本文介绍如何通过增量索引通过架构更改或内容更改更新Azure AI 搜索中的现有索引。
先决条件
更新或重新生成索引的权限:
- 基于密钥的身份验证:搜索服务的 管理员 API 密钥 。
- 基于角色的身份验证:用于文档更新的 搜索索引数据参与者角色,或用于架构更改的 搜索服务参与者角色。
对于 SDK 开发,请安装Azure搜索客户端库:
- Python:azure-search-documents
- .NET:Azure。Search.Documents
- JavaScript: @azure/search-documents
- Java:azure-search-documents
小窍门
在活动开发期间,在循环访问索引设计时通常会删除和重新生成索引。 使用具有代表性的小型数据示例,以便重新编制索引的速度会更快。 对于生产架构更改,请并排创建和测试新的索引,然后使用 索引别名 来交换索引,而无需更改应用程序代码。
更新内容
针对源数据的更改进行增量索引和同步索引是大多数搜索应用程序的基础。 本部分介绍通过 REST API 添加、删除或覆盖搜索索引内容的工作流,但Azure SDK提供等效的功能。
请求的正文包含要编入索引的一个或多个文档。 在请求中,索引中的每个文档为:
- 由区分大小写的唯一键标识。
- 与某个操作相关联:“上传”、“删除”、“合并”或“合并或上传”。
- 为每个要添加或更新的字段填充一组键/值对。
{
"value": [
{
"@search.action": "upload (default) | merge | mergeOrUpload | delete",
"key_field_name": "unique_key_of_document", (key/value pair for key field from index schema)
"field_name": field_value (key/value pairs matching index schema)
...
},
...
]
}
参考:文档 - 索引
首先,使用 API 加载文档,例如 Documents - Index (REST) 或Azure SDK中的等效 API。 有关索引技术的详细信息,请参阅加载文档。
对于大型更新,建议使用批处理(每批最多 1,000 个文档,或每批约 16 MB,具体取决于先达到哪个限制),以显著提高索引性能。
在 API 上设置
@search.action参数以确定对现有文档的影响。 用于mergeOrUpload增量更新(最常见的)、delete删除文档,或merge用于对现有文档进行部分字段更新。操作 效果 删除 从索引中移除整个文档。 如果你想删除某个字段,请改用合并,将相应字段设置为 NULL。 已删除的文档和字段不会立即释放索引中的空间。 每隔几分钟,后台进程就会执行物理删除。 无论是使用 Azure 门户还是 API 获取索引统计信息,删除操作在 Azure 门户和 API 中显示之前可能会稍有延迟。 有关详细信息,请参阅 搜索索引中的“删除文档”。 合并 更新已存在的文档,如果找不到该文档,则会失败。 合并将替换现有值。 因此,请务必检查是否有包含多个值的集合字段,例如类型为 Collection(Edm.String)的字段。 例如,如果tags字段以["budget"]值开头,并且你执行与["economy", "pool"]的合并,则tags字段的最终值为["economy", "pool"]。 不会是["budget", "economy", "pool"]。
同一行为适用于复杂的集合。 如果文档包含一个名为“Rooms”的复杂集合字段,其值为[{ "Type": "Budget Room", "BaseRate": 75.0 }],而你执行的合并的值为[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }],则“Rooms”字段的最终值将为[{ "Type": "Standard Room" }, { "Type": "Budget Room", "BaseRate": 60.5 }]。 它不会追加或合并新的和现有的值。合并或上传 如果文档已存在,则行为类似于合并;如果文档是新的,则类似于上传。 这是增量更新的最常见操作。 上传 类似于“更新插入”,如果文档是新文档,则插入;如果文档已经存在,则进行更新或替换。 如果文档缺少索引所需的值,则将文档字段的值设置为 null。
查询会在索引编制期间继续运行,但如果您更新或移除现有字段,则可能会出现混合结果,并且发生节流的可能性更高。
注意
对于请求正文中的哪个操作首先执行,没有任何顺序保证。 不建议在单个请求正文中,将多个“合并”操作与同一文档关联。 如果同一文档需要多个“merge”操作,请先在客户端执行合并操作,然后再更新搜索索引中的文档。
响应
成功的响应会返回状态代码 200,这意味着所有项都已持久存储并将开始编入索引。 索引编制在后台运行,使新文档在索引编制操作完成几秒钟后就可用(即可供查询和搜索)。 具体延迟取决于服务的负载。
如果所有项的 status 属性都设置为 true,且 statusCode 属性设置为 201(针对新上传的文档)或 200(针对合并或删除的文档),则表明已成功编制索引:
{
"value": [
{
"key": "unique_key_of_new_document",
"status": true,
"errorMessage": null,
"statusCode": 201
},
{
"key": "unique_key_of_merged_document",
"status": true,
"errorMessage": null,
"statusCode": 200
},
{
"key": "unique_key_of_deleted_document",
"status": true,
"errorMessage": null,
"statusCode": 200
}
]
}
当至少有一个项未成功编入索引时,会返回状态代码 207。 未编入索引的项会将“status”字段设置为 false。
errorMessage 和 statusCode 属性会指示索引编制错误的原因:
{
"value": [
{
"key": "unique_key_of_document_1",
"status": false,
"errorMessage": "The search service is too busy to process this document. Please try again later.",
"statusCode": 503
},
{
"key": "unique_key_of_document_2",
"status": false,
"errorMessage": "Document not found.",
"statusCode": 404
},
{
"key": "unique_key_of_document_3",
"status": false,
"errorMessage": "Index is temporarily unavailable because it was updated with the 'allowIndexDowntime' flag set to 'true'. Please try again later.",
"statusCode": 422
}
]
}
errorMessage 属性会尽可能指示索引编制错误的原因。
下表说明可在响应中返回的各种每文档状态代码。 某些状态代码会指示请求本身的问题,而另一些代码会指示临时错误条件。 对于后者,应在延迟后重试。
| 状态代码 | 含义 | 可重试 | 备注 |
|---|---|---|---|
| 200 | 文档已成功修改或删除。 | 不适用 | 删除操作是幂等的。 也就是说,即使索引中不存在某个文档键,使用该键尝试执行删除操作也会生成 200 状态代码。 |
| 201 | 已成功创建文档。 | 不适用 | |
| 400 | 文档中存在阻止其编入索引的错误。 | 否 | 响应中的错误消息指示文档存在的问题。 |
| 404 | 文档无法合并,因为索引中不存在给定键。 | 否 | 上传不会发生此错误,因为上传会创建新文档;删除不会发生此错误,因为删除是幂等的。 |
| 409 | 尝试将文档编入索引时检测到了版本冲突。 | 是 | 尝试将相同文档同时多次编入索引时,可能发生此错误。 |
| 422 | 索引暂时不可用,因为它在“allowIndexDowntime”标志设置为“true”时被更新。 | 是 | |
| 429 | 请求过多 | 是 | 如果在编制索引期间收到此错误代码,则通常意味着存储不足。 接近 存储限制时,服务可以进入在删除某些文档之前无法添加或更新的状态。 有关详细信息,请参阅 “规划和管理容量 ”(如果需要更多存储空间)或通过删除文档释放空间。 |
| 503 | 搜索服务暂时不可用,可能是因为负荷较重。 | 是 | 在此情况下,代码应在重试前等待,否则面临延长服务不可用性状态的风险。 |
如果客户端代码经常遇到 207 响应,则一个可能的原因是系统过载。 可通过检查 statusCode 属性是否为 503 来确认这种情况。 如果 statusCode 为 503,我们建议限制索引编制请求。 否则,如果索引流量不下降,系统可能开始使用 503 错误拒绝所有请求。
状态代码 429 指示已超出每个索引的文档数配额。 必须创建新索引或升级以提高容量限制。
注意
将带时区信息的 DateTimeOffset 值上传到索引时,Azure AI 搜索将这些值规范化为 UTC。 例如,2024-01-13T14:03:00-08:00 会存储为 2024-01-13T22:03:00Z。 如果需要存储时区信息,请在索引中为该数据点添加一个额外的列。
增量索引编制建议
索引器自动执行增量索引编制。 如果你可以使用索引器,并且数据源支持更改跟踪,则可以按定期计划运行索引器来添加、更新或覆盖可搜索的内容,以便将其同步到你的外部数据。
如果要直接通过推送 API 进行索引调用,请使用
mergeOrUpload作为搜索操作。负载必须包含要添加、更新或删除的每个文档的键或标识符。
如果索引包含矢量字段,且
stored属性设置为 false,请确保在部分文档更新中提供矢量,即使该值保持不变也是如此。 将stored设置为 false 的副作用是,在执行重新编制索引操作时会丢弃向量。 在文档有效负载中提供矢量可防止发生这种情况。若要更新复杂类型中简单字段和子字段的内容,请仅列出要更改的字段。 例如,如果只需要更新说明字段,则有效负载应包含文档键和修改后的说明。 省略其他字段会保留其现有值。
要将内联更改合并到字符串集合中,请提供整个值。 回想上一部分中的
tags字段示例。 新值会替换整个字段的旧值,字段内容中的数据不会进行合并。
下面是演示这些使用技巧的 REST API 示例:
### Get Stay-Kay City Hotel by ID
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
### Change the description, city, and tags for Stay-Kay City Hotel
POST {{baseUrl}}/indexes/hotels-vector-quickstart/docs/search.index?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"value": [
{
"@search.action": "mergeOrUpload",
"HotelId": "1",
"Description": "I'm overwriting the description for Stay-Kay City Hotel.",
"Tags": ["my old item", "my new item"],
"Address": {
"City": "Gotham City"
}
}
]
}
### Retrieve the same document, confirm the overwrites and retention of all other values
GET {{baseUrl}}/indexes/hotels-vector-quickstart/docs('1')?api-version=2026-04-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Reference:Documents - Index、 Lookup Document
SDK 示例
以下示例演示如何使用Azure SDK更新文档。
from azure.core.credentials import AzureKeyCredential
from azure.search.documents import SearchClient
# Set up the client
service_name = "<your-search-service-name>"
index_name = "hotels-sample"
api_key = "<your-admin-api-key>"
endpoint = f"https://{service_name}.search.azure.cn"
credential = AzureKeyCredential(api_key)
client = SearchClient(endpoint=endpoint, index_name=index_name, credential=credential)
# Update documents using merge_or_upload
documents = [
{
"HotelId": "1",
"Description": "Updated description for the hotel.",
"Tags": ["updated", "renovated"]
}
]
result = client.merge_or_upload_documents(documents=documents)
print(f"Updated {len(result)} document(s)")
Reference:SearchClient,merge_or_upload_documents
更新索引架构
索引架构定义在搜索服务上创建的物理数据结构,因此,没有很多无需完全重新生成即可进行的架构更改。
无需重建的更新
以下列表枚举了可无缝引入现有索引的架构更改。 通常,该列表包括查询执行期间使用的新字段和功能。
- 添加 索引说明
- 添加新字段
- 在现有字段上设置
retrievable特性 - 在具有现有的
searchAnalyzer的字段上更新indexAnalyzer - 在索引中添加新的分析器定义(该定义可应用于新字段)
- 添加、更新或删除评分配置文件
- 添加、更新或删除 同义词映射
- 添加、更新或删除语义配置
- 添加、更新或删除 CORS 设置
操作顺序为:
请根据上一个列表中的更新修订架构。
如果添加了新字段,请更新索引内容以匹配修订后的架构。 对于所有其他更改,将按原样使用现有索引内容。
更新索引架构以包含新字段时,将为索引中的现有文档提供该字段的 null 值。 在下一个索引作业中,外部源数据中的值将替换Azure AI 搜索添加的 null 值。
更新期间不应发生查询中断,但查询结果将会因更新生效而发生变化。
需要重建的更新
某些修改需要删除和重新生成索引,从而将当前索引替换为新的索引。
| 操作 | 说明 |
|---|---|
| 删除字段 | 若要以物理方式删除字段的所有跟踪,必须重新生成索引。 在立即重新生成不可行时,可修改应用程序代码以重定向访问,使其远离过时的字段,或者使用 searchFields 和 select 查询参数来选择要搜索和返回的字段。 实际上,当你应用省略了相关字段的架构时,字段定义和内容会一直保留在索引中,直至下次重新生成。 |
| 更改字段定义 | 对字段名称、数据类型或特定的索引属性(可搜索、可筛选、可排序、可查找)的修改需要完全重新生成。 |
| 向字段分配分析器 | 分析器在索引中定义,分配给字段,然后在索引编制期间进行调用,以告知令牌的创建方式。 随时都可以向索引添加新的分析器定义,但只有在创建字段时才能分配分析器。 对于 analyzer 和 indexAnalyzer 属性都是如此。 searchAnalyzer 属性是一个例外(可以向现有字段分配此属性)。 |
| 更新或删除索引中的分析器定义 | 无法删除或更改索引中的现有分析器配置(分析器、tokenizer、令牌筛选器或字符筛选器),除非重新生成整个索引。 |
| 将字段添加到建议器 | 如果某个字段已存在,并且希望将其添加到建议器构造,则重新生成索引。 |
| 切换级别 | 不支持就地升级。 如果需要更多容量,创建新服务并从头开始重新生成索引。 为了帮助自动执行此过程,可以使用将索引备份到一系列 JSON 文件的代码示例。 然后,可以在指定的搜索服务中重新创建索引。 |
操作顺序为:
如果需要索引定义以供将来参考,或将其用作新版本的基础,请获取索引定义。
请考虑使用备份和还原解决方案来保留索引内容的副本。 C# 和 Python 中有解决方案。 建议使用Python版本,因为它更最新。
如果搜索服务上具有容量,请在创建和测试新索引的同时保留现有索引。
删除现有索引。 针对该索引的查询会被立即删除。 请注意,删除索引是不可逆的,此操作会销毁字段集合和其他构造的物理存储空间。
发布修订后的索引,其中,请求正文包括已更改或已修改的字段定义和配置。
从外部来源用文档加载索引。 文档会通过新架构的字段定义和配置进行索引编制。
创建索引时,将为索引架构中的每个字段分配物理存储,并为每个可搜索字段和为每个矢量字段创建的矢量索引创建一个反向索引。 不可搜索的字段可以用于筛选器或表达式中,但没有反向索引也不支持全文或模糊搜索。 在重新生成索引时,这些反向索引和矢量索引会被删除,并根据你提供的索引架构重新创建。
为了最大限度地减少对应用程序代码的干扰,请考虑创建索引别名。 应用程序代码会引用该别名,而你可以更新该别名指向的索引的名称。
添加索引说明
索引具有一个 description 属性,可以在系统必须访问多个索引并根据说明做出决策时指定和使用该属性。 请考虑模型上下文协议 (MCP) 服务器,该服务器必须在运行时选取正确的索引。 决策可以基于说明而不是仅基于索引名称。
索引说明是架构更新,无需重新生成整个索引即可添加它。
- 字符串长度最大为 4,000 个字符。
- 在 Unicode 中,内容必须是人可读的。 用例应确定要使用的语言。
可以通过Azure门户、最新的稳定 REST API 或提供该功能的Azure SDK包添加索引说明。
Azure门户支持最新的预览 API。
在 Azure 门户中,转到你的搜索服务。
在 “搜索管理>索引”下,选择一个索引。
选择“编辑 JSON”。
插入
"description",后跟说明。 该值必须小于 4,000 个字符,并且必须位于 Unicode 中。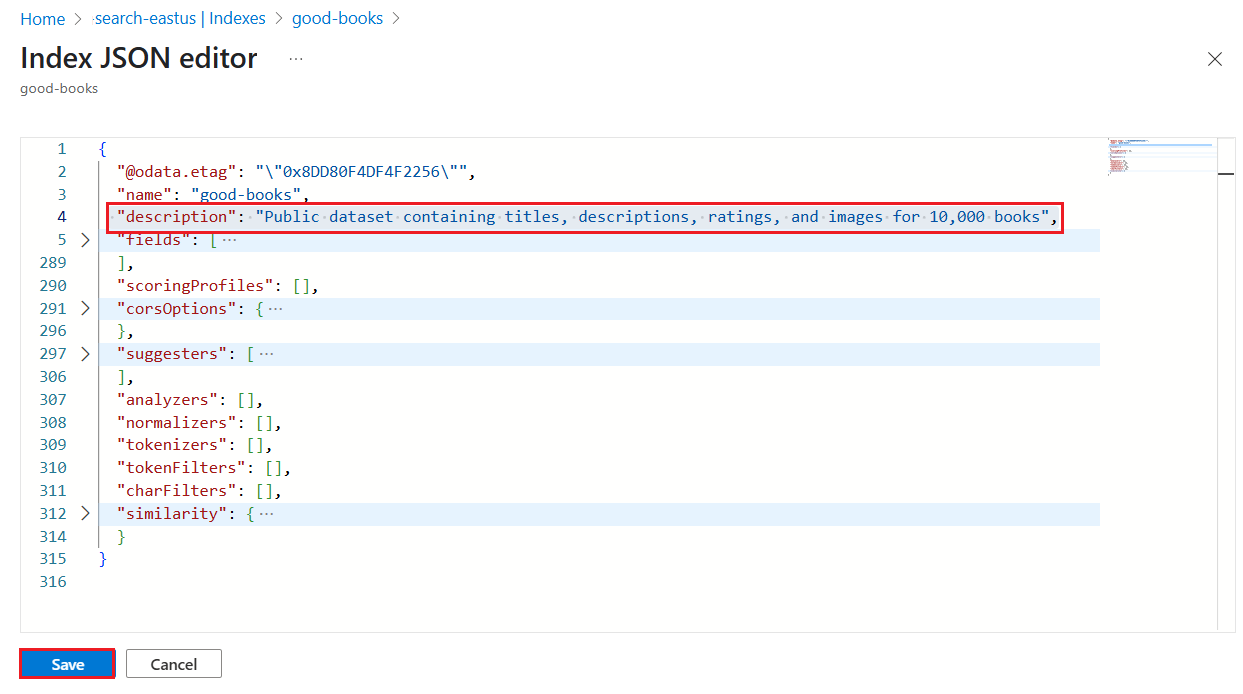
保存索引。
实现工作负载均衡
索引不在后台运行,但搜索服务会将所有索引作业与正在进行的查询进行均衡。 在编制索引期间,可以在Azure门户中监视查询请求,以确保查询及时完成。
如果索引工作负载导致查询延迟达到不可接受的级别,请执行性能分析,并查看这些性能提示来了解潜在的缓解措施。
检查更新
在加载第一个文档时就可以开始查询索引。 如果你知道文档的 ID,那么查找文档 REST API 将返回特定的文档。 对于更大型的测试,应该等待索引完全加载,然后使用查询来验证你想看到的上下文。
如果添加或重命名了某个字段,请使用 select 返回该字段:
"search": "*",
"select": "document-id, my-new-field, some-old-field",
"count": true
Azure门户提供索引大小和向量索引大小。 更新索引后,可以检查这些值,但请记住,在服务处理更改并考虑门户刷新率时会出现一点小延迟(可能为几分钟)。
索引重建疑难解答
下表列出了更新或重新生成索引时的常见问题,以及如何解决这些问题。
| 問题 | 原因 | 决议 |
|---|---|---|
| 包含混合结果的 207 响应 | 某些文档成功,其他文档失败。 | 请检查响应中的每个文档 statusCode。 如果为 503,请限制请求并重试。 |
| 409 版本冲突 | 对同一文档的并发更新。 | 序列化对同一文档的更新,或使用指数退避实现重试。 |
| 429 请求过多 | 超过存储配额或并发请求过多。 | 删除文档以释放空间,或升级服务层级以获取更多容量。 |
| 503 服务不可用 | 服务负载过重 | 等待并使用指数退避进行重试。 请考虑减小批大小。 |
| 删除后未更改的文档计数 | 删除是异步的。 | 等待 2-3 分钟,让后台进程完成物理删除。 |
| 新字段返回 null | 架构中已添加字段,但文档未重新编制索引。 | 运行索引器或推送更新的文档以填充新字段。 |
| 架构更改被拒绝 | 尝试执行不兼容的更改(例如重命名或类型更改)。 | 删除并重新生成索引。 使用索引别名将停机时间降到最低。 |