在 Azure Toolkit for Eclipse 中使用 HDInsight 工具开发以 Scala 编写的 Apache Spark 应用程序,并直接从 Eclipse IDE 将其提交到 Azure HDInsight Spark 群集。 可以通过多种不同方式使用 HDInsight 工具插件:
- 在 HDInsight Spark 群集中开发和提交 Scala Spark 应用程序。
- 访问 Azure HDInsight Spark 群集资源。
- 在本地开发和运行 Scala Spark 应用程序。
先决条件
HDInsight 上的 Apache Spark 群集。 有关说明,请参阅在 Azure HDInsight 中创建 Apache Spark 群集。
Eclipse IDE。 本文使用适用于 Java 开发人员的 Eclipse IDE。
安装所需插件
安装用于 Eclipse 的 Azure 工具包
有关安装说明,请参阅安装用于 Eclipse 的 Azure 工具包。
安装 Scala 插件
打开 Eclipse 时,HDInsight 工具会自动检测是否安装了 Scala 插件。 选择“确定”继续,然后按照说明从 Eclipse Marketplace 安装插件。 安装完成后重启 IDE。
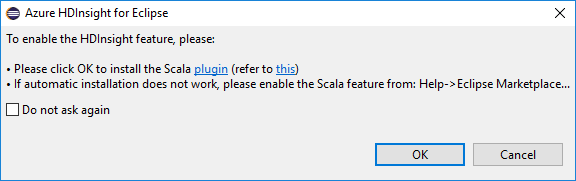
确认插件
导航到“帮助”>“Eclipse Marketplace...” 。
选择“已安装”选项卡。
至少应该看到:
- Azure Toolkit for Eclipse <版本>。
- Scala IDE <版本>。
登录到 Azure 订阅
启动 Eclipse IDE。
导航到“窗口”>“显示视图”>其他…”>“登录…” 。
从“显示视图”对话框中导航到“Azure”>“Azure 资源管理器”,然后选择“打开” 。
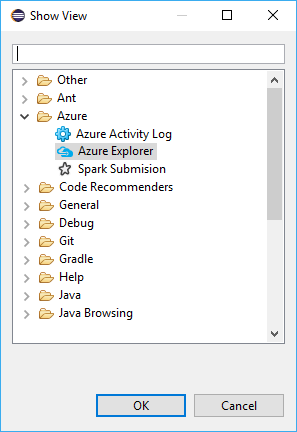
在 Azure 资源管理器中右键单击“Azure”节点,然后选择“登录” 。
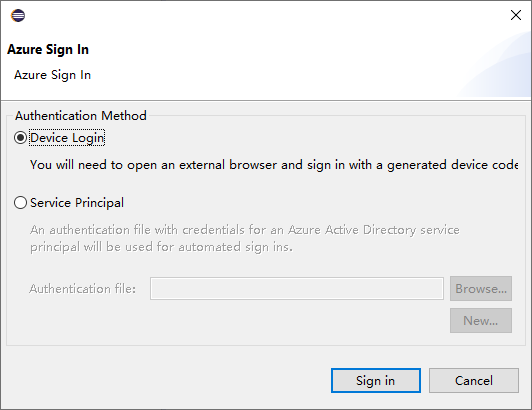
在“Azure 登录”对话框框中,选择“身份验证方法”,选择“登录”并完成登录过程 。
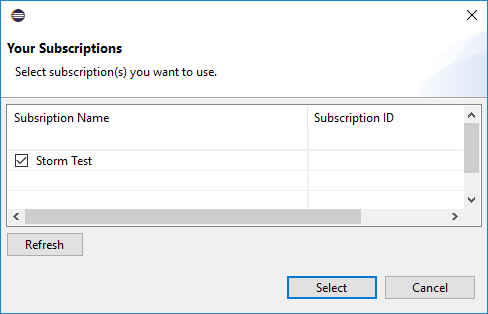
登录之后,“你的订阅”对话框会列出与凭据关联的所有 Azure 订阅。 按“选择”关闭对话框。
从“Azure 资源管理器”选项卡导航到“Azure”>“HDInsight”,查看订阅下的 HDInsight Spark 群集 。
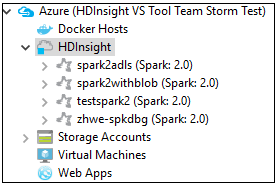
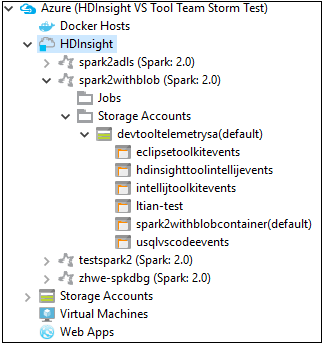
可以进一步展开群集名称节点,查看与群集关联的资源(例如存储帐户)。
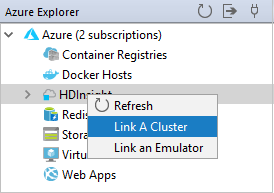
链接群集
可以使用 Ambari 管理的用户名链接标准群集。 同样,对于已加入域的 HDInsight 群集,也可使用这种域和用户名(例如 user1@contoso.com)进行链接。
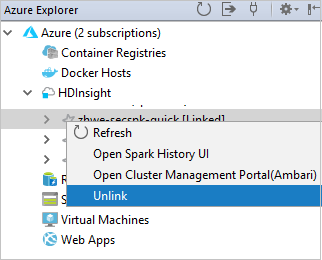
在“Azure 资源管理器”中右键单击“HDInsight”,然后选择“链接群集” 。
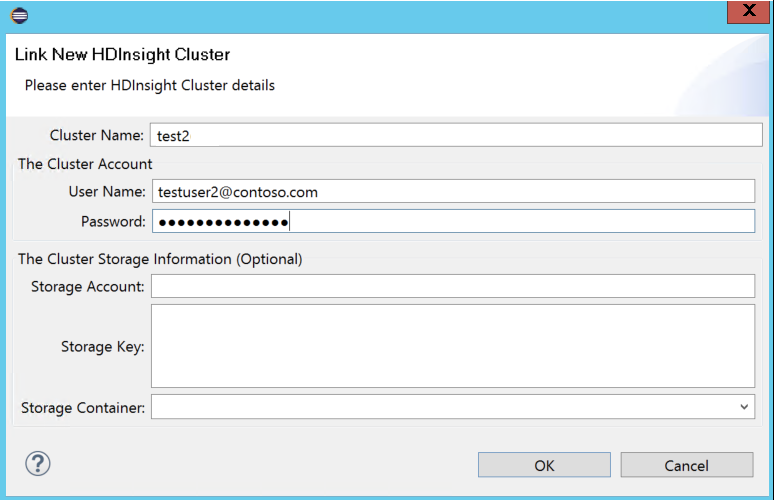
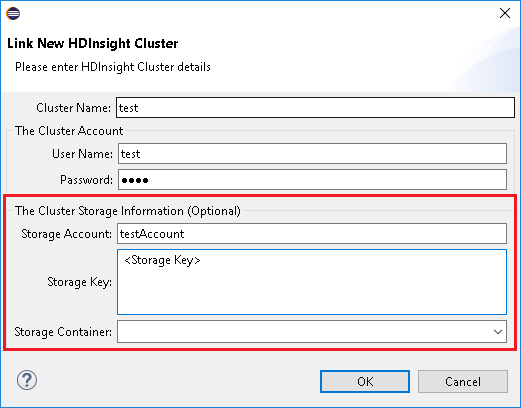
输入“群集名称”、“用户名”和“密码”,然后选择“确定” 。 (可选)输入“存储帐户”、“存储密钥”,然后选择“存储资源管理器”,以便存储资源管理器在左侧树状视图中工作
注意
如果群集已登录到 Azure 订阅中并且已链接群集,则我们使用链接存储密钥、用户名和密码。
对于仅使用键盘的用户,当前焦点位于“存储密钥”时,需要使用 Ctrl + TAB 来聚焦于对话框中的下一个字段。
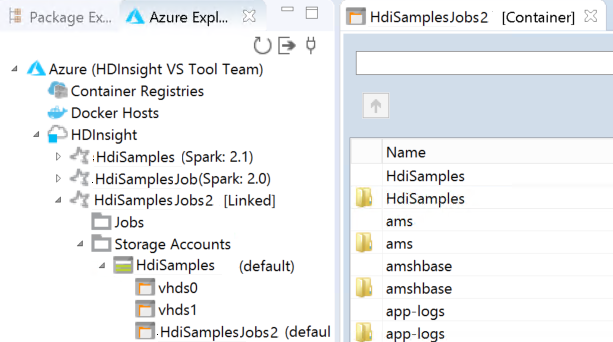
可在 HDInsight 下看到链接的群集。 现在可以将应用程序提交到此链接群集。
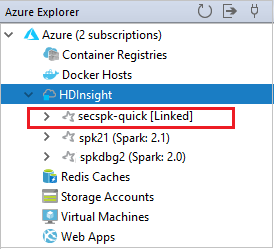
还可以从 Azure 资源管理器取消链接群集。
为 HDInsight Spark 群集设置 Spark Scala 项目
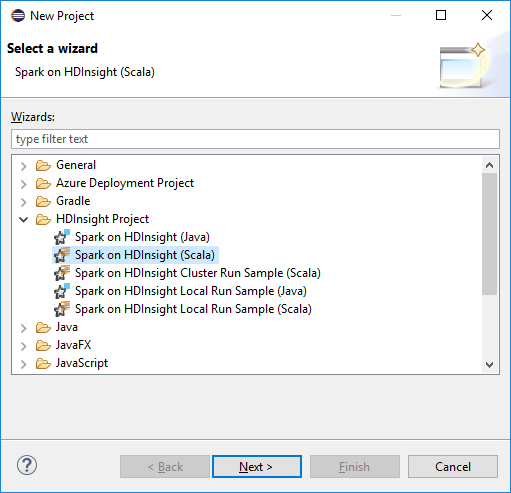
在 Eclipse IDE 工作区中选择“文件”>“新建”>“项目…” 。
在“新建项目”向导中选择“HDInsight 项目”>“Spark on HDInsight (Scala)” 。 然后,选择“下一步”。
在“新建 HDInsight Scala 项目”对话框中提供以下值,然后选择“下一步”:
- 输入项目的名称。
- 在“JRE”区域中,确保“使用执行环境 JRE”设置为“JavaSE-1.7”或更高版本。
- 在“Spark 库”区域中,可以选择“使用 Maven 配置 Spark SDK”选项。 我们的工具集成了适当版本的 Spark SDK 和 Scala SDK。 也可以选择“手动添加 Spark SDK”选项,手动下载并添加 Spark SDK。
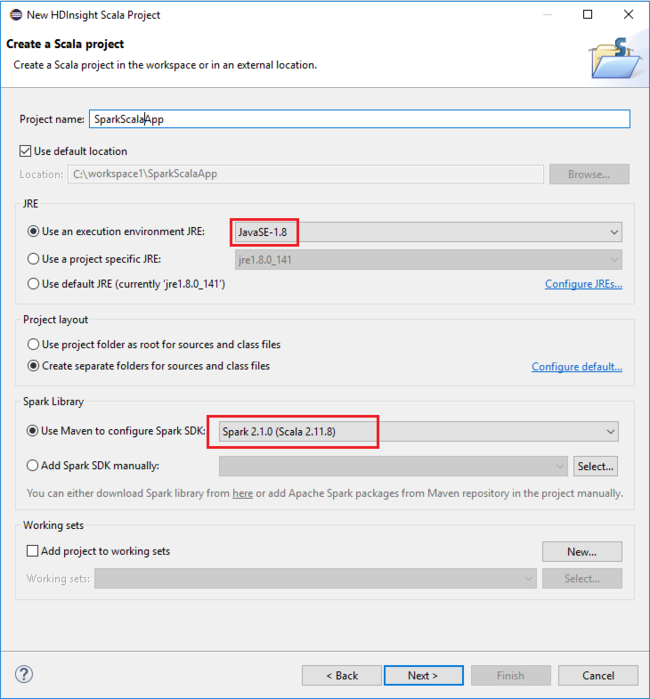
在下一个对话框中查看详细信息,然后选择“完成”。
为 HDInsight Spark 群集创建 Scala 应用程序
在“包资源管理器”中展开之前创建的项目。 右键单击“src”,选择“新建”>“其他…” 。
在“选择一个向导”对话框中选择“Scala 向导”>“Scala 对象” 。 然后,选择“下一步”。
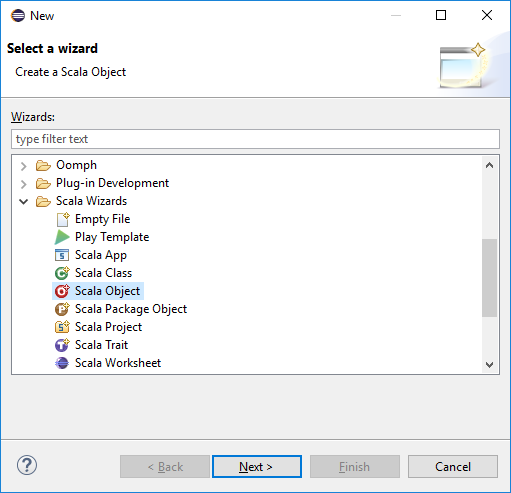
在“创建新文件”对话框中,输入对象的名称,然后选择“完成”。 将打开一个文本编辑器。
在文本编辑器中,将当前内容替换为以下代码:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object MyClusterApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("MyClusterApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }在 HDInsight Spark 群集中运行该应用程序:
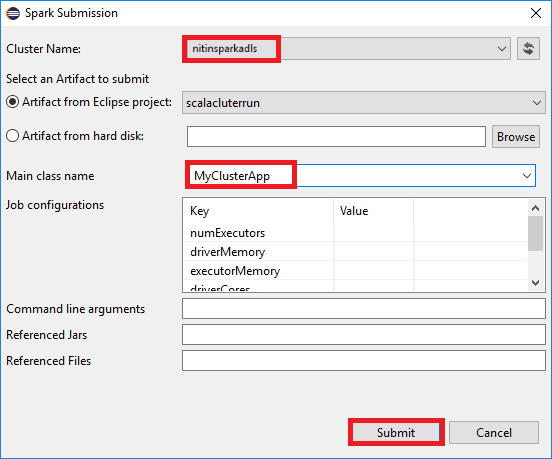
a. 在“包资源管理器”中,右键单击项目名称,然后选择“将 Spark 应用程序提交到 HDInsight”。
b. 在“Spark 提交”对话框中提供以下值,然后选择“提交”:
对于“群集名称”,选择要在其上运行应用程序的 HDInsight Spark 群集。
从 Eclipse 项目或硬盘中选择一个项目。 默认值取决于从包资源管理器右键单击的项。
在“主类名”下拉列表中,提交向导将显示项目中的所有对象名。 选择或输入要运行的对象的名称。 如果从硬盘中选择项目,必须手动输入主类名。
由于本示例中的应用程序代码不需要任何命令行参数,也不需要引用 JAR 或文件,因此可以将其余的文本框留空。
“Spark 提交”选项卡应开始显示进度。 可以通过选择“Spark 提交”窗口中的红色按钮停止应用程序。 也可以选择地球图标(以图中的蓝色框表示),查看此特定应用程序运行的日志。
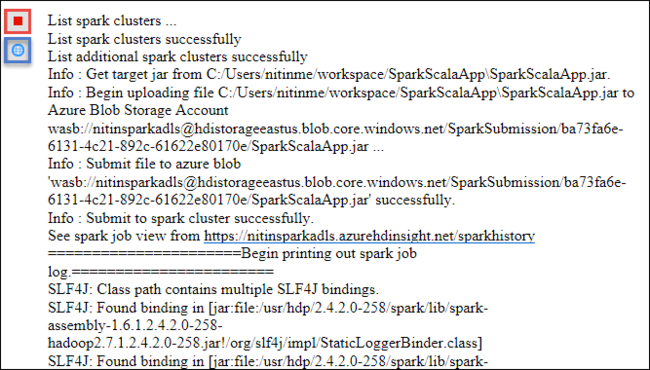
使用 Azure Toolkit for Eclipse 中的 HDInsight 工具访问和管理 HDInsight Spark 群集
可以使用 HDInsight 工具执行各种操作,包括访问作业输出。
访问作业视图
在“Azure 资源管理器”中依次展开“HDInsight”和 Spark 群集名称,然后选择“作业” 。
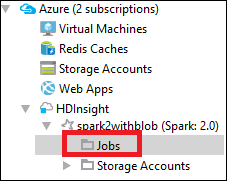
选择“作业”节点。 如果 Java 版本低于 1.8,HDInsight 工具会自动提醒你安装 E(fx)clipse 插件。 选择“确定”继续,然后按照向导指示从 Eclipse Marketplace 安装该插件并重启 Eclipse。
从“作业”节点打开作业视图。 在右窗格中,“Spark 作业视图”选项卡显示了群集上运行的所有应用程序。 选择想要查看其详细信息的应用程序的名称。
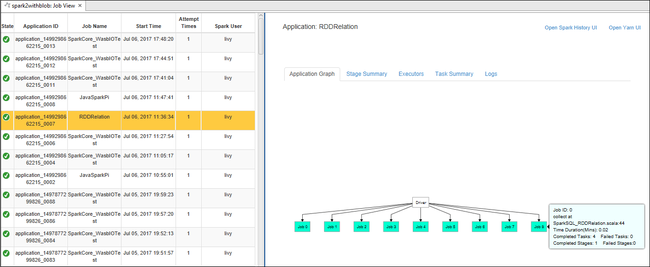
然后,可以执行以下任一操作:
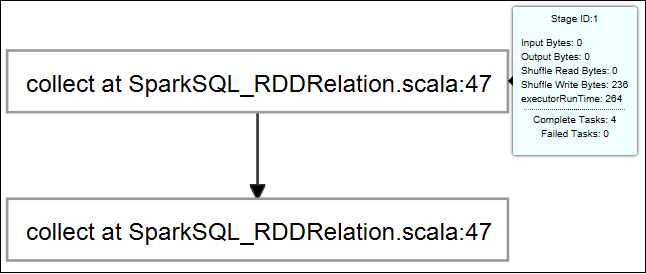
将鼠标悬停在作业图上。 将显示有关运行作业的基本信息。 选择作业图,可以看到每个作业生成的阶段和信息。
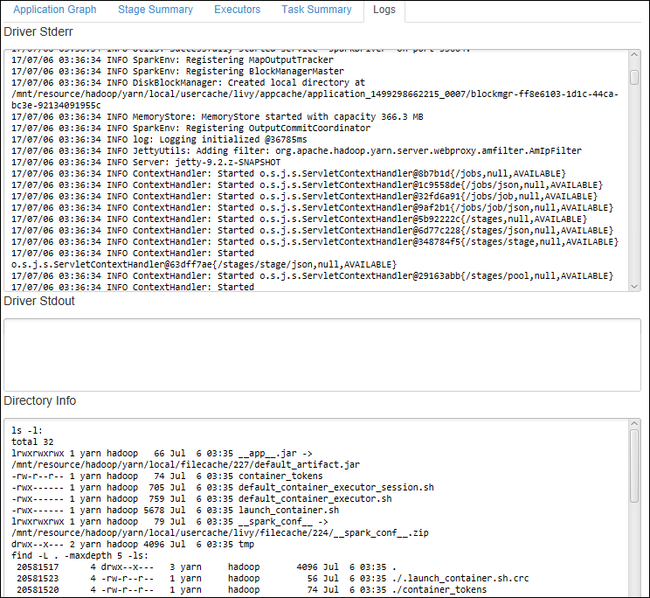
选择“日志”选项卡查看常用的日志,包括“驱动程序 Stderr”、“驱动程序 Stdout”和“目录信息”。
选择窗口顶部的超链接打开 Spark 历史记录 UI 和 Apache Hadoop YARN UI(应用程序级别)。
访问群集的存储容器
在 Azure 资源管理器中展开“HDInsight”根节点,查看可用 HDInsight Spark 群集的列表。
展开群集名称以查看群集的存储帐户和默认存储容器。
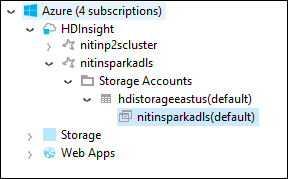
选择与群集关联的存储容器名称。 在右窗格中,双击“HVACOut”文件夹。 打开其中一个 part- 文件可查看应用程序的输出。
访问 Spark 历史记录服务器
在“Azure 资源管理器”中,右键单击 Spark 群集名称,然后选择“打开 Spark 历史记录 UI”。 出现提示时,请输入群集的管理员凭据。 预配群集时已指定这些凭据。
在“Spark 历史记录服务器”仪表板中,可以使用应用程序名称查找刚运行完的应用程序。 在上述代码中,已使用
val conf = new SparkConf().setAppName("MyClusterApp")设置了应用程序名称。 因此,Spark 应用程序名称为“MyClusterApp”。
启动 Apache Ambari 门户
在“Azure 资源管理器”中,右键单击 Spark 群集名称,然后选择“打开群集管理门户(Ambari)”。
出现提示时,请输入群集的管理员凭据。 预配群集时已指定这些凭据。
管理 Azure 订阅
默认情况下,用于 Eclipse 的 Azure 工具包中的 HDInsight 工具将列出所有 Azure 订阅中的 Spark 群集。 如果需要,可以指定想要访问其群集的订阅。
在“Azure 资源管理器”中,右键单击“Azure”根节点,并选择“管理订阅”。
在对话框中,清除不想访问的订阅对应的复选框,然后选择“关闭”。 如果想要从 Azure 订阅注销,可以选择“注销”。
本地运行 Spark Scala 应用程序
可以使用用于 Eclipse 的 Azure 工具包中的 HDInsight 工具在工作站上本地运行 Spark Scala 应用程序。 通常,这些应用程序不需要访问群集资源(如存储容器),并可以在本地运行和测试。
先决条件
在 Windows 计算机上运行本地 Spark Scala 应用程序时,可能会发生 SPARK-2356 中所述的异常。 发生这些异常的原因是 Windows 中缺少 WinUtils.exe。
若要解决此错误,需要将 Winutils.exe 下载到所需位置(例如 C:\WinUtils\bin),然后添加环境变量 HADOOP_HOME,并将该变量的值设为 C\WinUtils。
运行本地的 Spark Scala 应用程序
启动 Eclipse 并创建项目。 在“新建项目”对话框中做出以下选择,然后选择“下一步”。
在“新建项目”向导中选择“HDInsight 项目”>“Spark on HDInsight 本地运行示例 (Scala)” 。 然后,选择“下一步”。
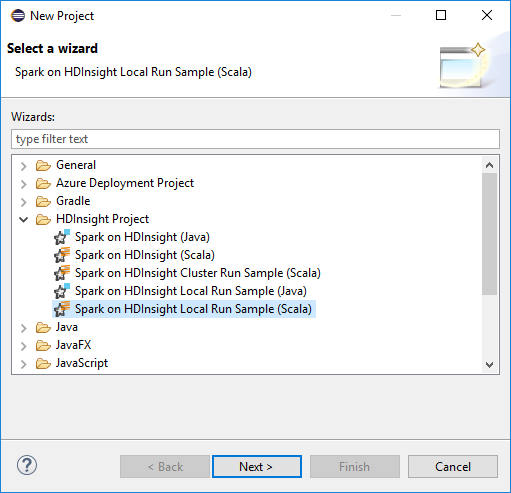
若要提供项目详细信息,请执行前面部分为 HDInsight Spark 群集设置 Spark Scala 项目中的步骤 3 到步骤 6。
模板将在 src 文件夹下面添加可在计算机上本地运行的示例代码 (LogQuery)。
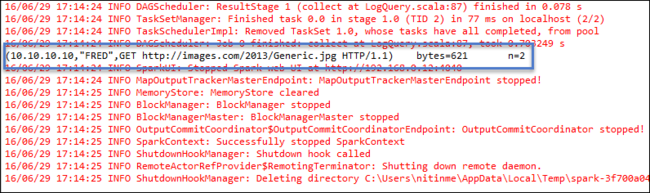
右键单击“LogQuery.scala”,并选择“运行方式”>“1 Scala 应用程序” 。 “控制台”选项卡上将出现如下所示的输出:
仅限读取者角色
当用户使用仅限读取者的角色权限将作业提交到群集时,必须提供 Ambari 凭据。
从上下文菜单链接群集
使用仅限读取者角色帐户登录。
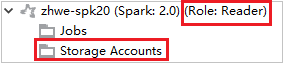
在“Azure 资源管理器”中展开“HDInsight”,查看订阅中的 HDInsight 群集。 标记为“角色:读取者”的群集只有仅限读取者角色权限。
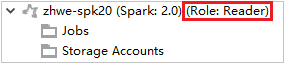
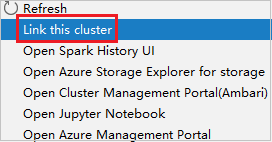
右键单击具有仅限读取者角色权限的群集。 从上下文菜单中选择“链接此群集”以链接群集。 输入 Ambari 用户名和密码。
如果已成功链接群集,HDInsight 将会刷新。 群集阶段将变为链接状态。
通过展开“作业”节点来链接群集
单击“作业”节点,此时会弹出“群集作业访问被拒绝”窗口。
单击“链接此群集”以链接群集。
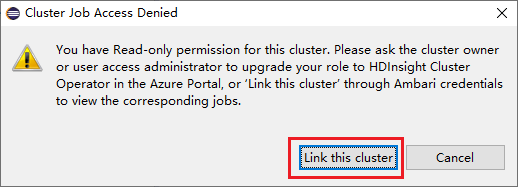
从“Spark 提交”窗口链接群集
创建一个 HDInsight 项目。
右键单击包。 然后选择“将 Spark 应用程序提交到 HDInsight”。
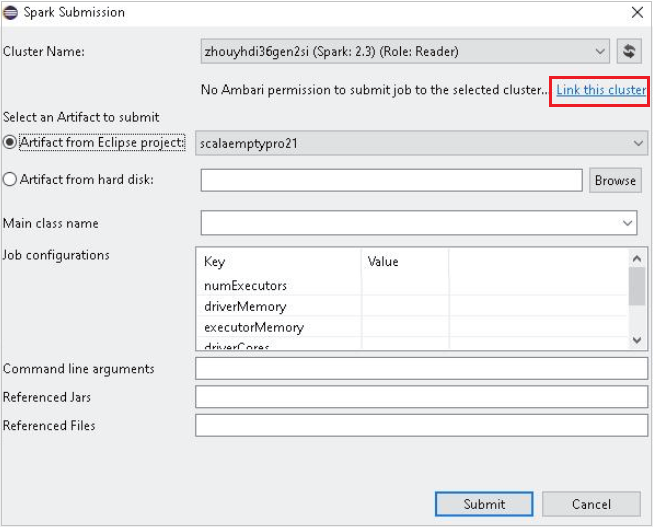
对于“群集名称”,请选择具有“仅读取者”角色权限的群集。 此时会显示警告消息。可以单击“链接此群集”以链接群集。
查看存储帐户
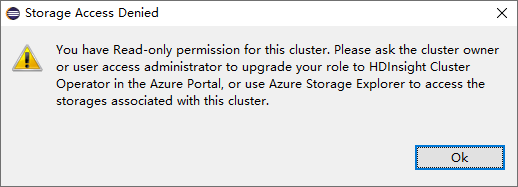
对于具有仅限读取者角色权限的群集,请单击“存储帐户”节点,此时会弹出“存储访问被拒绝”窗口。
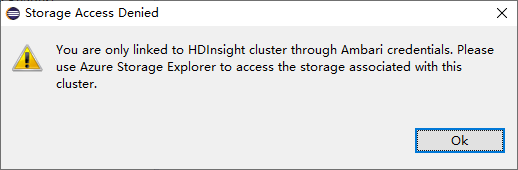
对于链接的群集,请单击“存储帐户”节点,此时会弹出“存储访问被拒绝”窗口。
已知问题
使用“链接群集”时,建议提供存储的凭据。
可通过两种模式提交作业。 如果提供存储凭据,则将使用批处理模式提交作业。 否则,将使用交互模式。 如果群集正忙,可能会收到以下错误。


另请参阅
方案
- Apache Spark 和 BI:使用 HDInsight 中的 Spark 和 BI 工具执行交互式数据分析
- Apache Spark 和机器学习:使用 HDInsight 中的 Spark 结合 HVAC 数据分析建筑物温度
- Apache Spark 与机器学习:使用 HDInsight 中的 Spark 预测食品检查结果
- 使用 HDInsight 中的 Apache Spark 分析网站日志
创建和运行应用程序
工具和扩展
- 使用用于 IntelliJ 的 Azure 工具包创建和提交 Spark Scala 应用程序
- 使用 Azure Toolkit for IntelliJ 通过 VPN 远程调试 Apache Spark 应用程序
- 使用 Azure Toolkit for IntelliJ 通过 SSH 远程调试 Apache Spark 应用程序
- 在 HDInsight 上的 Apache Spark 群集中使用 Apache Zeppelin 笔记本
- 在 HDInsight 的 Apache Spark 群集中可用于 Jupyter Notebook 的内核
- 将外部包与 Jupyter Notebook 配合使用
- Install Jupyter on your computer and connect to an HDInsight Spark cluster(在计算机上安装 Jupyter 并连接到 HDInsight Spark 群集)