适用于: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
如果要分析 Parquet 文件或以 Parquet 格式写入数据,请遵循此文章中的说明。
以下连接器支持 Parquet 格式:
- Amazon S3
- Amazon S3 兼容存储
- Azure Blob
- Azure Data Lake Storage Gen2
- Azure Files
- 文件系统
- FTP
- Google 云存储
- HDFS
- HTTP
- Oracle 云存储
- SFTP
有关所有可用连接器支持的功能的列表,请访问连接器概述一文。
使用自托管集成运行时
重要
对于通过自托管集成运行时授权的复制操作,例如在本地和云数据存储之间,如果您不以原样复制 Parquet 文件,则需要在 IR 机器上安装64 位 JRE 8(Java 运行时环境)、JDK 23(Java 开发工具包)或 OpenJDK。 请查看以下段落以了解更多详细信息。
对于在自托管 IR 上使用 Parquet 文件序列化/反序列化的运行任务,该服务首先会检查注册表(SOFTWARE\JavaSoft\Java Runtime Environment\{Current Version}\JavaHome)以寻找 JRE,如果没有找到,再检查系统变量JAVA_HOME以寻找 OpenJDK,从而定位 Java 运行时。
- 若要使用 JRE:64 位 IR 需要 64 位 JRE。 可在此处找到它。
-
若要使用 JDK:64 位 IR 需要 64 位 JDK 23。 可在此处找到它。 请务必将
JAVA_HOME系统变量更新为 JDK 23 安装的根文件夹,即C:\Program Files\Java\jdk-23,并将C:\Program Files\Java\jdk-23\bin和C:\Program Files\Java\jdk-23\bin\server文件夹的路径添加到Path系统变量中。 - 若要使用 OpenJDK:从 IR 版本 3.13 开始受支持。 将 jvm.dll 以及所有其他必需的 OpenJDK 程序集打包到自承载 IR 计算机中,并相应地设置系统环境变量 JAVA_HOME,然后重启自承载 IR,以便立即生效。 若要下载Microsoft Build of OpenJDK,请参阅 Microsoft Build of OpenJDK 。
提示
如果使用自承载集成运行时向/从 Parquet 格式复制数据并出现错误,显示“调用 java 时出错,消息:java.lang.OutOfMemoryError: Java 堆空间”,你可以在托管自承载 IR 的计算机上添加环境变量 _JAVA_OPTIONS,以调整 JVM 的最小/最大堆大小,从而支持数据复制,然后重新运行管道。
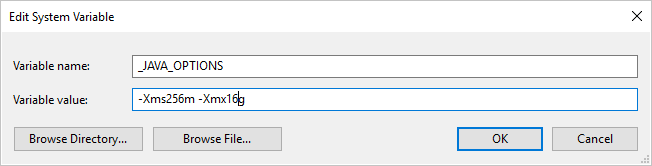
示例:将变量 _JAVA_OPTIONS 的值设置为 -Xms256m -Xmx16g。 标志 Xms指定Java虚拟机(JVM)的初始内存分配池,而 Xmx指定最大内存分配池。 这意味着 JVM 初始内存为 Xms,并且能够使用的最多内存为 Xmx。 默认情况下,该服务最少使用 64 MB 且最多使用 1G。
数据集属性
有关可用于定义数据集的各部分和属性的完整列表,请参阅数据集一文。 本部分提供了 Parquet 数据集支持的属性列表。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 数据集的 type 属性必须设置为 Parquet。 | 是 |
| 位置 | 文件的位置设置。 每个基于文件的连接器在 location 下都有其自己的位置类型和支持的属性。 请在连接器文章 -> 数据集属性部分中查看详细信息。 |
是 |
| 压缩编解码器 | 写入到 Parquet 文件时要使用的压缩编解码器。 从 Parquet 文件中读取时,数据工厂会基于文件元数据自动确定压缩编解码器。 支持的类型为“none”、“gzip”、“snappy”(默认值)和“lzo” 。 请注意,读取/写入 Parquet 文件时,当前 Copy activity 不支持 LZO。 |
否 |
注意
Parquet 文件不支持列名称中包含空格。
下面是 Azure Blob Storage 上的 Parquet 数据集示例:
{
"name": "ParquetDataset",
"properties": {
"type": "Parquet",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"compressionCodec": "snappy"
}
}
}
复制活动 属性
有关可用于定义活动的各部分和属性的完整列表,请参阅管道一文。 本部分提供了 Parquet 源和接收器支持的属性列表。
Parquet 作为源
复制活动 *source* 节中支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动源的 type 属性必须设置为 ParquetSource。 | 是 |
| storeSettings | 有关如何从数据存储读取数据的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自己支持的读取设置。
有关详细信息,请参阅连接器文章中的“复制活动属性”部分>。 |
否 |
Parquet 作为接收器
复制操作中的 sink 节支持以下属性。
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | 复制活动接收器的 type 属性必须设置为“ParquetSink”。 | 是 |
| 格式设置 | 一组属性。 请参阅下面的《Parquet 写入设置》表。 | 否 |
| storeSettings | 有关如何将数据写入到数据存储的一组属性。 每个基于文件的连接器在 storeSettings 下都有其自身支持的写入设置。
有关详细信息,请参阅连接器文章中的“复制活动属性”部分>。 |
否 |
下支持的 Parquet 写入设置:
| 属性 | 描述 | 必需 |
|---|---|---|
| 类型 | formatSettings 的类型必须设置为 ParquetWriteSettings。 | 是 |
| maxRowsPerFile | 在将数据写入到文件夹时,可选择写入多个文件,并指定每个文件的最大行数。 | 否 |
| 文件名前缀 | 配置 maxRowsPerFile 时适用。在将数据写入多个文件时,指定文件名前缀,生成的模式为 <fileNamePrefix>_00000.<fileExtension>。 如果未指定,将自动生成文件名前缀。 如果源是基于文件的存储或已启用分区选项的数据存储,则此属性不适用。 |
否 |
映射数据流属性
在映射数据流中, 可以在以下数据存储中读取和写入 parquet 格式:
源属性
下表列出了 parquet 源支持的属性。 可以在“源选项”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 格式 | 格式必须为 parquet |
是 | parquet |
格式 |
| 通配符路径 | 将处理与通配符路径匹配的所有文件。 重写数据集中设置的文件夹和文件路径。 | 否 | String[] | 通配符路径 |
| 分区根路径 | 对于已分区的文件数据,可以输入分区根路径,以便将已分区的文件夹读取为列 | 否 | 字符串 | 分区根路径 |
| 文件列表 | 源是否指向某个列出待处理文件的文本文件 | 否 |
true 或 false |
文件列表 |
| 用于存储文件名的列 | 使用源文件名称和路径创建新列 | 否 | 字符串 | rowUrlColumn |
| 完成后 | 在处理后删除或移动文件。 文件路径从容器根开始 | 否 | 删除:true 或 false 移动: [<from>, <to>] |
purgeFiles moveFiles |
| 按上次修改时间筛选 | 选择根据上次更改时间筛选文件 | 否 | 时间戳 | modifiedAfter 修改前 |
| 允许找不到文件 | 如果为 true,则找不到文件时不会引发错误 | 否 |
true 或 false |
ignoreNoFilesFound |
源示例
下图是映射数据流中 Parquet 源配置的一个示例。
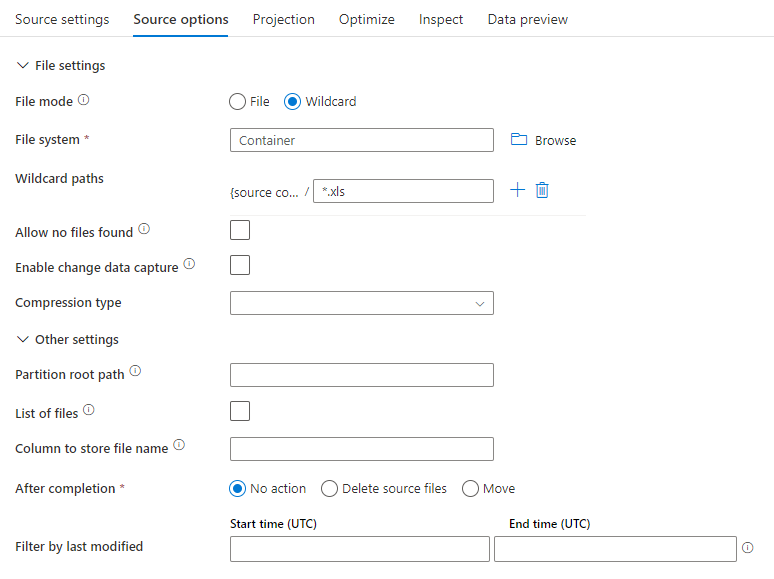
关联的数据流脚本为:
source(allowSchemaDrift: true,
validateSchema: false,
rowUrlColumn: 'fileName',
format: 'parquet') ~> ParquetSource
接收器属性
下表列出了 parquet 汇聚点所支持的属性。 你可以在“设置”选项卡中编辑这些属性。
| 名称 | 描述 | 必需 | 允许的值 | 数据流脚本属性 |
|---|---|---|---|---|
| 格式 | 格式必须为 parquet |
是 | parquet |
格式 |
| 清除文件夹 | 如果在写入前目标文件夹已被清除 | 否 |
true 或 false |
截断 |
| 文件名选项 | 写入的数据的命名格式。 默认情况下,每个分区有一个 part-#####-tid-<guid> 格式的文件 |
否 | 模式:字符串 每分区:String[] 作为列中的数据:字符串 输出到单个文件: ['<fileName>'] |
filePattern partitionFileNames rowUrlColumn partitionFileNames |
接收器示例
下图是映射数据流中 Parquet 终端配置的示例。
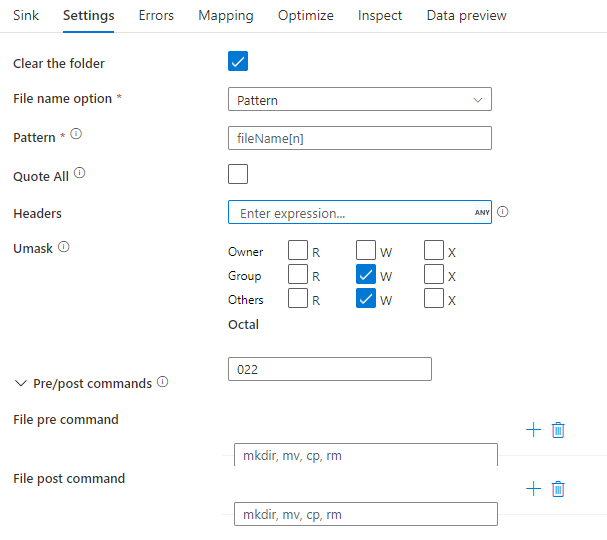
关联的数据流脚本为:
ParquetSource sink(
format: 'parquet',
filePattern:'output[n].parquet',
truncate: true,
allowSchemaDrift: true,
validateSchema: false,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> ParquetSink
Parquet 的数据类型映射
当从 Parquet 格式的数据源连接器读取数据时,将使用以下映射,从 Parquet 数据类型映射到服务内部的临时数据类型。
| Parquet 类型 | 临时服务数据类型 |
|---|---|
| BOOLEAN | 布尔 |
| INT_8 | SByte |
| INT_16 | Int16 |
| INT_32 | Int32 |
| INT_64 | Int64 |
| INT96 | 日期时间 |
| UINT_8 | 字节(Byte) |
| UINT_16 | UInt16 |
| UINT_32 | UInt32 |
| UINT_64 | UInt64 |
| DECIMAL | Decimal |
| FLOAT | Single |
| DOUBLE | Double |
| DATE | 日期 |
| TIME_MILLIS | TimeSpan |
| TIME_MICROS | Int64 |
| TIMESTAMP_MILLIS | 日期时间 |
| TIMESTAMP_MICROS | Int64 |
| STRING | 字符串 |
| UTF8 | 字符串 |
| ENUM | 字节数组 |
| 唯一通用识别码 (UUID) | 字节数组 |
| JSON | 字节数组 |
| BSON | 字节数组 |
| BINARY | 字节数组 |
| 固定长度字节数组 (FIXED_LEN_BYTE_ARRAY) | 字节数组 |
当以 Parquet 格式将数据写入接收器连接器时,服务内部使用的中间数据类型会被映射为 Parquet 数据类型。
| 临时服务数据类型 | Parquet 类型 |
|---|---|
| 布尔 | BOOLEAN |
| SByte | INT_8 |
| Int16 | INT_32 |
| Int32 | INT_32 |
| Int64 | INT_64 |
| 字节(Byte) | INT_32 |
| UInt16 | INT_32 |
| UInt32 | INT_64 |
| UInt64 | DECIMAL |
| Decimal | DECIMAL |
| Single | FLOAT |
| Double | DOUBLE |
| 日期 | DATE |
| 日期时间 | INT96 |
| DateTimeOffset | INT96 |
| TimeSpan | INT96 |
| 字符串 | UTF8 |
| GUID | UTF8 |
| 字节数组 | BINARY |
若要了解复制活动如何将源架构和数据类型映射到接收器,请参阅架构和数据类型映射。
Parquet 复杂数据类型(如 MAP、LIST、STRUCT)目前仅在数据流中被支持,而在复制活动中不被支持。 若要在数据流中使用复杂类型,请不要在数据集中导入文件架构,而是在数据集中将架构留空。 然后,在源转换中导入投影。