HDInsight 在 Spark 群集中有两个内置 Python 安装,即 Anaconda Python 2.7 和 Python 3.5。 客户可能需要自定义 Python 环境,例如安装外部 Python 包。 本文介绍的最佳做法涉及如何安全地管理 HDInsight 上 Apache Spark 群集的 Python 环境。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。 如果 HDInsight 上还没有 Spark 群集,则可以在群集创建过程中运行脚本操作。 访问有关如何使用自定义脚本操作的文档。
支持 HDInsight 群集上使用的开源软件
Azure HDInsight 服务使用围绕 Apache Hadoop 构建的开源技术环境。 Azure 为开源技术提供一般级别的支持。 有关详细信息,请参阅 Azure 支持常见问题解答网站。 HDInsight 服务为内置组件提供附加的支持级别。
HDInsight 服务中有两种类型的开放源代码组件:
| 组件 | 说明 |
|---|---|
| 内置 | 这些组件已预先安装在 HDInsight 群集上,并提供群集的核心功能。 例如,Apache Hadoop YARN 资源管理器、Apache Hive 查询语言 (HiveQL) 及 Mahout 库均属于此类别。 HDInsight 提供的 Apache Hadoop 群集版本的新增功能中提供了群集组件的完整列表。 |
| 自定义 | 群集用户可以安装或者在工作负荷中使用由社区提供的或自己创建的任何组件。 |
重要
完全支持通过 HDInsight 群集提供的组件。 Azure 支持部门将帮助找出并解决与这些组件相关的问题。
自定义组件可获得合理范围的支持,有助于进一步解决问题。 Azure 支持部门也许能够解决问题,也可能要求参与可用的开放源代码技术渠道,获取该技术的深入专业知识。 例如,有许多可以使用的社区站点,例如:有关 HDInsight 的 Microsoft Q&A 问题页面 (https://stackoverflow.com)。 此外,Apache 项目在 https://apache.org 上有项目站点。
了解默认 Python 安装
HDInsight Spark 群集已安装 Anaconda。 群集中有两个 Python 安装:Anaconda Python 2.7 和 Python 3.5。 下表显示 Spark、Livy 和 Jupyter 的默认 Python 设置。
| 设置 | Python 2.7 | Python 3.5 |
|---|---|---|
| 路径 | /usr/bin/anaconda/bin | /usr/bin/anaconda/envs/py35/bin |
| Spark 版本 | 默认设置为 2.7 | 可以将配置更改为 3.5 |
| Livy 版本 | 默认设置为 2.7 | 可以将配置更改为 3.5 |
| Jupyter | PySpark 内核 | PySpark3 内核 |
对于 Spark 3.1.2 版本,将移除 Apache PySpark 内核,并在 /usr/bin/miniforge/envs/py38/bin 下安装 PySpark3 内核使用的新 Python 3.8 环境。 PYSPARK_PYTHON 和 PYSPARK3_PYTHON 环境变量更新为以下内容:
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
