了解如何在 HDInsight 上使用 Apache Spark 分析 Application Insight 遥测数据。
Visual Studio Application Insights 是用于监视 Web 应用程序的分析服务。 可将 Application Insights 生成的遥测数据导出到 Azure 存储。 当数据位于 Azure 存储中后,可以使用 HDInsight 来分析数据。
先决条件
配置为使用 Application Insights 的应用程序。
熟悉基于 Linux 的 HDInsight 群集的创建过程。 有关详细信息,请参阅在 HDInsight 上创建 Apache Spark。
Web 浏览器。
开发和测试本文档时使用了以下资源:
配置为使用 Application Insights 的 Node.js Web 应用,用于生成 Application Insights 遥测数据。
HDInsight 群集上基于 Linux 的 Spark 版本 3.5 用于分析数据。
架构与规划
下图演示了本示例的服务体系结构:
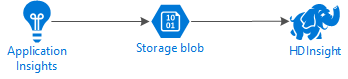
Azure 存储
Application Insights 可配置为将遥测信息连续导出到 blob。 然后,HDInsight 可读取存储在 blob 中的数据。 但是,必须符合某些要求:
位置:如果存储帐户和 HDInsight 位于不同位置,则可能会增加延迟。 此外还会增加成本,因为在区域之间移动数据会收取出口费用。
警告
不支持在 HDInsight 之外的其他位置使用存储帐户。
Blob 类型:HDInsight 仅支持块 Blob。 Application Insights 默认为使用块 Blob,因此,默认情况下可配合 HDInsight 一起使用。
有关向现有群集添加存储的信息,请参阅添加额外的存储帐户文档。
数据架构
Application Insights 为导出到 Blob 的遥测数据格式提供 导出数据模型 信息。 本文档中的步骤使用 Spark SQL 来处理数据。 Spark SQL 可以自动针对 Application Insights 记录的 JSON 数据结构生成架构。
导出遥测数据
根据配置连续导出中的步骤配置 Application Insights,将遥测信息导出到 Azure 存储 Blob。
配置 HDInsight 以访问数据
如果要创建 HDInsight 群集,请在创建群集期间添加存储帐户。
若要向现有群集添加 Azure 存储帐户,请使用添加额外的存储帐户文档中的信息。
分析数据:PySpark
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中 CLUSTERNAME 是群集的名称。在 Jupyter 页面右上角选择“新建”,并选择“PySpark”。 此时会打开新浏览器选项卡,其中包含基于 Python 的 Jupyter 笔记本。
在页面上的第一个字段(称为“单元格”)中输入以下文本:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')此代码将 Spark 配置为以递归方式访问输入数据的目录结构。 Application Insights 遥测数据将记录到类似于
/{telemetry type}/YYYY-MM-DD/{##}/的目录结构中。使用 SHIFT + ENTER 运行代码。 在单元格左侧,括号之间会出现“*”,以表示正在执行此单元格中的代码。 完成后,“*”会更改成数字,在单元格下面会显示类似于下面的输出:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...会在第一个单元格下方创建一个新单元格。 在新单元格中输入以下文本。 将
STORAGEACCOUNT和CONTAINER分别替换为包含 Application Insights 数据的 Azure 存储帐户名和 blob 容器名称。%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.chinacloudapi.cn/使用 SHIFT + ENTER 执行此单元格中的命令。 可看到类似于以下文本的结果:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.chinacloudapi.cn/contosoappinsights_2bededa61bc741fbdee6b556571a4831返回的 wasbs 路径是 Application Insights 遥测数据的位置。 将单元格中的
hdfs dfs -ls行更改为使用返回的 wasbs 路径,然后使用 Shift+Enter 再次执行单元格中的命令。 这一次,结果应显示包含遥测数据的目录。注意
本部分中的余下步骤使用了
wasbs://appinsights@contosostore.blob.core.chinacloudapi.cn/contosoappinsights_{ID}/Requests目录。 目录结构可能有所不同。在下一个单元格中输入以下代码:将
WASB_PATH替换为上一步中的路径。jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)此代码会从通过连续导出过程导出的 JSON 文件创建数据框架。 使用 SHIFT + ENTER 运行此单元格中的命令。
在下一个单元格中输入并运行以下命令,查看 Spark 为 JSON 文件创建的架构:
jsonData.printSchema()每种类型的遥测数据的架构各不相同。 以下示例是为 Web 请求生成的架构(数据存储在
Requests子目录中):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)使用以下命令将数据框架注册为临时表,并针对数据运行查询:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()此查询返回 context.location.city 不为 NULL 的前 20 条记录的城市信息。
注意
context 结构存在于由 Application Insights 记录的所有遥测中。 日志中可能没有填充 city 元素。 使用架构识别你可以查询的、可能包含日志数据的其他元素。
此查询返回类似于以下文本的信息:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
分析数据:Scala
在 Web 浏览器中,导航到
https://CLUSTERNAME.azurehdinsight.cn/jupyter,其中 CLUSTERNAME 是群集的名称。在 Jupyter 页面右上角选择“新建”,并选择“Scala”。 此时会打开新浏览器选项卡,其中包含基于 Scala 的 Jupyter Notebook。
在页面上的第一个字段(称为“单元格”)中输入以下文本:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")此代码将 Spark 配置为以递归方式访问输入数据的目录结构。 Application Insights 遥测数据将记录到类似于
/{telemetry type}/YYYY-MM-DD/{##}/的目录结构中。使用 SHIFT + ENTER 运行代码。 在单元格左侧,括号之间会出现“*”,以表示正在执行此单元格中的代码。 完成后,“*”会更改成数字,在单元格下面会显示类似于下面的输出:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...会在第一个单元格下方创建一个新单元格。 在新单元格中输入以下文本。 将
STORAGEACCOUNT和CONTAINER分别替换为包含 Application Insights 日志的 Azure 存储帐户名和 blob 容器名称。%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.chinacloudapi.cn/使用 SHIFT + ENTER 执行此单元格中的命令。 可看到类似于以下文本的结果:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.chinacloudapi.cn/contosoappinsights_2bededa61bc741fbdee6b556571a4831返回的 wasbs 路径是 Application Insights 遥测数据的位置。 将单元格中的
hdfs dfs -ls行更改为使用返回的 wasbs 路径,然后使用 Shift+Enter 再次执行单元格中的命令。 这一次,结果应显示包含遥测数据的目录。注意
本部分中的余下步骤使用了
wasbs://appinsights@contosostore.blob.core.chinacloudapi.cn/contosoappinsights_{ID}/Requests目录。 除非遥测数据用于 Web 应用,否则此目录可能并不存在。在下一个单元格中输入以下代码:将
WASB\_PATH替换为上一步中的路径。var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)此代码会从通过连续导出过程导出的 JSON 文件创建数据框架。 使用 SHIFT + ENTER 运行此单元格中的命令。
在下一个单元格中输入并运行以下命令,查看 Spark 为 JSON 文件创建的架构:
jsonData.printSchema每种类型的遥测数据的架构各不相同。 以下示例是为 Web 请求生成的架构(数据存储在
Requests子目录中):root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)使用以下命令将数据框架注册为临时表,并针对数据运行查询:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()此查询返回 context.location.city 不为 NULL 的前 20 条记录的城市信息。
注意
context 结构存在于由 Application Insights 记录的所有遥测中。 日志中可能没有填充 city 元素。 使用架构识别你可以查询的、可能包含日志数据的其他元素。
此查询返回类似于以下文本的信息:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
后续步骤
有关使用 Apache Spark 处理 Azure 中数据和服务的更多示例,请参阅以下文档:
- Apache Spark 与 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 和机器学习:使用 HDInsight 中的 Spark 结合 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
有关创建和运行 Spark 应用程序的信息,请参阅以下文档: