同步时,Ranger Usersync 不会定期同步用户或组。 |
| BUG-93361 | HIVE-12360 | 使用谓词下推在未压缩的 ORC 中进行错误查找 |
| BUG-93426 | CALCITE-2086 | 在某些情况下,大型授权标头导致 HTTP/413 |
| BUG-93429 | PHOENIX-3240 | Pig 加载程序中出现 ClassCastException |
| BUG-93485 | 空值 | 无法获取表 mytestorg.apache.hadoop.hive.ql.metadata.InvalidTableException:针对 LLAP 中的列运行分析表时找不到表 |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException:响应代码 500 - 执行 spark 作业以连接到 phoenix 查询服务器并加载数据 |
| BUG-93550 | 空值 | 由于 scala 版本不匹配,Zeppelin %spark.r 不适用于 spark1 |
| BUG-93910 | HIVE-18293 | Hive 无法压缩运行 HiveMetaStore 的标识不拥有的某个文件夹中的表 |
| BUG-93926 | ZEPPELIN-3114 | 在 >1d 压力测试后,笔记本和解释器不会在 zeppelin 中保存 |
| BUG-93932 | ATLAS-2320 | 包含查询的分类“*”引发 500 内部服务器异常。 |
| BUG-93948 | YARN-7697 | 由于日志聚合泄露 (part#1),NM 关闭并出现 OOM |
| BUG-93965 | ATLAS-2229 | DSL 搜索:orderby 非字符串属性引发异常 |
| BUG-93986 | YARN-7697 | 由于日志聚合泄露 (part#2),NM 关闭并出现 OOM |
| BUG-94030 | ATLAS-2332 | 使用具有嵌套集合数据类型的属性创建类型失败 |
| BUG-94080 | YARN-3742、YARN-6061 | 两个 RM 在安全群集中处于待机状态 |
| BUG-94081 | HIVE-18384 |
log4j2.x 库中发生 ConcurrentModificationException |
| BUG-94168 | 空值 | Yarn RM 关闭并且服务注册表处于错误的 ERROR 状态 |
| BUG-94330 | HADOOP-13190、HADOOP-14104、HADOOP-14814、HDFS-10489、HDFS-11689 | HDFS 应支持多个 KMS Uris |
| BUG-94345 | HIVE-18429 | 压缩应处理不生成任何输出的情况 |
| BUG-94372 | ATLAS-2229 | DSL 查询:hive_table name = ["t1","t2"] 引发 DSL 查询无效异常 |
| BUG-94381 | HADOOP-13227、HDFS-13054 | 处理 RequestHedgingProxyProvider RetryAction 顺序:FAIL < RETRY < FAILOVER_AND_RETRY。 |
| BUG-94432 | HIVE-18353 | CompactorMR 应调用 jobclient.close() 来触发清理 |
| BUG-94575 | SPARK-22587 | 如果 fs.defaultFS 和应用程序 jar 是不同的 url,Spark 作业将会失败 |
| BUG-94791 | SPARK-22793 | Spark Thrift 服务器出现内存泄漏 |
| BUG-94928 | HDFS-11078 | 修复 LazyPersistFileScrubber 中的 NPE |
| BUG-95013 | HIVE-18488 | LLAP ORC 读取器缺少一些 null 检查 |
| BUG-95077 | HIVE-14205 | Hive 不支持 AVRO 文件格式的联合类型 |
| BUG-95200 | HDFS-13061 | SaslDataTransferClient#checkTrustAndSend 不应信任部分信任的通道 |
| BUG-95201 | HDFS-13060 | 为 TrustedChannelResolver 添加 BlacklistBasedTrustedChannelResolver |
| BUG-95284 | HBASE-19395 | [branch-1] TestEndToEndSplitTransaction.testMasterOpsWhileSplitting 失败并出现 NPE |
| BUG-95301 | HIVE-18517 | 矢量化:修复 VectorMapOperator,以接受 VRB 并正确检查矢量化标志来支持 LLAP 缓存 |
| BUG-95542 | HBASE-16135 | 可能永远无法删除已删除的对等方的 rs 下的 PeerClusterZnode |
| BUG-95595 | HIVE-15563 | 忽略 SQLOperation.runQuery 中的非法操作状态转换异常,以公开实际异常。 |
| BUG-95596 | YARN-4126、YARN-5750 | TestClientRMService 失败 |
| BUG-96019 | HIVE-18548 | 修复 log4j 导入 |
| BUG-96196 | HDFS-13120 | concat 后,快照差异可能会损坏 |
| BUG-96289 | HDFS-11701 | 未解析的主机中的 NPE 导致永久性 DFSInputStream 失败 |
| BUG-96291 | STORM-2652 | JmsSpout 打开方法中引发异常 |
| BUG-96363 | HIVE-18959 | 避免在 LLAP 中创建额外的线程池 |
| BUG-96390 | HDFS-10453 | 对大型群集中同一文件执行复制和删除造成的资源争用可能会导致 ReplicationMonitor 线程长时间停滞。 |
| BUG-96454 | YARN-4593 | AbstractService.getConfig() 中出现死锁 |
| BUG-96704 | FALCON-2322 | submitAndSchedule 馈送时发生 ClassCastException |
| BUG-96720 | SLIDER-1262 |
Kerberized 环境中的 Slider 函数测试失败 |
| BUG-96931 | SPARK-23053、SPARK-23186、SPARK-23230、SPARK-23358、SPARK-23376、SPARK-23391 | 更新最新的 Spark2(2 月 19 日版) |
| BUG-97067 | HIVE-10697 | ObjectInspectorConvertors#UnionConvertor 执行错误的转换 |
| BUG-97244 | KNOX-1083 | HttpClient 默认超时应是一个有意义的值 |
| BUG-97459 | ZEPPELIN-3271 | 用于禁用计划程序的选项 |
| BUG-97511 | KNOX-1197 | 在服务中的 authentication=Anonymous 时,不会添加 AnonymousAuthFilter |
| BUG-97601 | HIVE-17479 | 不会针对更新/删除查询清理临时目录 |
| BUG-97605 | HIVE-18858 | 提交 MR 作业时不会解析作业配置中的系统属性 |
| BUG-97674 | OOZIE-3186 | Oozie 无法使用通过 jceks://file/... 链接的配置 |
| BUG-97743 | 空值 | 部署 storm 拓扑时发生 java.lang.NoClassDefFoundError 异常 |
| BUG-97756 | PHOENIX-4576 | 修复失败的 LocalIndexSplitMergeIT 测试 |
| BUG-97771 | HDFS-11711 | 发生“打开的文件过多”异常时 DN 不应删除块 |
| BUG-97869 | KNOX-1190 | Google OIDC 的 Knox SSO 支持已中断。 |
| BUG-97879 | PHOENIX-4489 | Phoenix MR 作业中的 HBase 连接泄漏 |
| BUG-98392 | RANGER-2007 | ranger-tagsync 的 Kerberos 票证无法续订 |
| BUG-98484 | 空值 | Hive 增量复制到云无法正常进行 |
| BUG-98533 | HBASE-19934、HBASE-20008 | 由于出现 Null 指针异常,HBase 快照还原失败 |
| BUG-98555 | PHOENIX-4662 | 重新发送缓存时 TableResultIterator.java 中发生 NullPointerException |
| BUG-98579 | HBASE-13716 | 停止使用 Hadoop 的 FSConstants |
| BUG-98705 | KNOX-1230 | 向 Knox 发送许多并发请求导致 URL 损坏 |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch 不会故障转移 |
| BUG-99107 | HIVE-19054 | 函数复制应使用“hive.repl.replica.functions.root.dir”作为根 |
| BUG-99145 | RANGER-2035 | 使用 Oracle 后端访问包含空 implClass 的 servicedefs 时出错 |
| BUG-99160 | SLIDER-1259 | Slider 在多宿主环境中无法工作 |
| BUG-99239 | ATLAS-2462 | 由于未在命令中提供任何表,针对所有表执行 Sqoop 导入引发 NPE |
| BUG-99301 | ATLAS-2530 | hive_process 和 hive_column_lineage 的名称属性开头存在换行符 |
| BUG-99453 | HIVE-19065 | 元存储客户端兼容性检查应包括 syncMetaStoreClient |
| BUG-99521 | 空值 | 重新实例化迭代器时,未重新创建 HashJoin 的 ServerCache |
| BUG-99590 | PHOENIX-3518 | RenewLeaseTask 中出现内存泄漏 |
| BUG-99618 | SPARK-23599、SPARK-23806 | 将 Spark2 更新到 2.3.0+(3 月 28 日版) |
| BUG-99672 | ATLAS-2524 | Hive 与 V2 通知挂钩 - 不正确地处理“alter view as”操作 |
| BUG-99809 | HBASE-20375 | 在 hbase spark 模块中删除 getCurrentUserCredentials 的使用 |
可支持性
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-87343 | HIVE-18031 | 支持“更改数据库”操作的复制。 |
| BUG-91293 | RANGER-2060 | 使用 Knox 的 knox-sso 代理不适用于 ranger |
| BUG-93116 | RANGER-1957 | 启用增量同步时,Ranger Usersync 不会定期同步用户或组。 |
| BUG-93577 | RANGER-1938 | 用于审核设置的 Solr 不会有效使用 DocValues |
| BUG-96082 | RANGER-1982 | 改善 Ranger Admin 和 Ranger Kms 分析指标的错误 |
| BUG-96479 | HDFS-12781 |
Datanode 关闭后,在 Namenode UI 中,Datanode 选项卡引发警告消息。 |
| BUG-97864 | HIVE-18833 | “作为 orcfile 插入目录时”自动合并失败 |
| BUG-98814 | HDFS-13314 | 如果检测到 FsImage 损坏,NameNode 应可选择性退出 |
升级
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100134 | SPARK-22919 | 还原“升级 Apache httpclient 版本” |
| BUG-95823 | 空值 |
Knox:升级 Beanutils |
| BUG-96751 | KNOX-1076 | 将 nimbus-jose-jwt 更新为 4.41.2 |
| BUG-97864 | HIVE-18833 | “作为 orcfile 插入目录时”自动合并失败 |
| BUG-99056 | HADOOP-13556 | 将 Configuration.getPropsWithPrefix 更改为使用 getProps 而不是迭代器 |
| BUG-99378 | ATLAS-2461、ATLAS-2554 | 用于在 Titan 图形数据库中导出 Atlas 数据的迁移实用工具 |
可用性
| Bug ID | Apache JIRA | 摘要 |
|---|---|---|
| BUG-100045 | HIVE-19056 | 当 ORC 文件包含 0 行时,FixAcidKeyIndex 中发生 IllegalArgumentException |
| BUG-100139 | KNOX-1243 | 规范化在 KnoxToken 服务中配置的所需 DN |
| BUG-100570 | ATLAS-2557 | 进行修复,以便在 UGI 中的组已错误设置或不为空时,能够 lookup hadoop ldap 组 |
| BUG-100646 | ATLAS-2102 | Atlas UI 改进:搜索结果页 |
| BUG-100737 | HIVE-19049 | 添加为 Druid 更改表和添加列的支持 |
| BUG-100750 | KNOX-1246 | 更新 Knox 中的服务配置,以支持 Ranger 的最新配置。 |
| BUG-100965 | ATLAS-2581 | 使用 V2 Hive 挂钩通知回归:将表移到不同的数据库 |
| BUG-84413 | ATLAS-1964 | UI:支持对搜索表中的列排序 |
| BUG-90570 | HDFS-11384、HDFS-12347 | 添加让均衡器分散 getBlocks 调用的选项,以避免 NameNode 的 rpc.CallQueueLength 峰值 |
| BUG-90584 | HBASE-19052 | FixedFileTrailer 应识别 branch-1.x 中的 CellComparatorImpl 类 |
| BUG-90979 | KNOX-1224 | 用于支持 HA 中的 Atlas 的 Knox 代理 HADispatcher。 |
| BUG-91293 | RANGER-2060 | 使用 knox-sso 的 Knox 代理不适用于 ranger |
| BUG-92236 | ATLAS-2281 | 使用 null/非 null 筛选器保存标记/类型属性筛选器查询。 |
| BUG-92238 | ATLAS-2282 | 如果存在 25 个以上的收藏项,只在创建后刷新时才显示保存的收藏搜索。 |
| BUG-92333 | ATLAS-2286 | 预生成的类型“kafka_topic”不应将“topic”属性声明为唯一属性 |
| BUG-92678 | ATLAS-2276 | hdfs_path 类型实体的路径值在 hive-bridge 中设置为小写。 |
| BUG-93097 | RANGER-1944 | 用于管理审核的操作筛选器不起作用 |
| BUG-93135 | HIVE-15874、HIVE-18189 | 将 hive.groupby.orderby.position.alias 设置为 true 时,Hive 查询返回错误结果 |
| BUG-93136 | HIVE-18189 | 在 cbo 禁用时,按位置排序不起作用 |
| BUG-93387 | HIVE-17600 | 使用户可设置 OrcFile 的“enforceBufferSize”。 |
| BUG-93495 | RANGER-1937 | Ranger tagsync 应处理 ENTITY_CREATE 通知,以支持 Atlas 导入功能 |
| BUG-93512 | PHOENIX-4466 | java.lang.RuntimeException:响应代码 500 - 执行 spark 作业以连接到 phoenix 查询服务器并加载数据 |
| BUG-93801 | HBASE-19393 | 使用 SSL 访问 HBase UI 时的 HTTP 413 FULL 标头。 |
| BUG-93804 | HIVE-17419 | ANALYZE TABLE...COMPUTE STATISTICS FOR COLUMNS 命令显示掩码表的计算统计信息 |
| BUG-93932 | ATLAS-2320 | 包含查询的分类“*”引发 500 内部服务器异常。 |
| BUG-93933 | ATLAS-2286 | 预生成的类型“kafka_topic”不应将“topic”属性声明为唯一属性 |
| BUG-93938 | ATLAS-2283、ATLAS-2295 | 分类的 UI 更新 |
| BUG-93941 | ATLAS-2296、ATLAS-2307 | 基本搜索增强,可以选择性地排除子类型实体和子分类类型 |
| BUG-93944 | ATLAS-2318 | UI:单击子标记两次会选择父标记 |
| BUG-93946 | ATLAS-2319 | UI:在平面结构和树结构中的标记列表内删除第 25 个位置以后的某个标记需要刷新,这样才能从该列表中删除该标记。 |
| BUG-93977 | HIVE-16232 | QuotedIdentifier 中的列支持统计信息计算 |
| BUG-94030 | ATLAS-2332 | 使用具有嵌套集合数据类型的属性创建类型失败 |
| BUG-94099 | ATLAS-2352 | Atlas 服务器应提供配置来指定 Kerberos DelegationToken 的有效性 |
| BUG-94280 | HIVE-12785 | 包含联合类型的视图和用于 `cast` 结构的 UDF 破坏 |
| BUG-94332 | SQOOP-2930 | Sqoop 作业 exec 不重写已保存的作业泛型属性 |
| BUG-94428 | 空值 |
Dataplane 探查器代理 REST API Knox 支持 |
| BUG-94514 | ATLAS-2339 | UI:基本搜索结果视图中“列”内的修改也影响 DSL。 |
| BUG-94515 | ATLAS-2169 | 配置硬删除时删除请求失败 |
| BUG-94518 | ATLAS-2329 | 如果用户单击另一个错误的标记,会显示 Atlas UI 多个悬停标记 |
| BUG-94519 | ATLAS-2272 | 使用保存搜索 API 保存已拖动列的状态。 |
| BUG-94627 | HIVE-17731 | 将面向外部用户的向后 compat 选项添加到 HIVE-11985 |
| BUG-94786 | HIVE-6091 | 为连接创建/关闭创建空的 pipeout 文件 |
| BUG-94793 | HIVE-14013 | 描述表未正确显示 unicode |
| BUG-94900 | OOZIE-2606、OOZIE-2658、OOZIE-2787、OOZIE-2802 | 设置 spark.yarn.jars 以修复包含 Oozie 的 Spark 2.0 |
| BUG-94901 | HBASE-19285 | 添加每个表的延迟直方图 |
| BUG-94908 | ATLAS-1921 | UI:使用实体和特征属性的搜索:UI 不执行范围检查,并允许为整型和浮点数据类型提供超限值。 |
| BUG-95086 | RANGER-1953 | 对用户组页列表做了改进 |
| BUG-95193 | SLIDER-1252 | Python 2.7.5-58 中 Slider 代理失败并出现 SSL 验证错误 |
| BUG 95314 | YARN-7699 | queueUsagePercentage 即将用作 getApp REST api 调用的 INF |
| BUG-95315 | HBASE-13947、HBASE-14517、HBASE-17931 | 将系统表分配到具有最高版本的服务器 |
| BUG-95392 | ATLAS-2421 | 通知更新为支持 V2 数据结构 |
| BUG-95476 | RANGER-1966 | 在某些情况下,策略引擎初始化不会创建上下文扩充器 |
| BUG-95512 | HIVE-18467 | 支持整个仓库转储/加载 + 创建/删除数据库事件 |
| BUG-95593 | 空值 | 扩展 Oozie DB 实用工具以支持 Spark2sharelib 创建 |
| BUG-95595 | HIVE-15563 | 忽略 SQLOperation.runQuery 中的非法操作状态转换异常,以公开实际异常。 |
| BUG-95685 | ATLAS-2422 | 导出:支持基于类型的导出 |
| BUG-95798 | PHOENIX-2714、PHOENIX-2724、PHOENIX-3023、PHOENIX-3040 | 不要使用 guideposts 串行执行查询 |
| BUG-95969 | HIVE-16828、HIVE-17063、HIVE-18390 | 分区视图失败并出现 FAILED:IndexOutOfBoundsException 索引:1,大小:1 |
| BUG-96019 | HIVE-18548 | 修复 log4j 导入 |
| BUG-96288 | HBASE-14123、HBASE-14135、HBASE-17850 | 向后移植 HBase 备份/还原 2.0 |
| BUG-96313 | KNOX-1119 |
Pac4J OAuth/OpenID 主体需要是可配置的 |
| BUG-96365 | ATLAS-2442 | 对实体资源拥有只读权限的用户无法执行基本搜索 |
| BUG-96479 | HDFS-12781 |
Datanode 关闭后,在 Namenode UI 中,Datanode 选项卡引发警告消息。 |
| BUG-96502 | RANGER-1990 | 在 Ranger Admin 中添加单向 SSL MySQL 支持 |
| BUG-96718 | ATLAS-2439 | 更新 Sqoop 挂钩以使用 V2 通知 |
| BUG-96748 | HIVE-18587 | 插入 DML 事件可能尝试针对目录计算校验和。 |
| BUG-96821 | HBASE-18212 | 在独立模式下出现本地文件系统 HBase 日志警告消息:无法在类 org.apache.hadoop.fs.FSDataInputStream 中调用“unbuffer”方法 |
| BUG-96847 | HIVE-18754 | REPL STATUS 应支持“with”子句 |
| BUG-96873 | ATLAS-2443 | 在传出的 DELETE 消息中捕获所需的实体属性 |
| BUG-96880 | SPARK-23230 | 当 hive.default.fileformat 是其他种类的文件类型时,创建 textfile 表会导致 serde 错误 |
| BUG-96911 | OOZIE-2571、OOZIE-2792、OOZIE-2799、OOZIE-2923 | 改善 Spark 选项分析 |
| BUG-97100 | RANGER-1984 | HBase 审核日志记录无法显示与访问过的列相关联的所有标记 |
| BUG-97110 | PHOENIX-3789 | 在 postBatchMutateIndispensably 中执行跨区域索引维护调用 |
| BUG-97145 | HIVE-12245、HIVE-17829 | 支持基于 HBase 的表的列注释 |
| BUG-97409 | HADOOP-15255 | LdapGroupsMapping 中的组名称支持大小写转换 |
| BUG-97535 | HIVE-18710 | 将 inheritPerms 扩展到 Hive 2.X 中的 ACID |
| BUG-97742 | OOZIE-1624 |
sharelib JAR 的排除模式 |
| BUG-97744 | PHOENIX-3994 | 索引 RPC 优先级仍依赖于 hbase-site.xml 中的控制器工厂属性 |
| BUG-97787 | HIVE-18460 | 压缩器不会将表属性传递给 Orc 写入器 |
| BUG-97788 | HIVE-18613 | 扩展 JsonSerDe 以支持 BINARY 类型 |
| BUG-97899 | HIVE-18808 | 统计信息更新失败时使压缩更加可靠 |
| BUG-98038 | HIVE-18788 | 清理 JDBC PreparedStatement 中的输入 |
| BUG-98383 | HIVE-18907 | 创建实用工具来解决 HIVE-18817 中的 acid 键索引问题 |
| BUG-98388 | RANGER-1828 | 合理的编码做法 - 在 ranger 中添加更多标头 |
| BUG-98392 | RANGER-2007 | ranger-tagsync 的 Kerberos 票证无法续订 |
| BUG-98533 | HBASE-19934、HBASE-20008 | 由于出现 Null 指针异常,HBase 快照还原失败 |
| BUG-98552 | HBASE-18083、HBASE-18084 | 使大/小文件清理线程数在 HFileCleaner 中可配置 |
| BUG-98705 | KNOX-1230 | 向 Knox 发送许多并发请求导致 URL 损坏 |
| BUG-98711 | 空值 | 在未修改 service.xml 的情况下,NiFi 调度无法使用双向 SSL |
| BUG-98880 | OOZIE-3199 | 让系统属性限制可配置 |
| BUG-98931 | ATLAS-2491 | 更新 Hive 挂钩,以使用 Atlas v2 通知 |
| BUG-98983 | KNOX-1108 | NiFiHaDispatch 不会故障转移 |
| BUG-99088 | ATLAS-2511 | 提供相应的选项用于选择地将数据库/表从 Hive 导入 Atlas |
| BUG-99154 | OOZIE-2844、OOZIE-2845、OOZIE-2858、OOZIE-2885 | Spark 查询失败并出现“java.io.FileNotFoundException: hive-site.xml (权限被拒绝)”异常 |
| BUG-99239 | ATLAS-2462 | 由于未在命令中提供任何表,针对所有表执行 Sqoop 导入引发 NPE |
| BUG-99636 | KNOX-1238 | 修复网关的自定义信任存储设置 |
| BUG-99650 | KNOX-1223 | Zeppelin 的 Knox 代理不按预期重定向 /api/ticket |
| BUG-99804 | OOZIE-2858 | HiveMain、ShellMain 和 SparkMain 不应在本地覆盖属性和配置文件 |
| BUG-99805 | OOZIE-2885 | 运行 Spark 操作不应该需要在类路径中使用 Hive |
| BUG-99806 | OOZIE-2845 | 替换在 HiveConf 中设置变量的基于反射的代码 |
| BUG-99807 | OOZIE-2844 | 当 log4j.properties 缺失或不可读时提高 Oozie 操作的稳定性 |
| RMP-9995 | AMBARI-22222 | 切换 druid 以使用 /var/druid 目录而不是本地磁盘上的 /apps/druid |
行为变更
| Apache 组件 | Apache JIRA | 摘要 | 详细信息 |
|---|---|---|---|
| Spark 2.3 | 不适用 | Apache Spark 发行说明中所述的更改 | - 提供了“弃用”文档和“行为变更”指南: https://spark.apache.org/releases/spark-release-2-3-0.html#deprecations - 对于 SQL 部分,提供了另一篇详细“迁移”指南(从 2.3 到 2.2):https://spark.apache.org/docs/latest/sql-programming-guide.html#upgrading-from-spark-sql-22-to-23| |
| Spark | HIVE-12505 | Spark 作业成功完成,但出现 HDFS 磁盘配额已满错误 |
场景: 当运行 insert overwrite 命令的用户的回收站文件夹中设置了配额时运行该命令。 以前的行为: 作业会成功,但无法将数据移到回收站。 结果可能错误地包含表中以前存在的一些数据。 新行为: 如果移到回收站失败,会永久删除文件。 |
| Kafka 1.0 | 不适用 | Apache Spark 发行说明中所述的更改 | https://kafka.apache.org/10/documentation.html#upgrade_100_notable |
| Hive/Ranger | INSERT OVERWRITE 需要其他 ranger hive 策略 |
场景:INSERT OVERWRITE 需要其他 ranger hive 策略 以前的行为: Hive INSERT OVERWRITE 查询像往常一样成功。 新行为: 升级到 HDP 2.6.x 之后,Hive INSERT OVERWRITE 查询意外失败并出现错误: 编译语句时出错:失败: HiveAccessControlException 权限被拒绝: 用户 jdoe 对 /tmp/* 没有写入权限(状态=42000,代码=40000) 从 HDP-2.6.0 开始,Hive INSERT OVERWRITE 查询需要 Ranger URI 策略才能允许写入操作,即使已通过 HDFS 策略为用户授予了写入特权。 解决方法/预期的客户操作: 1.在 Hive 存储库下创建新策略。 2.在显示“数据库”的下拉列表中,选择“URI”。 3.更新路径(示例:/tmp/*) 4.添加用户和组并保存。 5.重试 insert 查询。 |
|
| HDFS | 不适用 | HDFS 应支持多个 KMS Uris |
以前的行为: dfs.encryption.key.provider.uri 属性用于配置 KMS 提供程序路径。 新行为: 现已弃用 dfs.encryption.key.provider.uri,改用 hadoop.security.key.provider.path 来配置 KMS 提供程序路径。 |
| Zeppelin | ZEPPELIN-3271 | 用于禁用计划程序的选项 |
受影响的组件: Zeppelin-Server 以前的行为: 以前的 Zeppelin 版本未提供用于禁用计划程序的选项。 新行为:默认情况下,用户不再会看到计划程序,因为它默认已禁用。 解决方法/预期的客户操作: 若要启用计划程序,需要通过 Ambari 在 Zeppelin 中的自定义 zeppelin 站点设置下添加值为 true 的 azeppelin.notebook.cron.enable。 |
已知问题
HDInsight 与 ADLS Gen 2 集成 使用 Azure Data Lake Storage Gen 2 的 HDInsight ESP 群集在用户目录和权限上存在两个问题:
没有在头节点 1 上创建用户的主目录。 解决方法是,手动创建目录并将所有权更改为相应用户的 UPN。
/hdp 目录的权限当前未设置为 751。 这需要设置为该值
chmod 751 /hdp chmod -R 755 /hdp/apps
Spark 2.3
[SPARK-23523][SQL] SQL 规则 OptimizeMetadataOnlyQuery 导致错误的结果
[SPARK-23406] 流到流的自联接中存在 Bug
如果 Azure Data Lake Storage (Gen2) 是群集的默认存储,则 Spark 示例笔记本不可用。
企业安全性套餐
- Spark Thrift 服务器不接受来自 ODBC 客户端的连接。
解决方法步骤:
- 创建群集后等待大约 15 分钟。
- 检查 ranger UI 中是否存在 hivesampletable_policy。
- 重启 Spark 服务。 现在,STS 连接应该工作。
- Spark Thrift 服务器不接受来自 ODBC 客户端的连接。
解决方法步骤:
Ranger 服务检查失败的解决方法
RANGER-1607:从以前的 HDP 版本升级到 HDP 2.6.2 时 Ranger 服务检查失败的解决方法。
注意
仅当已在 Ranger 中启用 SSL 时。
尝试通过 Ambari 从以前的 HDP 版本升级到 HDP 2.6.1 时会出现此问题。 Ambari 使用 curl 调用对 Ambari 中的 Ranger 服务执行服务检查。 如果 Ambari 使用的 JDK 版本是 JDK-1.7,curl 调用将会失败并出现以下错误:
curl: (35) error:14077410:SSL routines:SSL23_GET_SERVER_HELLO:sslv3 alert handshake failure出现此错误的原因是 Ranger 中使用的 tomcat 版本是 Tomcat-7.0.7*。 使用 JDK-1.7 会与 Tomcat-7.0.7* 中提供的默认加密法产生冲突。
可通过两种方式解决此问题:
将 Ambari 中使用的 JDK 从 JDK 1.7 更新到 JDK 1.8(请参阅 Ambari 参考指南中的更改 JDK 版本部分)。
如果想要继续支持 JDK-1.7 环境:
在 Ambari Ranger 配置中的 ranger-admin-site 部分添加具有以下值的属性 ranger.tomcat.ciphers:
SSL_RSA_WITH_RC4_128_MD5、SSL_RSA_WITH_RC4_128_SHA、TLS_RSA_WITH_AES_128_CBC_SHA、SSL_RSA_WITH_3DES_EDE_CBC_SHA
如果为 Ranger-KMS 配置了环境,请在 Ambari Ranger 配置中的 theranger-kms-site 部分添加具有以下值的属性 ranger.tomcat.ciphers:
SSL_RSA_WITH_RC4_128_MD5、SSL_RSA_WITH_RC4_128_SHA、TLS_RSA_WITH_AES_128_CBC_SHA、SSL_RSA_WITH_3DES_EDE_CBC_SHA
注意
所述的值是工作示例,可能不会反映你的环境。 确保设置这些属性的方式与配置环境的方式相匹配。
RangerUI:转义在策略窗体中输入的策略条件文本
受影响的组件: Ranger
问题说明
如果用户想要创建包含自定义策略条件和表达式的策略,或文本中含有特殊字符,那么,强制实施策略将不起作用。 在数据库中保存策略之前,特殊字符将转换为 ASCII。
特殊字符:& < " ` '>
例如,保存策略后,条件 tags.attributes['type']='abc 将转换为以下内容。
tags.attds['dsds']='cssdfs'
可以通过在编辑模式下打开策略,查看包含这些字符的策略条件。
解决方法
选项 1:通过 Ranger REST API 创建/更新策略
REST URL: http://<host>:6080/service/plugins/policies
创建包含策略条件的策略:
以下示例将创建标记为 tags-test 的策略,并通过选择 select、update、create、drop、alter、index、lock、all 等所有 hive 组件权限,将该策略分配到策略条件为 astags.attr['type']=='abc' 的 public 组。
示例:
curl -H "Content-Type: application/json" -X POST http://localhost:6080/service/plugins/policies -u admin:admin -d '{"policyType":"0","name":"P100","isEnabled":true,"isAuditEnabled":true,"description":"","resources":{"tag":{"values":["tags-test"],"isRecursive":"","isExcludes":false}},"policyItems":[{"groups":["public"],"conditions":[{"type":"accessed-after-expiry","values":[]},{"type":"tag-expression","values":["tags.attr['type']=='abc'"]}],"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}]}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"service":"tagdev"}'更新包含策略条件的现有策略:
以下示例将更新标记为 tags-test 的策略,并通过选择 select、update、create、drop、alter、index、lock、all 等所有 hive 组件权限,将该策略分配到策略条件为 astags.attr['type']=='abc' 的 public 组。
REST URL: http://<host-name>:6080/service/plugins/policies/<policy-id>
示例:
curl -H "Content-Type: application/json" -X PUT http://localhost:6080/service/plugins/policies/18 -u admin:admin -d '{"id":18,"guid":"ea78a5ed-07a5-447a-978d-e636b0490a54","isEnabled":true,"createdBy":"Admin","updatedBy":"Admin","createTime":1490802077000,"updateTime":1490802077000,"version":1,"service":"tagdev","name":"P0101","policyType":0,"description":"","resourceSignature":"e5fdb911a25aa7f77af5a9546938d9ed","isAuditEnabled":true,"resources":{"tag":{"values":["tags"],"isExcludes":false,"isRecursive":false}},"policyItems":[{"accesses":[{"type":"hive:select","isAllowed":true},{"type":"hive:update","isAllowed":true},{"type":"hive:create","isAllowed":true},{"type":"hive:drop","isAllowed":true},{"type":"hive:alter","isAllowed":true},{"type":"hive:index","isAllowed":true},{"type":"hive:lock","isAllowed":true},{"type":"hive:all","isAllowed":true}],"users":[],"groups":["public"],"conditions":[{"type":"ip-range","values":["tags.attributes['type']=abc"]}],"delegateAdmin":false}],"denyPolicyItems":[],"allowExceptions":[],"denyExceptions":[],"dataMaskPolicyItems":[],"rowFilterPolicyItems":[]}'选项 2:应用 JavaScript 更改
更新 JS 文件的步骤:
在 /usr/hdp/current/ranger-admin 下找到 PermissionList.js 文件
找到 renderPolicyCondtion 函数的定义(第 404 行)。
从该函数中删除以下行,即在显示函数下(第 434 行)
val = _.escape(val);//Line No:460
删除上述行之后,Ranger UI 将允许你创建策略条件可以包含特殊字符的策略,并且针对同一策略执行策略评估将会成功。
HDInsight 与 ADLS Gen 2 的集成:ESP 群集出现用户目录和权限问题 1. 没有在头节点 1 上创建用户的主目录。 解决方法是,手动创建这些目录并将所有权更改为相应用户的 UPN。 2. /hdp 的权限当前未设置为 751。 这需要设置为 a. chmod 751 /hdp b. chmod -R 755 /hdp/apps
弃用
OMS 门户:我们已从指向 OMS 门户的 HDInsight 资源页中删除该链接。 Azure Monitor 日志一开始使用其自己的门户(称为 OMS 门户)来管理其配置并分析收集的数据。 此门户的所有功能已移至 Azure 门户,在其中继续进行开发。 HDInsight 已弃用 OMS 门户支持。 客户将在 Azure 门户中使用 HDInsight Azure Monitor 日志集成。
Spark 2.3:Spark 版本 2.3.0 弃用
正在升级
所有这些功能已在 HDInsight 3.6 中提供。 若要获取最新版本的 Spark、Kafka 和 R Server(机器学习服务),请在创建 HDInsight 3.6 群集时选择 Spark、Kafka 和 ML 服务版本。 若要获取 ADLS 支持,可以选择 ADLS 存储类型作为选项。 现有群集不会自动升级到这些版本。
在 2018 年 6 月后创建的所有新群集将自动获取所有开源项目的 1000 多个 bug 修复。 请遵循此指南,获取有关升级到较新 HDInsight 版本的最佳做法。