export PYSPARK3_PYTHON=${PYSPARK_PYTHON:-/usr/bin/miniforge/envs/py38/bin/python}
安全安装外部 Python 包
HDInsight 群集依赖于内置 Python 环境(Python 2.7 和 Python 3.5)。 直接在这些默认内置环境中安装自定义包可能会导致意外的库版本更改, 并进一步破坏群集。 若要为 Spark 应用程序安全安装自定义外部 Python 包,请执行以下步骤。
使用 conda 创建 Python 虚拟环境。 虚拟环境为你的项目提供隔离的空间,且不会破坏其他项目。 创建 Python 虚拟环境时,可以指定要使用的 Python 版本。 即使要使用 Python 2.7 和 3.5,仍需要创建虚拟环境。 此要求是为了确保群集的默认环境不会受到破坏。 使用以下脚本在群集上为所有节点运行脚本操作,以创建 Python 虚拟环境。
--prefix指定 conda 虚拟环境所在的路径。 需要根据此处指定的路径进一步更改几项配置。 本示例使用 py35new,因为群集中已包含名为 py35 的现有虚拟环境。python=指定虚拟环境的 Python 版本。 本示例使用版本 3.5,即群集的内置版本。 也可以使用其他 Python 版本来创建虚拟环境。anaconda将 package_spec 指定为 anaconda,以在虚拟环境中安装 Anaconda 包。
sudo /usr/bin/anaconda/bin/conda create --prefix /usr/bin/anaconda/envs/py35new python=3.5 anaconda=4.3 --yes根据需要在创建的虚拟环境中安装外部 Python 包。 使用以下脚本在群集上为所有节点运行脚本操作,以安装外部 Python 包。 此处需要有 sudo 权限才能将文件写入虚拟环境文件夹。
在包索引中搜索可用包的完整列表。 也可以从其他源获取可用包的列表。 例如,可以安装通过 conda-forge 提供的包。
如果要安装具有最新版本的库,请使用以下命令:
使用 conda 通道:
seaborn是要安装的包名称。-n py35new指定刚创建的虚拟环境名称。 确保根据虚拟环境创建相应地更改名称。
sudo /usr/bin/anaconda/bin/conda install seaborn -n py35new --yes或者使用 PyPi 存储库,请相应地更改
seaborn和py35new:sudo /usr/bin/anaconda/envs/py35new/bin/pip install seaborn
如果要安装特定版本的库,请使用以下命令:
使用 conda 通道:
numpy=1.16.1是要安装的包名称和版本。-n py35new指定刚创建的虚拟环境名称。 确保根据虚拟环境创建相应地更改名称。
sudo /usr/bin/anaconda/bin/conda install numpy=1.16.1 -n py35new --yes或者使用 PyPi 存储库,请相应地更改
numpy==1.16.1和py35new:sudo /usr/bin/anaconda/envs/py35new/bin/pip install numpy==1.16.1
如果不知道虚拟环境名称,则可以通过 SSH 连接到群集的头节点并运行
/usr/bin/anaconda/bin/conda info -e以显示所有虚拟环境。更改 Spark 和 Livy 配置,并指向创建的虚拟环境。
打开 Ambari UI,转到“Spark 2”页的“配置”选项卡。
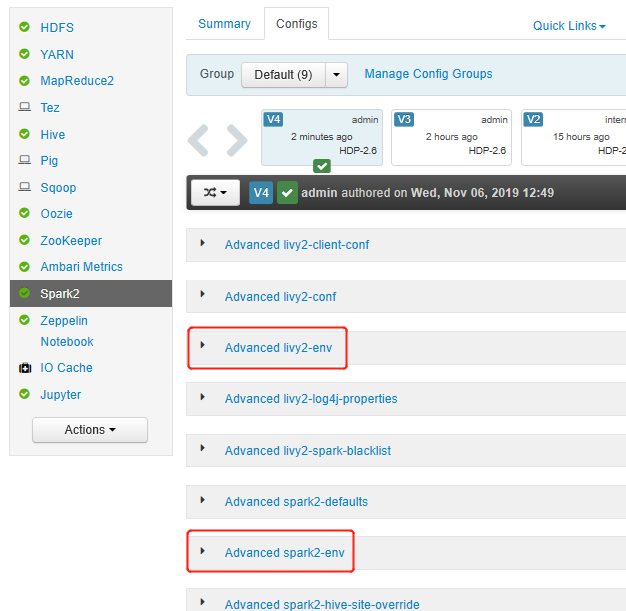
展开“高级 livy2-env”,将以下语句添加到底部。 如果使用不同的前缀安装了虚拟环境,请相应地更改路径。
export PYSPARK_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python export PYSPARK_DRIVER_PYTHON=/usr/bin/anaconda/envs/py35new/bin/python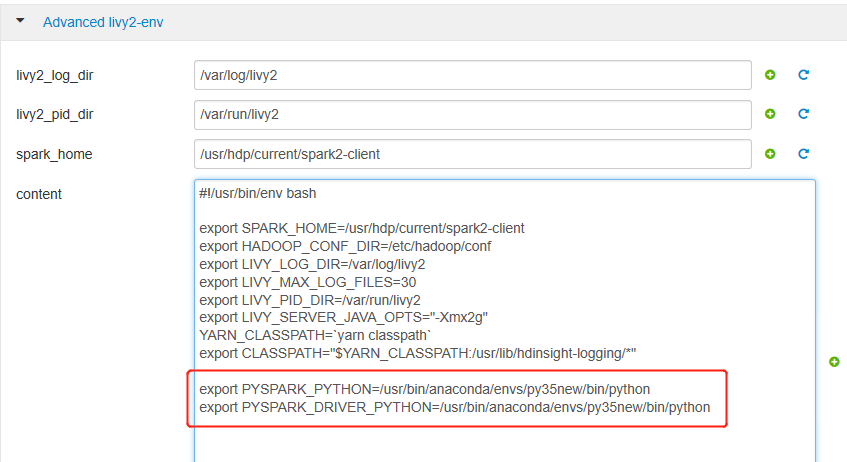
展开“高级 spark2-env”,替换底部的现有 export PYSPARK_PYTHON 语句。 如果使用不同的前缀安装了虚拟环境,请相应地更改路径。
export PYSPARK_PYTHON=${PYSPARK_PYTHON:-/usr/bin/anaconda/envs/py35new/bin/python}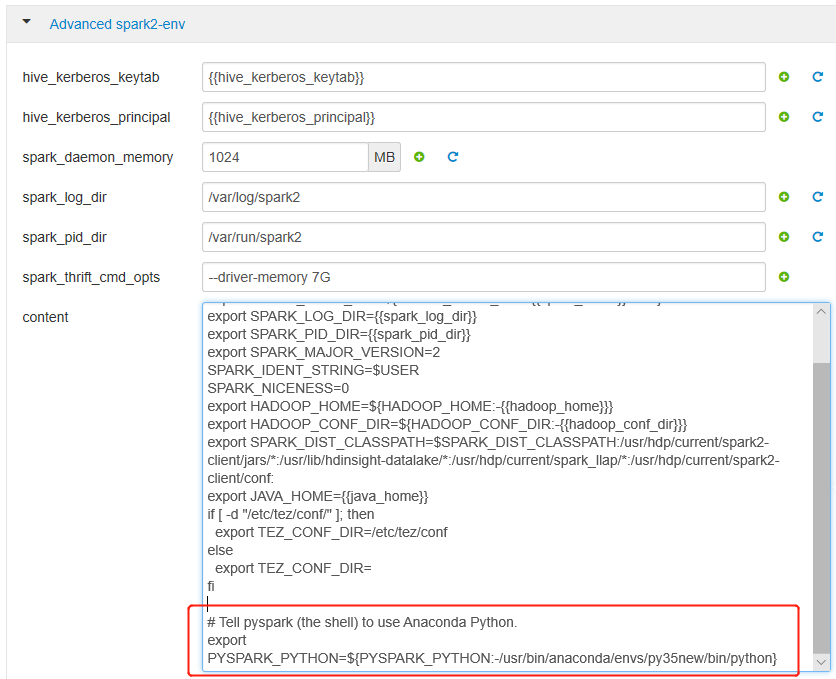
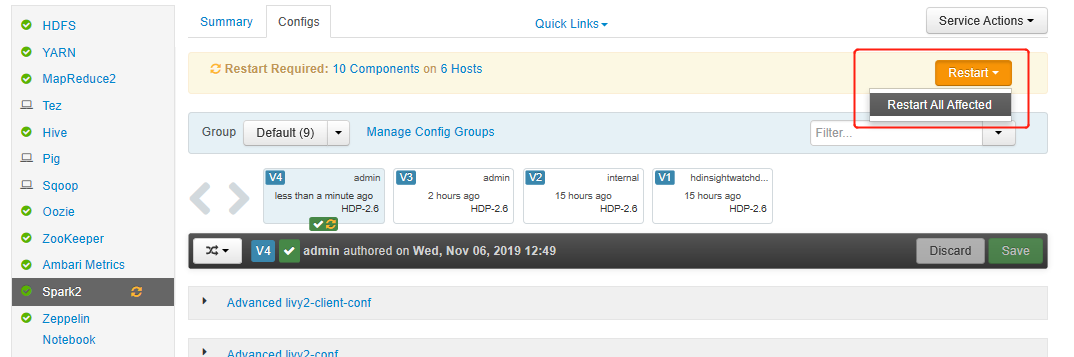
保存更改并重启受影响的服务。 这些更改需要重启 Spark 2 服务。 Ambari UI 将提示需要重启。单击“重启”以重启所有受影响的服务。
为 Spark 会话设置两个属性,以确保作业指向更新的 spark 配置:
spark.yarn.appMasterEnv.PYSPARK_PYTHON和spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON。使用终端或笔记本时,使用
spark.conf.set函数。spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python") spark.conf.set("spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON", "/usr/bin/anaconda/envs/py35/bin/python")如果使用的是
livy,请将以下属性添加到请求正文:"conf" : { "spark.yarn.appMasterEnv.PYSPARK_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python", "spark.yarn.appMasterEnv.PYSPARK_DRIVER_PYTHON":"/usr/bin/anaconda/envs/py35/bin/python" }
如果要在 Jupyter 上使用新创建的虚拟环境。 更改 Jupyter 配置并重启 Jupyter。 使用以下语句在所有头节点上运行脚本操作,使 Jupyter 指向新创建的虚拟环境。 请务必修改针对虚拟环境指定的前缀的路径。 运行此脚本操作后,通过 Ambari UI 重启 Jupyter 服务,使此项更改生效。
sudo sed -i '/python3_executable_path/c\ \"python3_executable_path\" : \"/usr/bin/anaconda/envs/py35new/bin/python3\"' /home/spark/.sparkmagic/config.json可以通过运行以下代码,在 Jupyter Notebook 中再次确认 Python 环境: